第八届泰迪杯C题
国赛三等奖,广东省二等奖
“智慧政务”中的文本挖掘应用
摘要
在这个信息时代,以怎样的方式去了解民意、汇集民智、凝聚民气是城市政府以及相关工作部门日益关心的重大问题之一。但随着各类社情相关的文本数据量的不断攀升,以人工的方式对群众的留言进行分类以及对热点问题的整理往往存在工作效率低下的问题。因此,本文将基于数据挖掘技术对“智慧政务“中的文本即群众的留言数、群众关心的热点问题、以及相关工作部门的解决方案数据进行内在信息的挖掘与分析。
首先,在本次数据挖掘过程中,我们首先对获取得到的留言数据利用基于Python的fastText原理对数据预处理、分词以及停用过滤操作,实现对留言数据的分类,并提升了可建模度,并使用F-Score对训练模型进行评价,经过不断的训练,最终得到评价值约为0.8835。
其次,对热点问题的挖掘,我们首先对留言语料进行文本预处理,使用TF-IDF方法进行分词及去除停用词操作,用欧氏距离来得到相似的度量报道与话题的相关性,最后通过文本聚类k-means算法,把相似的高的留言加到对应的话题簇中,得到了话题簇,因此得到了排名前5的热点问题和相应热点问题对应的留言信息。
最后,问题3主要从答复意见文本的相关性、完整性和可解性、时效性和信息量等角度出发,来建立相关工作部门对留言答复意见质量的评价指标。本文运用预先相似度计算方法来计算留言主题与相关工作部门的答复意见之间的相似度, 用自动化可读性指数ARI来表示可解释性,ARI的计算公式为:API=4.71*(总字符数/总字数)+0.5*(总字数/总句数)-21.43。基于主成分分析之权值计算方法,算出为接下来即将要构建的评价模型中各个评价指标的权重。其中相关性、可解释性、实效性和信息量分别所占的权重为0.26、0.28、0.18、0.28,最后得到答复意见质量评价模型为 Q=0.28Words+0.26Relevancy+0.28Credibility+0.18Timeliness+0.01。
关键词:自然语言、fastText原理、n-gram特征、F-Score评价、k-means算法、欧氏距离、TD-IDF方法,广义线性回归
Question C: Text Mining Application in "Smart Government Affairs"
Abstract
In this information age, how to understand public opinion, gather people's wisdom, and gather people's popularity is one of the major issues that the city government and related work departments are increasingly concerned about. However, as the amount of text data related to various social conditions continues to rise, there is often a problem of low work efficiency in manually categorizing the masses' messages and sorting out hot issues. Therefore, based on the data mining technology, this article will mine and analyze the intrinsic information of the text in the "smart government affairs", that is, the number of messages of the masses, the hot issues that the masses care about, and the solution data of the relevant work departments.
First of all, in this data mining process, we first use the Python-based fastText principle to preprocess the data, segment the words, and disable the filtering operation on the obtained message data, classify the message data, and improve the modelability And use F-Score to evaluate the training model. After continuous training, the final evaluation value is about 0.8835.
Secondly, for the mining of hot issues, we first perform text preprocessing on the message corpus, use the TF-IDF method to perform word segmentation and remove stop words, and use Euclidean distance to obtain similar measurement reports and topic relevance, and finally pass The text clustering k-means algorithm adds similar high messages to the corresponding topic clusters to obtain topic clusters. Therefore, the top 5 hotspot questions and the message information corresponding to the corresponding hotspot questions are obtained.
Finally, from the perspective of the relevance, completeness and solvability, timeliness and amount of information of the reply opinion text, to establish related work The evaluation index of the quality of the department's response to the message. This article uses the pre-similarity calculation method to calculate the similarity between the subject of the message and the reply of the relevant work department, and uses the automated readability index ARI to indicate the interpretability. The calculation formula of ARI is: API = 4.71 * Number / Total Words) + 0.5 * (Total Words / Total Sentences) -21.43. Based on the weight calculation method of principal component analysis, the weight of each evaluation index in the evaluation model to be constructed next is calculated. Among them, the weights of relevance, interpretability, effectiveness and amount of information are 0.26, 0.28, 0.18 and 0.28 respectively, and the quality evaluation model of the final opinion is Q = 0.28Words + 0.26Relevancy + 0.28Credibility + 0.18Timeliness + 0.01 .
Keywords: natural language, fastText principle, n-gram features, F-Score evaluation, k-means algorithm, Euclidean distance, TD-IDF method, generalized linear regression
evaluation, k-means algorithm, Euclidean distance, TD-IDF method, generalized linear regression
目录
1 引言... 1
1.1研究背景... 1
2 挖掘目标... 1
3 模型构建过程及结果分析... 2
3.1 问题1分析方法与过程... 2
3.1.1 流程图... 2
3.1.2 数据预处理... 2
3.1.3 留言文本分词... 2
3.1.4停用过滤词... 4
3.1.5 方法实现过程... 5
3.2 问题2方法与过程... 10
3.2.1问题分析:... 10
3.2.2 话题发现基本流程图... 10
3.2.3 文本预处理... 11
3.2.4 留言信息特征提取... 12
3.2.5 话题的表示模型... 13
3.2.6 热值计算... 15
3.2.7 文本聚类话题提取... 16
3.3 问题3方法与过程... 17
3.3.1 问题分析... 17
3.3.2 预处理... 18
3.3.3 指标提取... 19
3.3.6 构建答复意见质量评价指标体系... 25
4 结论... 26
参考文献... 27
附录... 28
1 引言
1.1研究背景
自然语言构成的文本中往往包含了丰富的信息,但是这些自然语言描述的信息是提供给人阅读理解,计算机无法组织里面的有效信息加以利用。一般的解决办法是人工直接从文本中提取信息,或者利用计算机程序通过自然语言特征抽取特定信息。如何让计算机更好的自动抽取文本信息成为急需解决的问题。中文文本信息抽取成为自然语言处理及文本挖掘领域的一个研究热点。
文本信息抽取主要分为实体抽取、实体关系抽取等部分,目前大多采用机器学习,尤其是基于概率统计的机器学习方法来解决这些问题。主要分为有指导(Supervised)和弱指导(Weakly Supervise)的学习方法。大多数自然语言处理问题面对的是一般领域语料,大多采用有指导的学习方法,需要费时费力的标注训练集,训练集的优劣直接决定了最终学习模型的好坏。然而信息抽取任务针对的往往是特殊领域语料,基于一般领域语料所总结出的抽取内容往往不能很好解决特殊领域问题。所以需要利用机器学习方法快速构建特殊领域文本信息抽取系统。
本文针对群众留言分类、热点留言以及相关部门回复方案评价问题实现了该方法,与直接通过模板提取信息相比,本文提出的方法大大提高了准确率召回率,以及减少了大量人工干预,建立模板的工作工作量。并且具有很好的扩展性,可以做到迅速构建系统应对新的中文文本抽取任务。
2 挖掘目标
本次的建模的目标是利用来自互联网公开来源的群众问政留言记录,及相关部门对部分群众留言的答复意见,采用fastText原理对文本信息进行分类,并通过不断的训练模型,调节相关参数,最终使得将不同的留言换分到不同的工作管理类别中,提高相关工作部门工作的效率。
对文本进行基本的机械预处理、中文分词、停用词过滤后、建立话题簇,对热点问题进行归类,得出当前的热点信息,以便相关部门针对性地解决实时问题,提高人民幸福指数。
实现对文本数据的倾向性判断以及所隐藏的信息的挖掘并分析,以期望得到有价值的内在内容。
3 模型构建过程及结果分析
3.1 问题1分析方法与过程
3.1.1 流程图

3.1.2 数据预处理
3.1.2.2 机械压缩取词
由于群众留言信息数据中,有些数据质量可能存在参差不齐、没有意义的情况
3.1.3 留言文本分词
在中文中,只有字、句和段落能够通过明显的分界符进行简单的化界,而对于“词”和“词组”来说,它们的边界模糊,没有一个形式上的分节符。因此,进行文本挖掘时,首先对文本分词,即将连续的字符按照一定的规范重新组合成词序列的过程。
问题1使用Jieba方法对留言文本分词,基于Jieba分词包,其运用了数据结构里的trie(前缀数或字典树),能够对词语进行高效的分类。Trie的原理如图2所示:
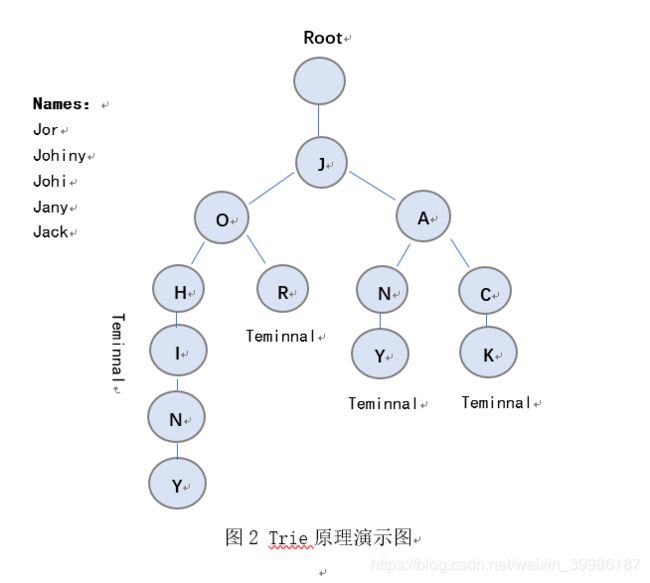 |
如上图2所示,比如我们有Johiny、Jor、Jany和Jack四个名字,假设我们要让计算机查找名字Jack是否存在,则trie会从上至下的搜索、每一次判定一个字母、如果某个特定的节点(node)的下一个节点(child node)不在符合搜索压迫求,那么搜索就会停止,从而使得效率大大的提高。
与此同时,在文本信息中,仅仅以trie原理进行分词会避免不了双重理解词语结合的情况,于是trie与有向无环图(DAG)的结合运用,可以高效的解决这个问题,其运用原理举例如图3所示:

通过设定,计算机自动识别出了两种分词方法,分别是‘有/意见/分歧/’和‘有意/见/分歧’。
由于使用tire与有向无环图结合原理对文本进行分词,结果为一个句子有多种分词方式。对比于Jieba分词细分的三种模式,分别为:精确模式、全模式和搜索引擎模式,我们经过不断的测试和训练和结合我们留言文本内容,最后选择使得这个句子出现概率最大的切分组合。对于留言文本内容分词后,Jieba的精确模式对留言文本进行分词的效果最佳。 最终我们对留言文本分词的部分结果如图4所示:

图4 留言文本分词结果
3.1.4停用过滤词
经过中文分词这一步骤,将初始的文本处理成为词的集合,即d=μ1;u2;,…,un,其中n为文本d中出现词语的个数。但是文本中含有对文本含义表达无意义的词语,这些词的存在及其普遍,且记录这些词在每一个文档中的数量需要很大的磁盘空间,比如文本中的一些副词、语气词以及一些无实际含义的实词,应进行删除,以消除它们对文本挖掘工作的不良影响。
对于虚词,比如文本中的“了”、“啊”、“无论”、“比如”等,特殊符号如“#”、“γ”、“μ”、“φ”等,英文中的“is”、“are”、“the”、“that”等。于此同时,由于在不同文本的应用中,构建的停用词表对文本数据分类的精确度以及维度有着不同程度的影响。
因此我们结和中文分词所分出的词的集合进行人工选取拟定停用此表,我们选取分类词频中前200的词,再通过统计这些分类在其他分类中出现的情况,即一个分词词频在各个类标签中出现词频是200,且该分词在超过四个类中同时出现,我们则将此定义为停用词,具体停用此表详见附录一
使用停用词表的效果示例如下:
原始留言:关于预防先天缺陷的建议
结果:预防 先天 缺陷 建议
3.1.5 方法实现过程
3.1.5.1 n-gram特征
在文本特征提取中,常常能看到n-gram的身影。它是一种基于语言模型的算法,基本思想是将文本内容按照字节顺序进行大小为N的滑动窗口操作,最终形成长度为N的字节片段序列。在本文问题1中,我们经过对数据的不断测试之后,得到的真是效果和时间空间的开销权衡之后,得出2-gram模型最适用且最为合理,即假设我们有有m个词组成的序列(或者说一个句子),根据链式规则,可得到整句的概率P(ω1,ω2,…,ω3),即
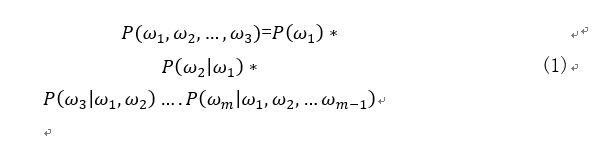
此时由于n=2,因此所构建的二元模型(bigram model)为:
比如任意选取群众问政留言数据中某一条分析如下:
A市何时能实现冬季集中供暖
相应的bigram的特征为:A市 市何 何时 时能 能实 实现 现冬 冬季 季集 集中 中供 供暖
相应的trigram特征为:A市何 市何时 何时能 时能实 能实现 实现冬 现冬季 冬季集 集中供 中供暖
经过以上分词和特征提取步骤,最终得到留言文本部分词频数据如图5所示:
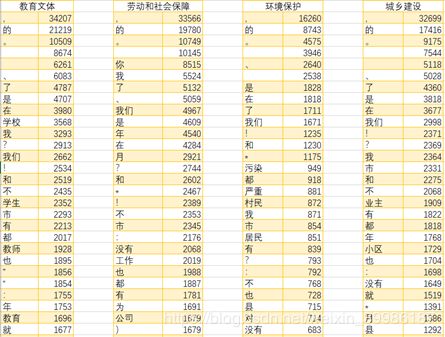
图5 分词频数统计结果
3.1.5.2 Softmax回归
Softmax回归(Softmax Regression)又被称作多项逻辑回归(multinomial logistic regression),它是逻辑回归在处理多类别任务上的推广。
在逻辑回归中,我们有m个被标注的文本:x(1),y(1),.. .,x(m),y(m),其中,x(i)∈Rn。由于类标是二元的,所以我们有y(i)∈{0,1},我们假设(hypothesis)有如下形式:hθx=11+e-θTx代价函数(cost function)如下:
其中1{••}是指示函数,即1{true}=1,1{false}=0
在Softmax回归中,类标是大于2的,因此我们的训练集x(1),y(1),...,x(m),y(m)中,。y(i)∈1,2,…,K。给定一个测试输入x,我们输入一个K维的向量,向量内每个元素的值表示x属于当前类别的概率。
在标准的Softmax回归中,由于要计算y=j时Softmax的概率:P(y=j),因此需要对所有的K个概率做归一化。于是使用Softmax分层示例如图6所示:

图6 Softmax分层示例
3.1.5.3 fastText模型构
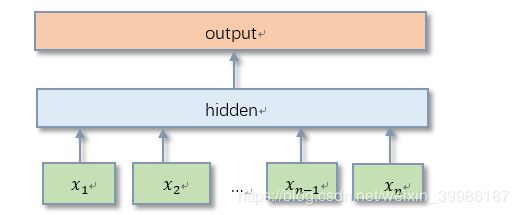
图7 fastText模型构架
fastText模型有三层:输入层、隐含层、输出层。
输入层: 输入层输入的是一批文档,每个文档由一个词汇索引序列构成。例如在处理问题1时,[10 30 80 1000] 可表示“A市 渔业路 洒水车 扰民”这个短文本,其中“A市”、“渔民路”、“洒水车”、“扰民”在词汇表中的索引分别是10、30、80、1000;
隐含层:隐含层对一个文档中的所有文本信息的向量进行叠加平均;
输出层:输出的是一个特定的target;
在输出时,fastText采用了Softmax很大程度上降低了模型训练的时间。
模型搭建遵循以下步骤:
fastText的代码结构以及各模块的功能如图8所示:(代码详见附录二)
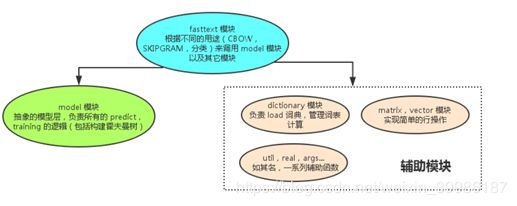
图8 fastText代码结构图
训练数据格式一行为一个句子,每个词用空格分隔,如果一个词带有前缀“__label__”,那,那么它就作为一个类标签,在文本分类时使用。于此同时,经过对数据选取以及对模型参数的不断调节并加以训练,最终得到文本分类的最佳模型,并使用F-Score对分类模型进行评价,最终评价值约为:0.8835
其中,F-Score评价公式为:

其中,Pi为第i类的查准率,Ri为第i类的查全率。
使用fastText分类结果以及F1值结果如表1所示:
表1 留言分类结果
| P |
R |
F |
||
| 劳动和社会障 |
0.937500 |
0.937500 |
0.937500 |
|
| 交通运输 |
0.900000 |
0.725806 |
0.803571 |
|
| 城乡建设 |
0.829268 |
0.880829 |
0.854271 |
|
| 卫生计生 |
0.964286 |
0.830769 |
0.892562 |
|
| 教育文体 |
0.891026 |
0.932886 |
0.911475 |
|
| 商贸旅游 |
0.812500 |
0.873950 |
0.842105 |
|
| 环境保护 |
0.972973 |
0.915254 |
0.943231 |
|

3.2 问题2方法与过程
3.2.1问题分析:
对于话题热度影响指标,在传统的话题中大部分是考虑了新闻的标题、正文等文本信息特征。然而,对于网络留言是有用户的参与,如评论、点赞等。针对新闻报道数据来说,首先,一个话题参与的人数越多,即该话题是人们关注并且讨论较多的,说明该话题在当前时间的是受人们关注的。其次,每个热门话题都经历一个生命周期,即每个话题的“热度”是在给定一段时间内发展的。因此,话题参与人数、点赞人数、反对人数、留言持续时间等可作为话题热度的一个影响指标,体现了用户的参与程度。
总之,再留言数据的背景下,一个“热点”话题具备以下的特点:
- 它有较强的持续性,即被定义为一段时间内多次被人们提及到的事件。
- 它的受欢迎程度(即热度)是随时间变化的。
- 它受人们关注度较高,对于此人们会有较多的赞成或是反对的声音。
3.2.2 话题发现基本流程图
 |
从图10中可知,留言话题发现从文本预处理到文本聚类共有五个主要步骤。首先留言数据公开已知,然后将所得的数据保存到奥文本语料库中;其次,对留言语料进行文本预处理,使用TF-IDF方法进行分词及去除停用词操作,并从预处理后的文本数据中提取特征此项建立文本表示模型;然后,用相似的度量报道与话题的相关性;最后通过文本聚类算法,把相似的高的留言加到对应的话题簇中,这样就得到了话题簇。
3.2.3 文本预处理
3.2.3.1 留言文本分词
同样的,我们使用问题1中的Jieba之精度确认模式对留言文本数据进行分词,然后构造通用词去除没有实际意义的词语。具体操作流程已经在问题1中进行详细描述,在此处不在重述。
最终得到留言分词结果如图11所示:

图11 留言分词结果
使用停用词,去掉留言文本中的虚词即副词、语气词等与无实际意义的词后,得到部分结果如图12所示:

图12 留言文本去停用词结果
3.2.4 留言信息特征提取
本文采用向量空间模型表示留言文本信息。将一个留言文本数据d表示n维向量,即d=t1,w1;t2,w2;…;ti,wi;…;tn,wn;,其中:n是d中的特征总数,ti(1
本文用TD-IDF计算特征词项权重,具体操作如下:
该操作的主要目的有两个,第一,为了提高程序的效率,提高运行速度;第二,所有词汇对文本分类的意义是不同,一些通用的、各个类别都普遍存在的词汇对分类的贡献小,为了提高精度,对于每一类应去除那些表现力不强的词汇,筛选出针对该类的特征项集合,采用了TFIDF方法来进行特征选择。该方法所用的主要公式如下所示,
TD-IDF的计算:
以及基于TF-IDF算法对留言文本进行分词以及关键字的提取,其中经过分词后统计词频所用的计算原理如下:
假设文档集合

其中,TF(term frequency,TF):词频,某个给定词语在该文件中出现的次数,计算公式为:

IDF(inverse document frequency,IDF):逆文件频率,如果半酣词条的文件越少,则说明词条具有很好的类别区分能力,计算公式为:

根据上面的计算我们可以算出文件,单词条w的TD-IDF权值W[i][j]= TD(j)*IDF(j)。其中i为文件集合T中的一个文件,而j是文件集合T中的一个单词。
通过对文件集合T的计算我们可以得到二维数组(矩阵)W[i][j].最终得到的特征此项如附录二,部分词项如图13所示:

图13 提取词项关键词
3.2.5 话题的表示模型
3.2.5.1 k-means聚类算法
对于留言文本语料进行话题发现时,我们无法预测会有多少个留言话题,以及何时又出现新的话题。因此,这个领域研究也等同于对无监督、无指导的聚类算法分析。聚类算法就是无监督的机械学习方法,将数据集划分为不同的类簇。将每个族看成是一个话题, 然后运用k-means聚类方法采用距离作为相似性的评价指标,即认为两个对象的距离越近,其相似度就越大。该算法认为簇是由距离靠近的对象组成的,因此把得到紧凑且独立的簇作为最终目标。其中,k个聚类具有以下特点:各聚类本身尽可能的紧凑,而各聚类之间尽可能的分开。
3.2.5.2 k-means聚类的迭代过程:
1.随机选取k个文件生成k个聚类cluster,k个文件分别对应这k个聚类的聚类中心Mean(cluster) = k ;对应的操作为从W[i][j]中0~i的范围内选k行(每一行代表一个样本),分别生成k个聚类,并使得聚类的中心mean为该行。
2.对W[i][j]的每一行,分别计算它们与k个聚类中心的距离(通过欧氏距离)distance(i,k)。
3.对W[i][j]的每一行,分别计算它们最近的一个聚类中心的n(i) = ki。
4.判断W[i][j]的每一行所代表的样本是否属于聚类,若所有样本最近的n(i)聚类就是它们的目前所属的聚类则结束迭代,否则进行下一步。
5.根据n(i) ,将样本i加入到聚类k中,重新计算计算每个聚类中心(去聚类中各个样本的平均值),调到第2步。
3.2.5.3 中心点的选择
k-means算法的能够保证收敛,但不能保证收敛于全局最优点,当初始中心点选取不好时,只能达到局部最优点,整个聚类的效果也会比较差。我们采用以下方法来确定k-means中心点:
- 选择彼此距离尽可能远的那些点作为中心点,对于sklearn中:
Km=KMeans(init=’k-means++’)
- 先采用层次进行初步聚类输出k个簇,以簇的中心点的作为k-means的中心点的输入。Km=KMeans(init=’random’)
- 多次随机选择中心点训练k-means,选择效果最好的聚类效果
3.2.3.3 K值的选择的依据
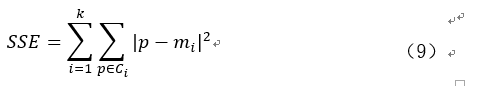
其中,Ci是第i个簇,p是Ci中个的样本点,mi是Ci的质心(Ci中所有样本的均值),SSE是所有样本的聚类误差,代表了聚类效果的好坏。
3.2.5.4 每个点到中心点的欧氏距离
欧几里得距离的定义如下:

其中xi,yi是文件单词的TD-IDF值和聚类中心的TD-IDF值,就可以算出与k个聚类中心的距离。对W[i][j]的每一行,分别计算它们最近的一个聚类中心的n(i) = ki,并且判断W[i][j]的每一行所代表的样本是否属于聚类。
基于簇内误差平方和如公式(9),使用肘方法确定簇的最佳数量,该方法的基本理念就是找出聚类偏差骤增的k值。最后,经过不断的测试和训练,最终我们得到当k=1500时,留言文本的聚类效果最佳。 最终的聚类结果以及代码实现如附录三。
3.2.6 热值计算
基于以上步骤,我们得到留言文本的聚类结果,即是把留言文本数据中相似的留言话题聚类,然后将其划分为同一类。与此同时,对于聚类后的不同话题,需对其进行话题热点的确定。在现实生活中,热点问题的确定伴随着诸多因素的作用,但在的已知数据中,我们将话题的点赞数、反对数、话题留言人数量以及该话题的活跃天数(即持续时间)作为热点话题的印象因子。再确定各因子间对一个话题的影响力度,从而确定各个因子的权值。在这里,我们进入符号:

由于留言是人们对生活各种问题的反映,希望将问题反映到相关工作部门,提高工作效率。因此,在一个话题中,一方面是点赞数即代表着人们支持的态度,点赞数α越多,意味着人们更迫切相关工作部门尽快给予回复与解决方案,即点赞人数α对话题热点值是起到正向促进作用;另一方面,反对人数β越多,说明该话题的实际意义不大,则反对人数β对话题热点值起到反向削弱作用;与此同时,话题留言数量越多γ则说明人们关注点集中,对话题热点值是起到正向促进作用,且活跃天数δ持续越长,说明话题人们持续关注,对话题热点值是起到正向促进作用。
于是有,话题热点值计算公式如下:
![]()
最终得到话题的聚类结果与话题热值的具体代码实现过程如附录三。
3.2.7 文本聚类话题提取
根据得到的聚合的话题类别,我们参考类似于数据附录1中二级标题与三级标题,再结合留言数据的文本内容,经过人工的不断提炼,得到全部话题分类之主题提取结果及具体实现代码如附录二所示,其中,排名前五的热点话题相关内容如表2与图14所示:
表2 排名前五的热点
| 热度排名 |
问题ID |
热度指数 |
时间范围 |
地点人群 |
问题描述 |
|
| 1 |
163 |
730 |
2017.06.08 至2019.11.27 |
A市经济学院学生 |
学校强制学生外出工作和实行问题 |
|
| 2 |
197 |
714.4 |
2019.04.11至2019.11.22 |
A市A3区 |
购房配套入学与孩子受教育权利问题 |
|
| 3 |
444 |
630.3 |
2019.08.19 至2019.08.19 |
A市A5区 |
小区住房安全保障与租房制度混乱一系列问题 |
|
| 4 |
547 |
395.8 |
2019.01.12至2019.-09.05 |
A市A4区 |
绿地海外滩小区高铁对周边影响问题 |
|
| 5 |
1332 |
394.4 |
2019.01.11至2019.07.08 |
A市 |
非法经营车贷并创造车贷诈骗案问题 |
|
|
|
|
|
|
|
|
|

根据表2与图14可知,排名第一的热点问题是A市A5区汇金路五矿万境小区住房安全保障与租房制度混乱问题,其问题ID为235,话题热度值为842.6;排名第二的热点问题是A市A3区学校强制学生外出工作和实行问题,其问题ID为150,话题热度值为768.7;排名第三的热点问题是A市金毛湾与A市华润琨瑜府购房配套入学与孩子受教育权利问题,其问题ID为120,话题热度值为689.4;排名第四的热点问题是A市A4区非法经营车贷并创造车贷诈骗案问题,其话题热度值为618.4;排名第五的热点问题是A市A2至A7区区民街道乱象与长期脏乱问题,其问题ID为70,话题热度值为512.1;
3.3 问题3方法与过程
3.3.1 问题分析
在日常生活中,人们渴望对“政务”的留言得到政府以及相关工作部门的合理回复和解决方案与政府以及相关工作部门希望能够给人民一个好的答复意见是一个相互的过程。那么,在这个信息发达的时代,人们利用留言的方式向政府以及相关工作部门吐露“心声”,但是对于政府以及相关工作部门的回复,我们需要有一个评价标准以判断政府以及相关工作部门所给答复意见的质量。一方面这不但确保人民提出的问题是否可以得到有效的解决,另一方面是又可以作为一个评价政府以及相关工作部门的工作效率。
对于如何构建答复意见质量评价指标与模型,本文主要从以下几个步骤进行分析与处理,首先针对相关部门对留言所给的答复意见选取答复意见数据特征,然后根据答复意见文本提取其他主要特诊,并通过各种计算和编程得到适合模型的指标变量以及答复意见数据质量评价指标,最后建立相关工作部门对留言答复意见质量的评价指标。整个操作过程路程图如图15所示:
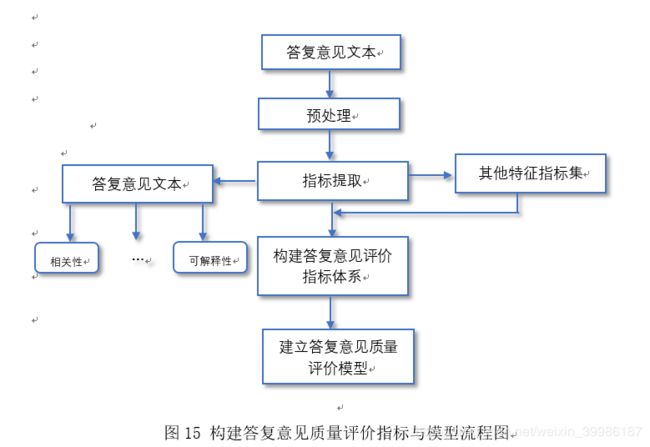
3.3.2 预处理
由于答复意见是以文本的形式存在的,其复杂度相比于数值型要复杂的多。因此我们根据整理好的答复意见内容,对数据经过一系列的计算和编程处理,提取出于留言主题相关度和答复意见一致性等指标因素。于此同时,为保证数据的质量,降低一些无关数据对我们实验结果精确率的影响,因此我们需要对以获得的数据进行预处理和一些特殊处理,以达到优化数据的效果。其中预处理的过程主要包括以下几个方面:
- 对于回复答复意见重复的数,保留重复答复意见中的一条;
- 删除无实际意义的答复意见数据
- 使用停用词剔除答复意见文本内容中的无用词,比如语气词、介词、副词等无实际意义的词;
3.3.3 指标提取
指标提取是对答复意见数据进行分析的一项重要步骤。根据留言的内容,即是从人们留言所反馈的问题意见中提取特征。对于本文在指标提取中发现的一些无关指标(引用)不在此处列出,本文对于答复意见文本信息中提取的主要特征指标有相关性、完整性、可解读等。对于以上特征指标我们通过以下不同的方式获得:
3.3.3.1 相关性
对于答复意见集中每一条答复对应语料库中的一个问大哥,通常用向量的形式来表达,由于两个相似的文档会有相似的主题,因此可以通过计算文档之间的距离来集散其相似度。本文运用预先相似度计算方法来计算留言主题与相关工作部门的答复意见之间的相似度。
其中,余弦函数在三角形中的计算公式为:

在直角坐标系中假设向量a用坐标(x1,y1)表示,向量b用坐标(x2,y2)表示,向量a和向量b中在直角坐标中长度为a=x12+y12,b=x22+y22,向量a与b之间的距离我们用向量c表示,则c=x2-x12+y2-y12,最后,将a,b,c代入三角函数的公式中得到如下的公式:
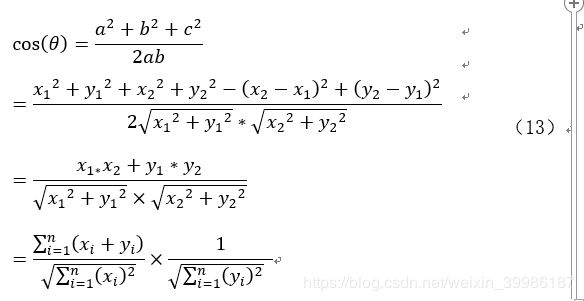
其中,一个向量空间中两个向量的夹角余弦值作为衡量两个个体之间差异的大小,当与相知接近1,夹角趋于0度时,说明两个向量越相似。当余弦值接近于0,夹角区域90度时,表明两个向量越不相似。
比如对已经进行分词后的两个句子:
句子A:A市特殊岗位
句子B:L市扶贫特岗
- 分词后分别得到两个列表:
ListA={‘A市’,‘特殊’,‘岗位’}
ListB={‘A市’,‘扶贫’,‘持’,‘岗’}
- 列出所有的词,将ListA和ListB放在一个 set中,得到:
set={‘A市’,‘特殊’,’扶贫’,‘岗位’,‘持’,‘岗’}
将上述set转换为dict,key为set中的词,value为set中词出现的位置,即‘A市’:1这样的字典形式。
Dict1={‘A市’:0,‘特殊’:1,’扶贫’:2,‘岗位’:3,‘持’:4,‘岗’:5 }可以看出‘A市’这个词在set中排在第一,下标为0。
- 将ListA于ListB进行编码,将每个字转换为出现在set中的位置,转换后为:
ListAcode={0,1,3}
ListBcode={0,2,3,4}
对于ListAcode于ListBcode,可以得到0对应‘A市’,3对应‘岗位’,即ListAcode与ListBcode转换为用数字表示
- 对ListAcode与ListBcode进行oneHot编码,即计算每个分词出现的次数。oneHot编号后得到的结果如下:
ListAcodeoneHot={0,1,1,1}
ListAcodeoneHot={1,0,1,1}
- 得出俩个句子的词频向量后,就变成了计算两个向量夹角的余弦值,余弦值越大相似度越高。
|
|
 |
根据余弦值相似度,可以得出句子A与句子B相似度较高。
答复意见与留言主题相关度越高,则该答复建议对主题的价值越大,其质量越高。本文选取一个阈值,进而筛选出每个主题相关度大于该阈值的评论作为该主题下质量较高的答复建议。得到部门留言与答复意见之间的相关性关系如图16所示:
3.3.4.2 可解释性
可解释性本文指的是可以追踪到数据来源,对于答复建议而言,可解释性对于中文答复意见来说意义不大,我们可以将可解释性理解为可读性,
相关工作部门答复意见的可读性可以用自动化可读性指数ARI(Automated Readability Index) 来表示。ARI的计算公式为:
![]()
其数值近似等于我们可以理解一段文字的最低程度。我们将绘制部分部门id留言以及相关部门答复意见之间的可解释性程度如图17
3.3.4.3 信息量
信息量,也称答复意见长度,他表示答复意见内容的多少。通常认为,答复意见越多表明包含的有用信息越多,对于人们的参考价值越大,同时在一定程度上会增加人们对相关工作部门的信服力,以帮助留言群众可到较为满意的答复。在本文中,我们使用文本的数字表示,答复意见中内容中,少于10个子为0.1分。11至20为0.2分,以此类推,大于90及以上为1分。
3.3.5确定评价指标权重
关于相关工作部门答复意见质量评价模型的研究,不同的评价指标权重将会得到不同的结果。基于以上我们得到的相关评价指标,并通过计算以及编程实现得到具体的成分值,于是本文应用基于主成分分析之权值计算方法,算出为接下来即将要构建的评价模型中各个评价指标的权重。
首先将所得相关工作部门答复意见中每天数据对应的各个评价指标的数据进行标准化,以降低各个不同评价指标中的量纲差异度。本文应用SPSS软件自带的数据标准版方法对数据进行标准化处理。
其次将标准化后的数据导入SPSS,对各个评价指标进行主成分分析以及权值的计算,得到结果如图18所示:

从图18中可直观看出,4个主成分累计的方差贡献率超过80%,因此4个主成分基本可以反应全部指标的信息。其中主成分1为信息量,主成分2为可解释性,主成分3为相关性,主成分4为时效性。
再者,利用SPSS对评价指标主成分分析得到的成分矩阵如图19所示:

图19 成分矩阵图
基于图18与图19,我们可以对信息量、可解释性、相关性、时效性4个主成分评价指标进行权重计算,权重确定具体计算过程如下:
首先将主成分分析中得出的“成分矩阵”及特征根输入;
然后计算线性组合中的系数,公式为:

其中,bj表示的是第i主成分第j变量的线性组合系数,aij表示的是第i主成分的第j变量的载荷数,ci表示的是第i主成分的特征根;
进而计算综合得分模型中的系数,公式为:
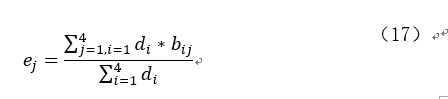
其中 di表示的第i主成分的方差,ej表示的是得分模型中第j变量的系数;
最后将所有指标数据进行归一化,使其权重综合为1,其中计算公式为:

其中indexj,表示的是指标权重。
基于以上步骤,最终得到的各个不同评价指标的权重值和其模型系数如图3所示:
表3 评级指标权重值以及系数表
| 评价指标 |
综合得分模型中的系数 |
指标权重 |
| LEN |
0.420458342 |
0.28 |
| SIM |
0.396046336 |
0.26 |
| ARI |
0.420013309 |
0.28 |
| REPLY |
0.270383824 |
0.18 |
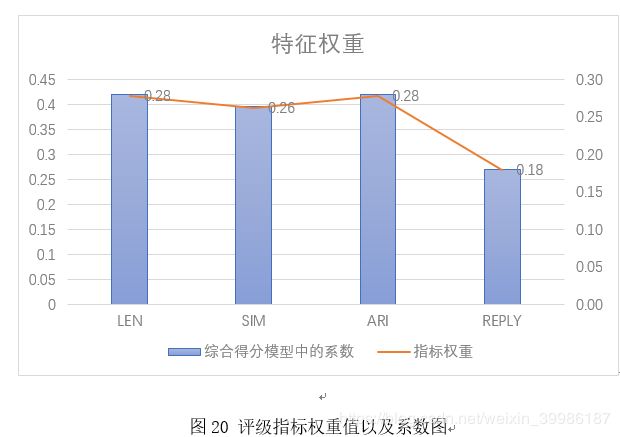
在图20中,LEN、SIM、ARI、REPLY分别对应评价指标信息量、相关性、可解释性、时效性。且其在综合得分模型中的系数分别为0.420458342、0.396046336、0.420013309、0.270383824,其权重分别为0.28、0.26、0.28、0.18。
3.3.6 构建答复意见质量评价指标体系
表4 答复意见质量评价指标
| 指标 |
说明 |
| 相关性 |
答复意见于留言主题的相关性 |
| 可解释性 |
关工作部门答复意见的可读性可以用自动化可读性指数ARI |
| 完整性 |
完整的数据标记为1,不完整则记为0 |
| 时效性 |
即留言时间与答复意见时间间隔,时间越短,时效性越高,反之则越低 |
| 信息量 |
从内容上确保答复意见质量,以答复意见长度衡量(词/字数统计) |
根据上文提取的指标特征,我们构建广义线性回归模型对相关工作部门的答复意见质量进行分析,以答复意见中提取到的相关特征,并利用成熟的回归或分类算法建立研究模型,最后对答复意见的质量进行预测。在本文中用Quality表示答复意见的质量,
引入符号:

则,建立回归模型如下
![]()
根据以上步骤计算得出各个评价指标的权重为φi=0.28,0.26,0.28,0.18 其中,ε表示常数项,φi=φ1,φ2,φ3,φ4表示各个评价指标对应的权值。
代入公式(19),并经过模型训练得到
Q=0.28Words+0.26Relevancy+0.28Credibility+0.18Timeliness+0.01
3.3.7 模型实验结果分析
在实验过程中,为了平衡模型,对文本模型的目标值数据进行标准化,保证实验数据同负一取值在[0,1]之间,并且我们规定对答复意见质量的评价,当Q取值在[0,0.5)之间,表示该答复意见质量较低,当Q取值在[0.5,1]之间则答复意见为高质量回复。
4 结论
本文经过阅读大量文献,进一步对“智慧政务“中的文本即群众的留言数、群众关心的热点问题、以及相关工作部门的解决方案数据进行内在信息的挖掘与分析。,整个过程包括数据筛选与特征提取处理,通过聚类分析,构建评价指标与建模,建模的验证分析等,最后得出本研究提出的模型具有良好的性能。本文主要结论如下:
- 对获得的留言数据利用基于Python的fastText原理,实现了对留言数据的分类,提升了可建模度,增加了模型的准确性。
- 聚类分析指将物理或抽象对象的集合分组成为由类似的对象组成的多个类的分析过程,利用k-means文本聚类算法,能更好的把留言加入对应的话题簇,能够对热点问题进行更好的分类。
- 在构建答复意见质量评价指标与模型中,通过提取的指标特征构建广义线性回归模型对相关部门的答复意见质量进行分析。为了平衡模型,我们对文本模型的目标值进行标准化,能够使对答复意见质量的评价更为准确。
参考文献
[1]艾楚涵,姜迪,吴建德.基于主题模型和文本相似度计算的专利推荐研究[J].信息技术,2020,44(04):65-70.
[2]王光慈,汪洋.基于FastText的短文本分类[J].电子设计工程,2020,28(03):98-101.
[3]王俊丰,贾晓霞,李志强.基于K-means算法改进的短文本聚类研究与实现[J].信息技术,2019,43(12):76-80.
[4]张弛,张贯虹.基于词向量和多特征语义距离的文本聚类算法[J].重庆科技学院学报(自然科学版),2019,21(03):69-72+77.
[5]冯勇,屈渤浩,徐红艳,王嵘冰,张永刚.融合TF-IDF和LDA的中文FastText短文本分类方法[J].应用科学学报,2019,37(03):378-388.
[6]郭银灵. 基于文本分析的在线评论质量评价模型研究[D].内蒙古大学,2017.
[7]王小华,徐宁,谌志群.基于共词分析的文本主题词聚类与主题发现[J].情报科学,2011,29(11):1621-1624.
[6]郭银灵. 基于文本分析的在线评论质量评价模型研究[D].内蒙古大学,2017.
[8]王小华,徐宁,谌志群.基于共词分析的文本主题词聚类与主题发现[J].情报科学,2011,29(11):1621-1624.
[9]Nan Hu,Indranil Bose,Noi Sian Koh etc.Manipulation od online reviews:An analysis of ratings,readability,and sentiments,2012(52):674-684.
[10]R.J.Senter,E.A.SmithAutomated readability index[OL]. http://oai.dtic.mil/oai/oai?verb=get Record&metadataPrefix=html&identifier=AD06672731967.Technical Report,1997.
[11]Titov I, McDonald R. Modeling Online Reviews with Multi-grain Topic Models(C].1n:
Proceedings of the17th International Conference on World Wide Web(WWW(8).New York:ACM, 2008:Il1.120.