Python读取CSV文件遇到问题
目前,Python3(以下简称Python)至少有三种办法读取CSV格式文件,分别是:
1.csv模块
2.numpy里面的loadtxt方法
3.pandas里面的read_csv方法
python中有一个读写csv文件的包,直接import csv即可。利用这个python包可以很方便对csv文件进行操作,一些简单的用法如下。
1. 读文件
csv_reader = csv.reader(open('data.file', encoding='utf-8'))
for row in csv_reader:
print(row)
例如有如下的文件
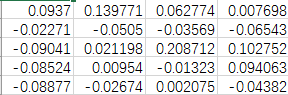
输出结果如下
['0.093700','0.139771','0.062774','0.007698']
['-0.022711','-0.050504','-0.035691','-0.065434']
['-0.090407','0.021198','0.208712','0.102752']
['-0.085235','0.009540','-0.013228','0.094063']
可见csv_reader把每一行数据转化成了一个list,list中每个元素是一个字符串。
2. 写文件
读文件时,我们把csv文件读入列表中,写文件时会把列表中的元素写入到csv文件中。
list = ['1', '2','3','4'] out = open(outfile, 'w') csv_writer = csv.writer(out) csv_writer.writerow(list)
可能遇到的问题:直接使用这种写法会导致文件每一行后面会多一个空行。
解决办法如下:
out = open(outfile, 'w', newline='') csv_writer = csv.writer(out, dialect='excel') csv_writer.writerow(list)
问题:想读取每列的数据,画出折线图,没想到总是报错,后来才意识到csv.reader函数读取的list是字符型,所以进行转换类型。
python中map()函数接收两个参数,一个是函数,一个是序列,map将传入的函数依次作用到序列的每个元素,并把结果作为新的list返回。
python里面直接转一维的list
问题 1:
list=['0', '1', '2', '3', '4', '5', '6', '7', '8', '9']
转化为:list=[0, 1 ,2, 3, 4, 5, 6, 7, 8, 9]
代码如下:
1 list_to_float = list(map(lambda x:float(x), list))问题2:(对于二维数组,需要加个循环,变成一维数组)
list=[['0', '1', '2'], ['3', '4', '5'], ['6', '7', '8']]
转化为:list=[[0, 1 ,2], [3, 4, 5], [6, 7, 8]]
代码如下:
list_to_float = []
for each in list:
each_line=list(map(lambda x: float(x), each))
list_to_float.append(each_line)这样输出才不会报错:
with open(filename) as f: #打开文件文件并将内容储存在reader中
csv_data=csv.reader(f) #读取并将内容储存在reader中
list_str = [row[0] for row in csv_data] #读取每列的数据
list_float = list(map(lambda x:float(x), list_str)) #将list中的字符转为数字
print(list_float)