R机器学习算法系列——人工神经网络
人工神经网络(ANN)
神经网络基本结构
人工神经网络由神经元模型构成,这种由许多神经元组成的信息处理网络具有并行分布结构。每个神经元具有单一输出,并且能够与其它神经元连接;存在许多(多重)输出连接方法,每种连接方法对应一个连接权系数。可把 ANN 看成是以处理单元 PE(processing element) 为节点,用加权有向弧(链)相互连接而成的有向图。令来自其它处理单元(神经元)i的信息为Xi,它们与本处理单元的互相作用强度为 Wi,i=0,1,…,n-1,处理单元的内部阈值为 θ。那么本神经元的输入为:
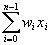
而处理单元的输出为:
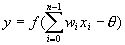
式中,xi为第 i 个元素的输入,wi 为第 i 个元素与本处理单元的互联权重。f 称为激发函数(activation function)或作用函数。它决定节点(神经元)的输出。该输出为 1 或 0 取决于其输入之和大于或小于内部阈值 θ。
下图所示神经元单元由多个输入Xi,i=1,2,...,n和一个输出y组成。中间状态由输入信号的权和表示,而输出为:
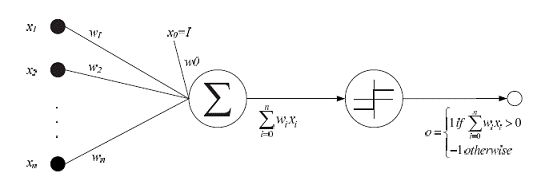
训练网络
神经网络结构被设计完成,有了输入、输出参数后,我们就要对网络进行训练。神经网络的训练有包括感知器训练、delta 规则训练和反向传播算法等训练,其中感知器训练是基础。
感知器和 delta 训练规则
理解神经网络的第一步是从对抽象生物神经开始,本文用到的人工神经网络系统是以被称为感知器的单元为基础,如图所示。感知器以一个实数值向量作为输入,计算这些输入的线性组合,如果结果大于某个阈值,就输出 1,否则输出 -1,如果 x 从 1 到 n,则感知器计算公式如下:
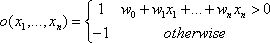
其中每个 wi 是一个实数常量,或叫做权值,用来决定输入 xi 对感知器输出的贡献率。特别地,-w0是阈值。
尽管当训练样例线性可分时,感知器法则可以成功地找到一个权向量,但如果样例不是线性可分时它将不能收敛,因此人们设计了另一个训练法则来克服这个不足,这个训练规则叫做 delta 规则。感知器训练规则是基于这样一种思路--权系数的调整是由目标和输出的差分方程表达式决定。而 delta 规则是基于梯度降落这样一种思路。这个复杂的数学概念可以举个简单的例子来表示。从给定的几点来看,向南的那条路径比向东那条更陡些。向东就像从悬崖上掉下来,但是向南就是沿着一个略微倾斜的斜坡下来,向西象登一座陡峭的山,而北边则到了平地,只要慢慢的闲逛就可以了。所以您要寻找的是到达平地的所有路径中将陡峭的总和减少到最小的路径。在权系数的调整中,神经网络将会找到一种将误差减少到最小的权系数的分配方式。这部分我们不做详细介绍,如有需要大家可参考相关的人工智能书籍。
反向传播算法
人工神经网络学习为学习实数值和向量值函数提供了一种实际的方法,对于连续的和离散的属性都可以使用。并且对训练数据中的噪声具有很好的健壮性。反向传播算法是最常见的网络学习算法。这是我们所知用来训练神经网络很普遍的方法,反向传播算法是一种具有很强学习能力的系统,结构比较简单,且易于编程。
鲁梅尔哈特(Rumelhart)和麦克莱兰(Meclelland)于 1985 年发展了 BP 网络学习算法,实现了明斯基的多层网络设想。BP网络不仅含有输入节点和输出节点,而且含有一层或多层隐(层)节点。输入信号先向前传递到隐藏节点,经过作用后,再把隐藏节点的输出信息传递到输出节点,最后给出输出结果。节点的激发函数一般选用 S 型函数。
反向传播(back-propagation,BP)算法是一种计算单个权值变化引起网络性能变化值的较为简单的方法。由于BP算法过程包含从输出节点开始,反向地向第一隐含层(即最接近输入层的隐含层)传播由总误差引起的权值修正,所以称为"反向传播"。反向传播特性与所求解问题的性质和所作细节选择有极为密切的关系。
对于由一系列确定的单元互连形成的多层网络,反向传播算法可用来学习这个多层网络的权值。它采用梯度下降方法试图最小化网络输出值和目标值之间的误差平方,因为我们要考虑多个输出单元的网络,而不是像以前只考虑单个单元,所以我们要重新计算误差E,以便对所有网络输出的误差求和:
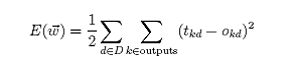
Outpus 是网络输出单元的集合,tkd 和 okd 是与训练样例 d 和第 k 个输出单元的相关输出值.
反向传播算法的一个迷人特性是:它能够在网络内部的隐藏层发现有用的中间表示:
1.训练样例仅包含网络输入和输出,权值调节的过程可以自由地设置权值,来定义任何隐藏单元表示,这些隐藏单元表示在使误差E达到最小时最有效。
2.引导反向传播算法定义新的隐藏层特征,这些特征在输入中没有明确表示出来,但能捕捉输入实例中与学习目标函数最相关的特征
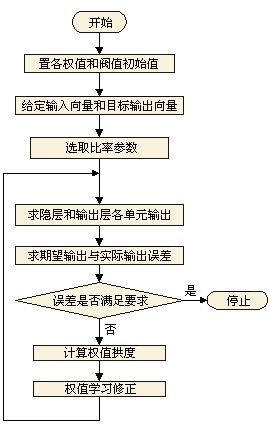
反向传播训练神经元的算法如下:
摘自:http://www.cnblogs.com/luxiaoxun/archive/2012/12/10/2811309.html
----R实现----
# 导入数据
concrete <- read.csv("concrete.csv")
str(concrete)
## 'data.frame': 1030 obs. of 9 variables:
## $ cement : num 141 169 250 266 155 ...
## $ slag : num 212 42.2 0 114 183.4 ...
## $ ash : num 0 124.3 95.7 0 0 ...
## $ water : num 204 158 187 228 193 ...
## $ superplastic: num 0 10.8 5.5 0 9.1 0 0 6.4 0 9 ...
## $ coarseagg : num 972 1081 957 932 1047 ...
## $ fineagg : num 748 796 861 670 697 ...
## $ age : int 28 14 28 28 28 90 7 56 28 28 ...
## $ strength : num 29.9 23.5 29.2 45.9 18.3 ...
# custom normalization function
normalize <- function(x) {
return((x - min(x)) / (max(x) - min(x)))
}
# 规范化数据
concrete_norm <- as.data.frame(lapply(concrete, normalize))
# confirm that the range is now between zero and one
summary(concrete_norm$strength)
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 0.0000 0.2664 0.4001 0.4172 0.5457 1.0000
# compared to the original minimum and maximum
summary(concrete$strength)
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 2.33 23.71 34.44 35.82 46.14 82.60
# 创建测试数据和训练数据
concrete_train <- concrete_norm[1:773, ]
concrete_test <- concrete_norm[774:1030, ]
## Step 3: Training a model on the data ----
# 训练数据集
library(neuralnet)
## Warning: package 'neuralnet' was built under R version 3.3.3
# simple ANN with only a single hidden neuron
set.seed(12345) # to guarantee repeatable results
concrete_model <- neuralnet(formula = strength ~ cement + slag +
ash + water + superplastic +
coarseagg + fineagg + age,
data = concrete_train)
# 显示神经网络
plot(concrete_model)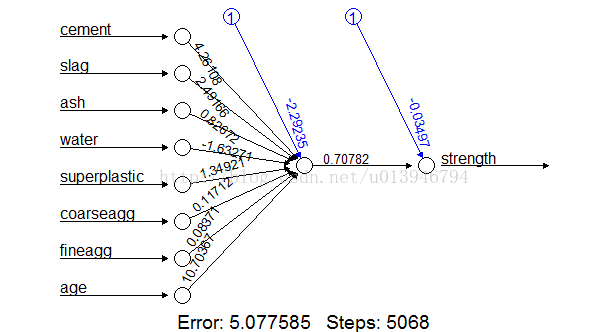
# concrete_model
## Step 4: Evaluating model performance ----
# obtain model results
model_results <- compute(concrete_model, concrete_test[1:8])
# obtain predicted strength values
predicted_strength <- model_results$net.result
# 监测预测值与实际值之间的相关性
cor(predicted_strength, concrete_test$strength)
## [,1]
## [1,] 0.8064655576
## Step 5: Improving model performance ----
# a more complex neural network topology with 5 hidden neurons
set.seed(12345) # to guarantee repeatable results
concrete_model2 <- neuralnet(strength ~ cement + slag +
ash + water + superplastic +
coarseagg + fineagg + age,
data = concrete_train, hidden = 5)
# plot the network
plot(concrete_model2) 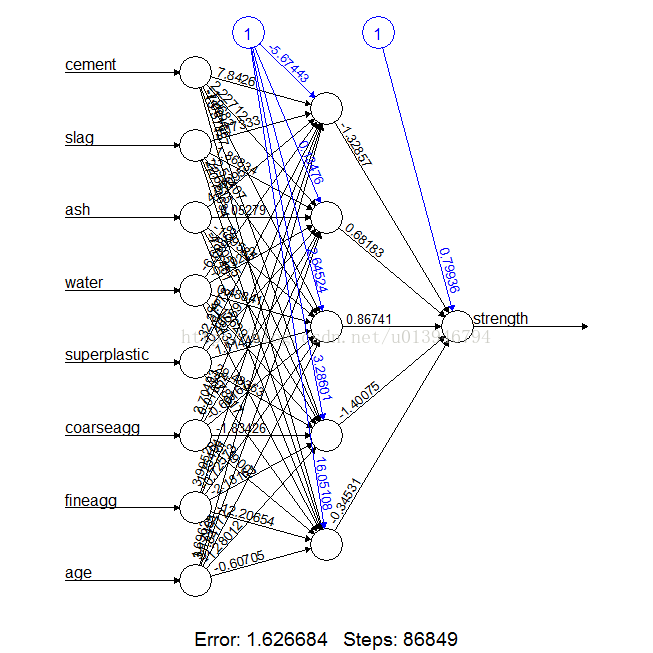
# evaluate the results as we did before
model_results2 <- compute(concrete_model2, concrete_test[1:8])
predicted_strength2 <- model_results2$net.result
cor(predicted_strength2, concrete_test$strength)
## [,1]
## [1,] 0.9244533426
备注:neuralnet(formula, data, hidden = 1, threshold = 0.01,
stepmax = 1e+05, rep = 1, startweights = NULL,
learningrate.limit = NULL,
learningrate.factor = list(minus = 0.5, plus = 1.2),
learningrate=NULL, lifesign = "none",
lifesign.step = 1000, algorithm = "rprop+",
err.fct = "sse", act.fct = "logistic",
linear.output = TRUE, exclude = NULL,
constant.weights = NULL, likelihood = FALSE)
解释:
formula:模型的公式表达形式,类似于y~x1+x2+x3
data:指定要分析的数据对象
weights:代表各类样本在模型中所占比重,默认将各类样本按原始比重建立模型
subset:可提取目标数据集的子集作为模型的训练样本
na.action:处理缺失值的方法,默认忽略缺失值
x:为输入的自变量矩阵或数据框
y:为输入的因变量,但必须经过class.ind()函数的预处理
size:指定隐藏层节点个数,通常为输入变量个数的1.2至1.5倍
Wts:设置初始的权重,默认情况将随机产生权重值
mask:指定哪个参数需要最优化,默认全部参数都需要最优化
linout:指定线性输出还是Logistic输出,默认为Logistic输出
rang:设置初始权重值的范围[-rang,rang]
decay:指模型建立过程中,模型权重值的衰减精度,默认为0
maxit:指定模型的最大迭代次数