2019独角兽企业重金招聘Python工程师标准>>> 
背景:
读取一个500w行的大文件,将每一行的数据读取出来做数据整合归并之后,再按照一定的逻辑和算法进行处理后存入redis。
文件格式:
url地址 用户32位标识 点击次数
http://jingpin.pgc.panda.tv/hd/xiaopianpian.html aaaaaaaaaaaaaaaaaaaa 5
具体场景:
本节先看一下大文件处理最简单的情况,即在读文件的过程中针对文件每一行都开启一个协程来做数据合并,看看这种情况下的定位以及优化的思路。
问题现象:
如果将整个文件串行执行来做数据整合的话,只需要4 or 5s就可以完成,但是每行并发处理却需要几十秒到几十分钟不等。
代码如下:
simple.go
package main
import (
"bufio"
"fmt"
"io"
"io/ioutil"
"log"
"net/http"
_ "net/http/pprof"
"os"
"singleflight"
"strconv"
"strings"
"sync"
"time"
"utils"
)
var (
wg sync.WaitGroup
mu sync.RWMutex //全局锁
single = &singleflight.Task{}
)
func main() {
defer func() {
if err := recover(); err != nil {
fmt.Println(err)
}
}()
go func() {
log.Println(http.ListenAndServe("localhost:8080", nil))
}()
file := "/data/origin_data/part-r-00000"
if fp, err := os.Open(file); err != nil {
panic(err)
} else {
start := time.Now()
defer fp.Close()
defer func() { //时间消耗
fmt.Println("time cost:", time.Now().Sub(start))
}()
//统计下每个url的点击用户数
hostNums := hostsStat()
buf := bufio.NewReader(fp)
hostToFans := make(map[string]utils.MidList) //[url][]用户id
for {
line, err := buf.ReadString('\n')
if err != nil {
if err == io.EOF { //遭遇行尾
fmt.Println("meet the end")
break //跳出死循环
}
panic(err)
}
//每一行单独处理
wg.Add(1)
go handleLine(line, hostToFans, hostNums)
}
wg.Wait()
fmt.Println("*************************handle file data complete************************")
}
}
//处理每一行的数据
func handleLine(line string, hostToFans map[string]utils.MidList, hostNums map[string]int) {
defer wg.Done()
line = strings.TrimSpace(line)
components := strings.Split(line, "\t")
//先判断是否是合法网站的url
schemes := strings.Split(components[0], "/")
if utils.In_array(utils.ValidPlatforms, schemes[2]) == false {
fmt.Println("invalid url: ", components[0])
return
}
mu.RLock()
if _, ok := hostToFans[components[0]]; ok {
mu.RUnlock()
click_times, _ := strconv.Atoi(components[2])
mu.Lock()
hostToFans[components[0]] = hostToFans[components[0]].Append(components[1], click_times)
mu.Unlock()
} else { //下一个url
mu.RUnlock()
startElement := false //用以标识是否是某个url统计的初始元素
//singleflight代码 防止有多个相同url同时访问时,该url对应的[]string还没有初始化,导致多次make代码的执行
single.Do(components[0], func() (interface{}, error) {
mu.RLock()
if _, ok := hostToFans[components[0]]; ok { //再判断一遍, 防止高并发的情形下,多个相同url的写map操作,都会进入重新分配空间的步骤
mu.RUnlock()
return nil, nil
}
mu.RUnlock()
mu.Lock()
click_times, _ := strconv.Atoi(components[2])
hostToFans[components[0]] = utils.NewMidList(hostNums[components[0]])
hostToFans[components[0]] = hostToFans[components[0]].Append(components[1], click_times)
mu.Unlock()
startElement = true
return nil, nil
})
if !startElement {
mu.Lock()
click_times, _ := strconv.Atoi(components[2])
hostToFans[components[0]] = hostToFans[components[0]].Append(components[1], click_times)
mu.Unlock()
}
}
}
//针对url:用户的统计文件 该文件列出每个url对应的独立用户个数
func hostsStat() map[string]int {
hostStats := "./scripts/data/stat.txt"
bytes, _ := ioutil.ReadFile(hostStats)
//....some code....
return hostNums
}
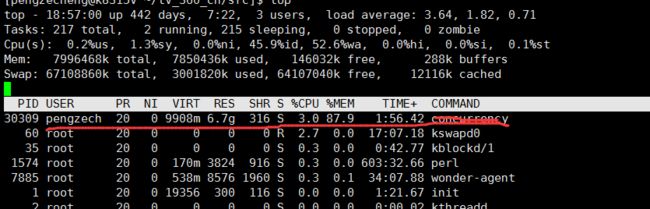
执行一下这个代码之后,发现程序执行不久,内存占用就噌噌噌的涨到90%+,过了一会cpu占用下降到极低,但是load一直保持再过载的水平,看下图。所以大胆猜测因为gc导致进程夯住了。之后用pprof和gctrace也印证了这个想法,如果对pprof和gctrace不太清楚的同学可以看笔者之前的文章 golang 如何排查和定位GC问题。
其实在笔者最开始的代码中,已经有一些地方在注意降低内存的消耗了,比如说在初始化每个url对应的用户id集合时借鉴groupcache的singleflight,确保不会多次重复申请空间;比如url对应的用户id切片,先算好具体大小再make。虽然代码很简单, 但是上文中的代码显然还是有一些问题。
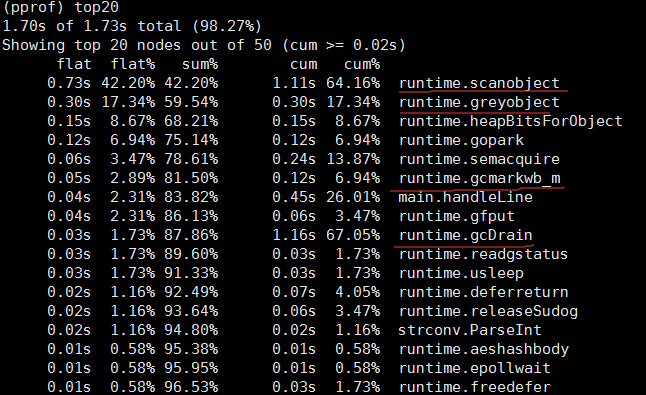
通过pprof,我发现程序执行的过程中,大部分时间都消耗在gc上,如下图。划红线的都是和gc有关的函数。所以问题就变成排查为什么gc会这么长时间。
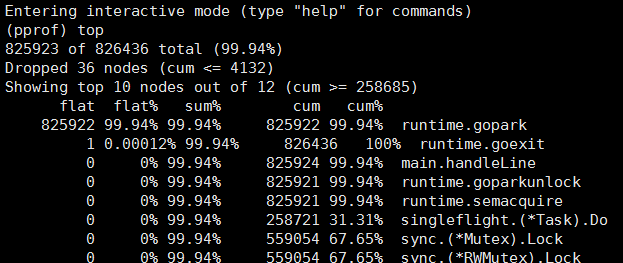
大部分情况下gc被导致的原因是分配的内存达到某个阈值,很显然,本例属于这种情况,前文提到内存占用稳定在90+。那么为什么这个进程会占用这么多的内存呢?笔者一直试图用pprof的heap和profile来分析出这个问题,但是一直无果。直到有一次通过pprof查看goroutine的状态时,发现当前正在工作的协程高达几十万,甚至有时能到达接近150w的量级, 如下图。这样就能够解释一部分问题了,单个协程如果是3K大小,那么当协程数量到达百万时,就算协程里什么都没有也会占用4G的内存。而笔者在做实验的机器只有8g的内存,所以肯定会出现内存被吃满频繁gc导致进程夯住。
所以第一步,肯定是要控制一下当前的协程数,不能无限的增长。在读取文本内容的loop里,加上对行数的计算,这样每到一个阈值时,就可以休息一下,暂缓下协程增长的速率。加上限制之后,进程不会再卡死,整个的执行时间稳定在20~30s之间。
iterator := 0
for {
line, err := buf.ReadString('\n')
if err != nil {
if err == io.EOF { //遭遇行尾
fmt.Println("meet the end")
break //跳出死循环
}
panic(err)
}
//每一行单独处理 这里需要加逻辑防止并发过大导致大量占用cpu和内存,使得整个进程因为gc夯住,
//可以每读10w行左右就休息一会降低一下程序同时在线的协程
iterator++
if iterator <= 120000 {
wg.Add(1)
go handleLine(line, hostToFans, hostNums)
} else {
iterator = 1
<-time.After(130 * time.Millisecond) //暂停需要5s左右
wg.Add(1)
go handleLine(line, hostToFans, hostNums)
}
}
wg.Wait()对比一下串行执行的结果,可以发现虽然现在并发执行已经稳定,但是就算刨去休眠时间,和串行执行相比还是慢很多,所以肯定还有优化的空间。这个时候pprof的profile以及heap分析就有了施展拳脚的地方了。看下面两张图,分别是内存消耗和cpu消耗图:
cpu耗时分析
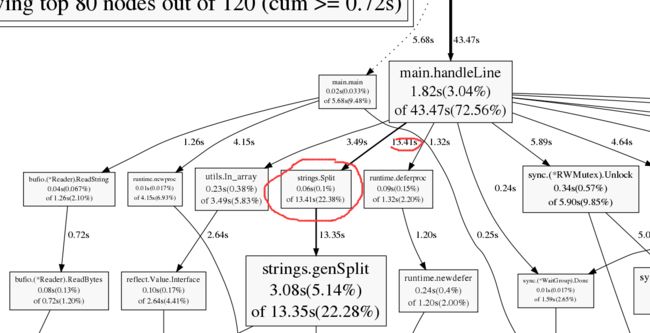
内存占用分析
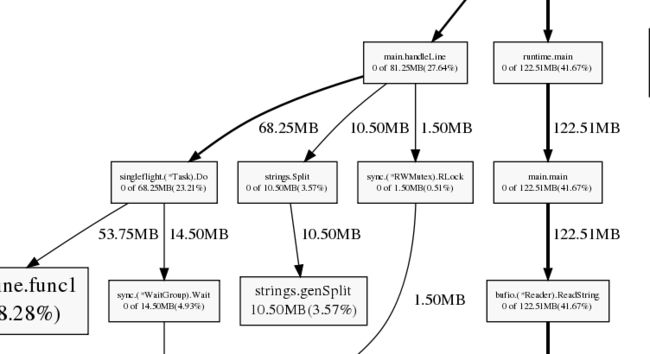
上面只截取了一部分的图,但是从中我们已经能够找到需要优化的地方了。可以看到strings.Split函数耗时和耗内存都很严重,主要是它会生成slice。分析一下前文的代码可以发现至少判断url是否是合法网站这一块的strings.Split是可以不要的。这里不光会有额外的运行时间还会生成slice占用内存导致gc。所以对这块功能进行改造:
//先判断是否是合法平台的主播
if is_valid_platform(utils.ValidPlatforms, components[0]) == false {
fmt.Println("invalid url: ", components[0])
return nil, errors.New("invalid url")
}
func is_valid_platform(platforms []string, hostUrl string) bool {
for _, platform := range platforms {
if strings.Index(hostUrl, platform) != -1 {
return true
}
}
return false
}这样的就可以减少不必要的slice引起的分配空间。改完之后再执行,整个任务稳定在15s左右,减去休眠时间的话就是10s。到这里其实已经算是优化的差不多了,但是其实还有一个地方可以看一下。
上面的heap分析图可以看到其实singleflight.(*Task).Do函数占用更多的内存,并且也占用了很多的cpu时间,如下:
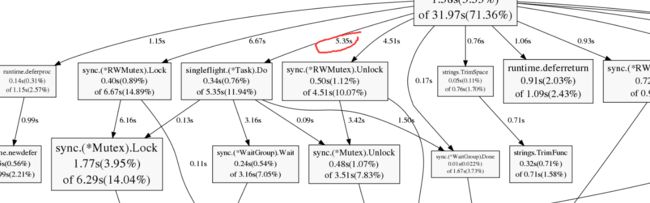
除了一些原生函数之外,就属它最高了,而且该函数也只会在每次新的url出现的时候才会执行。可以看下singleflight的主要结构体,会发现使用了指针变量,而指针变量在gc的时候会导致二次遍历,使得整个gc变慢。虽然笔者此处用的singleflight肯定是不能修改, 但是如果有可能的话,尽量还是要少用指针。
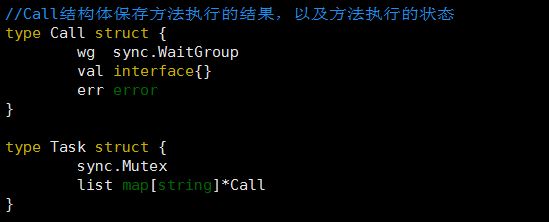
这一节只能算是简单讲了下优化的思路和过程,希望下一节能把完整版的优化方案写出来。