卷积神经网络的实现
最近开始学神经网络一个很重要的分支——卷积神经网络。什么是卷积神经网络,卷积神网络用来干什么,卷积神经网络比普通神经网络优越在哪儿,相信这些问题你都能在以下一些比较经典的博客或者教程中找到很好的答案,本篇博客,只是从我的角度来总结一下我所了解的卷积网络,做一个中间学习过程的巩固与拓展。
经典博客/教程
- 卷积神经网络的简单了解
- 知乎上对于CNN的直观解释
- 斯坦福大学CS231n课程的深入笔记
图像分类
谈CNN就不能不谈图像分类。卷积神经网络是一种专门来处理具有类似网格结构数据的神经网络,例如时间序列数据,图像数据。为什么说CNN也可用于时间序列数据呢?因为我们数据中所采用的时间,可以理解为是在时间轴上的一种按照一定规律采样的一维网格数据。但是卷积神经网络应用最多的,应该是图像分类领域。
图像分类问题涉及的方向很广,比如物体检测、图像分割、目标跟踪、背景建模……而在图像分类领域,所面临的困难与挑战也很多。相信大家在一些视频教学的开头也曾经看到(比如CS231n),其中有:
- Viewpoint variation 同物体可以从不同角度拍摄
- Scale variation 物体可视的大小通常有变化
- Deformation 很多物体形状会有所变化
- Occlusion 目标物体可能被挡住
- Illumination conditions 在像素层面上,光照影响很大
- Background clutter 背景干扰
- Intra-class variation 类内差异
诸多挑战。同样在设计算法进行图像方面的处理时,我们也要考虑到这些内在的问题,达到维持分类结论稳定的同时,保持对类间差距足够明敏感。
手动实现CNN
CNN的构成
-
卷积神经网络的卷积层包括:
- Zero Padding 零填充
- Convolve window 过滤器
- Convolution forward 前向传播
- Convolution backward 后向传播
-
卷积神经网络的池化层包括:
- Pooling forward 前向传播
- Create mask 创建mask
- Distribute value 分布值
- Pooling backward 后向传播
1. Zero-padding
每进行一次卷积和池化,数据矩阵的高度/宽度就会缩小一次。随着卷积神经网络层数的增多,高度/宽度就会一直缩小下去,直到0。采用Zero-padding可以保留住高和宽。
同时,填充可以保留图像边缘更多的信息,让每一层图像的边缘都发挥作用,而不至于被忽略掉。
实现:np.pad,假设a是一个五维数组(比如a.shape=(5,5,5,5,5)),你想在第二维上添加pad=1,在第三维上添加pad=3,剩下其他维度上pad=0,那么你可以这么实现:
a = np.pad(a, ((0,0), (1,1), (3,3), (0,0), (0,0)), 'constant', constant_values = (..,..))
实现zero_pad函数:
def zero_pad(X, pad):
"""
Pad with zeros all images of the dataset X. The padding is applied to the height and width of an image, as illustrated in Figure 1.
Argument:
X -- python numpy array of shape (m, n_H, n_W, n_C) representing a batch of m images
pad -- integer, amount of padding around each image on vertical and horizontal dimensions
Returns:
X_pad -- padded image of shape (m, n_H + 2*pad, n_W + 2*pad, n_C)
"""
X_pad = np.pad(X,((0,0),(pad,pad),(pad,pad),(0,0)),'constant',constant_values = 0)
return X_pad
2.卷积层
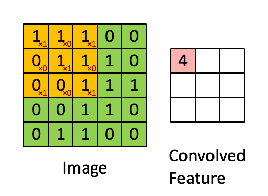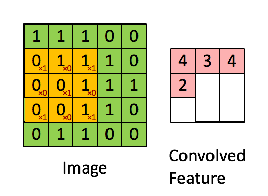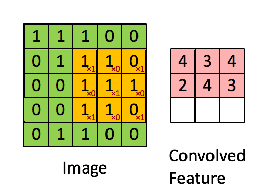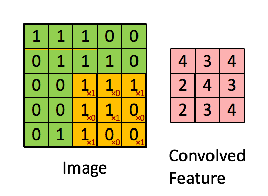
我们先建立一个卷积的单步函数,也就是只进行一次卷积中的一次计算。函数分为三部分:接收输入,应用过滤器,进行输出。
(1) 实现 conv_single_step函数:
def conv_single_step(a_slice_prev, W, b):
"""
Apply one filter defined by parameters W on a single slice (a_slice_prev) of the output activation of the previous layer.
Arguments:
a_slice_prev -- slice of input data of shape (f, f, n_C_prev)
W -- Weight parameters contained in a window - matrix of shape (f, f, n_C_prev)
b -- Bias parameters contained in a window - matrix of shape (1, 1, 1)
Returns:
Z -- a scalar value, result of convolving the sliding window (W, b) on a slice x of the input data
"""
s = np.multiply(a_slice_prev,W)
Z = np.sum(s)
Z = Z + float(b) #将b转化为浮点数,将Z转成标量.
return Z
下面基于上面的单步函数,实现一次卷积。输入值有: A_prev(前一层的值),过滤器F的权重(用W表示),每个过滤操作都有的不同的偏移量b,还有包含了stride(步幅)和padding(填充)的 hyperparameters dictionary(参数词典)。
(2) 实现conv_forward函数:
假定我们的过滤器大小为2×2×n,我们用vert_start、vert_end、horiz_start 和 horiz_end来准确定义每一个2×2 slice 的位置,如下图所示:
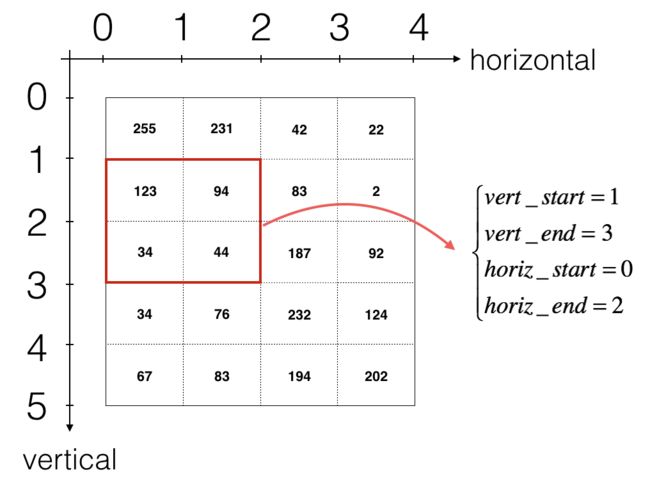
对于每个卷积层的输出,有如下公式计算n_H、n_W和N_c的shape。

我们不必担心矢量化, 只用 for 循环就可以实现一切。
def conv_forward(A_prev, W, b, hparameters):
"""
Implements the forward propagation for a convolution function
Arguments:
A_prev -- output activations of the previous layer, numpy array of shape (m, n_H_prev, n_W_prev, n_C_prev)
W -- Weights, numpy array of shape (f, f, n_C_prev, n_C)
b -- Biases, numpy array of shape (1, 1, 1, n_C)
hparameters -- python dictionary containing "stride" and "pad"
Returns:
Z -- conv output, numpy array of shape (m, n_H, n_W, n_C)
cache -- cache of values needed for the conv_backward() function
"""
# Retrieve dimensions from A_prev's shape
(m, n_H_prev, n_W_prev, n_C_prev) = A_prev.shape
# Retrieve dimensions from W's shape
(f, f, n_C_prev, n_C) = W.shape
# Retrieve information from "hparameters"
stride = hparameters['stride']
pad = hparameters['pad']
# Compute the dimensions of the CONV output volume using the formula given above.
n_H = int((n_H_prev - f +2 * pad)/stride) +1
n_W = int((n_W_prev - f +2 * pad)/stride) +1
# Initialize the output volume Z with zeros.
Z = np.zeros((m , n_H, n_W, n_C))
# Create A_prev_pad by padding A_prev
A_prev_pad = zero_pad(A_prev, pad)
for i in range(m): # loop over the batch of training examples
a_prev_pad = A_prev_pad[i] # Select ith training example's padded activation
for h in range(n_H): # loop over vertical axis of the output volume
for w in range(n_W): # loop over horizontal axis of the output volume
for c in range(n_C): # loop over channels (= #filters) of the output volume
# Find the corners of the current "slice"
vert_start = h*stride
vert_end = vert_start + f
horiz_start =w*stride
horiz_end = horiz_start + f
# Use the corners to define the (3D) slice of a_prev_pad (See Hint above the cell). (≈1 line)
a_slice_prev = a_prev_pad[vert_start:vert_end, horiz_start:horiz_end, :]
# Convolve the (3D) slice with the correct filter W and bias b, to get back one output neuron. (≈1 line)
Z[i, h, w, c] = conv_single_step(a_slice_prev, W[...,c], b[...,c])
# Making sure your output shape is correct
assert(Z.shape == (m, n_H, n_W, n_C))
# Save information in "cache" for the backprop
cache = (A_prev, W, b, hparameters)
return Z, cache
卷积层应该也包含一个激活函数,实现如下:
# Convolve the window to get back one output neuron
Z[i, h, w, c] = ...
# Apply activation
A[i, h, w, c] = activation(Z[i, h, w, c])
3.池化层
其实,池化层的一个作用是:通过最大池化方法来达到“视角不变性”。不变性意味着,如果我们略微调整输入,输出仍然是一样的。换句话说,在输入图像上,当我们稍微变换一下我们想要检测的对象时,由于最大池化的存在,网络活动(神经元的输出)将保持不变,网络仍然能检测到对象。
但是从另一个角度说,上述机制并不怎么好,因为最大池丢失了有价值的信息,也没有编码特征之间的相对空间关系。
池化方法一般来说通用的有两种,Max Pool和Average Pool,而Max Pool更加常用。输出的n_H、n_W以及n_C公式如下:

def pool_forward(A_prev, hparameters, mode = "max"):
"""
Implements the forward pass of the pooling layer
Arguments:
A_prev -- Input data, numpy array of shape (m, n_H_prev, n_W_prev, n_C_prev)
hparameters -- python dictionary containing "f" and "stride"
mode -- the pooling mode you would like to use, defined as a string ("max" or "average")
Returns:
A -- output of the pool layer, a numpy array of shape (m, n_H, n_W, n_C)
cache -- cache used in the backward pass of the pooling layer, contains the input and hparameters
"""
# Retrieve dimensions from the input shape
(m, n_H_prev, n_W_prev, n_C_prev) = A_prev.shape
# Retrieve hyperparameters from "hparameters"
f = hparameters["f"]
stride = hparameters["stride"]
# Define the dimensions of the output
n_H = int(1 + (n_H_prev - f) / stride)
n_W = int(1 + (n_W_prev - f) / stride)
n_C = n_C_prev
# Initialize output matrix A
A = np.zeros((m, n_H, n_W, n_C))
for i in range(m): # loop over the training examples
for h in range(n_H): # loop on the vertical axis of the output volume
for w in range(n_W): # loop on the horizontal axis of the output volume
for c in range (n_C): # loop over the channels of the output volume
# Find the corners of the current "slice"
vert_start = h*stride
vert_end = vert_start + f
horiz_start =w*stride
horiz_end = horiz_start + f
# Use the corners to define the current slice on the ith training example of A_prev, channel c.
a_prev_slice = A_prev[i, vert_start:vert_end, horiz_start:horiz_end, c]
# Compute the pooling operation on the slice. Use an if statment to differentiate the modes. Use np.max/np.mean.
if mode == "max":
A[i, h, w, c] = np.max(a_prev_slice)
elif mode == "average":
A[i, h, w, c] = np.mean(a_prev_slice)
# Store the input and hparameters in "cache" for pool_backward()
cache = (A_prev, hparameters)
# Making sure your output shape is correct
assert(A.shape == (m, n_H, n_W, n_C))
return A, cache
4.反向传播
在现代的深层学习框架中, 我们只需要实现前向传递, 而深度学习框架负责向后传递, 因此大多数深学习的工程师不必费心处理向后传递的细节。卷积网络的向后传递是复杂的。但是, 如果你想要去实现,可以通过下一节的内容, 去了解什么 Backprop 在一个卷积网络中是怎么个情况。