1、数据挖掘思维导图
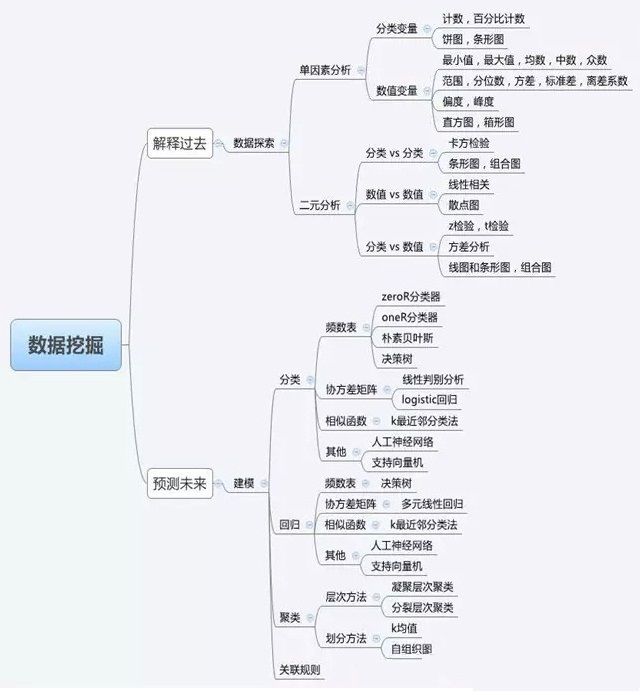
思维导图为:Dr. Saed Sayad总结的An Introduction to Data Mining
个人更喜欢的分类方式为:
1、分类与预测
2、关联
3、聚类
4、异常检测
2、信用评分中的常见算法
信用评分中主要包括申请评分、行为评分、催收评分卡、反欺诈。
其中,申请评分和行为评分比较成熟的是逻辑回归,其次层次聚类和判别分析、决策树。
申请和信用评分需要比较好的解释性,也有的使用神经网络做,只是个噱头。
在反欺诈中,不需要有好的解释性,神经网络在这方面这方面使用的比较多。
其实,当前在评分中,几乎没有单一的算法,都是综合处理。即使是传统的逻辑回归,针对变量的共线性分析也会采用很多方法,另外针对单一变量的分段也采用决策树来进行最优划分。
3、总结
实际上处理数据,主要包括:
1、针对数据进行数据的探索,各种统计指标,单个变量的情况分析,针对单变量的数据预处理和规范化
2、针对数据中变量和变量之间的关系进行分析
3、基于变量和变量之间的分析或者变量的分析,做出结论
4、通过原始数据验证模型和数据的吻合程度,通过新数据验证模型的预测程度
数据处理工具选择:
1、小数据量,spss比较简单好用,你可以不需要写代码,但是方法原理和结果还是要搞懂
2、中等数据量:sas不错,stat没用过
3、大数据量:Spark或者Hadoop,spark上有一些算法实现,有些算法还是要自己按照spark或者hadoop的变成模型来实现。从传统的算法变为可以在spark和hadoop上可以运行的算法也有很多工作量,需要既懂算法,又懂spark或者hadoop原理。
开发语言选择:
1、工具类,spss和sas都有自己的语言,sas在数据处理上还是很强大
2、开发类:如果只是分析,R和Python都很流行,看个人喜好;如果和程序的集成,相对来说Java更合适,虽然python集成也比较方便。
信用评分与数据挖掘-http://blog.csdn.net/everlasting_188/article/details/52294973
- 信用评分之一---P2P的逾期、坏账与违约定义
为“逾期”正名
所谓逾期,在金融领域是指借款人没有按照约定或承诺的时间点履行还本付息义务所导致的债务延期现象,说白了,就是借了钱,没有在说好的时间还,之前主要应用于银行贷款和信用卡领域。
对银行来说,逾期是指借款方在银行规定的最后还款日或缴息日,未能及时足额还款或缴息的情形。通常出现这种情况,银行会将借款方暂时列为催收对象,并于7日内打电话提醒,借款方如果在7日内补足,银行一般不会收取滞纳金,但如果超过7天仍未缴款,银行就会将这笔贷款正式列为“催收”并收取滞纳金。
信用卡逾期不是指到了最后还款日不还,而是到了下个月账单日不还才算逾期,一旦持卡人逾期,银行会从次日起按每天万分之五计息,逾期会计复利,因此逾期时间越长,每日利息就会越高。
在P2P行业,逾期率并没有一个统一的计算标准,目前使用率比较高的标准出自中国小额信贷联盟P2P行业委员会发布的《个人对个人(P2P)小额信贷信息咨询服务机构行业自律公约》,计算公式是“逾期90天以上的未还剩余资本金总额/可能产生90天+预期累计合同总额”,也就是说,当前已经产生90天以上的逾期,是分子,剩余的有可能产生的90天以上的逾期,是分母,而那些不可能产生90天以上逾期的,则被剔除在分母之外(如那些到期日期至当前不足90天或当前还处于正常借款期内的借款)。
翻阅P2P平台的季报、半年报、年报等信息,我们会发现这类报告格式普遍简洁明了,多以可视化形式展现。其中,披露的内容主要集中于累计成交额、注册用户数、为投资者赚取收益、平均年化收益等可以给平台增光添彩的部分,而对于逾期率、坏账率、营业收入、净利润等指标多有意绕过。目前,会在报告中正规、真实披露相关内容的多为在海外或新三板上市的平台。
除了避而不谈,还有一些平台故意压低逾期率等指标的比例,当然,这其中包括了合理压低与恶意压低两种。合理压低有以下几种方法:1、因为平台上线时间很多,所有借款都未到期,所以对外宣称自己逾期率为零;2、由第三方担保的平台,担保公司代偿的部分不计入逾期率;3、平台抵押类项目,因为有足值抵押物,所以不计入逾期率;4、平台用自有资金或风险拨备把逾期借款换上。恶意压低主要指不合理的扩大逾期率的分母,手段包括:1、将历史以来所有的成交额作为分母;2、将所有待收作为分母,这样逾期率看起来都会很低。
今年3月,当时还未正式挂牌的中国互联网金融协会曾出台一份《互联网金融信息披露规范(初稿)》,其中对P2P从业机构的应披露内容做了要求,其中就包括了累计违约率、平台项目逾期率、近三月项目逾期率、借款逾期金额、代偿金额、借贷逾期率、借贷坏账率等运营信息。6月,上海互金行业协会发布P2P平台信息披露工作指引,要求P2P会员单位定期披露主体、产品、业务、财务和其他等五大类49项信息,其中也包括了交易逾期情况、主要产品90天以上逾期金额和90天以上逾期率。
在此,希望监管层能够尽早对P2P平台逾期率的计算方法和披露方式进行出统一、规范的要求和标准,这将对P2P行业的健康发展起到很大帮助。
坏账与违约
不少分析P2P的文章中,往往将预期与坏账不加分辨或直接等同,这是不对的,实际上两者是有区别的。逾期的意思,上文已经解释,其重要的时间点是超过90天以上,也就是三个月左右。而坏账是在逾期的基础上,在对借款方进行了相关的催收等资产处置工作后,债权人依然无法收回本息,且在今后一段时间内都可能无法收回本息,在P2P行业内,这个时间段是超过120天。所以说,逾期并不意味着坏账。
所谓违约,是指借款方未能按照借款合同上的约定,偿还贷款本息,这是一个覆盖性更广的概念,逾期和坏账,其实都属于违约,因为它们都没有遵守合同上的约定时间还款。两者的区别是,逾期虽然没有遵守还款时间,但是在超过还款期限后的90天-120天这个时间段内还是还了,而坏账则是超过约定还款日期120天后还是没有还款,而且有可能一直不会还了。
转载于: http://blog.csdn.net/everlasting_188/article/details/51768611
- 信用评分之二--信用评分中的评分卡中的A卡、B卡和C卡
A卡(Application score card)申请评分卡
B卡(Behavior score card)行为评分卡
C卡(Collection score card)催收评分卡
评分机制的区别在于:
1.使用的时间不同。分别侧重贷前、贷中、贷后;
2.数据要求不同。A卡一般可做贷款0-1年的信用分析,B卡则是在申请人有了一定行为后,有了较大数据进行的分析,一般为3-5年,C卡则对数据要求更大,需加入催收后客户反应等属性数据。
3.每种评分卡的模型会不一样。在A卡中常用的有逻辑回归,AHP等,而在后面两种卡中,常使用多因素逻辑回归,精度等方面更好。
评分卡是综合个人客户的多个维度信息(如基本情况、偿债能力、信用状况等,重点关注借贷意愿、偿债能力、还款意愿),基于这些信息综合运用数学分析模型,给个人综合评分,判断违约的可能性的工具。
生活中存在许多“显性”或“隐性”的“评分卡”。例如:选购汽车--综合价格、油耗、安全系数、性能、外观等来因素。买还是不买?包括之前小编实习中参与的车联网交通数据清理,如何评价车主是否为“中国好司机”会涉及到车辆是否绿色出行(早晚高峰、周末是否出行),车主的驾驶行为(是否疲劳驾驶、是否夜间驾驶、急加速急转弯百公里次数等)以及月出行次数的合理程度等。
就分析方法发而言,现在分类算法有很多种,决策树,逻辑回归,支持向量机,神经网络等等,都可以实现这个目的。但要明确一点是:数据是决定模型的核心,什么样的数据决定什么样的模型。
转载于: http://blog.csdn.net/everlasting_188/article/details/52084094
- 信用评分之三--逻辑回归中的统计方法
逻辑回归汇总的变量选择
1、 使用所有的变量:这是拟合模型的最简单的方法;
2、 正向选择:这种模型如要如下步骤。第一步,用截距对模型进行拟合,接下来,检验没有纳入模型的变量并选择卡方统计量最大、符合进入条件的变量,这个条件可以通选选项SLE确定。一旦这个变量被纳入模型就不会被移出,重复这个过程知道所有变量纳入。
3、 逆向选择:与正向相反,第一步,使用所有的变量进行拟合,然后,在每一步,移出Wald卡方统计量P值最大的变量,一旦移出,将不会纳入。
4、 stepwise选择:刚开始模型只有截距项,正向选择最优,逆向选择最差,通过SLE和SLS的值控制纳入和移出模型变量的p值。
5、 得分最有统计模型:最优得分法与stepwise方法相似,但是使用分支界定算法找出木偶性的分数统计量最高变量的子集,从而找出最优解。
相关方法
MLE极大似然估计
极大似然原理的直观想法是:一个随机试验如有若干个可能的结果A,B,C,…。若在仅仅作一次试验中,结果A出现,则一般认为试验条件对A出现有利,也即A出现的概率很大。一般地,事件A发生的概率与参数a相关,A发生的概率记为P(A,a),则a的估计应该使上述概率达到最大,这样的a顾名思义称为极大似然估计。
极大似然估计是能沟通通过模型以最大概率在线样本观察数据,逻辑回归模型主要使用极大似然法来进行估计
SLE
sas中在变量选举进入的参数,SLE(sets criterion for entry into model) 是变量进入模型的标准即统计意义水平值P<0.3,是定逻辑回归中变量纳入的主要条件。
SLS
sas中在变量选举进入的参数,SLS(sets criterion for staying in model)是变量在模型中保留的标准即统计意义水平值P<0.3,是定逻辑回归中变量保留的主要条件。逻辑回归变量进入后,因为新的变量进入导致老的变量对整个模型的贡献不足,从中移出的阀值。
卡方校验
原理
卡方检验就是统计样本的实际观测值与理论推断值之间的偏离程度,实际观测值与理论推断值之间的偏离程度就决定卡方值的大小,卡方值越大,越不符合;卡方值越小,偏差越小,越趋于符合,若两个值完全相等时,卡方值就为0,表明理论值完全符合。
卡方检验的两个应用是拟合性检验和独立性检验。拟合性检验是用于分析实际次数与理论次数是否相同,适用于单个因素分类的计数数据。独立性检验用于分析各有多项分类的两个或两个以上的因素之间是否有关联或是否独立的问题。
应用场景
卡方校验的场景
1.应用实例——适合度检验
实际执行多项式试验而得到的观察次数,与虚无假设的期望次数相比较,称为卡方适度检验,即在于检验二者接近的程度,利用样本数据以检验总体分布是否为某一特定分布的统计方法。
2.应用实例2——独立性检验
卡方独立性检验是用来检验两个属性间是否独立。一个变量作为行,另一个变量作为列。
3.应用实例3——统一性检验
检验两个或两个以上总体的某一特性分布,也就是各“类别”的比例是否统一或相近,一般称为卡方统一性检验或者卡方同质性检验。
具体参考例子
见文档:http://wiki.mbalib.com/wiki/%E5%8D%A1%E6%96%B9%E6%A3%80%E9%AA%8C
卡方分布与皮尔逊卡方检验的关系
摘录自知乎,总结的比较到位
我们知道,从正态分布里随机抽取n个值的平方的和构成了自由度为n-1的卡方分布,在使用卡方分布表进行假设检验时,我们需要用样本方差除总体方差进行标准化。现在的问题是使用皮尔逊卡方检验的时候,为什么用的不是总体方差进行标准化,而是使用理论频数进行标准化?
理论证明,实际观察次数(fo)与理论次数(fe),又称期望次数)之差的平方再除以理论次数所得的统计量,近似服从卡方分布。所以用理论次数标准化
模型选择的几种方法:AIC,BIC,HQ准则
引用:http://blog.csdn.net/xianlingmao/article/details/7891277
经常地,对一堆数据进行建模的时候,特别是分类和回归模型,我们有很多的变量可供使用,选择不同的变量组合可以得到不同的模型,例如我们有5个变量,2的5次方,我们将有32个变量组合,可以训练出32个模型。但是哪个模型更加的好呢?目前常用有如下方法:
AIC=-2 ln(L) + 2 k 中文名字:赤池信息量 akaike information criterion
BIC=-2 ln(L) + ln(n)*k 中文名字:贝叶斯信息量 bayesian information criterion
HQ=-2 ln(L) + ln(ln(n))*k hannan-quinn criterion
其中L是在该模型下的最大似然,n是数据数量,k是模型的变量个数。
注意这些规则只是刻画了用某个模型之后相对“真实模型”的信息损失【因为不知道真正的模型是什么样子,所以训练得到的所有模型都只是真实模型的一个近似模型】,所以用这些规则不能说明某个模型的精确度,即三个模型A, B, C,在通过这些规则计算后,我们知道B模型是三个模型中最好的,但是不能保证B这个模型就能够很好地刻画数据,因为很有可能这三个模型都是非常糟糕的,B只是烂苹果中的相对好的苹果而已。
这些规则理论上是比较漂亮的,但是实际在模型选择中应用起来还是有些困难的,例如上面我们说了5个变量就有32个变量组合,如果是10个变量呢?2的10次方,我们不可能对所有这些模型进行一一验证AIC, BIC,HQ规则来选择模型,工作量太大。
总结
逻辑回归比较复杂,推荐《Logistic回归模型——方法与应用》王济川郭志刚著,这本书不错
转载于: http://blog.csdn.net/everlasting_188/article/details/51603530
- 信用评分之四--What Is a Hard Inquiry?(Fico信用查询之“硬查询”)
您或许听说过一次硬查询可能使您的信用记录受影响。但是您可能并不知道这到底是为什么,到底什么是硬查询?
(因审核贷款业务申请原因而查询信用报告叫硬查询。如贷款审批、信用卡审批。)
理解硬查询如何进行至关重要:通过低息贷款购物可以为您省钱。但是如果您忘了按时还款,很可能会在信用查询时为您的信用减分,使您之后的借款利率升高。对于类似车贷、房贷这样的大额贷款来说,哪怕信用分只降了一点,都意味着贷款人将支付更高的利率,进而导致您在还贷期支付更多的利息。所以避免不必要的违约其实是为自己省钱。
在您查询信用信息时,会标注在贷款人信用报告里。比如说您申请一项汽车贷款,借款方通过Experian征信公司调用了您的信息记录和FICO分数。“您的信用信息被一家特定公司使用了”这一记录将记录在您的Experian公司报告中,标注了索取报告的公司名以及查询的方式。
在我们谈论硬查询如何工作的细节之前,宏观的判断很重要。除非您真的是一个重度刷卡消费者(不止是一时使用),硬查询不会对您的信用分造成多大的影响。“建立新的信用账户”占到您FICO信用评分的10%,查询只是这类中的一部分。所以单次查询不会使您的信用分降低5分以上,但这只是在硬查询时,而且有一些限制条件。
另外,这样的一次询价将在您的信用记录上保留两年,但是只有一年内的记录会对您的FICO信用分产生影响,至少现在大部分评分模型是这样设计的。而过久的查询记录早已被忽略。
硬查询 VS. 软查询
硬查询是那些会影响您信用评分的查询行为,他们表明您正在积极地获取信用额度,不管是车贷、抵押、学生贷款还是信用卡贷款。
恰恰相反,软查询并不是为使用信用卡或贷款购物而发生,不会影响您的信用评分。比如说,如果一个借款人给您发来一个预授权的信用额度,这样的查询被称为“奖励”查询,是一种软查询。这时当您查询自己的信用评分时,也会被定义为软查询。类似的,如果您已经持有一张信用卡或者得到一笔贷款,征信公司将不定期地查询您的账户,而这种查询将不会记录在您的信用报告中。
雇主或者保险公司出于对您信用分数的计算目的而进行的查询也不会被记录。
避免信用损失
有几种方式来最小化您因为硬查询而导致的个人信用损失。
做好决定再出手:正在寻找一份按揭贷款,车贷,或是学生贷款?请在两周的时间内完成所有消费。这样的话,所有申请仅算作一次查询。因为大部分信用评分模型会把14到45天内的查询行为统一视为一次(具体时间取决于被使用的是哪种模型)。
时刻监控您的信用账户:在您要使用信用消费之前检查一下您的信用报告和信用评分。然后做些功课,申请您最有可能得到的贷款额。通过Credit.com的免费信用报告卡,您能每月免费查看您的信用分数。在查看期间,我们会根据您的个人信用档案和信用评分为您推荐适合您的信用卡和贷款项目,您帮助您省钱。
谁在访问我的信用账户
您阅览您的信用报告时,您会看到一个查询清单,但是您不会看到清单中的公司名字。首先确定这些查询是不是奖励询价。如果是,那么您很可能是得到了一个预授权的信用贷款,请不要担心(您可以在OptOutPrescreen.com网站上拒绝预授权)。如果不是这种情况,那么公司的联系方式一定会显示在清单上,所以您能够联系到他们。如果这些信息没有被提供,可以请信用报告代理商帮您取得。
转载于: http://blog.csdn.net/everlasting_188/article/details/51706312
- 信用评分之五--并行逻辑回归
逻辑回归(Logistic Regression,简称LR)是机器学习中十分常用的一种分类算法,在互联网领域得到了广泛的应用,无论是在广告系统中进行CTR预估,推荐系统中的预估转换率,反垃圾系统中的识别垃圾内容……都可以看到它的身影。LR以其简单的原理和应用的普适性受到了广大应用者的青睐。实际情况中,由于受到单机处理能力和效率的限制,在利用大规模样本数据进行训练的时候往往需要将求解LR问题的过程进行并行化,本文从并行化的角度讨论LR的实现。
1. LR的基本原理和求解方法
LR模型中,通过特征权重向量对特征向量的不同维度上的取值进行加权,并用逻辑函数将其压缩到0~1的范围,作为该样本为正样本的概率。逻辑函数为 ,曲线如图1。
,曲线如图1。
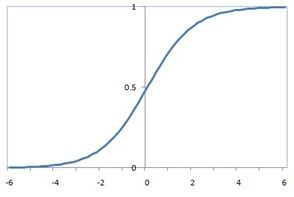
图1 逻辑函数曲线
给定M个训练样本并行逻辑回归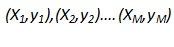 ,其中Xj={xji|i=1,2,…N} 为N维的实数向量(特征向量,本文中所有向量不作说明都为列向量);yj取值为+1或-1,为分类标签,+1表示样本为正样本,-1表示样本为负样本。在LR模型中,第j个样本为正样本的概率是:
,其中Xj={xji|i=1,2,…N} 为N维的实数向量(特征向量,本文中所有向量不作说明都为列向量);yj取值为+1或-1,为分类标签,+1表示样本为正样本,-1表示样本为负样本。在LR模型中,第j个样本为正样本的概率是:
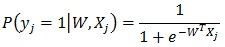 其中W是N维的特征权重向量,也就是LR问题中要求解的模型参数。
其中W是N维的特征权重向量,也就是LR问题中要求解的模型参数。
求解LR问题,就是寻找一个合适的特征权重向量W,使得对于训练集里面的正样本, 并行逻辑回归值尽量大;对于训练集里面的负样本,这个值尽量小(或
并行逻辑回归值尽量大;对于训练集里面的负样本,这个值尽量小(或 并行逻辑回归尽量大)。用联合概率来表示:
并行逻辑回归尽量大)。用联合概率来表示:

对上式求log并取负号,则等价于:
 公式(1)
公式(1)
公式(1)就是LR求解的目标函数。
寻找合适的W令目标函数f(W)最小,是一个无约束最优化问题,解决这个问题的通用做法是随机给定一个初始的W0,通过迭代,在每次迭代中计算目标函数的下降方向并更新W,直到目标函数稳定在最小的点。如图2所示。
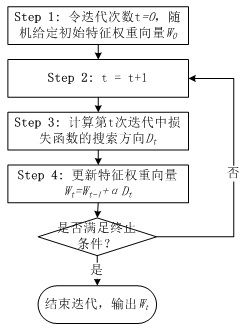
图2 求解最优化目标函数的基本步骤
不同的优化算法的区别就在于目标函数下降方向Dt的计算。下降方向是通过对目标函数在当前的W下求一阶倒数(梯度,Gradient)和求二阶导数(海森矩阵,Hessian Matrix)得到。常见的算法有梯度下降法、牛顿法、拟牛顿法。
(1) 梯度下降法(Gradient Descent)
梯度下降法直接采用目标函数在当前W的梯度的反方向作为下降方向:

其中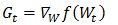 并行逻辑回归为目标函数的梯度,计算方法为:
并行逻辑回归为目标函数的梯度,计算方法为:

(2) 牛顿法(Newton Methods)
牛顿法是在当前W下,利用二次泰勒展开近似目标函数,然后利用该近似函数来求解目标函数的下降方向:

其中Bt为目标函数f(W)在Wt处的海森矩阵。这个搜索方向也称作牛顿方向。
(3) 拟牛顿法(Quasi-Newton Methods):
拟牛顿法只要求每一步迭代中计算目标函数的梯度,通过拟合的方式找到一个近似的海森矩阵用于计算牛顿方向。最早的拟牛顿法是DFP(1959年由W. C. Davidon提出,并由R. Fletcher和M. J. D. Powell进行完善)。DFP继承了牛顿法收敛速度快的优点,并且避免了牛顿法中每次迭代都需要重新计算海森矩阵的问题,只需要利用梯度更新上一次迭代得到的海森矩阵,但缺点是每次迭代中都需要计算海森矩阵的逆,才能得到牛顿方向。
BFGS是由C. G. Broyden, R. Fletcher, D. Goldfarb和D. F. Shanno各自独立发明的一种方法,只需要增量计算海森矩阵的逆Ht=Bt-1,避免了每次迭代中的矩阵求逆运算。BFGS中牛顿方向表示为
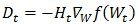
L-BFGS(Limited-memory BFGS)则是解决了BFGS中每次迭代后都需要保存N*N阶海森逆矩阵的问题,只需要保存每次迭代的两组向量和一组标量即可:

在L-BFGS的第t次迭代中,只需要两步循环既可以增量计算牛顿方向:

2. 并行LR的实现
由逻辑回归问题的求解方法中可以看出,无论是梯度下降法、牛顿法、拟牛顿法,计算梯度都是其最基本的步骤,并且L-BFGS通过两步循环计算牛顿方向的方法,避免了计算海森矩阵。因此逻辑回归的并行化最主要的就是对目标函数梯度计算的并行化。从公式(2)中可以看出,目标函数的梯度向量计算中只需要进行向量间的点乘和相加,可以很容易将每个迭代过程拆分成相互独立的计算步骤,由不同的节点进行独立计算,然后归并计算结果。
将M个样本的标签构成一个M维的标签向量,M个N维特征向量构成一个M*N的样本矩阵,如图3所示。其中特征矩阵每一行为一个特征向量(M行),列为特征维度(N列)。
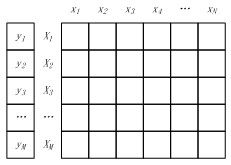
图3 样本标签向量 & 样本矩阵
如果将样本矩阵按行划分,将样本特征向量分布到不同的计算节点,由各计算节点完成自己所负责样本的点乘与求和计算,然后将计算结果进行归并,则实现了“按行并行的LR”。按行并行的LR解决了样本数量的问题,但是实际情况中会存在针对高维特征向量进行逻辑回归的场景(如广告系统中的特征维度高达上亿),仅仅按行进行并行处理,无法满足这类场景的需求,因此还需要按列将高维的特征向量拆分成若干小的向量进行求解。
(1) 数据分割
假设所有计算节点排列成m行n列(m*n个计算节点),按行将样本进行划分,每个计算节点分配M/m个样本特征向量和分类标签;按列对特征向量进行切分,每个节点上的特征向量分配N/n维特征。如图4所示,同一样本的特征对应节点的行号相同,不同样本相同维度的特征对应节点的列号相同。
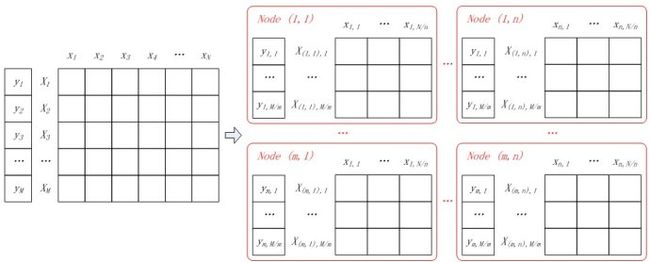
图4 并行LR中的数据分割
一个样本的特征向量被拆分到同一行不同列的节点中,即:
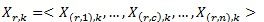
其中Xr,k表示第r行的第k个向量,X(r,c),k表示Xr,k在第c列节点上的分量。同样的,用Wc表示特征向量W在第c列节点上的分量,即:

(2) 并行计算
观察目标函数的梯度计算公式(公式(2)),其依赖于两个计算结果:特征权重向量Wt和特征向量Xj的点乘,标量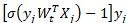 和特征向量Xj的相乘。可以将目标函数的梯度计算分成两个并行化计算步骤和两个结果归并步骤
和特征向量Xj的相乘。可以将目标函数的梯度计算分成两个并行化计算步骤和两个结果归并步骤
① 各节点并行计算点乘,计算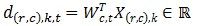 并行逻辑回归,其中k=1,2,…,M/m,d(r,c),k,t表示第t次迭代中节点(r,c)上的第k个特征向量与特征权重分量的点乘,Wc,t为第t次迭代中特征权重向量在第c列节点上的分量。
并行逻辑回归,其中k=1,2,…,M/m,d(r,c),k,t表示第t次迭代中节点(r,c)上的第k个特征向量与特征权重分量的点乘,Wc,t为第t次迭代中特征权重向量在第c列节点上的分量。
② 对行号相同的节点归并点乘结果

计算得到的点乘结果需要返回到该行所有计算节点中,如图5所示。
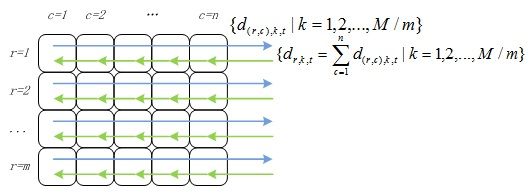
图5 点乘结果归并
③ 各节点独立算标量与特征向量相乘
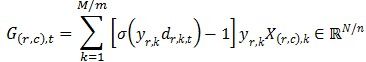
G(r,c),t可以理解为由第r行节点上部分样本计算出的目标函数梯度向量在第c列节点上的分量。
④ 对列号相同的节点进行归并:
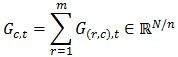
Gc,t就是目标函数的梯度向量Gt在第c列节点上的分量,对其进行归并得到目标函数的梯度向量:
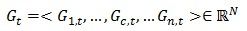
这个过程如图6所示。

综合上述步骤,并行LR的计算流程如图7所示。比较图2和图7,并行LR实际上就是在求解损失函数最优解的过程中,针对寻找损失函数下降方向中的梯度方向计算作了并行化处理,而在利用梯度确定下降方向的过程中也可以采用并行化(如L-BFGS中的两步循环法求牛顿方向)
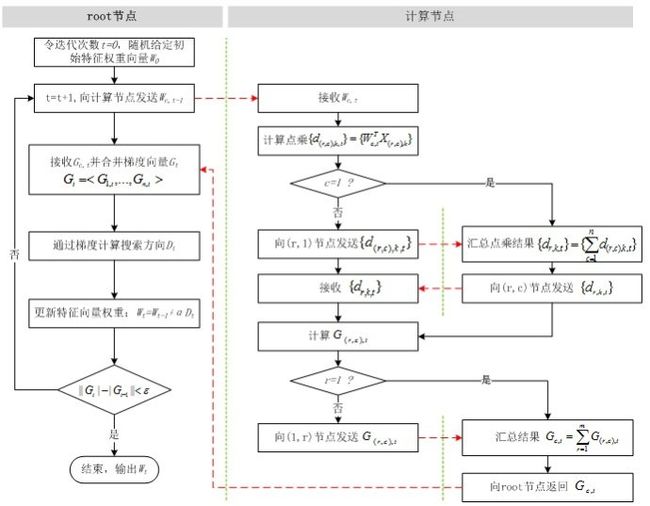
3. 实验及结果
利用MPI,分别基于梯度下降法(MPI_GD)和L-BFGS(MPI_L-BFGS)实现并行LR,以Liblinear为基准,比较三种方法的训练效率。Liblinear是一个开源库,其中包括了基于TRON的LR(Liblinear的开发者Chih-Jen Lin于1999年创建了TRON方法,并且在论文中展示单机情况下TRON比L-BFGS效率更高)。由于Liblinear并没有实现并行化(事实上是可以加以改造的),实验在单机上进行,MPI_GD和MPI_L-BFGS均采用10个进程。
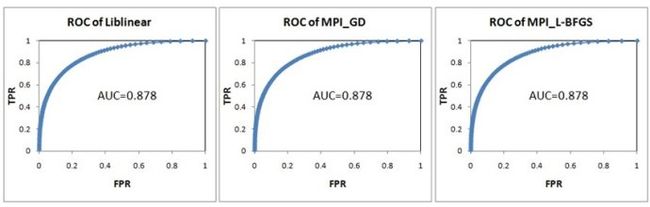
实验数据是200万条训练样本,特征向量的维度为2000,正负样本的比例为3:7。采用十折交叉法比较MPI_GD、MPI_L-BFGS以及Liblinear的分类效果。结果如图8所示,三者几乎没有区别。
将训练数据由10万逐渐增加到200万,比较三种方法的训练耗时,结果如图9,MPI_GD由于收敛速度慢,尽管采用10个进程,单机上的表现依旧弱于Liblinear,基本上都需要30轮左右的迭代才能达到收敛;MPI_L-BFGS则只需要3~5轮迭代即可收敛(与Liblinear接近),虽然每轮迭代需要额外的开销计算牛顿方向,其收敛速度也要远远快于MPI_GD,另外由于采用多进程并行处理,耗时也远低于Liblinear。
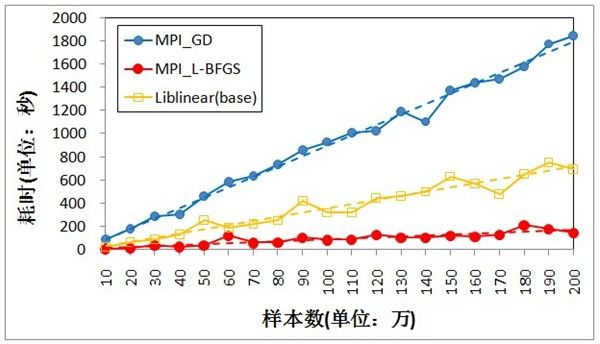
图9 训练耗时对比
转载于: http://blog.sina.com.cn/s/blog_6cb8e53d0101oetv.html
- 信用评分之六--逻辑回归模型梯度下降法跟牛顿法比较
1、综述
机器学习的优化问题中,梯度下降法和牛顿法是常用的两种凸函数求极值的方法,他们都是为了求得目标函数的近似解。梯度下降的目的是直接求解目标函数极小值,而牛顿法则变相地通过求解目标函数一阶导为零的参数值,进而求得目标函数最小值。在逻辑回归模型的参数求解中,一般用改良的梯度下降法,也可以用牛顿法。
2 梯度下降法
2.1算法描述
1、确定误差范围和下降的步长,确定函数的导函数
2、while(|新值 -旧值| >误差)
3、 旧值=新值
4、 新值=初始值-步长*导函数值,来进行梯度下降
算法的一些问题:每一步走的距离在极值点附近非常重要,如果走的步子过大,容易在极值点附近震荡而无法收敛。解决办法:将alpha设定为随着迭代次数而不断减小的变量,但太小会导致迭代次数很多。
2.2、java代码示例
代码转自:http://www.lailook.net/klxx/04/2016-01-05/51426.html
[java] view plain copy
- /**
- * 梯度下降算法,求解 f(x)=x^4-3x^3+2 最小值
- * 导数为: f'(x)=4x^3-9x^2
- * @author Zealot
- * @date 2015年12月13日
- */
- public class GradientDescent {
- // 经过计算, we expect that the local minimum occurs at x=9/4
- double x_old = 0;
- static double x_new = 6; // 从 x=6 开始迭代
- double gamma = 0.01; // 每次迭代的步长
- double precision = 0.00001;//误差
- static int iter = 0;//迭代次数
- //目标函数的导数
- private double derivative(double x) {
- return 4 * Math.pow(x, 3) - 9 *Math.pow(x, 2);
- }
- private void getmin() {
- while (Math.abs(x_new - x_old) > precision){
- iter++;
- x_old = x_new;
- x_new = x_old - gamma * derivative(x_old);
- }
- }
- public static void main(String[] args) {
- GradientDescent gd = new GradientDescent();
- gd.getmin();
- System.out.println(iter+": "+x_new);
- }
- }
3、牛顿法
3.1算法描述
求解f(x)=0,如果f(x)可导,等价为迭代x = x-f(x)/f'(x)的最小值,算法如下:
输入:初始值x0,误差荣制TOL;最大迭代次数m
输入: 近似解p或者失败信息
1、 p0=x0
2、while (小于迭代次数)
3、 p= p0-f(p0)/f'(p0)
4、 若|p-p0|3.2例子

4、参考文档
机器学习中梯度下降法跟牛顿法的比较
http://www.myexception.cn/cloud/1987100.html
梯度下降法(一)入门
http://blog.csdn.NET/nupt123456789/article/details/8281923
Java实现梯度下降算法
http://blog.csdn.Net/nupt123456789/article/details/8281923
梯度下降、牛顿法、拟牛顿法
http://blog.csdn.net/luo86106/article/details/40510383
讲解更深入和详细的如下:
梯度下降法与牛顿法的解释与对比
http://www.cnblogs.com/happylion/p/4172632.html
牛顿法、雅克比矩阵、海森矩阵
http://blog.csdn.net/ubunfans/article/details/41520047
4、参考文档
机器学习中梯度下降法跟牛顿法的比较
http://www.myexception.cn/cloud/1987100.html
梯度下降法(一)入门
http://blog.csdn.NET/nupt123456789/article/details/8281923
Java实现梯度下降算法
http://blog.csdn.Net/nupt123456789/article/details/8281923
梯度下降、牛顿法、拟牛顿法
http://blog.csdn.net/luo86106/article/details/40510383
讲解更深入和详细的如下:
梯度下降法与牛顿法的解释与对比
http://www.cnblogs.com/happylion/p/4172632.html
牛顿法、雅克比矩阵、海森矩阵
http://blog.csdn.net/ubunfans/article/details/41520047
- 信用评分之七--逻辑回归中的虚拟变量设置
系列文章收集在比特币与互联网金融风控专栏中
虚拟变量定义
在实际建模过程中,被解释变量不但受定量变量影响,同时还受定性变量影响。例如需要考虑性别、民族、不同历史时期、季节差异、企业所有制性质不同等因素的影响。这些因素也应该包括在模型中。
由于定性变量通常表示的是某种特征的有和无,所以量化方法可采用取值为1或0。这种变量称作虚拟变量,用D表示。虚拟变量应用于模型中,对其回归系数的估计与检验方法与定量变量相同。
虚拟变量对模型的意义
通常,我们假设的因变量与自变量之间的关系既是线性的,又是可以叠加,如果这些假设条件被违背,参数估计将发生偏差。
将连续变量分成不同组表并用一套虚拟变量来表达,这不仅有助于检查这一变量的非线性模式,还提供在非线性关系存在条件下的无偏参数估计,这实际上是在建立回归模型时对方非线性关系的一个常用的方法。
如何设置虚拟变量
虚拟变量通常是对无序分类资料而言。在线性回归中,如果自变量中有分类变量,那么一定要事先把这些分类变量事先重新编码,生成多个二分类虚拟变量。
在模型中引入多个虚拟变量时,虚拟变量的个数应按下列原则确定:
(1)如果回归模型有截距项
有m种互斥的属性类型,在模型中引入(m-1)个虚拟变量。
(2)如果回归模型无截距项,有m个特征,设置m个虚拟变量
虚拟变量在计算广告和信用评分中很常用。
人大经济论坛这个例子讲的非常好
http://bbs.pinggu.org/thread-3702024-1-1.html
假如现有4个省份,分别是山西,山西,江苏,江西,要纳入到模型中。
理解虚拟变量的真正含义:是要体现出不同省份之间的差异,而并不是所谓的控制变量。而其要充分理解多元线性回归当中参数估计量的真正含义:是偏回归系数,即自变量的边际量,表明了在其他条件不变的情况下,自变量每增加一个单位因变量的变化。
如果按照你的理解假设X为地区变量,X的取值为1代表山西;2代表陕西;3代表江苏;4代表江西,那么回归完了以后如何来解释X前面的参数:X前面的参数表示X每增加一个单位因变量增加多少,而此时按照X的取值,陕西和山西之间相差一个单位,陕西和江苏之间也是差一个单位、江苏和江西之间也差一个单位,那么这个系数究竟是说明陕西和山西之间的差别呢?还是陕西和江苏还是江苏和江西之间的差别呢?这显然无法解释。还有X前面的回归参数是一个常数,那么就是说陕西和山西、陕西和江苏、江苏和江西之间因变量的差异是相同的,这显然是不合理的。
要把四个省份用数值区分开来,用1,2,3,4呢?那用10,20,30,40也可以,那样的话参数估计量就更没法解释。所以,虚拟变量的定义一定是按照1和0来定义,即是就等于1,不是就等于0,比如,假设模型中有常数项,那么可以定义3个虚拟变量,D1为陕西(是陕西D1=1,不是陕西D1=0);D2为江苏(是江苏D2=1,不是江苏D2=0);D3为江西(是江西D3=1,不是江西D3=0),那么山西呢?如果D1,D2,D3都同时为0,肯定就是山西了,这样回归之后D1前面的参数表明了陕西与山之间的差别;D2前面的参数表明了江苏与山西之间的差异;D3前面的参数表明了江西与山西之间的差异,参数的经济意义非常明确。从深层次上讲虚拟变量模型实际上是解决了方差分析只能说明不同省份之间有无差异,而不能说明不同省份之间的这种差异究竟有多大的问题。
spss中设置虚拟变量
http://cos.name/cn/topic/306/
摘要
如果自变量是多分类的,如果数据类型是(ordinal)整序变量,则不用设置哑变量,如果是多分类名义变量(观测类型是norminal)则必须设置哑变量,SPSS会自动设置,但具体设置也可以自己选择,一般默认的情况下,是以最后一个组为对照组。
ordinal的时候,和nomial会有比较大的不同的处理方式,可以参考专门讲ordinal变量分析的资料,或者logistic方面的资料,总之要谨慎使用。
转载于: http://blog.csdn.net/everlasting_188/article/details/52124041