一、爬取数据
Python版本是3.6,爬取后保存在MySQL中,版本是5.5。
51job搜索位置的链接是【数据分析师招聘,求职】-前程无忧
首先是可以在ide中运行scrapy的文件run.py:
from scrapy.cmdline import execute
execute(['scrapy', 'crawl', 'job51'])
需要爬取并存储的字段item.py:
import scrapy
class Job51Item(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
zhiwei = scrapy.Field()
gongsi = scrapy.Field()
didian = scrapy.Field()
xinzi = scrapy.Field()
gongsileixing = scrapy.Field()
guimo = scrapy.Field()
hangye = scrapy.Field()
jingyan = scrapy.Field()
xueli = scrapy.Field()
fuli = scrapy.Field()
zhiweiyaoqiu = scrapy.Field()
lianjie = scrapy.Field()
爬虫的入口 job51.py:
import re
import scrapy
from bs4 import BeautifulSoup
from items import Job51Item
class Myspider(scrapy.Spider):
name = 'job51'
allowed_domains = ['51job.com']
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'}
def start_requests(self):
for i in range(1, 208):
url_1 = 'http://search.51job.com/list/000000,000000,0000,00,9,99,%25E6%2595%25B0%25E6%258D%25AE%25E5%2588%2586%25E6%259E%2590%25E5%25B8%2588,2,'
url_2 = '.html?lang=c&stype=1&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=1&dibiaoid=0&address=&line=&specialarea=00&from=&welfare='
url = url_1 + str(i) + url_2
yield scrapy.Request(url, headers=self.headers, callback=self.parse)
#获取每个职位的详细信息入口url
def parse(self, response):
soup = BeautifulSoup(response.text, 'lxml')
tls = soup.find_all('p', class_='t1 ')
for tl in tls:
url = tl.find('a', target='_blank')['href']
yield scrapy.Request(url, callback=self.get_content, meta={'url': url})
#用BeautifulSoup爬取详细页字段
def get_content(self, response):
soup = BeautifulSoup(response.text, 'lxml')
item = Job51Item()
item['zhiwei'] = soup.find('h1').get_text().replace('\xa0', '')
item['gongsi'] = soup.find('p', class_='cname').find('a', target='_blank').get_text().replace('\xa0', '')
item['didian'] = soup.find('span', class_='lname').get_text().replace('\xa0', '')
item['xinzi'] = soup.find('div', class_='cn').find('strong').get_text().replace('\xa0', '')
gongsixinxi = soup.find('p', class_='msg ltype').get_text().replace('\t', '').replace('\r', '').replace('\n', '').replace('\xa0', '')
item['gongsileixing'] = gongsixinxi.split('|')[0]
item['guimo'] = gongsixinxi.split('|')[1]
item['hangye'] = gongsixinxi.split('|')[2]
zhaopinyaoqiu = soup.find('div', class_='t1').get_text().replace('\xa0', '')
item['jingyan'] = zhaopinyaoqiu.split('\n')[1]
try:
item['xueli'] = re.findall(r'(.*?)', response.text)[0]
except:
item['xueli'] = '无'
try:
item['fuli'] = soup.find('p', class_='t2').get_text().replace('\n', ' ').replace('\xa0', '')
except:
item['fuli'] = '无'
item['zhiweiyaoqiu'] =
re.findall(r'< div class="bmsg job_msg inbox">(.*?)
', response.text, re.I|re.S|re.M)[0].replace('\r', '').replace('\n', '').replace('\t', '').replace('\xa0', '').replace('
', '').replace('
', '')item['lianjie'] = response.meta['url']
yield item
SQL部分sql.py:
import pymysql.cursors
import settings
MYSQL_HOSTS = settings.MYSQL_HOSTS
MYSQL_USER = settings.MYSQL_USER
MYSQL_PASSWORD = settings.MYSQL_PASSWORD
MYSQL_PORT = settings.MYSQL_PORT
MYSQL_DB = settings.MYSQL_DB
cnx = pymysql.connect(
host=MYSQL_HOSTS,
port=MYSQL_PORT,
user=MYSQL_USER,
passwd=MYSQL_PASSWORD,
db=MYSQL_DB,
charset='gbk')
cur = cnx.cursor()
class Sql:
@classmethod
def insert_job51(cls, zhiwei, gongsi, didian, xinzi, gongsileixing, guimo, hangye, jingyan, xueli, fuli, zhiweiyaoqiu, lianjie):
sql = 'INSERT INTO job51(zhiwei,gongsi,didian,xinzi,gongsileixing,guimo,hangye,jingyan,xueli,fuli,zhiweiyaoqiu,lianjie) ' \
'VALUES(%(zhiwei)s,%(gongsi)s,%(didian)s,%(xinzi)s,%(gongsileixing)s,%(guimo)s,%(hangye)s,%(jingyan)s,%(xueli)s,%(fuli)s,%(zhiweiyaoqiu)s,%(lianjie)s)'
value = {'zhiwei': zhiwei,
'gongsi': gongsi,
'didian': didian,
'xinzi': xinzi,
'gongsileixing': gongsileixing,
'guimo': guimo,
'hangye': hangye,
'jingyan': jingyan,
'xueli': xueli,
'fuli': fuli,
'zhiweiyaoqiu': zhiweiyaoqiu,
'lianjie': lianjie,}
cur.execute(sql, value)
cnx.commit()
管道存储pipelines.py:
from .sql import Sql
from items import Job51Item
class Job51Pipeline(object):
def process_item(self, item, spider):
zhiwei = item['zhiwei']
gongsi = item['gongsi']
didian = item['didian']
xinzi = item['xinzi']
gongsileixing = item['gongsileixing']
guimo = item['guimo']
hangye = item['hangye']
jingyan = item['jingyan']
xueli = item['xueli']
fuli = item['fuli']
zhiweiyaoqiu = item['zhiweiyaoqiu']
lianjie = item['lianjie']
Sql.insert_job51(zhiwei, gongsi, didian, xinzi, gongsileixing, guimo, hangye, jingyan, xueli, fuli, zhiweiyaoqiu, lianjie)
print('写入职位信息')
在MySQL中建立新表,包含所有字段:
CREATE TABLE `job51` (
`id` int(10) NOT NULL AUTO_INCREMENT,
`zhiwei` varchar(255) DEFAULT NULL,
`gongsi` varchar(255) DEFAULT NULL,
`didian` varchar(255) DEFAULT NULL,
`xinzi` varchar(255) DEFAULT NULL,
`gongsileixing` varchar(255) DEFAULT NULL,
`guimo` varchar(255) DEFAULT NULL,
`hangye` varchar(255) DEFAULT NULL,
`jingyan` varchar(255) DEFAULT NULL,
`xueli` varchar(255) DEFAULT NULL,
`fuli` varchar(255) DEFAULT NULL,
`zhiweiyaoqiu` text,
`lianjie` text,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=gbk
配置settings.py:
BOT_NAME = 'job51'
SPIDER_MODULES = ['job51.spiders']
NEWSPIDER_MODULE = 'job51.spiders'
MYSQL_HOSTS = 'localhost'
MYSQL_USER = 'root'
MYSQL_PASSWORD = '123456'
MYSQL_PORT = 3306
MYSQL_DB = 'job51'
ROBOTSTXT_OBEY = True
ITEM_PIPELINES = {
'job51.pipelines.Job51Pipeline': 300,
}
HTTPCACHE_ENABLED = True
HTTPCACHE_EXPIRATION_SECS = 0
HTTPCACHE_DIR = 'httpcache'
HTTPCACHE_IGNORE_HTTP_CODES = []
HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
二、数据清洗和可视化
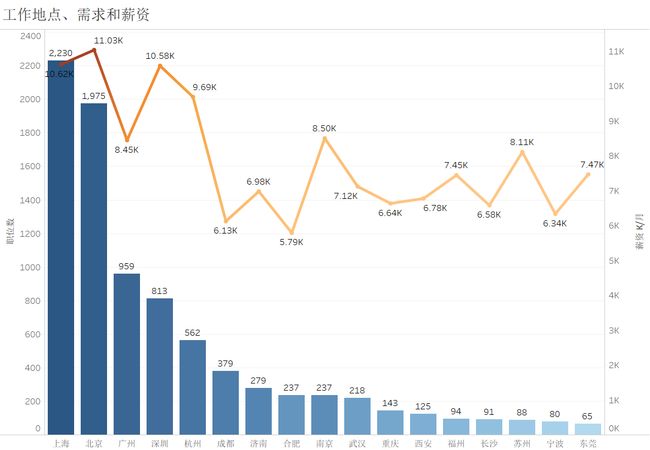
一共爬取了9705条职位信息,如图所示。

通过Excel清洗数据后导入Tableau进行可视化分析。
1.民营公司招聘需求占了近2/3,其次是合资公司

2.150-500人规模的公司需求最多,薪资基本随着公司规模扩大而增加

3.不同行业的数据分析职位平均薪资水平,集中在9-11K之间

4.北上深杭平均薪资10K左右
5.要求为本科的最多,硕士以上很少,要求不限学历的也很可观

6.1年经验的职位薪资略低于应届生,5年以上经验的薪资水平上了一个台阶

7.聚类分析

根据职位特征进行聚类分析,大致可以把职位需求分为三种类型:
从薪资上看,其中第一、三类属于高薪职位,平均薪资能够达到11K,第三类的薪资水平分布稍稳定;第二类平均薪资仅7K左右。
从规模上看,大型公司提供的待遇更加优渥,全部属于高薪职位;小型公司和中型公司分别有45.5%、40.2%的职位薪资水平较低。
从经验要求来看,要求少量经验的公司最多,但是56.5%的职位薪资不高;而经验较丰富的职位都属于高薪。
从学历要求来看,无学历要求和专科集中在第二类,而本科和研究生集中在第一、三类,可见在数据分析职位上学历是比较重要的因素。
8.招聘要求的关键词词云

三、总结
1、从公司岗位需求来看,北上广深杭是缺口比较大的地区,民营公司的需求最大,规模越大的公司能开出更高的薪资条件来吸引人才;
2、从薪资水平来看,刚入行薪资在7-8K,2年后能够达到每2年增加4-5K的发展水平。北上深杭的平均薪资能达到10K,属于第一梯队,其次是南京广州苏州在8K左右,福州东莞武汉在7K左右,属于第二梯队;
3、从求职者角度来看,高薪职位基本在本科及以上学历中分布,需要掌握的技能包括业务类如分析能力、表达能力以及逻辑能力,工具类如Excel、Python、SPSS、Hadoop等。