CSAPP(6)The Memory Hierarchy
文章目录
- Storage Techologies
- Random-Access Memory
- Static vs Dynamic
- Conventional DRAMs
- Nonvolatile Memory
- Disk Storage
- Disk Geometry
- Disk Operation
- Logical Disk Blocks
- Direct Memory Access
- Solid State Disks
- Locality
- The Memory Hierarchy
- Cache
- Cache Memories
- direct-mapped caches
- 步骤
- Conflict Misses
- Set Associative Caches
- 步骤
- Fully Associative Caches
- write
- write hit
- write miss
- Anatomy of a real cache hierarchy
- performance impact of cache parameters
- Write Cache-friendly Code
- The Impact of Caches on Program Performance
- memory mountain
- rearranging loops to increase spatial locality
- guideline
- Summary
Storage Techologies
Random-Access Memory
Static vs Dynamic
Static RAM(SRAM) is faster and significantly more expensive than Dynamic RAM(DRAM).SRAM is userd for cache memories,both on and off the CPU chip.DRAM is used for the main memory plus the frame buffer of a graphics system.Typically,a desktop system will hava no more than a few megabyptes of SRAM,but hundreds of thousands of megabytes of DRAM.
| Transistors per bit | ralative access time | persistent? | sensitive? | relative cost | applications | power | |
|---|---|---|---|---|---|---|---|
| SRAM | 6 | 1 X | Yes | No | 100 X | Cache memory | more |
| DRAM | 1 | 10 X | No | Yes | 1X | Main mem,frame buffers | less |
对于SRAM和DRAM而言,这背后是两种制造工艺,由于SRAM更复杂,它有两个稳定态,如果收到扰动会自动恢复,但是DRAM内部其实是一个电容,由于各种原因里面的电量会泄露,所以就需要不停的刷(把数据读出来再保存进去)或者使用校验位来保证数据正确.
Conventional DRAMs
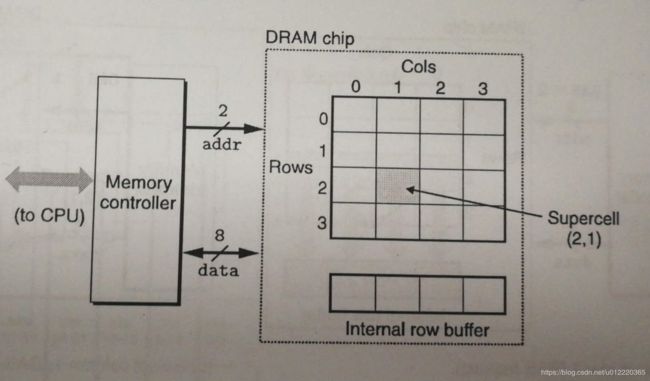
如上图所示,一个chip由r ✖ c 个supercell组成,每个supercell可以存储w bit的数据(一般w=8),除此外内部还有一个buffer.那么这个chip的容量就是w✖d=w✖(r✖c) bit.
chip对外连接依赖于pin,每个pin一次只能传输1bit数据,按照图中是由2个pin用于传输地址(所以传输地址时需要两次,一次用于RAS(Row Access Strobe),一次用于CAS(Column Access Strobe),8个pin用于传输数据.当chip收到RAS时就会把改行拷贝到buffer,当收到CAS后就将指定数据返回.采用RAS和CAS两次访问的好处是可以减少pin的数量,缺点当然是速度会慢一些
Nonvolatile Memory
Disk Storage
Disk Geometry
Disks are constructed from platters
each platter consists of two sides,of surfaces
a rotating spindle in the center of the platter spins the paltter
each surface consists of a collection of concentric rings called tracks
each track is partitioned into a collection of sectors,each sector contains an equal number of data bits(typically 512bytes) encoded in the magnetic material on the sector.
sectors are separated by gaps where no data bits are stored.Gaps store formatting bits that identify sectors
Disk manufacturers describe the geometry of multiple-platter drives in terms of cylinders,where a cylinder is the collection of tracks on all the surfaces that are equidistant from the center of the spindle.
至于每个track有多少sector呢?对于软盘是一样的,但是硬盘做了升级(否则太浪费),一般会把track分组,然后然后不同组的track所包含的sector不一样.
Disk Operation
磁盘一般是按sector来读取数据,所以读取一个sector的时间由三部分组成 T a c c e s s = T a v g s e e k + T a v g r o t a t i o n + T a v g t r a n s f e r T_{access}=T_{avg seek}+T_{avg rotation}+T_{avg_transfer} Taccess=Tavgseek+Tavgrotation+Tavgtransfer,其中前两者是占大头.
Logical Disk Blocks
人们将磁盘结构进行抽象为logical block,屏蔽了底层的物理细节,OS只关心logical block number,然后由disk controller来负责读取数据.当OS发出命令后先有Firmware根据fast table来获得对应的surface,track,sector,然后调用Hardware完成读取.
Direct Memory Access
DMA模式减少了将数据从磁盘读到内存中CPU的参与,CPU执行三条指令,分别是初始化,设置logical block number和发送内存地址给Disk Controller,然后就不用再参与直到完成后被中断.
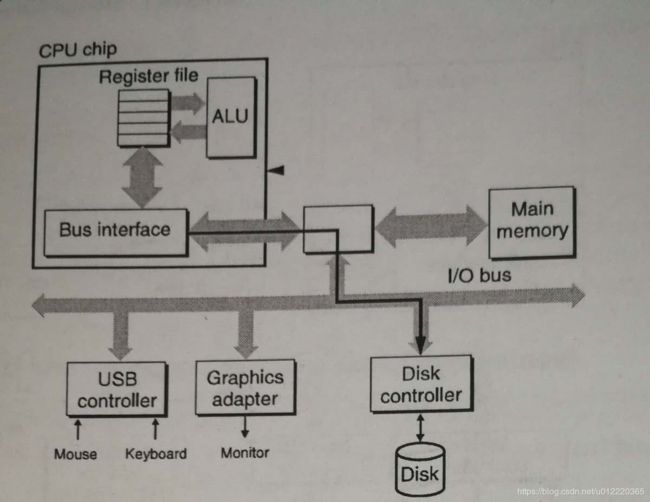
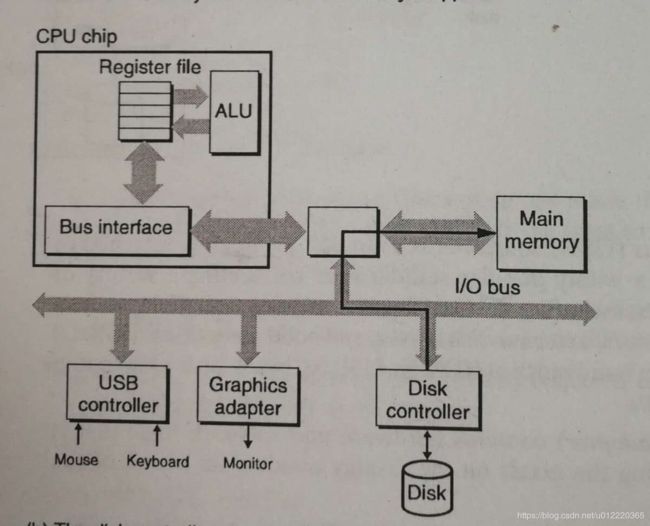
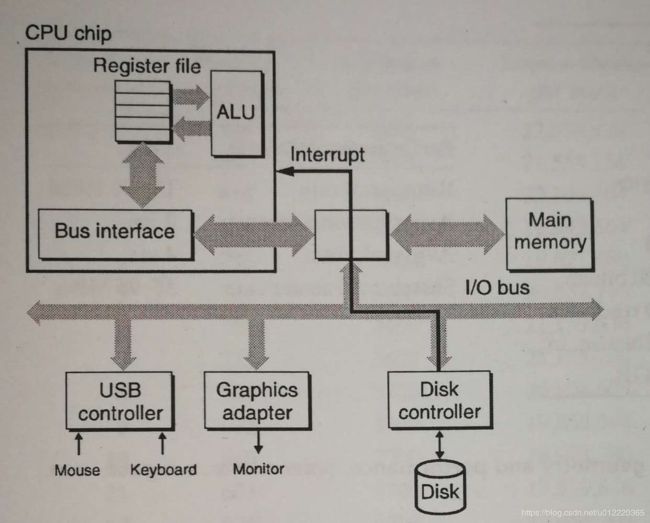
Solid State Disks
SSD的写比读慢的原因是写之前要先将被写的块进行格式化.随机写比顺序写慢很多的原因是写一个block的时候往往涉及到把block里的有用数据移动带其他空白的block里
Locality
temporal locality & spatial locality
三点技巧:
- 使用最近用过的变量
- 每次向前移动一步(对于array特别是多维)
- 使用循环
The Memory Hierarchy
Cache
这个涉及K和K+1之间怎么映射,当MISS的时候怎么剔除,包括最先开始的预热.
Cache Memories
在下面图中,Cache有S个set组成,而每个set又是由E个line组成,每个line由valid,tag,data三部分.其中valid用于表示改行是否有效,而数据的大小是B bytes.所以整个Cache的大小就是 C = S × E × B C=S\times E\times B C=S×E×B
根据上图可以知道查找Cache的过程:对于一个给出的内存地址m,可以得到t,s,b,其中s就是Cache的 S = 2 s S=2^s S=2s,可以直接到Cache的Set S中寻找,至于tag可能无法命中,如果命中就取出对应line的偏移量为b的数据
然后解释下为什么Set index要取address的中间几位.对于一个spatial locality良好的程序,他将会读地址连续的一些数据,如果取高位,那么这些数据就会映射到同一个set,从而冲突.下面的图更清楚解释了这个问题.
根据E的值不同可以分为以下几类
direct-mapped caches
E = 1 E=1 E=1
步骤
- Set Selection
这个比较简单,直接读取address的set index即可 - Line Matching
这个就是检查valid是true(1)并且tag和address的tag相等.如果没有则需要先执行下面第5步 - word selection
根据address的b值从cache中取出数据即可 - Line Replacement
如果没有则把cache中该line(在制定的Set中只有一个line)剔除
Conflict Misses
这种发生在数组长度是S的整数倍(由于 S = 2 s S=2^s S=2s,这时数组长度也是2的指数倍)
float dotprod(float x[8],float y[8]){
float sum=0.0;
int i;
for(i=0;i<8;i++){
sum+=x[i]+y[i];
}
return sum;
}
可以预想到x[0]和x[1]在同一个set,但是他们和y[0]y[1]对应的set是同一个,所以在访问y[0]时就把x[1]从cache中换出,一种解决方案是把x的长度设置成12.
Set Associative Caches
1 < E < C / B 1 \lt E \lt C/B 1<E<C/B
步骤
- Set Selection
- Line Matching
这个时候就要逐行比较tag - Line Replacement
如果没有其他硬件支持,那么只能选用Random的策略,否者还有LRU,LFU等方案
Fully Associative Caches
E = C / B E=C/B E=C/B
在这种情况下不再需要Set index,所以也就不再需要Set Selection这一步了,而对于Line Matching这一步由于要全量搜索,所以要么执行并行策略,要么只能限制cache的大小
write
下面有各种方案,并且具体是怎么实现的也缺少文档,在这种情况下书中建议按write-back & write-allocate来处理
write hit
write-through的方案是在写cache的同时也写下一级(Main Memory),这样的话Bus的压力会比较大,性能差.
write-back是在最后才将cache写到下一级,这样有更好的locality但是需要一个dirty bit
write miss
write-allocate会将下一级数据存入cache,一般配合write-back使用(这里的假设是强locality)
no-write-allocate则忽略缓存只更新下一级,一般配合write-through使用
Anatomy of a real cache hierarchy
a cache that holds instructions only is called an i-cache
a cache that holds program data only is called a d-cache
a cache that holds both instructions and data is known as a unified cache
上面的图是Intel的CPU缓存示意,L1分为i-cache和d-cache,这样的好处是可以分别优化(可以设置不同的方案和不同的block size等参数),另外i-cache一般是只读的.至于L2则未作区分.前面两级是每个核独用,到了L3就是一个CPU里面的多核共享了.
performance impact of cache parameters
| S | B | E | |
|---|---|---|---|
| hit rate | increate | spatial locality | decrease thrash |
| hit time | slow | ||
| miss rate | |||
| miss penalty | negative | complex to choose a victim | |
| cost | more tag data | ||
| result | L1小 | 32-64 bytes | 8way for L1/L2,16way for L3 |
基本上看来hit rate vs (hit time & miss penalty)这是一组矛盾,增加就会导致hit rate上升,这是好的,但是也会导致后面两个时间上升,因为有更复杂的查找和更多数据复制.另外文中对write strategy也做了比较,偏爱write-back
Write Cache-friendly Code
The Impact of Caches on Program Performance
memory mountain
文中使用了下面的代码来构建memory mountain
double data[MAXELEMS];/* The globe array we will be traversing */
/*
* test-Iterate over first "elems" elements of array "data"
* with stride of "stride".
*/
void test(int eles,int stride){/* the test function*/
int i;
double result=0.0;
volatile double sink;
for(i=0;i<elems;i+=stride){
result+=data[i];
}
sink=result;/*so compiler does not optimize away the loop*/
}
/*
*run-Run test(elems,stride) and return read throughtput(MB/s).
* "size" is in bytes,"stride" is in array elements,
* and Mhz is CPU clock frequency in Mhz.
*/
double run(int size,int stride,double Mhz){
double cycles;
int elems=size/sizeof(double);
test(elems,stride); /* warm up the cache */
cycles=fryc2(test,elems,stride,0); /* call test(elems,stride) */
return (size/stride)/(cycles/Mhz); /* convert cycles to MB/s */
}
然后会得到那张著名的图.图相对于单个指标更加明确的说明在不同情况下的不同表现,从而让成需要可以对于具体的情况做出更加具体的优化.
rearranging loops to increase spatial locality
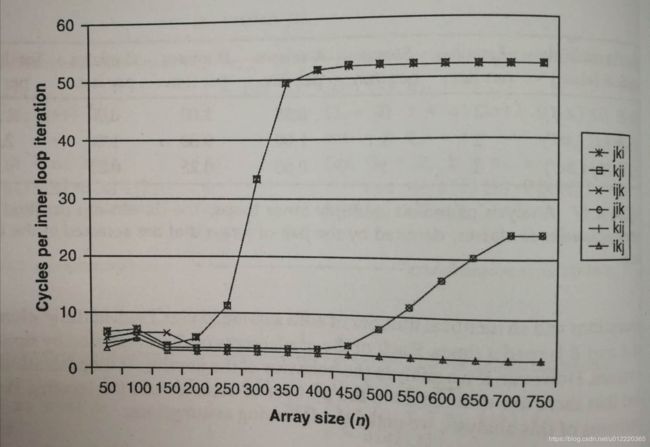
guideline
- forcus your attention on the inner loops,where the bulk of the computations and memory accesses occur.
- try to maximize the spatial locality in your programs by reading data objects sequentially,with stride 1,in the order they are stored in memory.
- try to maximize the temporal locality in your programs by using a data object as often as possible once it has been read from memory.