【计算机视觉】图像检索
目录
-
- 一、图像检索基本概述
- 二、基于Bag of words模型的图像检索
- (一)Bag of words模型简介
- 1、Bag of words模型
- 2、Bag of words模型在计算机视觉中的应用
- (二)Bag of features算法
- 1、Bag of features算法基础流程
- 2、补充:K-means算法
- 2.1 K-means算法简介
- 2.2 K-means算法基本步骤
- 三、实验代码及结果
一、图像检索基本概述
从20世纪70年代开始,有关图像检索的研究就已开始,当时主要是基于文本的图像检索技术(简称TBIR),利用文本描述的方式描述图像的特征,如绘画作品的作者、年代、流派、尺寸等。
到90年代以后,出现了对图像的内容语义,如图像的颜色、纹理、布局等进行分析和检索的图像检索技术,即基于内容的图像检索(简称CBIR)技术。CBIR属于基于内容检索(简称CBR)的一种,CBR中还包括对动态视频、音频等其它形式多媒体信息的检索技术。
在检索原理上,无论是基于文本的图像检索还是基于内容的图像检索,主要包括三方面:一方面对用户需求的分析和转化,形成可以检索索引数据库的提问;另一方面,收集和加工图像资源,提取特征,分析并进行标引,建立图像的索引数据库;最后一方面是根据相似度算法,计算用户提问与索引数据库中记录的相似度大小,提取出满足阈值的记录作为结果,按照相似度降序的方式输出。
为了进一步提高检索的准确性,许多系统结合相关反馈技术来收集用户对检索结果的反馈信息,这在CBIR中显得更为突出,因为CBIR实现的是逐步求精的图像检索过程,在同一次检索过程中需要不断地与用户进行交互。
二、基于Bag of words模型的图像检索
(一)Bag of words模型简介
1、Bag of words模型
Bag-of-words模型是信息检索领域常用的文档表示方法。在信息检索中,BOW模型假定对于一个文档,忽略它的单词顺序和语法、句法等要素,将其仅仅看作是若干个词汇的集合,文档中每个单词的出现都是独立的,不依赖于其它单词是否出现。也就是说,文档中任意一个位置出现的任何单词,都不受该文档语意影响而独立选择的。
例如有如下两个文档:
1:Bob likes to play basketball, Jim likes too.
2:Bob also likes to play football games.
基于这两个文本文档,构造一个词典:
Dictionary = {1:”Bob”, 2. “like”, 3. “to”, 4. “play”, 5. “basketball”, 6. “also”, 7. “football”, 8. “games”, 9. “Jim”, 10. “too”}。
这个词典一共包含10个不同的单词,利用词典的索引号,上面两个文档每一个都可以用一个10维向量表示(用整数数字0~n(n为正整数)表示某个单词在文档中出现的次数):
1:[1, 2, 1, 1, 1, 0, 0, 0, 1, 1]
2:[1, 1, 1, 1 ,0, 1, 1, 1, 0, 0]
向量中每个元素表示词典中相关元素在文档中出现的次数(/可用单词的直方图表示)。
2、Bag of words模型在计算机视觉中的应用
计算机视觉领域的研究者们尝试将同样的思想应用到图像处理和识别领域,建立了由文本处理技术向图像领域的过渡。将文本分类问题与图像分类问题相比较,会发现这样的问题,对于文本来讲,文本是由单词组成的,因此提取关键词的过程也是顺理成章,没有任何歧义或者限制。但对于图像来讲,如何定义图像的“单词”,则是需要首先解决的问题之一。
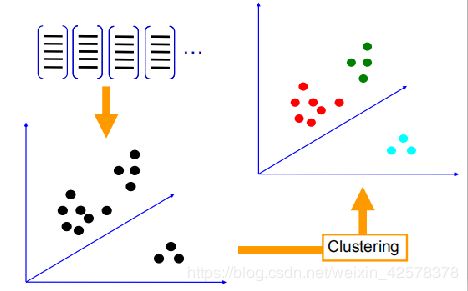
研究者们通过对 BoW 模型进行研究和探索,提出了采用k -means 聚类方法对所提取的大量特征进行无监督聚类,将具有相似性较强的特征归入到一个聚类类别里,定义每个聚类的中心即为图像的“单词”,聚类类别的数量即为整个视觉词典的大小。这样,每个图像就可以由一系列具有代表性的视觉单词来表示,如下图所示。

根据Bow模型的思想延伸出了Bag of features算法。
(二)Bag of features算法
Bag of features,简称Bof,中文翻译为“词袋”,是一种用于图像或视频检索的技术。而检索就要进行比对。两幅不同的图像如何比对,比对什么,这就需要提炼出每幅图像中精练的东西出来进行比较。
1、Bag of features算法基础流程
1、收集图片,对图像进行sift特征提取。

2、从每类图像中提取视觉词汇,将所有的视觉词汇集合在一起。
3、利用K-Means算法构造单词表。
K-Means算法是一种基于样本间相似性度量的间接聚类方法,此算法以K为参数,把N个对象分为K个簇,以使簇内具有较高的相似度,而簇间相似度较低。SIFT提取的视觉词汇向量之间根据距离的远近,可以利用K-Means算法将词义相近的词汇合并,作为单词表中的基础词汇,假定我们将K设为3,那么单词表的构造过程如下:
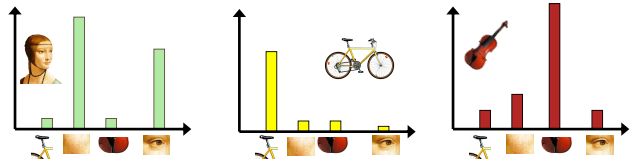
4、针对输入的特征集,根据视觉词典进行量化,把输入图像转化成视觉单词的频率直方图。
5、构造特征到图像的倒排表,通过倒排表快速索引相关图像。
6、根据索引结果进行直方图匹配。
2、补充:K-means算法
2.1 K-means算法简介
k-means算法是一种聚类算法,所谓聚类,即根据相似性原则,将具有较高相似度的数据对象划分至同一类簇,将具有较高相异度的数据对象划分至不同类簇。聚类与分类最大的区别在于,聚类过程为无监督过程,即待处理数据对象没有任何先验知识,而分类过程为有监督过程,即存在有先验知识的训练数据集。
k-means算法中的k代表类簇个数,means代表类簇内数据对象的均值(这种均值是一种对类簇中心的描述),因此,k-means算法又称为k-均值算法。k-means算法是一种基于划分的聚类算法,以距离作为数据对象间相似性度量的标准,即数据对象间的距离越小,则它们的相似性越高,则它们越有可能在同一个类簇。数据对象间距离的计算有很多种,k-means算法通常采用欧氏距离来计算数据对象间的距离。
2.2 K-means算法基本步骤
k-means算法基本步骤
(1)从数据中选择k个对象作为初始聚类中心;
(2)计算每个聚类对象到聚类中心的距离来划分;
(3)再次计算每个聚类中心;
(4)计算标准测度函数,之道达到最大迭代次数,则停止,否则,继续操作。
三、实验代码及结果
1、图像的sift特征提取以及构造视觉词典
import pickle
from PCV.imagesearch import vocabulary
from PCV.tools.imtools import get_imlist
from PCV.localdescriptors import sift
#获取图像列表
imlist = get_imlist('first1000/')
nbr_images = len(imlist)
#获取特征列表
featlist = [imlist[i][:-3]+'sift' for i in range(nbr_images)]
#提取文件夹下图像的sift特征
for i in range(nbr_images):
sift.process_image(imlist[i], featlist[i])
#生成词汇
voc = vocabulary.Vocabulary('ukbenchtest')
voc.train(featlist, 1000, 10)
#保存词汇
with open('first1000/vocabulary.pkl', 'wb') as f:
pickle.dump(voc, f)
print ('vocabulary is:', voc.name, voc.nbr_words)
运行结果:
2、根据视觉词典进行量化,并将数据模型保存到数据库中
import pickle
from PCV.imagesearch import imagesearch
from PCV.localdescriptors import sift
from sqlite3 import dbapi2 as sqlite
from PCV.tools.imtools import get_imlist
#获取图像列表
imlist = get_imlist('first1000/')
nbr_images = len(imlist)
#获取特征列表
featlist = [imlist[i][:-3]+'sift' for i in range(nbr_images)]
#载入词汇
with open('first1000/vocabulary.pkl', 'rb') as f:
voc = pickle.load(f)
#创建索引
indx = imagesearch.Indexer('testImaAdd.db',voc)
indx.create_tables()
#遍历所有的图像,并将它们的特征投影到词汇上
for i in range(nbr_images)[:1000]:
locs,descr = sift.read_features_from_file(featlist[i])
indx.add_to_index(imlist[i],descr)
#提交到数据库
indx.db_commit()
con = sqlite.connect('testImaAdd.db')
print(con.execute('select count (filename) from imlist').fetchone())
print(con.execute('select * from imlist').fetchone())
运行结果:
![]()
3、利用索引在数据库中搜索图像
import pickle
from PCV.localdescriptors import sift
from PCV.imagesearch import imagesearch
from PCV.geometry import homography
from PCV.tools.imtools import get_imlist
#载入图像列表
imlist = get_imlist('first1000/')
nbr_images = len(imlist)
#载入特征列表
featlist = [imlist[i][:-3]+'sift' for i in range(nbr_images)]
#载入词汇
with open('first1000/vocabulary.pkl', 'rb') as f:
voc = pickle.load(f)
src = imagesearch.Searcher('testImaAdd.db',voc)
#查询图像索引和查询返回的图像数
q_ind = 0
nbr_results = 20
# 常规查询(按欧式距离对结果排序)
res_reg = [w[1] for w in src.query(imlist[q_ind])[:nbr_results]]
print('top matches (regular):', res_reg)
#载入查询图像特征
q_locs,q_descr = sift.read_features_from_file(featlist[q_ind])
fp = homography.make_homog(q_locs[:,:2].T)
#用单应性进行拟合建立RANSAC模型
model = homography.RansacModel()
rank = {}
#载入候选图像的特征
for ndx in res_reg[1:]:
locs,descr = sift.read_features_from_file(featlist[ndx])
matches = sift.match(q_descr,descr)
ind = matches.nonzero()[0]
ind2 = matches[ind]
tp = homography.make_homog(locs[:,:2].T)
try:
H,inliers = homography.H_from_ransac(fp[:,ind],tp[:,ind2],model,match_theshold=4)
except:
inliers = []
rank[ndx] = len(inliers)
sorted_rank = sorted(rank.items(), key=lambda t: t[1], reverse=True)
res_geom = [res_reg[0]]+[s[0] for s in sorted_rank]
print ('top matches (homography):', res_geom)
# 显示查询结果
imagesearch.plot_results(src,res_reg[:8]) #常规查询
imagesearch.plot_results(src,res_geom[:8]) #重排后的结果
运行结果:


4、测试
#载入词汇
f = open('first1000/vocabulary.pkl', 'rb')
voc = pickle.load(f)
f.close()
src = imagesearch.Searcher('testImaAdd.db',voc)
locs,descr = sift.read_features_from_file(featlist[0])
iw = voc.project(descr)
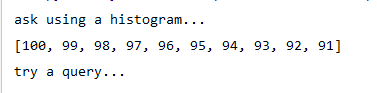
print ('ask using a histogram...')
print (src.candidates_from_histogram(iw)[:10])
src = imagesearch.Searcher('testImaAdd.db',voc)
print ('try a query...')
nbr_results = 12
res = [w[1] for w in src.query(imlist[0])[:nbr_results]]
imagesearch.plot_results(src,res)
运行结果:

5、建立演示程序及Web应用
import cherrypy
import pickle
import urllib
import os
from numpy import *
from PCV.imagesearch import imagesearch
import random
class SearchDemo:
def __init__(self):
# 载入图像列表
self.path = 'first1000/'
self.imlist = [os.path.join(self.path,f) for f in os.listdir(self.path) if f.endswith('.jpg')]
self.nbr_images = len(self.imlist)
print (self.imlist)
print (self.nbr_images)
self.ndx = list(range(self.nbr_images))
print (self.ndx)
# 载入词汇
with open('first1000/vocabulary.pkl','rb') as f:
self.voc = pickle.load(f)
# 显示搜索返回的图像数
self.maxres = 10
self.header = """
Image search
"""
self.footer = """