今天测试团队反馈说,服务A的响应很慢,我在想,测试环境也会慢?于是我自己用postman请求了一下接口,真的很慢,竟然要2s左右,正常就50ms左右的。
于是去测试服务器看了一下,发现服务器负载很高,并且该服务A占了很高的cpu。先用top命令,看了load average,发现都到了1.5左右(双核cpu)了,并且有一个java进程(20798)占用cpu一直很高,如下图:
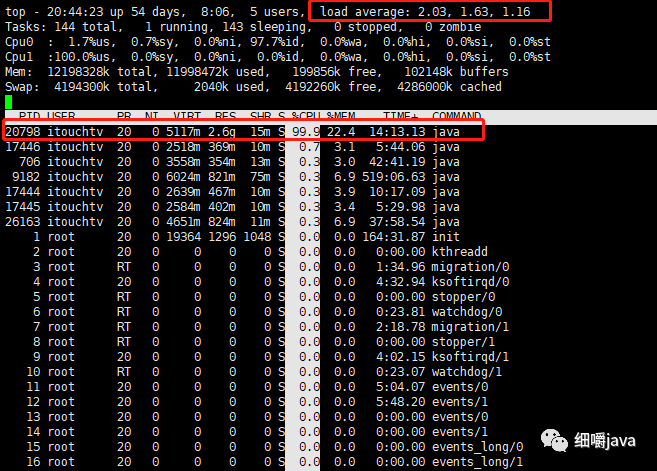
于是,用命令jps -l看了一下java的20798,刚好就是服务A。
究竟服务A在跑什么,毕竟是测试环境。于是使用top -Hp 20798看一下是哪个线程在跑,如下图:
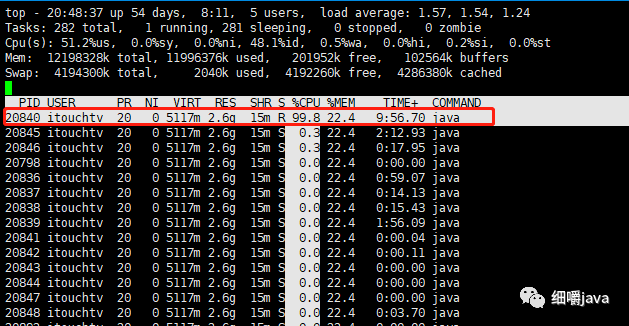
发现线程20840占用cpu非常高,其他几乎都是0。通过以下命令输出该线程id(20840)的16进制:
printf "%x\n" 20840
输出如下:
![]()
线程id(20840)的16进制是5186。
然后使用以下命令打印出该线程的堆栈信息:
jstack -l 20798 | grep -A 20 5168
输入如下:
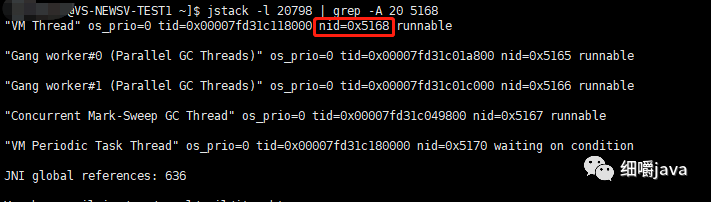
发现占用cpu的进程是jvm的GC线程,于是猜测是不是由于一直在进行FGC导致cpu飙高,于是使用以下命令看下FGC的频率和耗时:
jstat -gc 20798 1000
输出如下:
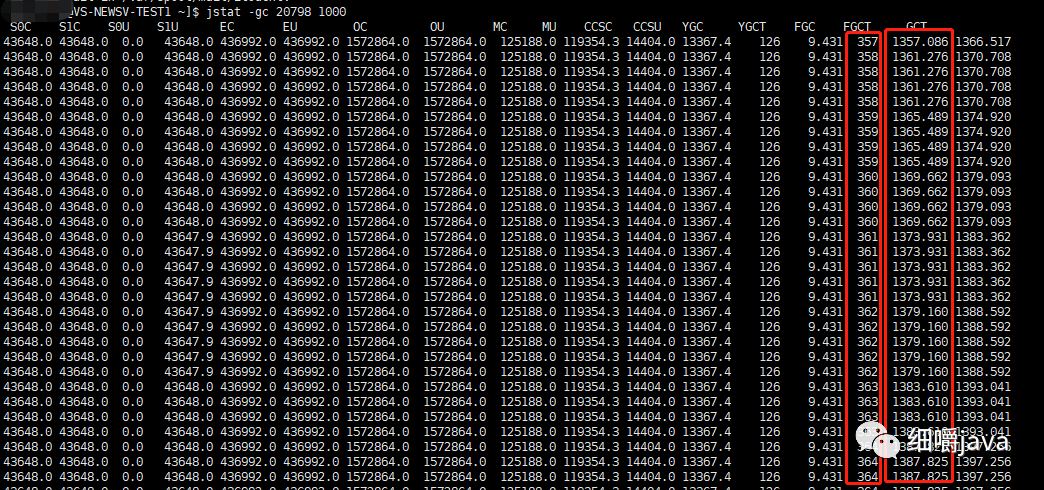
发现,果然是不断地在进行着FGC,并且每次FGC的时间一直在升高。是什么导致一直都在FGC呢?是有大对象一直在创建,回收不了?于是使用以下命令看下heap中的对象情况:
jmap -histo:live 20798 | head -20
输出如下:
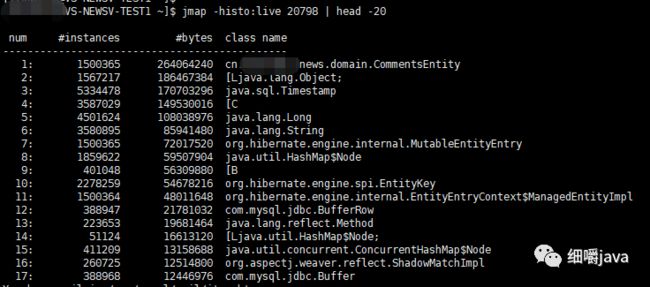
发现一个业务类对象竟然有150w+个,并且占用了264M的堆大小,什么情况,并且这150w+个对象还是存活的(注意jmap使用的时候,已经带上了:live选项,只输出存活的对象),吓我一跳。于是赶紧使用以下命令打出线程堆栈来看一下:
jstack -l 20798 > jstack_tmp.txt
输出如下:
![]()
然后使用如下命令在输出的线程堆栈中根据对象类查找一下:
grep -C 30 'omments' jstack_tmp.txt
输出如下:
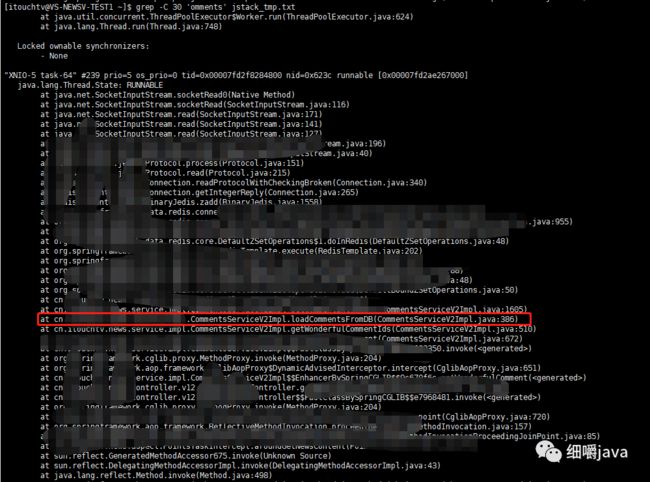
猜测是由于一下次从db load出了太多的CommentsEntity。
于是使用以下命令dump出heapdump出来重复确认一下:
jmap -dump:live,format=b,file=news_busy_live.hprof 20798
把heapdump文件news_busy_live.hprof下载到windows本地,使用mat工具进行分析,第一次打开发现打不开,毕竟news_busy_live.hprof有3G那么大,mat直接报OOM打不开,发现mat的配置文件MemoryAnalyzer.ini里面的配置-Xmx1024m,heap size才1G,太小了,于是改成-Xmx4096m,保存,重新打开mat,再打开news_busy_live.hprof文件即可,如下图:
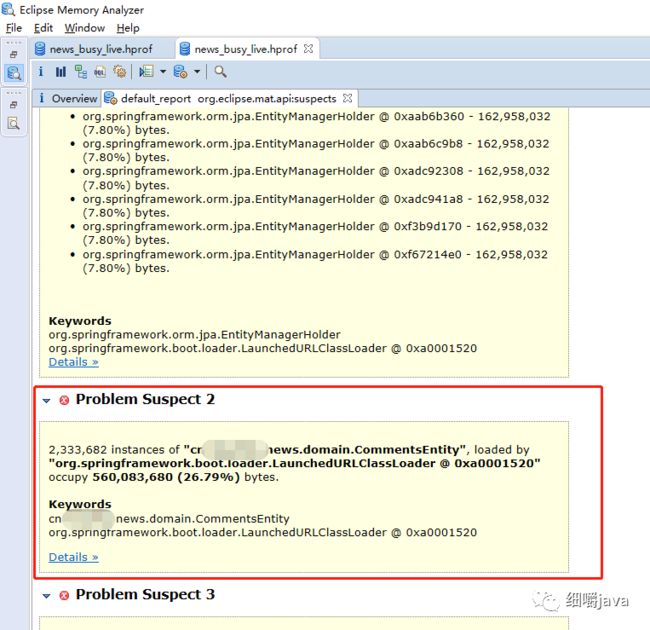
发现mat已经帮我们分析出了内存泄漏的可以对象,233w+个对象(前面通过jmap命令输出的150W+个,是后面为了写文章而专门重现的操作,这里的233w+个是当时真的出问题的时候dump出来的heap dump文件),太恐怖了。
通过以下操作,查看
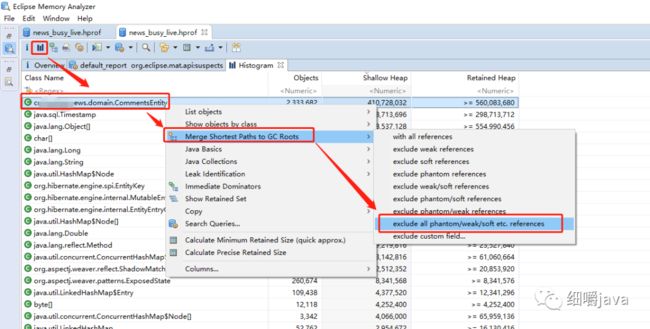
点击exclude all ....,因为弱引用,软引用,虚引用等都可以被GC回收的,所以exclude,输出如下:
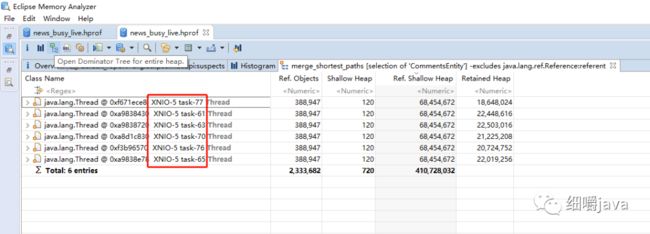
发现一共有6个线程引用了那233w+个对象,于是去前面dump出来的线程堆栈跟踪以下这几个线程的情况,发现堆栈里面刚好这几个线程也是在处理comments相关的逻辑,这个是刚好碰巧,一般线程id都对不上的,毕竟线程处理完之后就释放了的。所以我们还是看回前面线程堆栈的信息,这里贴出根据关键字"omment"搜索出来的线程堆栈的信息,如下:
"XNIO-5 task-77" #248 prio=5 os_prio=0 tid=0x00007fc4511be800 nid=0x8f7 runnable [0x00007fc3e5af2000] java.lang.Thread.State: RUNNABLE ... at cn.xxxxxx.news.commons.redis.RedisUtil.setZSet(RedisUtil.java:1080) at cn.xxxxxx.news.service.impl.CommentsServiceV2Impl.setCommentIntoRedis(CommentsServiceV2Impl.java:1605) at cn.xxxxxx.news.service.impl.CommentsServiceV2Impl.loadCommentsFromDB(CommentsServiceV2Impl.java:386) ... at cn.xxxxxx.xxxs.controller.vxxx.xxxxController.getxxxxxx(NewsContentController.java:404) at cn.xxxxxx.xxx.controller.vxxx.xxxxxController$$FastClassBySpringCGLIB$$e7968481.invoke() ... at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617) at java.lang.Thread.run(Thread.java:745) Locked ownable synchronizers: - <0x00000000f671ecd0> (a java.util.concurrent.ThreadPoolExecutor$Worker)
从上面的堆栈信息,结合前面的猜测(猜测是一次性从db load出太多的CommentsEntity),猜测应该是函数loadCommentsFromDB一次性从db load出太多CommentsEntity了。于是看了一下业务代码,发现load出来的commentsEntity会放到redis的某一个zset,于是使用redis destopmanger看一下这个zset的数据,发现这个zset有22w的数据,从中找出几条,发现对应的newsPk都是同一个,根据newsPk在db中找一下该newsPk的comments总记录,发现该newsPk的comments记录数是38w+条,那就是这个问题了,一次性从db中load了38w+的数据到内存。
一次性load那么多数据到内存,这肯定是一个慢查询,不管是db还是网络io,都肯定很慢。然后发现业务代码还会有一个for循环,把这个CommentsEntityList遍历一遍,一条一条放到redis,这也是一个非常慢的过程。
然后我去看了服务A的access log,发现在短时间内,请求了该newsPk多次数据,所以就导致了jvm的heap空间不够,然后出现不断FGC的现象,并且该newsPk的请求,由于超时,都在网关超时返回了。
为了验证这个问题,我把相关的redis缓存删除,然后调用该newsPk的接口获取数据,发现很慢,并且cpu立刻飚上去了,然后调多几次,并且不断地进行FGC,至此已经复现了该问题,和猜测的一样。等数据load到redis之后,再访问该接口,就很正常没问题。
上面发现问题的代码,找时间做一下优化才行,先重启服务A,让服务可用先。
欢迎关注微信公众号“ismallboy”,请扫码并关注以下公众号,并在公众号下面回复“FGC”,获得本文最新内容。