毕业论文——知识总结
注意事项: 该部分内容来自于自己的研究生论文,
目录
1 slam分类
2 常见传感器的优缺点:
声纳传感器、激光传感器、红外传感器、惯性导航传感器、GPS
3 路径规划算法整理
图搜索算法:
Dijkstra算法
A*算法原理:
A*算法总结:
D*算法实现:
LPA*算法
D* Lite算法
ARA*
参考文献、来源、参考网址
局部路径规划
人工势场模型、动态窗口法(DWA)、弹性带法(Elastic Bands)、模糊逻辑算法、强化学习算法,
4 深度学习网络
图像领域
点云领域
5 三维路径规划现状
rtabmap实现有两种方法:
rtabmap实现参考网页:
1 slam分类
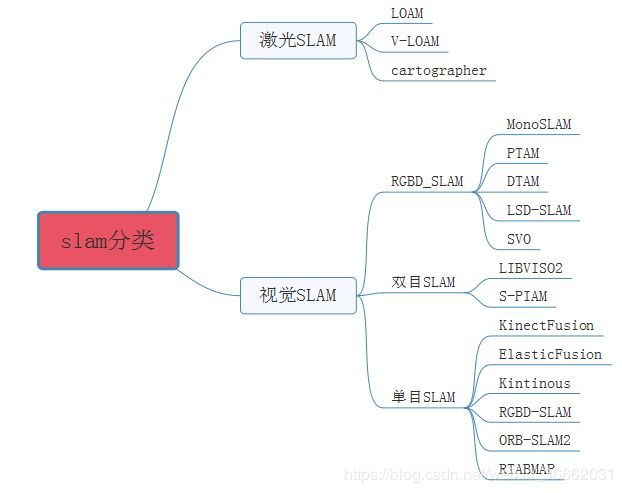
KinectFusion[1]是首个基于RGB-D相机的实时三维重建框架,通过用深度图像生成的点云通过ICP估计相机位姿,再依据相机位姿拼接多帧点云,并用TSDF模型表达重建结果。KinectFusion虽然能实时构建三维模型,但它实时性差,算法环境适应性较差,当环境主要由平行平面构成时,ICP会匹配失败。没有使用闭环检测进行优化。由于使用固定体积的网格模型表示重建的三维场景,因而只能重建固定大小的场景。
2012年的Kintinuous[2]是对KinectFusion的改进,在原基础上添加了闭环检测,并首次使用deformation graph对三维刚体重建做非刚体变换,使得闭环中两次重建的结果能够重合。
2015年的ElasticFusion[3]充分利用RGBD相机的信息,利用RGB的颜色一致性估计相机位姿,以及利用深度图像生成点云进行ICP来估计相机位姿,通过不断优化重建的map来提高相机位姿的估计精度,最后用surfel模型进行地图表达。但由于代码没有进行优化,它只适合对房间大小的场景进行重建。
RGBD SLAM2[4]将SLAM领域的图像特征、优化、闭环检测、点云、octomap等技术融为一体,但是其算法实时性不好,相机必须慢速运动。
RTAB Map[5]通过改善内存管理机制,减少图优化和闭环检测中需要用到的结点数,保证实时性以及闭环检测的准确性,能够在超大场景中运行,但是其代码过于冗杂。
2016年的ORB-SLAM2[6]兼容单目、双目、RGB-D三种模式,回环检测中引入了ORB字典,有效避免了误差累计而且数据丢失后可迅速找回。其采用三线程同步进行,很好的保证了轨迹与地图的全局一致性。
参考网址:https://blog.csdn.net/qq_27550989/article/details/78341904
文献:
- Newcombe R A, Izadi S, Hilliges O, et al. KinectFusion: Real-time dense surface mapping and tracking[C]//2011 IEEE International Symposium on Mixed and Augmented Reality. IEEE, 2011: 127-136.
- Whelan T, Kaess M, Fallon M, et al. Kintinuous: Spatially extended kinectfusion[J]. 2012.
- Whelan T, Leutenegger S, Salas-Moreno R, et al. ElasticFusion: Dense SLAM without a pose graph[C]. Robotics: Science and Systems, 2015.
- Engelhard N, Endres F, Hess J, et al. Real-time 3D visual SLAM with a hand-held RGB-D camera[C]//Proc. of the RGB-D Workshop on 3D Perception in Robotics at the European Robotics Forum, Vasteras, Sweden. 2011, 180: 1-15.
- Labbe M, Michaud F. Appearance-based loop closure detection for online large-scale and long-term operation[J]. IEEE Transactions on Robotics, 2013, 29(3): 734-745.
- Mur-Artal R, Tardós J D. Orb-slam2: An open-source slam system for monocular, stereo, and rgb-d cameras[J]. IEEE Transactions on Robotics, 2017, 33(5): 1255-1262.
2 常见传感器的优缺点:
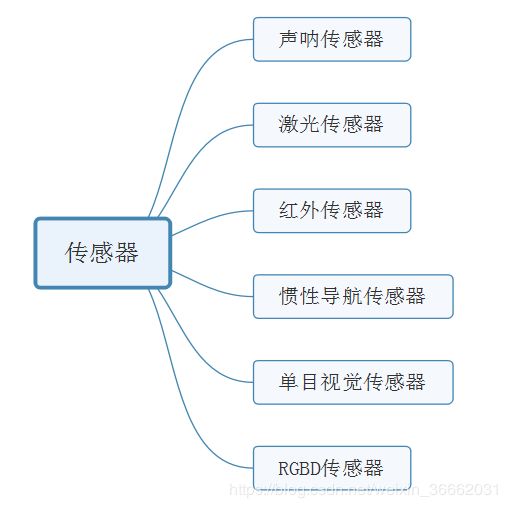
声纳传感器、激光传感器、红外传感器、惯性导航传感器、GPS
与这些传感器相关的定位和地图构建问题已经得到了非常详细的研究。但是他们都有自己的缺点,
声纳传感器受环境干扰可靠性较差,而且其波束较宽导致角度分辨率较差[1];
激光传感器可提供更高可靠性的瞬时测量、更精确的测距精度和角分辨率,但是成本较高;
红外传感器作为测距仪测距范围有限、易受环境光的干扰且具有非线性特征[2];
惯性导航传感器虽然能达到定位效果但是不能提供实时障碍物信息和GPS容易受到卫星视线遮挡的影响[3]。
单目视觉传感器可获得场景的色彩和纹理信息,但易受光照变化的影响,且缺少深度信息的表达。
RGBD相机可以同时获取彩色图像信息和深度信息,彩色图像信息与深度信息融合可充分发挥各自的优势, 避免单个传感器感知能力有限、环境描述不全等问题进而保证了移动机器人对环境感知和理解,提高了系统的整体性能以及系统运行的安全稳定性。
参考书籍:基于视觉的自主机器人导航

参考文献:
- 28.Flynn A M. Combining sonar and infrared sensors for mobile robot navigation[J]. The International Journal of Robotics Research, 1988, 7(6): 5-14.
- 29.Benet G, Blanes F, Simó J E, et al. Using infrared sensors for distance measurement in mobile robots[J]. Robotics and autonomous systems, 2002, 40(4): 255-266.
- 30.Saeedi P, Lawrence P D, Lowe D G, et al. An autonomous excavator with vision-based track-slippage control[J]. IEEE Transactions on Control Systems Technology, 2005, 13(1): 67-84.
3 路径规划算法整理
包括三部分:图搜索算法、采样规划算法、局部路径优化
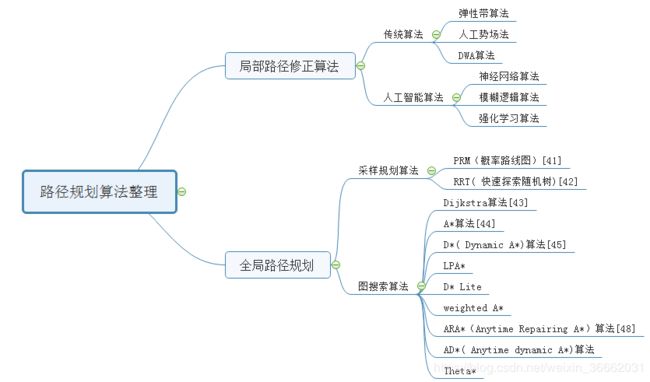
图搜索算法:
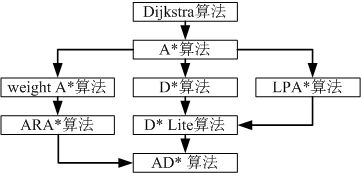
图搜索算法最早可以追溯到1959年荷兰计算机科学家提出的Dijkstra算法[1]。该算法利用贪心思想获取与当前点距离最近的节点,以起始点为首节点逐渐向外扩展,进而获得从起始点到其他所有点最短路径,成功的将占用网格转化为一张成本地图。Dijkstra算法缺点在于向四周搜索时盲目的,以至于效率很低。
在Dijkstra算法基础上,A*算法[2]利用估价函数对搜索方向进行限制,提高了搜索效率。A*算法属于静态环境下的路径规划算法,而现实环境通常是一个权重等因素不断变化的动态环境。
1994年卡内及梅隆机器人中心提出了D*( Dynamic A*)算法[3],运行过程中发现实际情况与地图不符,该算法通过增量式规划快速构建新的路径,成功的解决了动态问题。
2001年Sven Koenig和Maxim Likhachev等提出了LPA*(life Planning A*)算法[4],在机器人开始运行时,实际情况与地图不符,该算法结合环境信息对估价函数进行进一步调整,进一步提高路径搜索效率。
2002年,Sven Koening 等提出了 D* Lite 算法[5]结合D*算法和LPA*算法的改进过程,进一步提高了算法的性能。
Rolf Drechsler等提出的weighted A* 算法是在原A*算法的基础上引入了一个膨胀系数,使得该算法运行效率更高,但是其所得到的结果是次优解。
ARA*(Anytime Repairing A*)算法[6]在weighted A* 算法基础上,通过在机器人运行过程中不断减小膨胀系数,在保证效率前提下,使结果逐渐接近最优路径。
结合D* Lite算法,2005年提出了AD*( Anytime dynamic A*)算法[7],该算法在2007年DAPPA挑战赛中被很多汽车使用。
局部路径规划
Dijkstra算法
迪杰斯特拉(Dijkstra)算法是典型的最短路径的算法,由荷兰计算机科学家迪杰斯特拉于1959年提出,用来求得从起始点到其他所有点最短路径。该算法采用了贪心的思想,每次都查找与该点距离最近的点,也因为这样,它不能用来解决存在负权边的图。解决的问题可描述为:在无向图 G=(V,E) 中,假设每条边 E[i] 的长度为 w[i],找到由顶点vs到其余各点的最短路径。
1) 基本思想:
通过Dijkstra计算图G中的最短路径时,需要指定起点vs(即从顶点vs开始计算)。此外,引进两个集合S和U。S的作用是记录已求出最短路径的顶点(以及相应的最短路径长度),而U则是记录还未求出最短路径的顶点(以及该顶点到起点vs的距离)。初始时,S中只有起点vs;U中是除vs之外的顶点,并且U中顶点的路径是"起点vs到该顶点的路径"。然后,从U中找出路径最短的顶点,并将其加入到S中;接着,更新U中的顶点和顶点对应的路径。 然后,再从U中找出路径最短的顶点,并将其加入到S中;接着,更新U中的顶点和顶点对应的路径。重复该操作,直到遍历完所有顶点。
2) 算法步骤:
a.初始时,S只包含源点,即S={vs},vs的距离为0。U包含除vs外的其他顶点,即U={其余顶点},若u不是vs的出边邻接点,则
b.从U中选取一个距离vs最小的顶点k,把k加入S中(该选定的距离就是vs到k的最短路径长度min);
c.以k为新考虑的中间点,修改U中各顶点的距离;若从源点vs到顶点u的距离(经过顶点k)比原来距离(不经过顶点k)短,则修改顶点u的距离值,即dist[u] = min( dist[u], min + w[k][u] );
d.重复步骤b和c直到所有顶点都包含在S中。
A*算法原理:
在计算机科学中,A*算法作为Dijkstra算法的扩展,因其高效性而被广泛应用于寻路及图的遍历,如星际争霸等游戏中就大量使用。在理解算法前,我们需要知道几个概念:
- 搜索区域(The Search Area):图中的搜索区域被划分为了简单的二维数组,数组每个元素对应一个小方格,当然我们也可以将区域等分成是五角星,矩形等,通常将一个单位的中心点称之为搜索区域节点(Node)。
- 开放列表(Open List):我们将路径规划过程中待检测的节点存放于Open List中,而已检测过的格子则存放于Close List中。
- 父节点(parent):在路径规划中用于回溯的节点,开发时可考虑为双向链表结构中的父结点指针。
- 路径排序(Path Sorting):具体往哪个节点移动由以下公式确定:F(n) = G + H 。G代表的是从初始位置A沿着已生成的路径到指定待检测格子的移动开销。H指定待测格子到目标节点B的估计移动开销。
- 启发函数(Heuristics Function):H为启发函数,也被认为是一种试探,由于在找到唯一路径前,我们不确定在前面会出现什么障碍物,因此用了一种计算H的算法,具体根据实际场景决定。在我们简化的模型中,H采用的是传统的曼哈顿距离(Manhattan Distance),也就是横纵向走的距离之和。
A*算法总结:
1. 把起点加入 open list 。
2. 重复如下过程:
a. 遍历open list ,查找F值最小的节点,把它作为当前要处理的节点,然后移到close list中
b. 对当前方格的 8 个相邻方格一一进行检查,如果它是不可抵达的或者它在close list中,忽略它。否则,做如下操作:
□ 如果它不在open list中,把它加入open list,并且把当前方格设置为它的父亲
□ 如果它已经在open list中,检查这条路径 ( 即经由当前方格到达它那里 ) 是否更近。如果更近,把它的父亲设置为当前方格,并重新计算它的G和F值。如果你的open list是按F值排序的话,改变后你可能需要重新排序。
c. 遇到下面情况停止搜索:
□ 把终点加入到了 open list 中,此时路径已经找到了,或者
□ 查找终点失败,并且open list 是空的,此时没有路径。
3. 从终点开始,每个方格沿着父节点移动直至起点,形成路径。
A*(A-Star)算法是一种静态路网中求解最短路最有效的方法。公式表示为: f(n)=g(n)+h(n), 其中f(n) 是节点n从初始点到目标点的估价函数,g(n) 是在状态空间中从初始节点到n节点的实际代价,h(n)是从n到目标节点最佳路径的估计代价。
保证找到最短路径(最优解的)条件,关键在于估价函数h(n)的选取:
估价值h(n)<= n到目标节点的距离实际值,这种情况下,搜索的点数多,搜索范围大,效率低。但能得到最优解。
如果 估价值>实际值, 搜索的点数少,搜索范围小,效率高,但不能保证得到最优解。
估价值与实际值越接近,估价函数取得就越好。
例如对于几何路网来说,可以取两节点间欧几理德距离(直线距离)做为估价值,即f=g(n)+sqrt((dx-nx)*(dx-nx)+(dy-ny)*(dy-ny));这样估价函数f在g值一定的情况下,会或多或少的受估价值h的制约,节点距目标点近,h值小,f值相对就小,能保证最短路的搜索向终点的方向进行。明显优于Dijstra算法的毫无无方向的向四周搜索。
D*算法实现:
D*是动态A*(D-Star,Dynamic A Star) 卡内及梅隆机器人中心的Stentz在1994和1995年两篇文章提出,主要用于机器人探路。是火星探测器采用的寻路算法。
D*算法在动态环境中寻路非常有效,向目标点移动中,只检查最短路径上下一节点或临近节点的变化情况,如机器人寻路等情况。对于距离远的最短路径上发生的变化,则感觉不太适用。
1.先用Dijstra算法从目标节点G向起始节点搜索。储存路网中目标点到各个节点的最短路和该位置到目标点的实际值h,k(k为所有变化h之中最小的值,当前为k=h。每个节点包含上一节点到目标点的最短路信息1(2),2(5),5(4),4(7)。则1到4的最短路为1-2-5-4。
原OPEN和CLOSE中节点信息保存。
2.机器人沿最短路开始移动,在移动的下一节点没有变化时,无需计算,利用上一步Dijstra计算出的最短路信息从出发点向后追述即可,当在Y点探测到下一节点X状态发生改变,如堵塞。机器人首先调整自己在当前位置Y到目标点G的实际值h(Y),h(Y)=X到Y的新权值c(X,Y)+X的原实际值h(X).X为下一节点(到目标点方向Y->X->G),Y是当前点。k值取h值变化前后的最小。
3.用A*或其它算法计算,这里假设用A*算法,遍历Y的子节点,点放入CLOSE,调整Y的子节点a的h值,
LPA*算法
LPA*或life Planning A_star是一种基于A*的增量启发式搜索算法。2001年,斯文·柯尼格(Sven Koenig)和马克西姆·利卡切夫(Maxim Likhachev)首次提出。
LPA_star是A_star的增量版本,它可以适应图形中的变化而无需重新计算整个图形,方法是在当前搜索期间更新前一次搜索的g值(从开始起的距离),以便在必要时进行更正。与A_star一样,LPA*使用启发式算法,该启发性来源于从给定节点到目标路径代价的更低边界。如果保证是非负的(零可以接受)并且从不大于到目标的最低路径的代价,则允许该启发式。
启发式搜索和增量式搜索的区别在于,启发式搜索是利用启发函数来对搜索进行指导,从而实现高效的搜索,启发式搜索是一种“智能”搜索,典型的算法例如A_star算法、遗传算法等。增量搜索是对以前的搜索结果信息进行再利用来实现高效搜索,大大减少搜索范围和时间,典型的例如LPA_star、D_star Lite算法等。
D* Lite算法
D_star Lite 算法之于 LPA* 算法犹如 D* 算法之于 A*算法。与 LPA* 采用的正向搜索算法不同,D* Lite 采用反向搜索方式,效果与D_star 算法相当。无论是前文提到LPA_star 算法还是A_star 算法都不能满足移动机器人在未知环境中的路径规划需求,因为其在未知地图中需要不断的尝试,与边走边找到最优路径背道而驰。此时反向搜索算法能够很好的处理这种情况,D* 算法虽然可以实现未知环境的路径规划,但效率较低,基于 LPA* 的D* Lite可以很好的应对环境未知的情况,其算法核心在于假设了未知区域都是自由空间,以此为基础,增量式地实现路径规划,通过最小化rhs值找到目标点到各个节点的最短距离。在移动机器人按照规划的路径进行前进时其所到的节点即设置为起始节点,因此路径变化或者key值需要更新时,需要更新从目标点到新起点的启发值以及估计成本。由于移动机器人不断的靠近目标点,节点的启发值将不断减少,且减少至不会超过h(start Org,start New)。由于每次都要减去相同的值,开启列表的顺序并不会改变,因此可以不进行这部分的计算,这样便避免了每次路径改变时的队列遍历过程。
若前行过程中发现障碍物则将障碍物所对应环境地图位置设置为障碍物空间,并再以之为起点利用“路径场”信息重新规划出一条路径来。此时不仅更新规划路径的节点数据,也要更新智能体遍历过的节点。其关键点在于如何在未知的环境中根据传感器获取的极少周边地图信息来进行最有效的靠近目标点的任务。其实整个靠近的过程一直在扩大已知地图范围,尽可能少的尝试次数来实现完成抵达目标点的任务。下图为 D* Lite 搜索示意图,黑点是在按照反向搜索的路径执行时发现的障碍点,到遇到不能通行的障碍点后便更新地图信息,重新规划出一条新的路径继续前行。
D* Lite 算法的原理类似 D* ,起初需要根据已知的环境信息,未知部分视作自由空间,规划出从目标点到起始点的全局最优路径,此时即建立了一个“路径场”信息,为增量靠近目标点提供择优依据。D* Lite算法是反向搜索的,因此LPA* 里的g(s),h(s)有了新的定义,即分别代表从目标点到当前s点的代价值以及当前s点到出发点的启发值。与LPA_star 中相反,g*(s) 记录栅格节点的前继节点,计算式为
D* Lite结合了D_star 算法动态规划的特性(由目标位置开始向起始位置进行路径搜索。当路径中存在新的障碍时,对于目标位置到新障碍之间的范围内的路径节点,新的障碍是不会影响到其到目标的路径的)和LPA_star 算法的利用增量式搜索特性。
D* Lite算法能够很好的适用于未知环境做路经规划,由于其增量规划的思想,它可以做到较少重规划次数以及较少的重规划影响节点数。但是当状态空间比较大,也就是环境地图比较大的时候,采用的 D_star Lite 路径规划算法的反向搜索过程需要维护的栅格节点数急剧增加,增加了搜索的时间复杂度。除此之外,D_star Lite 路径规划不能应对环境复杂的情况,即局部环境的精细规划。对于大环境下的路径规划,D_star Lite 算法的做法是将环境地图进行更细粒度的栅格化,虽然在足够细粒化的环境地图中可以实现较优的路径解,但也会带来更多的规划序列导致执行次数以及重规划次数增多,进而路径规划执行花费时间也会变得更长。
ARA*
ARA*算法通过多次调用WA*算法实现,WA*算法通过加重g(n)在评估公式中的权重,采用公式h(n)=f(n)+eg(n)(e>1)让算法以更快的速度趋近于目标点。算法思路为:设定算法求解时间,首先在相对宽松的条件下规划出一条次优路径,然后在设定时间内不断对路径进行优化,直到求解出的路径信息最优,或者设定时间结束。优势在于加快了算法向目标节点靠近的速度,同时保证算法求解时间不超过预期。
参考文献、来源、参考网址
参考文献:
- Boyle J P, Dykstra R L. A method for finding projections onto the intersection of convex sets in Hilbert spaces[M]//Advances in order restricted statistical inference. Springer, New York, NY, 1986: 28-47.
- Appi J M A. A formal basis for the heuristic determination of minimum cost paths[J]. 1966.
- Stentz A. The focussed D^* algorithm for real-time replanning[C]//IJCAI. 1995, 95: 1652-1659.
- Koenig S, Likhachev M, Furcy D. Lifelong planning A∗[J]. Artificial Intelligence, 2004, 155(1-2): 93-146.
- Koenig S, Likhachev M. Improved fast replanning for robot navigation in unknown terrain[C]//Proceedings 2002 IEEE International Conference on Robotics and Automation (Cat. No. 02CH37292). IEEE, 2002, 1: 968-975.
- Likhachev M, Gordon G J, Thrun S. ARA*: Anytime A* with provable bounds on sub-optimality[C]//Advances in neural information processing systems. 2004: 767-774.
- Likhachev M, Ferguson D I, Gordon G J, et al. Anytime Dynamic A*: An Anytime, Replanning Algorithm[C]//ICAPS. 2005: 262-271.
来源: 李宁.面向家庭环境的移动机器人局部路径算法研究[J].哈尔滨工业大学,2018. http://www.doc88.com/p-9793830645220.html
张明明. 基于 Kinect2 的光伏清洗机器人实时环境重建与自主导航技术研究[J]. 哈尔滨工业大学, 2016: 1-z.
参考网页
Dijkstra算法 https://www.cnblogs.com/21207-iHome/p/6048969.html
A* D* 之间的关系 https://blog.csdn.net/chinaliping/article/details/8525411
LPA https://blog.csdn.net/lqzdreamer/article/details/85175372
D* Lite https://blog.csdn.net/lqzdreamer/article/details/85108310
A*算法、ARA*算法与经典路径搜索算法的对比 https://blog.csdn.net/wangkaikai1996/article/details/80947194
局部路径规划
人工势场模型、动态窗口法(DWA)、弹性带法(Elastic Bands)、模糊逻辑算法、强化学习算法,
局部路径规划算法主要可分为传统的经典算法其中包括:人工势场法[29]、基于速度空间的算法:动态窗口法 DWA 与弹性带算法 TEB 等,与人工智能(AI) 算法主要包括:神经网络算法、模糊逻辑算法与强化学习算法等。
在人工势场模型中,目标点对机器人建立引力场而障碍物对机器人建立斥力场,其合力的方向表示机器人期望的速度方向,力的大小表示机器人期望的速度值。Fujimura[30]提出了时变的势场函数增加了人工势场法的适应能力。Ko与 Lee[31]提出的可避障的测量函数,即运用机器人与障碍物的距离,障碍物相对于机器人的速度来计算机器人碰撞障碍物的可能性,该函数可以使机器人避免正在接近的障碍物并且远离。
基于速度空间的算法将运动规划问题分为两个部分,运动学与动态约束。第一步为求解运动学轨迹,第二步为施加动态约束得到可行轨迹。动态窗口法(DWA)[32]通过在动态窗口即可行的速度空间内进行采样运用机器人运动学推算其轨迹,之后运用考虑了限制约束的评价函数对其进行评价,综合得到最优的线速度与角速度。
由于传统的 DWA 算法存在对于复杂环境适应性较弱等缺陷,许多研究人员在此基础上做了改进工作,如分析机器人前进方向的连通性,评价函数考虑机器人前方障碍物之间的距离与机器人自身的几何尺寸,不再将障碍物单纯考虑为质点,提高机器人在狭窄通道或者多障碍物环境内的路径规划能力[33]、以直方图代表轨迹碰撞到障碍物的概率提出了新的避障目标函数,提升机器人避障效果[34],将 DWA 算法从差动的非完整约束机器人拓展到了完整约束的机器人上[35],利用模糊控制理论改进了 DWA 算法提升了机器人在复杂多动态障碍物环境中的表现[36]等方法,一定程度上提高了 DWA 的适用性。但是基于传统DWA 改进的算法都存在一些问题,具体来说没有考虑机器人运动轨迹的最优性,平滑性、方向性与快速性等因素,所以容易出现运动路径并非最优,路径距离不是最短,转弯过多,运动速度波动较大,易陷入局部最优状态等问题,对于移动机器人运动影响较大。
弹性带法(Elastic Bands)[37-39],将全局路径粒子化为'bubbles'集合,每个'bubbles'包含半径、位置、速度与最近障碍物的坐标。对于每个'bubbles'最近的障碍物对其产生斥力,周围的'bubbles'对其产生聚集力,利用力与速度计算新'bubbles'的位置。
AI 算法主要包括:神经网络算法,模糊逻辑算法与强化学习算法等。Singh[40]等人设计了一种基于神经网络的算法能够使机器人安全的在未知环境中导航,神经网络的输入为机器人前方、左前方与右前方障碍物的距离和机器人与目标点的角度,网络的输出为机器人的转向角。障碍物信息由机器人前方传感器获取。
模糊逻辑算法,除了神经网络之外,模糊逻辑被认为能够表达人类头脑中的主观不确定性。人类没有任何确定的测量与计算能力便能完成导航任务,因此模仿这种能力开发自主机器人导航算法是非常理想的[41],在模糊逻辑算法中,机器人导航的决策可以用一组 IF-THEN 规则来描述,为了方便实施,导航问题可以分解为更简单的任务和行为。
H. Chang 和 T. Jin 提出了基于命令融合的避障模糊控制器[42]。传感器可以感知未知动态环境中障碍物的位置和机器人的当前速度。在该模型中,代价函数中包含三个主要的导航目标:目标方向,避障和旋转运动(维护航向角)以计算得出最佳转向角 θ。移动机器人通过根据环境改变代价函数的权重来进行导航。
强化学习算法,强化学习 Q_learning[43]算法无需知道机器人模型与静态环境地图,可以使机器人在不断的与环境交互过程中学习训练提高其路径规划能力。在 2013 年,Mnih V 等人提出的深度强化学习算法[44-45],利用图像作为输出,其算法玩 Atari 游戏的能力超越了人类,在 2015 年 Schaul T 等人提出了优先级经验回放技术[46],提高了算法的学习效率。
强化学习算法在导航方面的应用有:Jaradat 提出了一种基于强化学习的移动机器人路径规划算法[47],将环境模型定义为三类:机器人周围目标点所在象限,机器人周围最近障碍物所在象限与机器人与障碍物连线和机器人与目标点 连线的夹角大小,并按照机器人与障碍物目标点的距离将机器人划分为成功、失败、安全与不安全状态,并由状态的转移来定义报酬函数。其缺点是只考虑了最近障碍物信息,并且处于安全状态时朝向目标点移动过于简单,对于简单场景学习能力较强,对于复杂场景适应能力较弱。Duguleana M 等人[48]在上述论文的基础上,引入神经网络拟合 Q_table,提高了算法的收敛性,但其对周围障碍物的分布情况不明确,容易陷入局部最小状态。Huang B Q 等人[49]提出了基于强化学习与神经网络的移动机器人避障算法,状态为机器人前方传感器获取的障碍物信息,将状态与动作输入网络,输出为其对应的 Q 值,选取 Q 值最大的动作执行,算法能够较好的完成避障任务,但由于缺乏目标点的信息,所以无法进行路径规划。
参考文献:
[29]Y Koren,and J.Borenstein, Potential field methods and their inherent limitations for mobile robot navigation, in Proceedings of IEEE International Conference on Robotics and Automation, 1991:1398-1404.
[30] Kikuo Fujimura, Motion Planning in Dynamic Environments, Springer-Verlag Berlin and Heidelberg GmbH &Co.k, 1991 ISBN10:3540700838.
[31] N.Y. Ko, B.H. Lee, Avoidability measure in moving obstacle avoidance problem and its use for robot motion planning, in: Proceedings of the IEEE International Conference on Intelligent Robots and Systems, Osaka, Japan, 1996,November, pp. 1296-1303.
[32] Fox D, Burgard W, Thrun S. The Dynamic Window Approach to Collision Avoidance [J]. IEEE Robotics&Automation Magazine, 1997, 4( l ): 23-33.
[33] 梁山,刘娟,鲜晓东,一种考虑机器人尺寸约束的动态窗避障方法[J].控制工程,2011,18(6):872-876.
[34] Piyapat S,Nattee N,Attawith S. Robust local obstacle avoidance for mobile robot based on Dynamic Window approach[C]. Proceeding of 10th International Conference on Electrical Engineering and Electronics, Computer, Telecommunications and Information Technoloy (ECTI-CON), 2013:1-4.
[35] Felipe P V IV,Ansu M S,Deok J L.Design convergent Dynamic Window Approach for quadrotor navigation[J].International Journal of Precision Engineering and Manufacturing, 2014,15(10):2177-2184.
[36] Choi B, Kim B,Kim E.A modified Dynamic Window Approach in crowded indoor environment for intelligent transport robot[C].Proceeding of 2012 12th International Conference on Control.Automation and Systems, 2012.
[37] Quinlan, S. and Khatib, O. "Elastic Bands: Connecting Path Planning and Robot Control." Proc. IEEE International Conference on Robotics and Automation, Atlanta, Georgia 1993, pp. 802-807.
[38] Roesmann C, Feiten W, Woesch T, et al. Trajectory modification considering dynamic constraints of autonomous robots[C]// Robotics; Proceedings of Robotik 2012;, German Conference on. VDE, 2012:1-6.
[39] Rosmann C, Feiten W, Wosch T, et al. Efficient trajectory optimization using a sparse model[C]// European Conference on Mobile Robots. IEEE, 2014:138-143.
[40] Singh M K, Parhi D R. Path optimisation of a mobile robot using an artificial neural network controller[J]. International Journal of Systems Science, 2011, 42(1):107-120.
[41] T.S. Hong, D. Nakhaeinia, B. Karasfi, Application of fuzzy logic in mobile robot navigation, in: Fuzzy Logic - Controls, Concepts, Theories and Applications, 2012, pp. 21–36.
[42] H. Chang, T. Jin, Command fusion based fuzzy controller design for moving obstacle avoidance of mobile robot, in: Future Information Communication echnology and Applications, in: Lecture Notes in Electrical Engineering,2013, pp. 905–913.
[43] C. J. C. H. Watkins, and P. Dayan, Q learning, Machine Leamning, 8(3-4): 279-292,1992.
[44] Mnih V, Kavukcuoglu K, Silver D, et al. Playing Atari with Deep Reinforcement Learning[J]. Computer Science, 2013.
[45] Mnih V, Kavukcuoglu K, Silver D, et al. Human-level control through deep reinforcement learning.[J]. Nature, 2015, 518(7540):529.
[46] Schaul T, Quan J, Antonoglou I, et al. Prioritized Experience Replay[J]. Computer Science, 2015.
[47] Jaradat M A K, Al-Rousan M, Quadan L. Reinforcement based mobile robot navigation in dynamic environment[J]. Robotics & Computer Integrated Manufacturing, 2011, 27(1):135-149.
来源: 李宁.面向家庭环境的移动机器人局部路径算法研究[J].哈尔滨工业大学,2018. http://www.doc88.com/p-9793830645220.html
4 深度学习网络
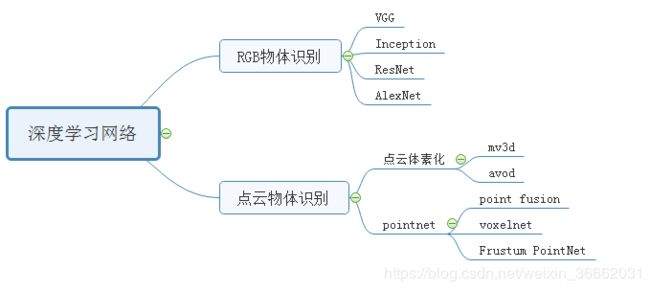
图像领域
常见的通过图像数据实现的识别方法包括ResNet[1], AlexNet[2], VGG[3], Inception[4]等算法。由于常规的网络的堆叠随着网络深度的增加,梯度逐渐消失,网络的训练效果越差。Resnet主要解决的是深度网络中的退化问题。2012年AlexNet通过dropout技术来减少过拟合进而实现识别;vgg通过增加网络深度,减小卷积核尺寸使得定位效果更好,在ILSVRC上定位方面获得第一名;inception将稀疏矩阵聚类为较为密集的子矩阵来提高计算性能,既保持网络结构的稀疏性,又能利用密集矩阵的高计算性能。
点云领域
在点云领域产生了许多基于将点云体素化(格网化)的深度学习框架,取得了很好的效果,如2016年Xiaozhi Chen, Huimin Ma 等人提出的mv3d[5]框架,通过引入了三维体素模式实现了三维激光雷达数据和二维图像数据融合的物体检测。 2017年,Jason Ku, Melissa Mozifian等人提出了avod[6]方法中将图像和鸟瞰图特征图中全分辨率的特征要素作为输入,实现了较高精度的物体识别和定位。但是将点云体素化势必会改变点云数据的原始特征,造成不必要的数据损失,并且额外增加了工作量。 2016年斯坦福大学提出了一种点云分类深度学习框架PointNet[7],PointNet 采用了原始点云的输入方式,最大限度地保留了点云的空间特征,并在最终的测试中取得了很好的效果。紧接着2017年,Danfei Xu等人提出了point fusion方法[8],该方法通过pointnet处理点云数据并通过ResNet处理颜色数据,通过将二者加权融合,得到了较为精确的识别检测。同年,一系列根据点云信息和颜色信息融合的物体识别方法随之出现了,其中还包括voxelnet[9]、Frustum PointNets[10]等算法。然而目前由于点云三维数据量大,且训练过程需要大量的时间,并不能满足机器人的实时性的需要。2011年Kevin Lai, Liefeng Bo 等利用sift特征点检测和颜色直方图实现了物体检测[11],2013年,Haider Ali , Faisal Shafait等利用三维特征和色彩直方图实现了物体检测[12]。
参考文献:
- He K, Zhang X, Ren S, et al. Deep residual learning for image recognition[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 770-778.
- Krizhevsky A , Sutskever I , Hinton G . ImageNet Classification with Deep Convolutional Neural Networks[J]. Advances in neural information processing systems, 2012, 25(2).
- Hu X , Xu X , Xiao Y , et al. SINet: A Scale-Insensitive Convolutional Neural Network for Fast Vehicle Detection[J]. IEEE Transactions on Intelligent Transportation Systems, 2018:1-10.
- Szegedy C, Vanhoucke V, Ioffe S, et al. Rethinking the inception architecture for computer vision[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 2818-2826.
- Chen X, Ma H, Ji W, et al. Multi-view 3D Object Detection Network for Autonomous Driving[C]// IEEE Conference on Computer Vision & Pattern Recognition. 2017.
- Ku J , Mozifian M , Lee J , et al. Joint 3D Proposal Generation and Object Detection from View Aggregation[J]. 2017.
- Qi C R, Su H, Mo K, et al. Pointnet: Deep learning on point sets for 3d classification and segmentation[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017: 652-660.
- Xu D, Anguelov D, Jain A. Pointfusion: Deep sensor fusion for 3d bounding box estimation[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018: 244-253.
- Zhou Y, Tuzel O. Voxelnet: End-to-end learning for point cloud based 3d object detection[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018: 4490-4499.
- Qi C R, Liu W, Wu C, et al. Frustum pointnets for 3d object detection from rgb-d data[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018: 918-927.
- Lai K, Bo L, Ren X, et al. A large-scale hierarchical multi-view rgb-d object dataset[C]//2011 IEEE international conference on robotics and automation. IEEE, 2011: 1817-1824.
- Ali H, Shafait F, Giannakidou E, et al. Contextual object category recognition for rgb-d scene labeling[J]. Robotics and Autonomous Systems, 2014, 62(2): 241-256.
网页参考:
kitti官网 网址:http://www.cvlibs.net/datasets/kitti/eval_object.php 内容:包括各种物体识别定位算法的检测正确率
5 三维路径规划现状
3d_navigation 、autoware、三维栅格地图、rtabmap
2012年Hornung A等针对PR2机器人实现三维路径规划[1],通过将三维点云数据简化成为3层二维点云数据,然后通过对三层的数据分别进行路径规划,最后将其汇总,进而实现三维路径规划。
还有其他方法是将三维栅格数据投影到二维平面上实现导航[2,3],
哈尔滨工业大学的张明明在其基础上实现了基于Kinect2光伏清洗机器人实时环境重建与自主导航技术研究[4]。获取的信息成功实现了路径规划。
2014年Mathieu Labbé等人将三维点云数据投影到平面上,然后实现针对三维地图的二维导航。在商业上用于城市自主驾驶的开源软件autoware通过多传感器融合也实现三维环境导航[5]。但是其处理的数据量过大。
rtabmap实现有两种方法:
使用 rtabmap + handsfree 进行导航其实是用 rtabmap 的投影地图或者是scan地图来作为 move_base 的地图输入,然后利用 Navigation Stack 进行路径规划等。
rtabmap 除了可以用 scan 来生成二维地图以外,还可以使用 rtabmap 提供的一个 nodelet —— obstacles_detection 来计算二维投影地图。它的原理是将三维点云直接投影到平面上,可以通过设定 ground_normal_angle 参数来区分地面和障碍物。使用这种方法的好处是不需要激光数据,但是需要将 kinect 向下倾斜一点角度,保证kinect能够照到地面。
参考文献:
- Hornung A, Phillips M, Jones E G, et al. Navigation in three-dimensional cluttered environments for mobile manipulation[C]//2012 IEEE International Conference on Robotics and Automation. IEEE, 2012: 423-429.
- 张彪, 曹其新, 王雯珊. 使用三维栅格地图的移动机器人路径规划[J]. 西安交通大学学报, 2013, 47(10): 57-61.
- 马丽莎. 基于数字高程模型栅格地图的移动机器人路径规划研究[D]. 浙江大学, 2012.
- 张明明. 基于 Kinect2 的光伏清洗机器人实时环境重建与自主导航技术研究[J]. 哈尔滨工业大学, 2016: 1-z.
- Kato S, Takeuchi E, Ishiguro Y, et al. An open approach to autonomous vehicles[J]. IEEE Micro, 2015, 35(6): 60-68.
rtabmap实现参考网页:
https://blog.csdn.net/u010925447/article/details/78258633
https://www.rosclub.cn/thread-25.html