神经网络初始化常用方法
Xavier初始化方法
https://blog.csdn.net/shuzfan/article/details/51338178
“Xavier”初始化方法是一种很有效的神经网络初始化方法,方法来源于2010年的一篇论文《Understanding the difficulty of training deep feedforward neural networks》,可惜直到近两年,这个方法才逐渐得到更多人的应用和认可。
这里先介绍一个方差相乘的公式,以便理解Xavier:

为了使得网络中信息更好的流动,每一层输出的方差应该尽量相等。
基于这个目标,现在我们就去推导一下:每一层的权重应该满足哪种条件。
文章先假设的是线性激活函数,而且满足0点处导数为1,即 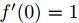
现在我们先来分析一层卷积: 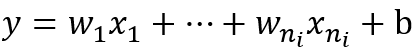
其中ni表示输入个数。
根据概率统计知识我们有下面的方差公式: 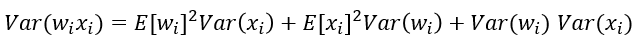
特别的,当我们假设输入和权重都是0均值时(目前有了BN之后,这一点也较容易满足),上式可以简化为: 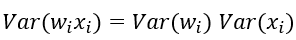
进一步假设输入x和权重w独立同分布,则有: 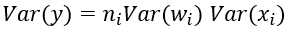
于是,为了保证输入与输出方差一致,则应该有: 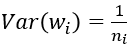
对于一个多层的网络,某一层的方差可以用累积的形式表达: 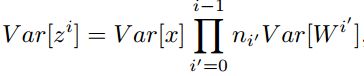
特别的,反向传播计算梯度时同样具有类似的形式: 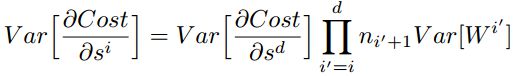
综上,为了保证前向传播和反向传播时每一层的方差一致,应满足:
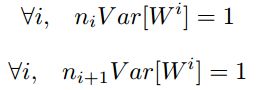
但是,实际当中输入与输出的个数往往不相等,于是为了均衡考量,最终我们的权重方差应满足:
——————————————————————————————————————— 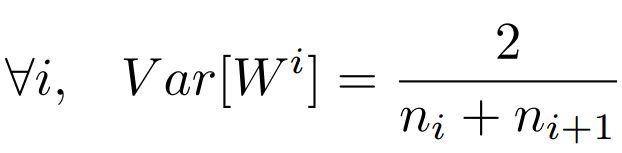
———————————————————————————————————————
学过概率统计的都知道 [a,b] 间的均匀分布的方差为: 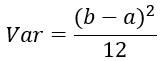
因此,Xavier初始化的实现就是下面的均匀分布:
—————————————————————————————————————————— 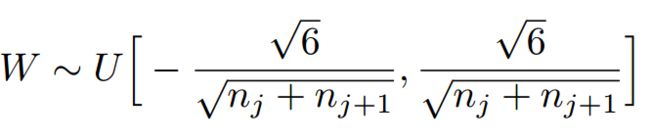
———————————————————————————————————————————
下面,我们来看一下caffe中具体是怎样实现的,代码位于include/caffe/filler.hpp文件中。
template
class XavierFiller : public Filler {
public:
explicit XavierFiller(const FillerParameter& param)
: Filler(param) {}
virtual void Fill(Blob* blob) {
CHECK(blob->count());
int fan_in = blob->count() / blob->num();
int fan_out = blob->count() / blob->channels();
Dtype n = fan_in; // default to fan_in
if (this->filler_param_.variance_norm() ==
FillerParameter_VarianceNorm_AVERAGE) {
n = (fan_in + fan_out) / Dtype(2);
} else if (this->filler_param_.variance_norm() ==
FillerParameter_VarianceNorm_FAN_OUT) {
n = fan_out;
}
Dtype scale = sqrt(Dtype(3) / n);
caffe_rng_uniform(blob->count(), -scale, scale,
blob->mutable_cpu_data());
CHECK_EQ(this->filler_param_.sparse(), -1)
<< "Sparsity not supported by this Filler.";
}
}; 由上面可以看出,caffe的Xavier实现有三种选择
(1) 默认情况,方差只考虑输入个数: 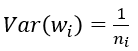
(2) FillerParameter_VarianceNorm_FAN_OUT,方差只考虑输出个数: 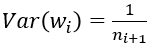
(3) FillerParameter_VarianceNorm_AVERAGE,方差同时考虑输入和输出个数: 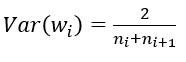
之所以默认只考虑输入,我个人觉得是因为前向信息的传播更重要一些
MSRA初始化方法
本次简单介绍一下MSRA初始化方法,方法同样来自于何凯明paper 《Delving Deep into Rectifiers:Surpassing Human-Level Performance on ImageNet Classification》.
He/MSRA et al. initialization tends to work better forthe VGG family of networks
-
- Motivation
- MSRA初始化
- 推导证明
- 补充说明
Motivation
网络初始化是一件很重要的事情。但是,传统的固定方差的高斯分布初始化,在网络变深的时候使得模型很难收敛。此外,VGG团队是这样处理初始化的问题的:他们首先训练了一个8层的网络,然后用这个网络再去初始化更深的网络。
“Xavier”是一种相对不错的初始化方法,我在我的另一篇博文“深度学习——Xavier初始化方法”中有介绍。但是,Xavier推导的时候假设激活函数是线性的,显然我们目前常用的ReLU和PReLU并不满足这一条件。
MSRA初始化
只考虑输入个数时,MSRA初始化是一个均值为0方差为2/n的高斯分布:
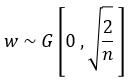
推导证明
推导过程与Xavier类似。
首先,用下式表示第L层卷积:
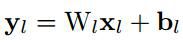
则其方差为:(假设x和w独立,且各自的每一个元素都同分布,即下式中的n_l表示输入元素个数,x_l和w_l都表示单个元素)
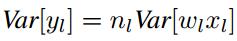
当权重W满足0均值时,上述方差可以进一步写为:
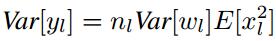
对于ReLU激活函数,我们有:(其中f是激活函数)
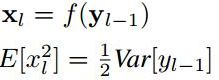
带入之前的方差公式则有:
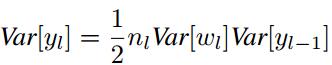
由上式易知,为了使每一层数据的方差保持一致,则权重应满足:
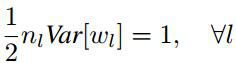
补充说明
(1) 对于第一层数据,由于其之前没有经过ReLU,因此理论上这一层的初始化方差应为1/n。但是,因为只有一层,系数差一点影响不大,因此为了简化操作整体都采用2/n的方差;
(2) 反向传播需要考虑的情况完全类似于“Xavier”。对于反向传播,可以同样进行上面的推导,最后的结论依然是方差应为2/n,只不过因为是反向,这里的n不再是输入个数,而是输出个数。文章中说,这两种方法都可以帮助模型收敛。
(3) 对于PReLU激活函数来说,条件变成了:
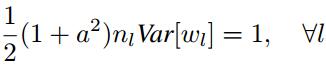
因此初始化和PReLU有关,但是目前caffe的代码并不在支持在MSRA初始化时手动指定a的值。
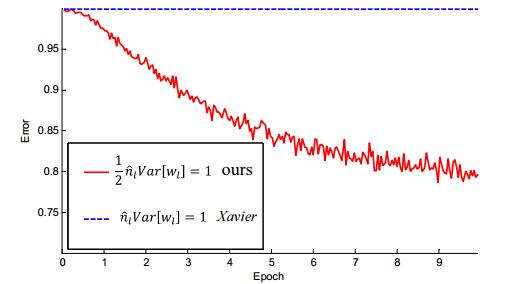
(4) 文章做了一些对比试验,表明在网络加深后,MSRA初始化明显优于Xavier初始化。
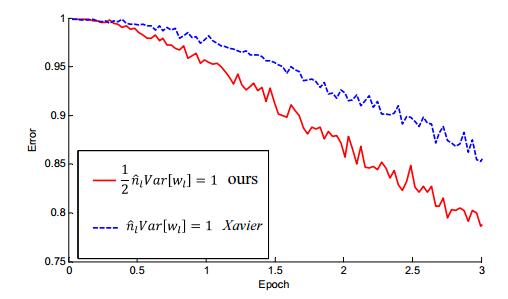
特别当网络增加到33层之后,对比效果更加明显