Santander Customer Transaction Prediction(2)
https://www.kaggle.com/c/santander-customer-transaction-prediction/leaderboard
import pandas as pd
import matplotlib.pyplot as plt
# 初始化spark
def spark_init(master = "yarn",appName="test"):
from pyspark.sql import SparkSession
from pyspark.sql import types
spark = SparkSession.builder.master(master).appName(appName).getOrCreate()
return spark
# 将单个数据源转成dataframe
def get_input_data(path, header=True, inferSchema=True, schema=None, sep=',',encoding='UTF-8'):
df = spark.read.csv(path, header=header, inferSchema=inferSchema, schema=schema,sep=sep,encoding=encoding)
return df
# 将处理过后的数据源持久化到hdfs
def output_data(df, location, size=1, format="csv", mode="overwrite", header=False, delimiter=','):
df.repartition(size).write.save(location, format=format, header=header, delimiter=delimiter,
mode=mode)
return location
# 数据源描述
# 数据探索
#数据统计性描述
def data_describe(df):
import json
des = df.describe().toPandas()
return json.dumps(des.to_dict(), ensure_ascii=False)
# 两个变量因子的相关性描速
def data_single_corr(df,col1,col2):
return df.corr(col1, col1)
# 所有数值类型的变量因子的相关性
def data_all_corr(df):
import json
import pandas as pd
numerical = [t[0] for t in df.dtypes if t[1] == 'int']
n_numerical = len(numerical)
corr = []
for i in range(0, n_numerical):
temp = [None] * i
for j in range(i, n_numerical):
temp.append(df.corr(numerical[i], numerical[j]))
corr.append(temp)
df01 = pd.DataFrame(corr,columns=numerical)
return json.dumps(df01.to_dict(), ensure_ascii=False)
# 预处理-抽样
def sample(df,withReplacement=False, fraction=0.5, seed=None):
sample1 = df.sample(
withReplacement=withReplacement, # 无放回抽样
fraction=fraction,
seed=seed)
return sample1
# 字段筛选
def field_select(df, select_fields):
"""
字段筛选
:return:
"""
df = df.select(*select_fields)
return df
# 缺失值填充(暂时只提供均值填充)
def fill_mean(df,col):
from pyspark.sql.functions import mean
mean_val = df.select(mean(df[col])).collect()
mean_sales = mean_val[0][0] # to show the number
return df.na.fill(mean_sales,[col])
# 字符串类别特征onehot的处理
def deal_categoricalCol(categoricalColumns):
satge = []
new_cols = []
for categoricalCol in categoricalColumns:
stringIndexer = StringIndexer(inputCol=categoricalCol, outputCol=categoricalCol + 'Index')
# encoder = OneHotEncoderEstimator(inputCols=[stringIndexer.getOutputCol()], outputCols=[categoricalCol + "classVec"])
outputCol = categoricalCol + "classVec"
encoder = OneHotEncoder(inputCol=stringIndexer.getOutputCol(), outputCol=outputCol)
satge += [stringIndexer, encoder]
new_cols.append(outputCol)
return satge,new_cols
# fit pipeline
def fit_pipeline(train, stages):
cols = train.columns
from pyspark.ml import Pipeline
pipeline = Pipeline(stages=stages)
# 适配pipeline
pipelineModel = pipeline.fit(train)
return pipelineModel
# 保存模型
def save_model(pipelineModel,path):
"""
:type pipelineModel Pipeline
:param pipelineModel:
:return:
"""
pipelineModel.save(path)
return path
# 模型预测
def model_pre(test,input_path,output_path,size=1, format="csv", mode="overwrite", header=False, delimiter=','):
"""
:type return Pipeline
:return
"""
from pyspark.ml import PipelineModel
pipeModel = PipelineModel.load(path)
predictions = pipeModel.transform(test)
predictions.repartition(size).write.save(output_path, format=format, header=header, delimiter=delimiter,
mode=mode)
predictions.show()
In [2]:
spark = spark_init(master='local[*]',appName='sant_demo01') base_path = "F:\\001experience\\MatchSummary\\resources\\sant\\" spark
Out[2]:
SparkSession - in-memory
SparkContext
Spark UI
Version
v2.2.0
Master
local[*]
AppName
sant_demo01
数据探索
- 查看数据分布情况
- 区分连续变量和离散变量
- 相关性分析
- Hypothesis testing
- 可视化展示
- 统计分析
- 问题理解
- 异常数据原因分析
- 空数据原因分析
- 错误数据分析
在Santander,我们的使命是帮助人们和企业繁荣发展。 我们一直在寻找方法来帮助客户了解他们的财务状况,并确定哪些产品和服务可以帮助他们实现货币目标。
我们的数据科学团队不断挑战我们的机器学习算法,与全球数据科学界合作,确保我们能够更准确地识别解决我们最常见挑战的新方法,二元分类问题,例如:客户是否满意? 客户会购买此产品吗? 客户可以支付这笔贷款吗?
在此挑战中,我们邀请Kagglers帮助我们确定哪些客户将来会进行特定交易,无论交易金额多少。 为此次竞赛提供的数据与我们可用于解决此问题的实际数据具有相同的结构。
In [3]:
df_train = get_input_data(base_path + 'train.csv') pd.DataFrame(df_train.take(10), columns=df_train.columns).transpose()
Out[3]:
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | |
|---|---|---|---|---|---|---|---|---|---|---|
| ID_code | train_0 | train_1 | train_2 | train_3 | train_4 | train_5 | train_6 | train_7 | train_8 | train_9 |
| target | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| var_0 | 8.9255 | 11.5006 | 8.6093 | 11.0604 | 9.8369 | 11.4763 | 11.8091 | 13.558 | 16.1071 | 12.5088 |
| var_1 | -6.7863 | -4.1473 | -2.7457 | -2.1518 | -1.4834 | -2.3182 | -0.0832 | -7.9881 | 2.4426 | 1.9743 |
| var_2 | 11.9081 | 13.8588 | 12.0805 | 8.9522 | 12.8746 | 12.608 | 9.3494 | 13.8776 | 13.9307 | 8.896 |
| var_3 | 5.093 | 5.389 | 7.8928 | 7.1957 | 6.6375 | 8.6264 | 4.2916 | 7.5985 | 5.6327 | 5.4508 |
| var_4 | 11.4607 | 12.3622 | 10.5825 | 12.5846 | 12.2772 | 10.9621 | 11.1355 | 8.6543 | 8.8014 | 13.6043 |
| var_5 | -9.2834 | 7.0433 | -9.0837 | -1.8361 | 2.4486 | 3.5609 | -8.0198 | 0.831 | 6.163 | -16.2859 |
| var_6 | 5.1187 | 5.6208 | 6.9427 | 5.8428 | 5.9405 | 4.5322 | 6.1961 | 5.689 | 4.4514 | 6.0637 |
| var_7 | 18.6266 | 16.5338 | 14.6155 | 14.925 | 19.2514 | 15.2255 | 12.0771 | 22.3262 | 10.1854 | 16.841 |
| var_8 | -4.92 | 3.1468 | -4.9193 | -5.8609 | 6.2654 | 3.5855 | -4.3781 | 5.0647 | -3.1882 | 0.1287 |
| var_9 | 5.747 | 8.0851 | 5.9525 | 8.245 | 7.6784 | 5.979 | 7.9232 | 7.1971 | 9.0827 | 7.9682 |
| var_10 | 2.9252 | -0.4032 | -0.3249 | 2.3061 | -9.4458 | 0.801 | -5.1288 | 1.4532 | 0.9501 | 0.8787 |
| var_11 | 3.1821 | 8.0585 | -11.2648 | 2.8102 | -12.1419 | -0.6192 | -7.5271 | -6.7033 | 1.7982 | 3.0537 |
| var_12 | 14.0137 | 14.0239 | 14.1929 | 13.8463 | 13.8481 | 13.638 | 14.1629 | 14.2919 | 14.0654 | 13.9639 |
| var_13 | 0.5745 | 8.4135 | 7.3124 | 11.9704 | 7.8895 | 1.2589 | 13.3058 | 10.9699 | -3.0572 | 0.8071 |
| var_14 | 8.7989 | 5.4345 | 7.5244 | 6.4569 | 7.7894 | 8.1939 | 7.8412 | 6.919 | 11.1642 | 9.924 |
| var_15 | 14.5691 | 13.7003 | 14.6472 | 14.8372 | 15.0553 | 14.9894 | 14.3363 | 14.2459 | 14.8757 | 15.2659 |
| var_16 | 5.7487 | 13.8275 | 7.6782 | 10.743 | 8.4871 | 12.0763 | 7.5951 | 9.5376 | 10.0075 | 11.39 |
| var_17 | -7.2393 | -15.5849 | -1.7395 | -0.4299 | -3.068 | -1.471 | 11.0922 | -0.7226 | -8.9472 | 1.5367 |
| var_18 | 4.284 | 7.8 | 4.7011 | 15.9426 | 6.5263 | 6.7341 | 21.1976 | 5.1548 | 3.8349 | 5.4649 |
| var_19 | 30.7133 | 28.5708 | 20.4775 | 13.7257 | 11.3152 | 14.8241 | 6.2946 | 17.1535 | 0.856 | 13.6196 |
| var_20 | 10.535 | 3.4287 | 17.7559 | 20.301 | 21.4246 | 19.7172 | 15.8877 | 13.7326 | 10.6958 | 23.7806 |
| var_21 | 16.2191 | 2.7407 | 18.1377 | 12.5579 | 18.9608 | 11.9882 | 24.2595 | 14.4195 | 6.3738 | 4.4221 |
| var_22 | 2.5791 | 8.5524 | 1.2145 | 6.8202 | 10.1102 | 1.0468 | 8.1159 | 1.2375 | 6.558 | 6.1695 |
| var_23 | 2.4716 | 3.3716 | 3.5137 | 2.7229 | 2.7142 | 3.8663 | 3.9769 | 3.1711 | 2.6182 | 3.2978 |
| var_24 | 14.3831 | 6.9779 | 5.6777 | 12.1354 | 14.208 | 4.7252 | 7.6851 | 9.1258 | 13.2506 | 4.5923 |
| var_25 | 13.4325 | 13.891 | 13.2177 | 13.7367 | 13.5433 | 13.9427 | 13.36 | 13.325 | 13.7929 | 13.3778 |
| var_26 | -5.1488 | -11.7684 | -7.994 | 0.8135 | 3.1736 | -1.2796 | -0.5156 | 3.3883 | -14.4918 | -3.22 |
| var_27 | -0.4073 | -2.5586 | -2.9029 | -0.9059 | -3.3423 | -4.3763 | 0.069 | -0.4418 | -2.5407 | -2.3302 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| var_170 | -4.7645 | 5.5378 | -7.0927 | -7.1541 | 1.4493 | -6.1449 | 0.2619 | 8.9519 | 3.1838 | -3.0868 |
| var_171 | -8.4254 | 5.0988 | -3.9116 | -6.192 | -2.6627 | -2.0285 | -1.1405 | -2.3522 | -1.7865 | -1.2558 |
| var_172 | 20.8773 | 22.033 | 7.2569 | 18.2366 | 19.8056 | 18.4106 | 25.1675 | 6.1335 | 4.9105 | 24.2683 |
| var_173 | 3.1531 | 5.5134 | -5.8234 | 11.7134 | 2.3705 | 1.4457 | 2.6965 | 0.0876 | 3.5803 | -4.5382 |
| var_174 | 18.5618 | 30.2645 | 25.682 | 14.7483 | 18.4685 | 21.8853 | 17.0152 | 19.5642 | 32.9149 | 18.2209 |
| var_175 | 7.7423 | 10.4968 | 10.9202 | 8.1013 | 16.3309 | 9.2654 | 12.7942 | 13.2008 | 13.0201 | 7.5652 |
| var_176 | -10.1245 | -7.2352 | -0.3104 | 11.8771 | -3.3456 | -6.5247 | -3.0403 | -11.1786 | -2.4845 | 6.3377 |
| var_177 | 13.7241 | 16.5721 | 8.8438 | 13.9552 | 13.5261 | 10.7687 | 8.1735 | 17.3041 | 11.0988 | 14.6223 |
| var_178 | -3.5189 | -7.3477 | -9.7009 | -10.4701 | 1.7189 | -7.6283 | 4.5637 | -0.6535 | 7.4609 | -13.896 |
| var_179 | 1.7202 | 11.0752 | 2.4013 | 5.6961 | 5.1743 | 1.0208 | 3.8973 | 0.0592 | -2.1408 | 2.391 |
| var_180 | -8.4051 | -5.5937 | -4.2935 | -3.7546 | -7.6938 | 7.1968 | -8.1416 | 5.114 | -3.9172 | 2.7878 |
| var_181 | 9.0164 | 9.4878 | 9.3908 | 8.4117 | 9.7685 | 11.1227 | 10.057 | 10.5478 | 7.7291 | 11.3457 |
| var_182 | 3.0657 | -14.91 | -13.2648 | 1.8986 | 4.891 | 2.2257 | 15.7862 | 6.9736 | -11.4027 | -9.6774 |
| var_183 | 14.3691 | 9.4245 | 3.1545 | 7.2601 | 12.2198 | 6.4056 | 3.3593 | 6.9724 | 2.0696 | 10.3382 |
| var_184 | 25.8398 | 22.5441 | 23.0866 | -0.4639 | 11.8503 | 21.055 | 11.914 | 24.0369 | -1.7937 | 19.0645 |
| var_185 | 5.8764 | -4.8622 | -5.3 | -0.0498 | -7.8931 | -13.6509 | -4.287 | -4.822 | -0.003 | -7.6785 |
| var_186 | 11.8411 | 7.6543 | 5.3745 | 7.9336 | 6.4209 | 4.7691 | 7.5015 | 8.4947 | 11.5024 | 6.758 |
| var_187 | -19.7159 | -15.9319 | -6.266 | -12.8279 | 5.927 | -8.9114 | -29.9763 | -5.9076 | -18.3172 | -21.607 |
| var_188 | 17.5743 | 13.3175 | 10.1934 | 12.4124 | 16.0201 | 15.1007 | 17.2867 | 18.8663 | 13.1403 | 20.8112 |
| var_189 | 0.5857 | -0.3566 | -0.8417 | 1.8489 | -0.2829 | 2.4286 | 1.8539 | 1.9731 | 0.7014 | -0.1873 |
| var_190 | 4.4354 | 7.6421 | 2.9057 | 4.4666 | -1.4905 | -6.3068 | 8.783 | 13.17 | 1.4298 | 0.5543 |
| var_191 | 3.9642 | 7.7214 | 9.7905 | 4.7433 | 9.5214 | 6.6025 | 6.4521 | 6.5491 | 14.751 | 6.316 |
| var_192 | 3.1364 | 2.5837 | 1.6704 | 0.7178 | -0.1508 | 5.2912 | 3.5325 | 3.9906 | 1.6395 | 1.0371 |
| var_193 | 1.691 | 10.9516 | 1.6858 | 1.4214 | 9.1942 | 0.4403 | 0.1777 | 5.8061 | 1.4181 | 3.6885 |
| var_194 | 18.5227 | 15.4305 | 21.6042 | 23.0347 | 13.2876 | 14.9452 | 18.3314 | 23.1407 | 14.837 | 14.8344 |
| var_195 | -2.3978 | 2.0339 | 3.1417 | -1.2706 | -1.5121 | 1.0314 | 0.5845 | -0.3776 | -1.994 | 0.4467 |
| var_196 | 7.8784 | 8.1267 | -6.5213 | -2.9275 | 3.9267 | -3.6241 | 9.1104 | 4.2178 | -1.0733 | 14.1287 |
| var_197 | 8.5635 | 8.7889 | 8.2675 | 10.2922 | 9.5031 | 9.767 | 9.1143 | 9.4237 | 8.1975 | 7.9133 |
| var_198 | 12.7803 | 18.356 | 14.7222 | 17.9697 | 17.9974 | 12.5809 | 10.8869 | 8.6624 | 19.5114 | 16.2375 |
| var_199 | -1.0914 | 1.9518 | 0.3965 | -8.9996 | -8.8104 | -4.7602 | -3.2097 | 3.4806 | 4.8453 | 14.2514 |
202 rows × 10 columns
In [20]:
df_des = df_train.toPandas().describe(include = 'all') # df_des.transpose() df_des
Out[20]:
| ID_code | target | var_0 | var_1 | var_2 | var_3 | var_4 | var_5 | var_6 | var_7 | ... | var_190 | var_191 | var_192 | var_193 | var_194 | var_195 | var_196 | var_197 | var_198 | var_199 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 200000 | 200000.000000 | 200000.000000 | 200000.000000 | 200000.000000 | 200000.000000 | 200000.000000 | 200000.000000 | 200000.000000 | 200000.000000 | ... | 200000.000000 | 200000.000000 | 200000.000000 | 200000.000000 | 200000.000000 | 200000.000000 | 200000.000000 | 200000.000000 | 200000.000000 | 200000.000000 |
| unique | 200000 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| top | train_46809 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| freq | 1 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| mean | NaN | 0.100490 | 10.679914 | -1.627622 | 10.715192 | 6.796529 | 11.078333 | -5.065317 | 5.408949 | 16.545850 | ... | 3.234440 | 7.438408 | 1.927839 | 3.331774 | 17.993784 | -0.142088 | 2.303335 | 8.908158 | 15.870720 | -3.326537 |
| std | NaN | 0.300653 | 3.040051 | 4.050044 | 2.640894 | 2.043319 | 1.623150 | 7.863267 | 0.866607 | 3.418076 | ... | 4.559922 | 3.023272 | 1.478423 | 3.992030 | 3.135162 | 1.429372 | 5.454369 | 0.921625 | 3.010945 | 10.438015 |
| min | NaN | 0.000000 | 0.408400 | -15.043400 | 2.117100 | -0.040200 | 5.074800 | -32.562600 | 2.347300 | 5.349700 | ... | -14.093300 | -2.691700 | -3.814500 | -11.783400 | 8.694400 | -5.261000 | -14.209600 | 5.960600 | 6.299300 | -38.852800 |
| 25% | NaN | 0.000000 | 8.453850 | -4.740025 | 8.722475 | 5.254075 | 9.883175 | -11.200350 | 4.767700 | 13.943800 | ... | -0.058825 | 5.157400 | 0.889775 | 0.584600 | 15.629800 | -1.170700 | -1.946925 | 8.252800 | 13.829700 | -11.208475 |
| 50% | NaN | 0.000000 | 10.524750 | -1.608050 | 10.580000 | 6.825000 | 11.108250 | -4.833150 | 5.385100 | 16.456800 | ... | 3.203600 | 7.347750 | 1.901300 | 3.396350 | 17.957950 | -0.172700 | 2.408900 | 8.888200 | 15.934050 | -2.819550 |
| 75% | NaN | 0.000000 | 12.758200 | 1.358625 | 12.516700 | 8.324100 | 12.261125 | 0.924800 | 6.003000 | 19.102900 | ... | 6.406200 | 9.512525 | 2.949500 | 6.205800 | 20.396525 | 0.829600 | 6.556725 | 9.593300 | 18.064725 | 4.836800 |
| max | NaN | 1.000000 | 20.315000 | 10.376800 | 19.353000 | 13.188300 | 16.671400 | 17.251600 | 8.447700 | 27.691800 | ... | 18.440900 | 16.716500 | 8.402400 | 18.281800 | 27.928800 | 4.272900 | 18.321500 | 12.000400 | 26.079100 | 28.500700 |
11 rows × 202 columns
In [5]:
# df_des = df_des.transpose()
df_des = pd.read_csv("./describe.csv",index_col=False)
df_des['range'] = df_des['max']-df_des['min'] #极差
df_des['var'] = df_des['std']/df_des['mean'] #变异系数
df_des['dis'] = df_des['75%']-df_des['25%'] #四分位数间距
df_des.to_csv("./describe.csv")
df_des
Out[5]:
| Unnamed: 0 | Unnamed: 0.1 | IDcode | count | mean | std | min | 25% | 50% | 75% | max | range | var | dis | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | target | 200000.0 | 0.100490 | 0.300653 | 0.0000 | 0.000000 | 0.00000 | 0.000000 | 1.0000 | 1.0000 | 2.991870 | 0.000000 |
| 1 | 1 | 1 | var_0 | 200000.0 | 10.679914 | 3.040051 | 0.4084 | 8.453850 | 10.52475 | 12.758200 | 20.3150 | 19.9066 | 0.284651 | 4.304350 |
| 2 | 2 | 2 | var_1 | 200000.0 | -1.627622 | 4.050044 | -15.0434 | -4.740025 | -1.60805 | 1.358625 | 10.3768 | 25.4202 | -2.488320 | 6.098650 |
| 3 | 3 | 3 | var_2 | 200000.0 | 10.715192 | 2.640894 | 2.1171 | 8.722475 | 10.58000 | 12.516700 | 19.3530 | 17.2359 | 0.246463 | 3.794225 |
| 4 | 4 | 4 | var_3 | 200000.0 | 6.796529 | 2.043319 | -0.0402 | 5.254075 | 6.82500 | 8.324100 | 13.1883 | 13.2285 | 0.300642 | 3.070025 |
| 5 | 5 | 5 | var_4 | 200000.0 | 11.078333 | 1.623150 | 5.0748 | 9.883175 | 11.10825 | 12.261125 | 16.6714 | 11.5966 | 0.146516 | 2.377950 |
| 6 | 6 | 6 | var_5 | 200000.0 | -5.065317 | 7.863267 | -32.5626 | -11.200350 | -4.83315 | 0.924800 | 17.2516 | 49.8142 | -1.552374 | 12.125150 |
| 7 | 7 | 7 | var_6 | 200000.0 | 5.408949 | 0.866607 | 2.3473 | 4.767700 | 5.38510 | 6.003000 | 8.4477 | 6.1004 | 0.160217 | 1.235300 |
| 8 | 8 | 8 | var_7 | 200000.0 | 16.545850 | 3.418076 | 5.3497 | 13.943800 | 16.45680 | 19.102900 | 27.6918 | 22.3421 | 0.206582 | 5.159100 |
| 9 | 9 | 9 | var_8 | 200000.0 | 0.284162 | 3.332634 | -10.5055 | -2.317800 | 0.39370 | 2.937900 | 10.1513 | 20.6568 | 11.727941 | 5.255700 |
| 10 | 10 | 10 | var_9 | 200000.0 | 7.567236 | 1.235070 | 3.9705 | 6.618800 | 7.62960 | 8.584425 | 11.1506 | 7.1801 | 0.163213 | 1.965625 |
| 11 | 11 | 11 | var_10 | 200000.0 | 0.394340 | 5.500793 | -20.7313 | -3.594950 | 0.48730 | 4.382925 | 18.6702 | 39.4015 | 13.949350 | 7.977875 |
| 12 | 12 | 12 | var_11 | 200000.0 | -3.245596 | 5.970253 | -26.0950 | -7.510600 | -3.28695 | 0.852825 | 17.1887 | 43.2837 | -1.839494 | 8.363425 |
| 13 | 13 | 13 | var_12 | 200000.0 | 14.023978 | 0.190059 | 13.4346 | 13.894000 | 14.02550 | 14.164200 | 14.6545 | 1.2199 | 0.013552 | 0.270200 |
| 14 | 14 | 14 | var_13 | 200000.0 | 8.530232 | 4.639536 | -6.0111 | 5.072800 | 8.60425 | 12.274775 | 22.3315 | 28.3426 | 0.543893 | 7.201975 |
| 15 | 15 | 15 | var_14 | 200000.0 | 7.537606 | 2.247908 | 1.0133 | 5.781875 | 7.52030 | 9.270425 | 14.9377 | 13.9244 | 0.298226 | 3.488550 |
| 16 | 16 | 16 | var_15 | 200000.0 | 14.573126 | 0.411711 | 13.0769 | 14.262800 | 14.57410 | 14.874500 | 15.8633 | 2.7864 | 0.028251 | 0.611700 |
| 17 | 17 | 17 | var_16 | 200000.0 | 9.333264 | 2.557421 | 0.6351 | 7.452275 | 9.23205 | 11.055900 | 17.9506 | 17.3155 | 0.274011 | 3.603625 |
| 18 | 18 | 18 | var_17 | 200000.0 | -5.696731 | 6.712612 | -33.3802 | -10.476225 | -5.66635 | -0.810775 | 19.0259 | 52.4061 | -1.178327 | 9.665450 |
| 19 | 19 | 19 | var_18 | 200000.0 | 15.244013 | 7.851370 | -10.6642 | 9.177950 | 15.19625 | 21.013325 | 41.7480 | 52.4122 | 0.515046 | 11.835375 |
| 20 | 20 | 20 | var_19 | 200000.0 | 12.438567 | 7.996694 | -12.4025 | 6.276475 | 12.45390 | 18.433300 | 35.1830 | 47.5855 | 0.642895 | 12.156825 |
| 21 | 21 | 21 | var_20 | 200000.0 | 13.290894 | 5.876254 | -5.4322 | 8.627800 | 13.19680 | 17.879400 | 31.2859 | 36.7181 | 0.442126 | 9.251600 |
| 22 | 22 | 22 | var_21 | 200000.0 | 17.257883 | 8.196564 | -10.0890 | 11.551000 | 17.23425 | 23.089050 | 49.0443 | 59.1333 | 0.474946 | 11.538050 |
| 23 | 23 | 23 | var_22 | 200000.0 | 4.305430 | 2.847958 | -5.3225 | 2.182400 | 4.27515 | 6.293200 | 14.5945 | 19.9170 | 0.661480 | 4.110800 |
| 24 | 24 | 24 | var_23 | 200000.0 | 3.019540 | 0.526893 | 1.2098 | 2.634100 | 3.00865 | 3.403800 | 4.8752 | 3.6654 | 0.174495 | 0.769700 |
| 25 | 25 | 25 | var_24 | 200000.0 | 10.584400 | 3.777245 | -0.6784 | 7.613000 | 10.38035 | 13.479600 | 25.4460 | 26.1244 | 0.356869 | 5.866600 |
| 26 | 26 | 26 | var_25 | 200000.0 | 13.667496 | 0.285535 | 12.7200 | 13.456400 | 13.66250 | 13.863700 | 14.6546 | 1.9346 | 0.020892 | 0.407300 |
| 27 | 27 | 27 | var_26 | 200000.0 | -4.055133 | 5.922210 | -24.2431 | -8.321725 | -4.19690 | -0.090200 | 15.6751 | 39.9182 | -1.460423 | 8.231525 |
| 28 | 28 | 28 | var_27 | 200000.0 | -1.137908 | 1.523714 | -6.1668 | -2.307900 | -1.13210 | 0.015625 | 3.2431 | 9.4099 | -1.339049 | 2.323525 |
| 29 | 29 | 29 | var_28 | 200000.0 | 5.532980 | 0.783367 | 2.0896 | 4.992100 | 5.53485 | 6.093700 | 8.7874 | 6.6978 | 0.141581 | 1.101600 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 171 | 171 | 171 | var_170 | 200000.0 | -0.004962 | 4.424621 | -14.5060 | -3.258500 | 0.00280 | 3.096400 | 16.7319 | 31.2379 | -891.690223 | 6.354900 |
| 172 | 172 | 172 | var_171 | 200000.0 | -0.831777 | 5.378008 | -22.4793 | -4.720350 | -0.80735 | 2.956800 | 17.9173 | 40.3966 | -6.465689 | 7.677150 |
| 173 | 173 | 173 | var_172 | 200000.0 | 19.817094 | 8.674171 | -11.4533 | 13.731775 | 19.74800 | 25.907725 | 53.5919 | 65.0452 | 0.437712 | 12.175950 |
| 174 | 174 | 174 | var_173 | 200000.0 | -0.677967 | 5.966674 | -22.7487 | -5.009525 | -0.56975 | 3.619900 | 18.8554 | 41.6041 | -8.800833 | 8.629425 |
| 175 | 175 | 175 | var_174 | 200000.0 | 20.210677 | 7.136427 | -2.9953 | 15.064600 | 20.20610 | 25.641225 | 43.5468 | 46.5421 | 0.353102 | 10.576625 |
| 176 | 176 | 176 | var_175 | 200000.0 | 11.640613 | 2.892167 | 3.2415 | 9.371600 | 11.67980 | 13.745500 | 20.8548 | 17.6133 | 0.248455 | 4.373900 |
| 177 | 177 | 177 | var_176 | 200000.0 | -2.799585 | 7.513939 | -29.1165 | -8.386500 | -2.53845 | 2.704400 | 20.2452 | 49.3617 | -2.683948 | 11.090900 |
| 178 | 178 | 178 | var_177 | 200000.0 | 11.882933 | 2.628895 | 4.9521 | 9.808675 | 11.73725 | 13.931300 | 20.5965 | 15.6444 | 0.221233 | 4.122625 |
| 179 | 179 | 179 | var_178 | 200000.0 | -1.014064 | 8.579810 | -29.2734 | -7.395700 | -0.94205 | 5.338750 | 29.8413 | 59.1147 | -8.460821 | 12.734450 |
| 180 | 180 | 180 | var_179 | 200000.0 | 2.591444 | 2.798956 | -7.8561 | 0.625575 | 2.51230 | 4.391125 | 13.4487 | 21.3048 | 1.080076 | 3.765550 |
| 181 | 181 | 181 | var_180 | 200000.0 | -2.741666 | 5.261243 | -22.0374 | -6.673900 | -2.68880 | 0.996200 | 12.7505 | 34.7879 | -1.918995 | 7.670100 |
| 182 | 182 | 182 | var_181 | 200000.0 | 10.085518 | 1.371862 | 5.4165 | 9.084700 | 10.03605 | 11.011300 | 14.3939 | 8.9774 | 0.136023 | 1.926600 |
| 183 | 183 | 183 | var_182 | 200000.0 | 0.719109 | 8.963434 | -26.0011 | -6.064425 | 0.72020 | 7.499175 | 29.2487 | 55.2498 | 12.464637 | 13.563600 |
| 184 | 184 | 184 | var_183 | 200000.0 | 8.769088 | 4.474924 | -4.8082 | 5.423100 | 8.60000 | 12.127425 | 23.7049 | 28.5131 | 0.510307 | 6.704325 |
| 185 | 185 | 185 | var_184 | 200000.0 | 12.756676 | 9.318280 | -18.4897 | 5.663300 | 12.52100 | 19.456150 | 44.3634 | 62.8531 | 0.730463 | 13.792850 |
| 186 | 186 | 186 | var_185 | 200000.0 | -3.983261 | 4.725167 | -22.5833 | -7.360000 | -3.94695 | -0.590650 | 12.9975 | 35.5808 | -1.186256 | 6.769350 |
| 187 | 187 | 187 | var_186 | 200000.0 | 8.970274 | 3.189759 | -3.0223 | 6.715200 | 8.90215 | 11.193800 | 21.7392 | 24.7615 | 0.355592 | 4.478600 |
| 188 | 188 | 188 | var_187 | 200000.0 | -10.335043 | 11.574708 | -47.7536 | -19.205125 | -10.20975 | -1.466000 | 22.7861 | 70.5397 | -1.119948 | 17.739125 |
| 189 | 189 | 189 | var_188 | 200000.0 | 15.377174 | 3.944604 | 4.4123 | 12.501550 | 15.23945 | 18.345225 | 29.3303 | 24.9180 | 0.256523 | 5.843675 |
| 190 | 190 | 190 | var_189 | 200000.0 | 0.746072 | 0.976348 | -2.5543 | 0.014900 | 0.74260 | 1.482900 | 4.0341 | 6.5884 | 1.308652 | 1.468000 |
| 191 | 191 | 191 | var_190 | 200000.0 | 3.234440 | 4.559922 | -14.0933 | -0.058825 | 3.20360 | 6.406200 | 18.4409 | 32.5342 | 1.409803 | 6.465025 |
| 192 | 192 | 192 | var_191 | 200000.0 | 7.438408 | 3.023272 | -2.6917 | 5.157400 | 7.34775 | 9.512525 | 16.7165 | 19.4082 | 0.406441 | 4.355125 |
| 193 | 193 | 193 | var_192 | 200000.0 | 1.927839 | 1.478423 | -3.8145 | 0.889775 | 1.90130 | 2.949500 | 8.4024 | 12.2169 | 0.766881 | 2.059725 |
| 194 | 194 | 194 | var_193 | 200000.0 | 3.331774 | 3.992030 | -11.7834 | 0.584600 | 3.39635 | 6.205800 | 18.2818 | 30.0652 | 1.198170 | 5.621200 |
| 195 | 195 | 195 | var_194 | 200000.0 | 17.993784 | 3.135162 | 8.6944 | 15.629800 | 17.95795 | 20.396525 | 27.9288 | 19.2344 | 0.174236 | 4.766725 |
| 196 | 196 | 196 | var_195 | 200000.0 | -0.142088 | 1.429372 | -5.2610 | -1.170700 | -0.17270 | 0.829600 | 4.2729 | 9.5339 | -10.059738 | 2.000300 |
| 197 | 197 | 197 | var_196 | 200000.0 | 2.303335 | 5.454369 | -14.2096 | -1.946925 | 2.40890 | 6.556725 | 18.3215 | 32.5311 | 2.368031 | 8.503650 |
| 198 | 198 | 198 | var_197 | 200000.0 | 8.908158 | 0.921625 | 5.9606 | 8.252800 | 8.88820 | 9.593300 | 12.0004 | 6.0398 | 0.103459 | 1.340500 |
| 199 | 199 | 199 | var_198 | 200000.0 | 15.870720 | 3.010945 | 6.2993 | 13.829700 | 15.93405 | 18.064725 | 26.0791 | 19.7798 | 0.189717 | 4.235025 |
| 200 | 200 | 200 | var_199 | 200000.0 | -3.326537 | 10.438015 | -38.8528 | -11.208475 | -2.81955 | 4.836800 | 28.5007 | 67.3535 | -3.137802 | 16.045275 |
201 rows × 14 columns
In [68]:
df_des['stddev'].min()
Out[68]:
0.007186267883143137
In [69]:
df_des['stddev'].quantile(q=0.5)
Out[69]:
3.944604281951493
In [24]:
# 中位数的取值情况 df_des.plot(kind='bar',x='IDcode',y='50%',color='red',figsize=(14,6)) plt.show()

In [5]:
df_train.select('var_193').distinct().count()
Out[5]:
110557
In [7]:
df_train.select('var_45').distinct().count()
Out[7]:
169968
In [21]:
df_train.select('var_91').distinct().count()
Out[21]:
7962
In [24]:
# 查看每个变量的种类
for col in df_train.columns:
print(col,df_train.select(col).distinct().count())
ID_code 200000 target 2 var_0 94672 var_1 108932 var_2 86555 var_3 74597 var_4 63515 var_5 141030 var_6 38599 var_7 103063 var_8 98617 var_9 49417 var_10 128764 var_11 130193 var_12 9561 var_13 115181 var_14 79122 var_15 19810 var_16 86918 var_17 137823 var_18 139515 var_19 144180 var_20 127764 var_21 140062 var_22 90661 var_23 24913 var_24 105101 var_25 14853 var_26 127089 var_27 60186 var_28 35859 var_29 88339 var_30 145977 var_31 77388 var_32 85964 var_33 112239 var_34 25164 var_35 122384 var_36 96404 var_37 79040 var_38 115366 var_39 112674 var_40 141878 var_41 131896 var_42 31592 var_43 15188 var_44 127702 var_45 169968 var_46 93450 var_47 154781 var_48 152039 var_49 140641 var_50 32308 var_51 143455 var_52 121313 var_53 33460 var_54 144776 var_55 128077 var_56 103045 var_57 35545 var_58 113908 var_59 37744 var_60 113763 var_61 159369 var_62 74778 var_63 97098 var_64 59379 var_65 108347 var_66 47722 var_67 137253 var_68 451 var_69 110346 var_70 153193 var_71 13527 var_72 110115 var_73 142582 var_74 161058 var_75 129383 var_76 139317 var_77 106809 var_78 72254 var_79 53212 var_80 136432 var_81 79065 var_82 144829 var_83 144281 var_84 133766 var_85 108437 var_86 140594 var_87 125296 var_88 84918 var_89 103522 var_90 157210 var_91 7962 var_92 110743 var_93 26708 var_94 89146 var_95 29388 var_96 148099 var_97 158739 var_98 33266 var_99 69301 var_100 150727 var_101 122295 var_102 146237 var_103 9376 var_104 72627 var_105 39115 var_106 71065 var_107 137827 var_108 8525 var_109 112172 var_110 106121 var_111 46464 var_112 60482 var_113 116496 var_114 43084 var_115 86729 var_116 63467 var_117 164469 var_118 143667 var_119 112403 var_120 158269 var_121 64695 var_122 121768 var_123 129893 var_124 91022 var_125 16059 var_126 32411 var_127 95711 var_128 98200 var_129 113425 var_130 36638 var_131 21465 var_132 57923 var_133 19236 var_134 131620 var_135 140774 var_136 156615 var_137 144397 var_138 117429 var_139 137294 var_140 121384 var_141 134444 var_142 128613 var_143 94372 var_144 40595 var_145 108526 var_146 84314 var_147 137559 var_148 10608 var_149 148504 var_150 83660 var_151 109667 var_152 95823 var_153 73728 var_154 119342 var_155 127457 var_156 40634 var_157 126534 var_158 144556 var_159 112830 var_160 156274 var_161 11071 var_162 57396 var_163 123168 var_164 122744 var_165 119403 var_166 17902 var_167 140955 var_168 97227 var_169 18242 var_170 113721 var_171 125914 var_172 143366 var_173 128120 var_174 134945 var_175 92659 var_176 142521 var_177 85720 var_178 145236 var_179 90091 var_180 123477 var_181 56164 var_182 149196 var_183 117529 var_184 145185 var_185 120747 var_186 98060 var_187 157031 var_188 108813 var_189 41765 var_190 114959 var_191 94266 var_192 59066 var_193 110557 var_194 97069 var_195 57870 var_196 125560 var_197 40537 var_198 94153 var_199 149430
In [6]:
df_train.count()
Out[6]:
200000
In [6]:
dd = float(df_des[df_des['IDcode']=='var_199']['50%']) dd
Out[6]:
-2.81955
In [ ]:
# 数据清洗 1. 缺失值处理 2. 异常数据处理 3. 剔除多重共线性变量 4. 数据分箱
In [14]:
df_std01 = df_des[df_des['std']<0.1][['IDcode','std']].sort_values(by=['std'],ascending=True)
select_cols01 = df_std01['IDcode'].tolist()
# select_cols01.remove('target')
df_std02 = df_des[df_des['std']>=0.1][['IDcode','std']].sort_values(by=['std'],ascending=True)
select_cols02 = df_std02['IDcode'].tolist()
select_cols02.remove('target')
# print(select_cols)
stages = []
from pyspark.ml.feature import OneHotEncoder, StringIndexer, VectorAssembler,StandardScaler
import pyspark.ml.feature as ft
def deal_binarizer(categoricalColumns):
satge = []
new_cols = []
for categoricalCol in categoricalColumns:
outputCol = categoricalCol+"bin"
dd = float(df_des[df_des['IDcode']==categoricalCol]['50%'])
# print(categoricalCol,dd)
binarizer = ft.Binarizer(threshold=dd, inputCol=categoricalCol, outputCol=outputCol)
satge += [binarizer]
new_cols.append(outputCol)
return satge,new_cols
satge,new_cols = deal_binarizer(select_cols01)
stages += satge
inputCols = new_cols + select_cols02
print(inputCols)
assembler = VectorAssembler(inputCols=inputCols, outputCol="asfeatures")
stages += [assembler]
label_stringIdx = StringIndexer(inputCol='target', outputCol='label')
stages += [label_stringIdx]
scaler = StandardScaler(inputCol="asfeatures", outputCol="features",
withStd=True, withMean=False)
stages += [scaler]
from pyspark.ml import Pipeline
pipeline = Pipeline(stages = stages)
pipelineModel = pipeline.fit(df_train)
df = pipelineModel.transform(df_train)
train, test = df.randomSplit([0.7, 0.3], seed=2019)
print("Training Dataset Count: " + str(train.count()))
print("Test Dataset Count: " + str(test.count()))
# 测试
from pyspark.ml.classification import LogisticRegression
lr = LogisticRegression(featuresCol='features',regParam=0.01, labelCol='label', maxIter=200)
lrModel = lr.fit(train)
import matplotlib.pyplot as plt
import numpy as np
beta = np.sort(lrModel.coefficients)
plt.plot(beta)
plt.ylabel('Beta Coefficients')
plt.show()
trainingSummary = lrModel.summary
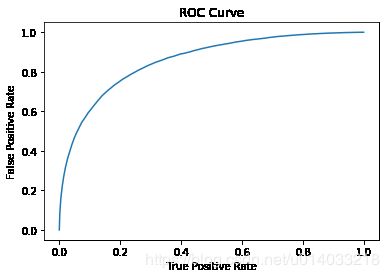
roc = trainingSummary.roc.toPandas()
plt.plot(roc['FPR'],roc['TPR'])
plt.ylabel('False Positive Rate')
plt.xlabel('True Positive Rate')
plt.title('ROC Curve')
plt.show()
print('Training set areaUnderROC: ' + str(trainingSummary.areaUnderROC))
pr = trainingSummary.pr.toPandas()
plt.plot(pr['recall'],pr['precision'])
plt.ylabel('Precision')
plt.xlabel('Recall')
plt.show()
predictions = lrModel.transform(test)
from pyspark.ml.evaluation import BinaryClassificationEvaluator
evaluator = BinaryClassificationEvaluator()
print('Test Area Under ROC', evaluator.evaluate(predictions))
print('areaUnderROC', evaluator.evaluate(predictions,
{evaluator.metricName: 'areaUnderROC'}))
print('areaUnderPR', evaluator.evaluate(predictions,{evaluator.metricName: 'areaUnderPR'}))
# predictions.select('features').show()
predictions = predictions.select('features', 'target', 'label', 'rawPrediction', 'prediction', 'probability')
# predictions.show()
pd.DataFrame(predictions.take(10), columns=predictions.columns).transpose()
['var_68bin', 'var_91', 'var_108', 'var_103', 'var_12', 'var_148', 'var_161', 'var_71', 'var_25', 'var_43', 'var_125', 'var_169', 'var_166', 'var_133', 'var_15', 'var_131', 'var_23', 'var_34', 'var_93', 'var_95', 'var_50', 'var_42', 'var_98', 'var_53', 'var_126', 'var_28', 'var_57', 'var_130', 'var_59', 'var_105', 'var_6', 'var_197', 'var_144', 'var_156', 'var_189', 'var_114', 'var_111', 'var_66', 'var_9', 'var_79', 'var_181', 'var_162', 'var_195', 'var_132', 'var_192', 'var_64', 'var_27', 'var_112', 'var_4', 'var_116', 'var_121', 'var_99', 'var_106', 'var_104', 'var_78', 'var_153', 'var_62', 'var_3', 'var_31', 'var_14', 'var_37', 'var_81', 'var_150', 'var_88', 'var_146', 'var_16', 'var_32', 'var_29', 'var_115', 'var_177', 'var_2', 'var_124', 'var_94', 'var_179', 'var_22', 'var_46', 'var_175', 'var_143', 'var_152', 'var_198', 'var_191', 'var_0', 'var_168', 'var_63', 'var_36', 'var_194', 'var_127', 'var_186', 'var_128', 'var_8', 'var_7', 'var_56', 'var_89', 'var_24', 'var_65', 'var_77', 'var_110', 'var_145', 'var_85', 'var_188', 'var_72', 'var_69', 'var_151', 'var_193', 'var_1', 'var_39', 'var_159', 'var_129', 'var_119', 'var_92', 'var_60', 'var_38', 'var_58', 'var_33', 'var_109', 'var_170', 'var_113', 'var_183', 'var_138', 'var_190', 'var_13', 'var_185', 'var_140', 'var_101', 'var_154', 'var_52', 'var_165', 'var_122', 'var_35', 'var_180', 'var_163', 'var_171', 'var_196', 'var_164', 'var_10', 'var_157', 'var_87', 'var_55', 'var_142', 'var_155', 'var_20', 'var_44', 'var_26', 'var_41', 'var_173', 'var_11', 'var_75', 'var_123', 'var_134', 'var_84', 'var_17', 'var_141', 'var_174', 'var_67', 'var_147', 'var_80', 'var_73', 'var_176', 'var_107', 'var_135', 'var_139', 'var_86', 'var_167', 'var_18', 'var_49', 'var_5', 'var_158', 'var_76', 'var_30', 'var_19', 'var_51', 'var_21', 'var_40', 'var_83', 'var_54', 'var_82', 'var_96', 'var_178', 'var_102', 'var_172', 'var_118', 'var_137', 'var_182', 'var_100', 'var_184', 'var_136', 'var_149', 'var_199', 'var_47', 'var_160', 'var_48', 'var_187', 'var_61', 'var_70', 'var_120', 'var_97', 'var_90', 'var_117', 'var_74', 'var_45'] Training Dataset Count: 140208 Test Dataset Count: 59792
Training set areaUnderROC: 0.8572874986254869

Test Area Under ROC 0.8604638791224748 areaUnderROC 0.8604638791224721 areaUnderPR 0.5145853422620837
Out[14]:
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | |
|---|---|---|---|---|---|---|---|---|---|---|
| features | [2.0000262487479796, 47.42117806123396, 82.294... | [0.0, 46.302865299428504, 82.68222664303848, 7... | [2.0000262487479796, 45.757139153802285, 84.51... | [0.0, 44.64668799313429, 83.20358606228598, 8.... | [0.0, 44.38397948845709, 82.9966788488178, 7.3... | [2.0000262487479796, 46.29958963228788, 85.204... | [0.0, 44.481594369247375, 82.99434091420234, 9... | [0.0, 47.517482675168, 83.12409628536034, 9.30... | [2.0000262487479796, 45.63659460302771, 82.554... | [0.0, 46.1672526798071, 82.50746603053287, 10.... |
| target | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
| label | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
| rawPrediction | [2.745411097253725, -2.745411097253725] | [2.2770635627955, -2.2770635627955] | [1.7640231694663067, -1.7640231694663067] | [2.3870306837485726, -2.3870306837485726] | [2.699555439548069, -2.699555439548069] | [1.9689919906092934, -1.9689919906092934] | [2.236223494259175, -2.236223494259175] | [2.352430409935469, -2.352430409935469] | [2.8009650886646655, -2.8009650886646655] | [2.6047753141937164, -2.6047753141937164] |
| prediction | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| probability | [0.9396536620507552, 0.0603463379492449] | [0.9069595547320315, 0.09304044526796858] | [0.8537128180771243, 0.14628718192287574] | [0.9158329668960973, 0.08416703310390271] | [0.9370004063505419, 0.06299959364945804] | [0.8775028018243339, 0.12249719817566608] | [0.9034555593377342, 0.09654444066226563] | [0.9131272157024063, 0.08687278429759375] | [0.942727953398344, 0.05727204660165593] | [0.9311682791393624, 0.06883172086063759] |
In [20]:
df_test = get_input_data(base_path + 'test.csv')
pd.DataFrame(df_test.take(10), columns=df_test.columns).transpose()
df_test = pipelineModel.transform(df_test)
predictions = lrModel.transform(df_test)
# predictions.select('features').show()
predictions = predictions.select('ID_code', 'prediction')
# predictions.show()
pd.DataFrame(predictions.take(10), columns=predictions.columns).transpose()
Out[20]:
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | |
|---|---|---|---|---|---|---|---|---|---|---|
| ID_code | test_0 | test_1 | test_2 | test_3 | test_4 | test_5 | test_6 | test_7 | test_8 | test_9 |
| prediction | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
In [19]:
predictions.show(5)
+--------------------+--------------------+----------+--------------------+ | features| rawPrediction|prediction| probability| +--------------------+--------------------+----------+--------------------+ |[0.0,46.405721247...|[1.84608169708193...| 0.0|[0.86366639261870...| |[2.00002624874797...|[1.86154755297036...| 0.0|[0.86547722599330...| |[0.0,45.986435853...|[2.29001370850934...| 0.0|[0.90804659470819...| |[0.0,45.318199756...|[1.90419746231964...| 0.0|[0.87036585836244...| |[2.00002624874797...|[2.07114740649738...| 0.0|[0.88806706897729...| +--------------------+--------------------+----------+--------------------+ only showing top 5 rows
In [23]:
# predictions = predictions.toPandas()
predictions['target'] = predictions['prediction'].apply(lambda x: int(x))
predictions[["ID_code","target"]].to_csv("./submit01.csv",index=False)
predictions[["ID_code","target"]]
Out[23]:
| ID_code | target | |
|---|---|---|
| 0 | test_0 | 0 |
| 1 | test_1 | 0 |
| 2 | test_2 | 0 |
| 3 | test_3 | 0 |
| 4 | test_4 | 0 |
| 5 | test_5 | 0 |
| 6 | test_6 | 0 |
| 7 | test_7 | 0 |
| 8 | test_8 | 0 |
| 9 | test_9 | 0 |
| 10 | test_10 | 0 |
| 11 | test_11 | 0 |
| 12 | test_12 | 0 |
| 13 | test_13 | 0 |
| 14 | test_14 | 0 |
| 15 | test_15 | 0 |
| 16 | test_16 | 0 |
| 17 | test_17 | 0 |
| 18 | test_18 | 0 |
| 19 | test_19 | 0 |
| 20 | test_20 | 0 |
| 21 | test_21 | 0 |
| 22 | test_22 | 0 |
| 23 | test_23 | 0 |
| 24 | test_24 | 0 |
| 25 | test_25 | 0 |
| 26 | test_26 | 0 |
| 27 | test_27 | 0 |
| 28 | test_28 | 0 |
| 29 | test_29 | 0 |
| ... | ... | ... |
| 199970 | test_199970 | 0 |
| 199971 | test_199971 | 0 |
| 199972 | test_199972 | 0 |
| 199973 | test_199973 | 0 |
| 199974 | test_199974 | 0 |
| 199975 | test_199975 | 0 |
| 199976 | test_199976 | 0 |
| 199977 | test_199977 | 0 |
| 199978 | test_199978 | 0 |
| 199979 | test_199979 | 0 |
| 199980 | test_199980 | 0 |
| 199981 | test_199981 | 0 |
| 199982 | test_199982 | 0 |
| 199983 | test_199983 | 0 |
| 199984 | test_199984 | 0 |
| 199985 | test_199985 | 0 |
| 199986 | test_199986 | 0 |
| 199987 | test_199987 | 0 |
| 199988 | test_199988 | 0 |
| 199989 | test_199989 | 0 |
| 199990 | test_199990 | 0 |
| 199991 | test_199991 | 0 |
| 199992 | test_199992 | 0 |
| 199993 | test_199993 | 0 |
| 199994 | test_199994 | 0 |
| 199995 | test_199995 | 0 |
| 199996 | test_199996 | 0 |
| 199997 | test_199997 | 0 |
| 199998 | test_199998 | 0 |
| 199999 | test_199999 | 0 |
200000 rows × 2 columns
In [ ]:
from pyspark.ml.classification import DecisionTreeClassifier
dt = DecisionTreeClassifier(featuresCol = 'features', labelCol = 'label', maxDepth = 20)
dtModel = dt.fit(train)
predictions = dtModel.transform(test)
evaluator = BinaryClassificationEvaluator()
print("Test Area Under ROC: " + str(evaluator.evaluate(predictions, {evaluator.metricName: "areaUnderROC"})))
from pyspark.ml.classification import RandomForestClassifier
rf = RandomForestClassifier(featuresCol = 'features', labelCol = 'label')
rfModel = rf.fit(train)
predictions = rfModel.transform(test)
evaluator = BinaryClassificationEvaluator()
print("Test Area Under ROC: " + str(evaluator.evaluate(predictions, {evaluator.metricName: "areaUnderROC"})))
from pyspark.ml.classification import GBTClassifier
gbt = GBTClassifier(maxIter=100)
gbtModel = gbt.fit(train)
predictions = gbtModel.transform(test)
evaluator = BinaryClassificationEvaluator()
print("Test Area Under ROC: " + str(evaluator.evaluate(predictions, {evaluator.metricName: "areaUnderROC"})))
print(gbt.explainParams())
# from pyspark.ml.tuning import ParamGridBuilder, CrossValidator
# paramGrid = (ParamGridBuilder()
# .addGrid(gbt.maxDepth, [12, 8, 20])
# .addGrid(gbt.maxBins, [200, 600])
# .addGrid(gbt.maxIter, [100, 1000])
# .build())
# cv = CrossValidator(estimator=gbt, estimatorParamMaps=paramGrid, evaluator=evaluator, numFolds=5)
# # Run cross validations. This can take about 6 minutes since it is training over 20 trees!
# cvModel = cv.fit(train)
# predictions = cvModel.transform(test)
# print('Test Area Under ROC', evaluator.evaluate(predictions))
# print('areaUnderROC', evaluator.evaluate(predictions,
# {evaluator.metricName: 'areaUnderROC'}))
# print('areaUnderPR', evaluator.evaluate(predictions,{evaluator.metricName: 'areaUnderPR'}))
# predictions.show()
pd.DataFrame(predictions.take(10), columns=predictions.columns).transpose()