在启用了HDFS HA的集群误删了一个NameNode解决实践
在启用了HDFS HA的集群,2个NameNode节点上一般都会部署三个角色:NameNode,JournalNode和Failover Controller。在实际生产中,我们有时会碰到一个情况,你不小心删掉了某个NameNode节点上的所有角色包括NameNode,JournalNode和Failover Controller,或者你不小心通过Cloudera Manager直接从主机管理列表里移除了该NameNode节点,然后你想再把这个节点加回去的时候,发现无论如何HDFS服务都没办法正常使用了。本文会在一个HDFS HA的CDH集群中模拟这种情况,然后尝试去解决,即先删除一个NameNode,然后如何通过配置将该NameNode重新加回到HDFS服务中。
- 测试环境
1.CDH6.1
2.Redhat7.4
3.采用root进行操作
2
模拟异常
1.首先Fayson准备一个正常的CDH6.1的集群,并且HDFS已经启用了HA。
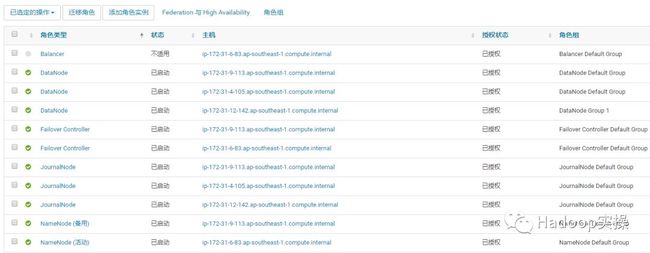
2.我们停止ip-172-31-9-113.ap-southeast-1.compute.internal节点上的NameNode,JournalNode和Failover Controller服务。
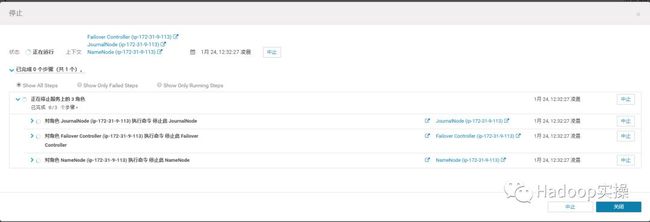
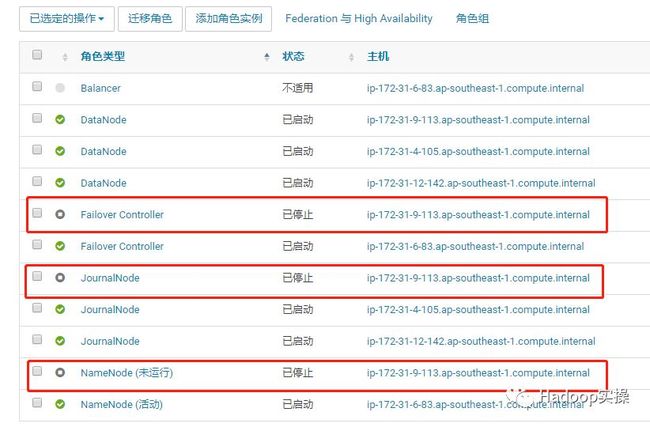
3.删除这三个角色,注意下表已经少了这三个角色。
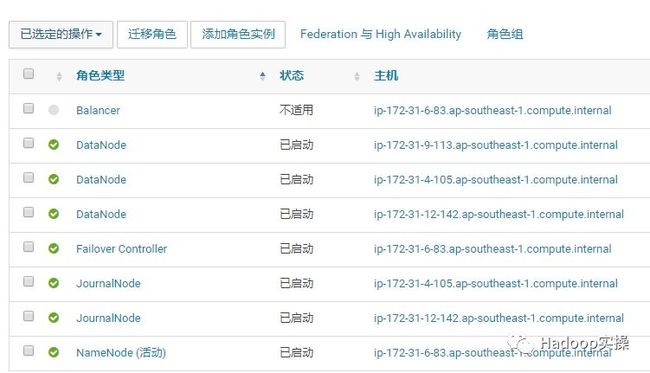
4.这时HDFS服务直接报错了。
3 个验证错误。
Quorum Journal 需要至少三个 JournalNode
Quorum Journal 需要奇数的 JournalNode
Nameservice nameservice1 has no SecondaryNameNode or High-Availability partner
1 个验证警告。
在 NameNode (ip-172-31-6-83) 个非 HA Nameservice nameservice1 上启用自动故障转移不起作用。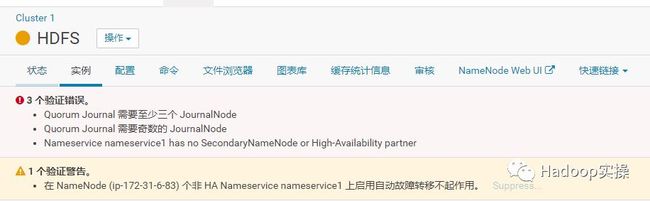
故障修复方法1
1.我们选择HDFS服务,然后点击“操作”,发现虽然是HDFS HA的集群,操作列表显示却是“启用High Availability”,实际应该是“禁用High Availability”,应该是因为手动删除了一个NameNode后引起的。
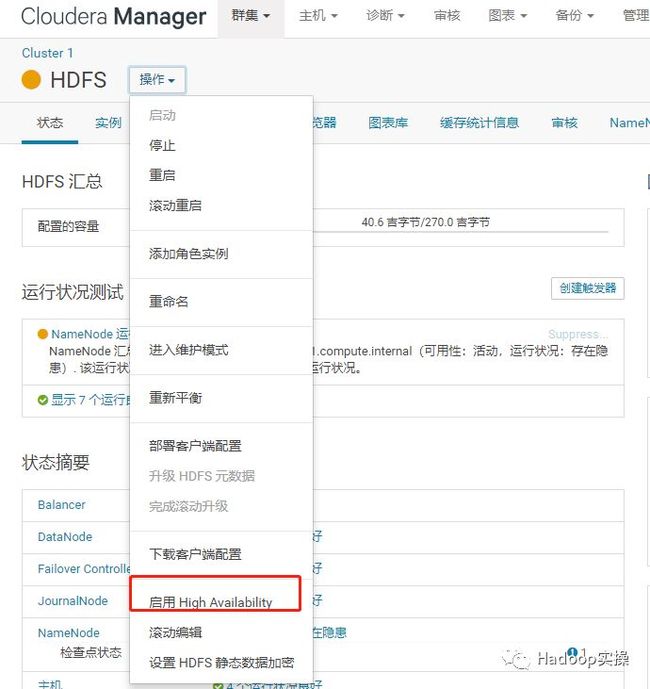
2.我们先尝试点击该按钮,尝试重新启用HDFS的HA。
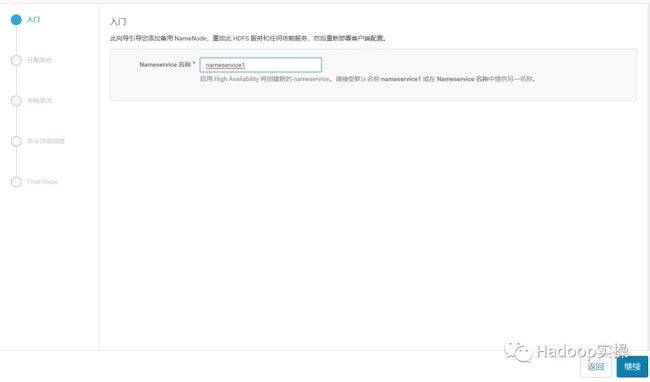
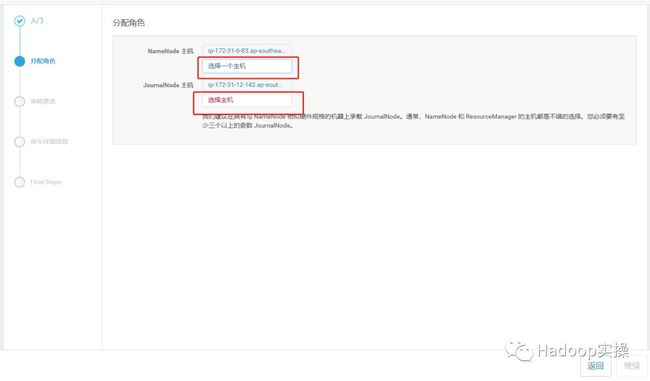
这里我们选择之前的删掉的NameNode和JournalNode节点
ip-172-31-9-113.ap-southeast-1.compute.internal
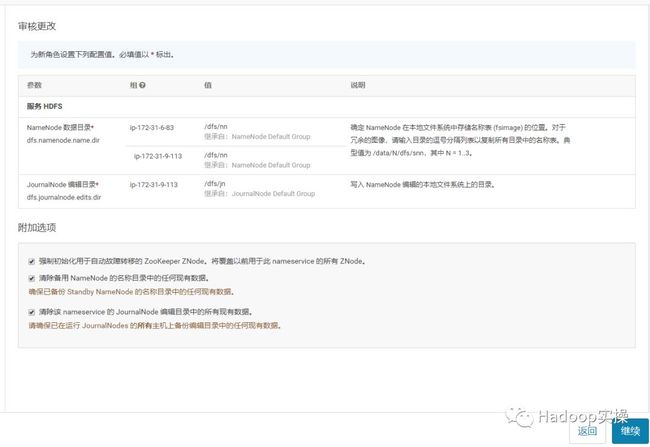
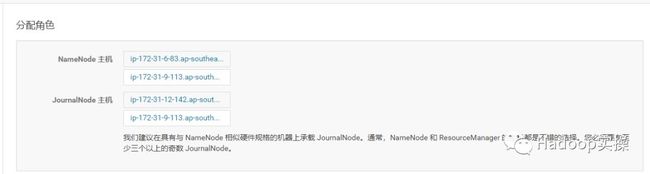

报错,启用失败,实际其实我们已经选择了三个JournalNode,但仍旧报错需要3个JournalNode,返回,我们继续尝试。
故障修复方法2 --我用的该方法直接把误删的namenode加上去修改配置重启即可
1.从以下界面把删掉的NameNode,JournalNode和Failover Controller的三个角色再给加回去。
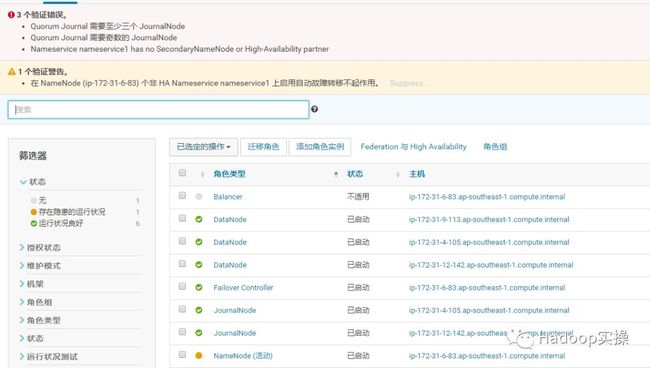
2.点击添加角色实例,并相应的选择之前删掉NameNode,JournalNode和Failover Controller角色所在的主机ip-172-31-9-113.ap-southeast-1.compute.internal
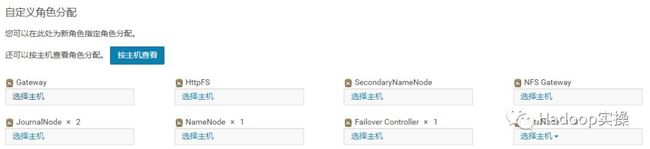
3.点击“继续”
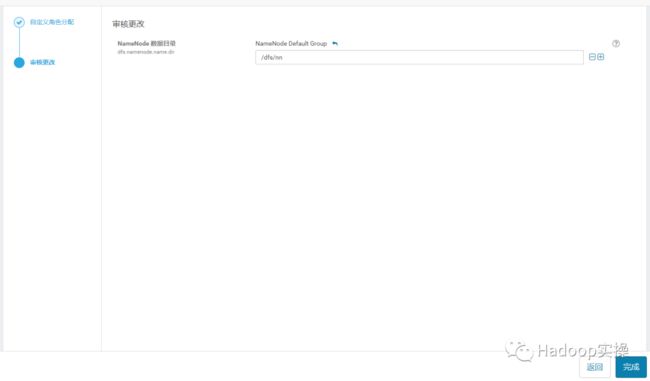 4.点击“完成”
4.点击“完成”
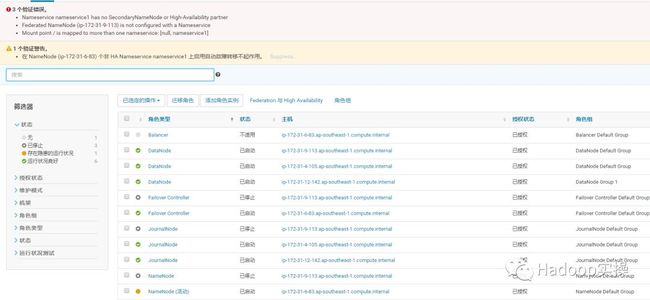
5.直接重启HDFS服务,尝试拉起刚刚新加的三个角色

还是失败。
6.进入ip-172-31-9-113.ap-southeast-1.compute.internal节点所在的NameNode配置页面。
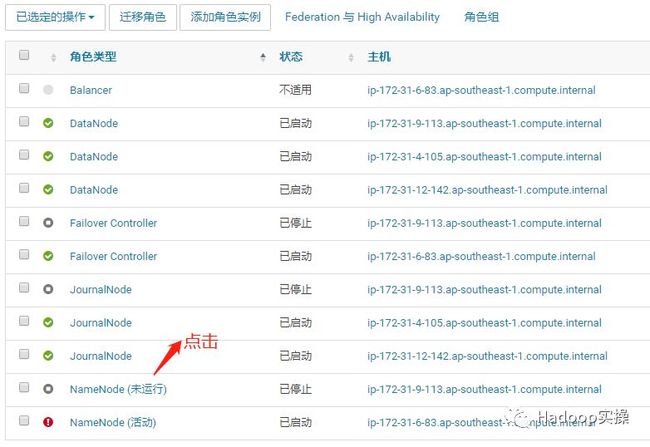
选择“配置”标签页
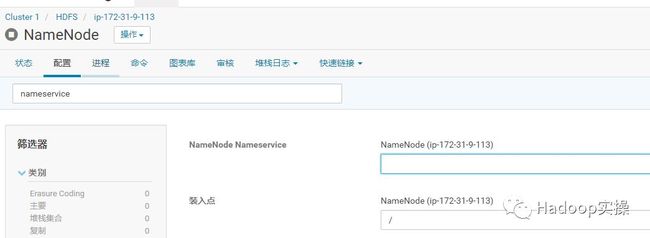
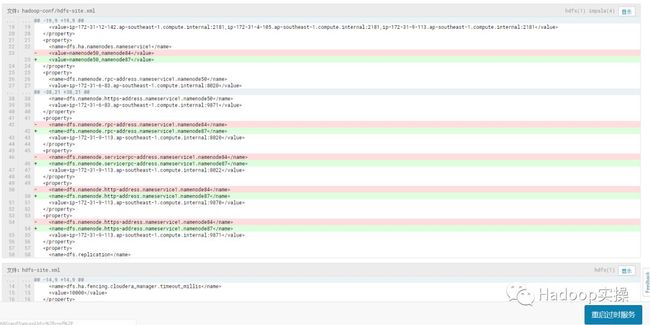
在“NameNode Nameservice”配置项中输入nameservice1,这里根据你集群启用HA后的实际情况nameservice的名字输入,然后保存。
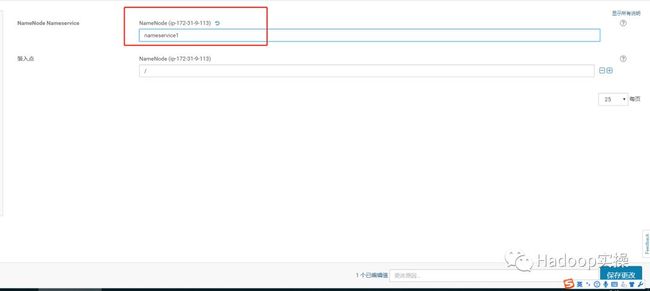
7.在“Quorum Journal 名称”配置项也输入nameservice1,这里根据你集群启用HA后的实际情况nameservice的名字输入,然后保存。
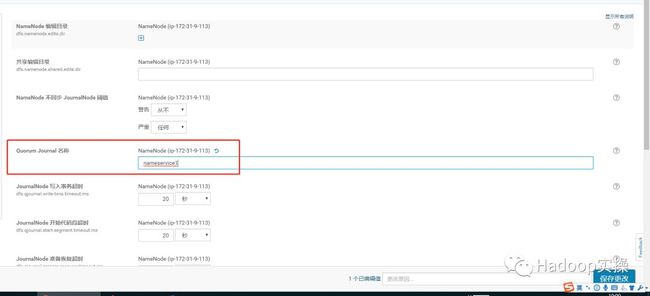
8.勾选“启用自动故障转移”,然后保存。
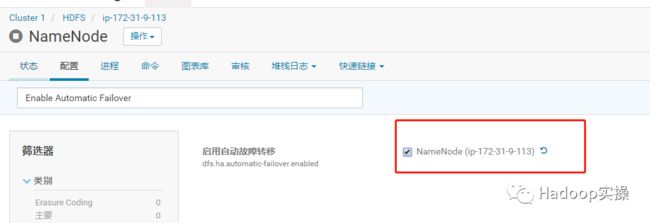
9.回到HDFS服务的实例页面,发现之前的错误已经消失了。
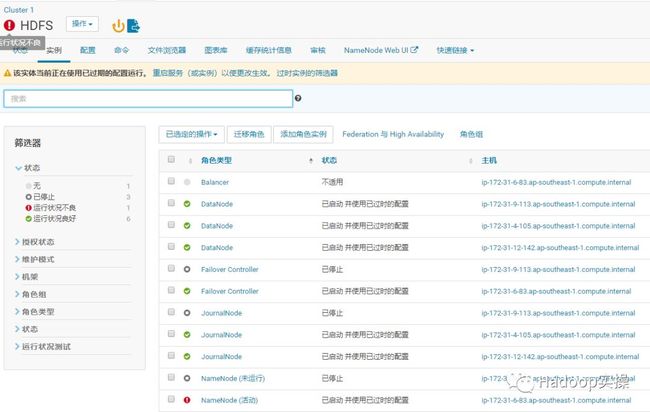
10.回到CM主页重新部署客户端,并重启集群所有服务。
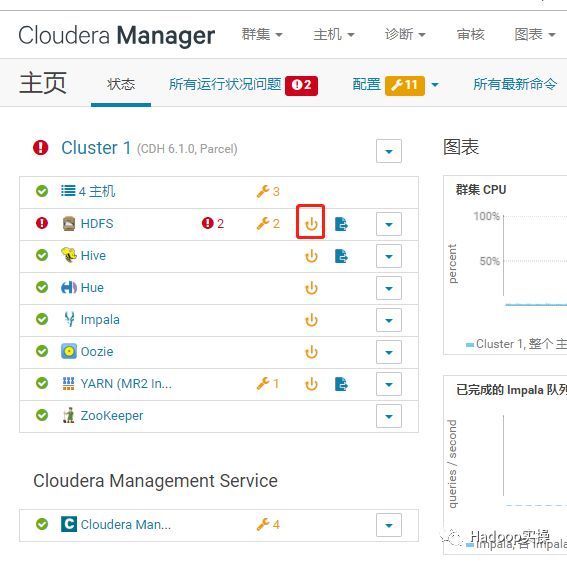
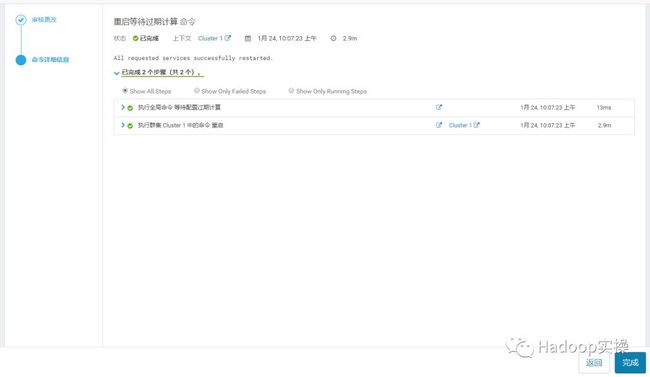
重启成功,集群恢复正常。
我这边参照方法2解决后的测试:
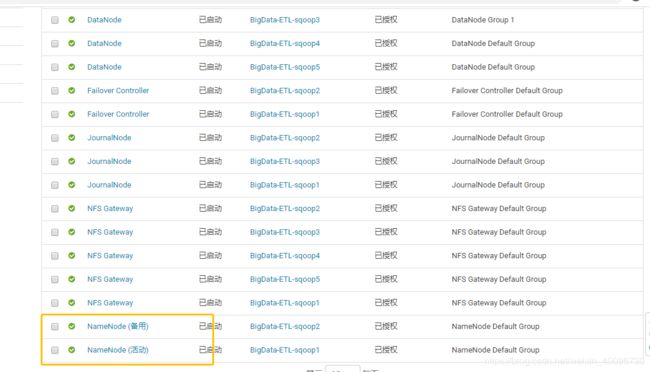
测试hive
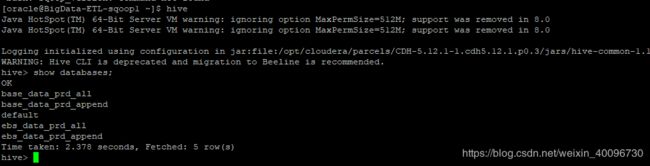 测试sqoop
测试sqoop
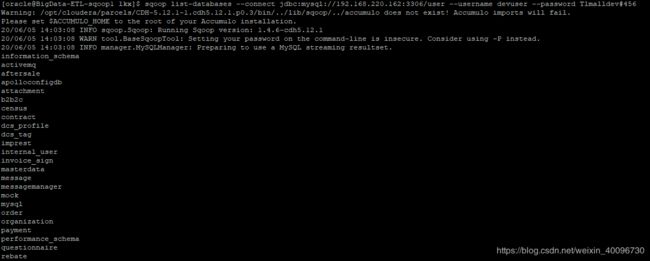
一切正常!
参考:https://mp.weixin.qq.com/s?__biz=MzI4OTY3MTUyNg==&mid=2247495873&idx=1&sn=2aa2057c70e954baa3cecd4ab2a8c170&chksm=ec2920c8db5ea9deb61c51a76d2d170df51ff7ff78f4ec9223123ee829791ff199a989b7d9ac&scene=21#wechat_redirect