数据结构&算法-----(5)图、DFS与BFS、Dijstra
数据结构&算法-----(5)图、DFS与BFS
- 图(Graph)
- 邻接链表(Adjacency List)
- 邻接矩阵(Adjacency Matrix)
- LeetCode 第 785 题:二部图
- 深度优先搜索(栈实现)(Depth-First Search / DFS)
- 例题分析一:二维迷宫
- 算法复杂度分析
- 例题分析二:利用 DFS 去寻找最短的路径
- LeetCode 22 题:括号生成
- 方法一:深度优先遍历
- 方法二:广度优先遍历
- 方法三:动态规划
- 广度优先搜索(Breadth-First Search / BFS)
- 例题分析一:运用广度优先搜索的算法在迷宫中寻找最短的路径
- 算法分析
- 例题分析二:最多允许打通 3 堵墙
- 有向无环图 单源最短路径 Dijstra算法
- 度小满2020笔试编程题
图(Graph)
假设图里有 V 个顶点,E 条边,图有两种存储和表达方式:
邻接链表(Adjacency List)
访问所有顶点的时间为 O(V),而查找所有顶点的邻居一共需要 O(E) 的时间,所以总的时间复杂度是 O(V + E)。
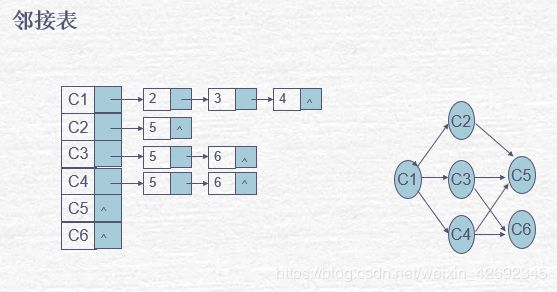

邻接矩阵(Adjacency Matrix)
查找每个顶点的邻居需要 O(V) 的时间,所以查找整个矩阵的时候需要 O(V2) 的时间。


- 图的遍历:深度优先DFS、广度优先BFS
- 二部图的检测(Bipartite)、树的检测、环的检测:有向图、无向图
- 拓扑排序
- 联合-查找算法(Union-Find)
- 最短路径:Dijkstra、Bellman-Ford
LeetCode 第 785 题:二部图
给定一个无向图 graph,当这个图为二部图时返回 true。如果能将一个图的节点集合分割成两个独立的子集 A 和 B,并使图中的每一条边的两个节点一个来自 A 集合,一个来自 B 集合,就将这个图称为二部图。
graph将会以邻接表方式给出,graph[i]表示图中与节点i相连的所有节点。每个节点都是一个
在0到graph.length-1之间的整数。
这图中没有自环和平行边: graph[i] 中不存在i,并且graph[i]中没有重复的值。
示例一:
输入: [[1,3], [0,2], [1,3], [0,2]]
输出: true
无向图如下:
0----1
| |
| |
3----2
我们可以将节点分成两组: {0, 2} 和 {1, 3}。
示例二:
输入: [[1,2,3], [0,2], [0,1,3], [0,2]]
输出: false
解释:
无向图如下:
0----1
| \ |
| \ |
3----2
我们不能将节点分割成两个独立的子集。
代码实现:
- 给图里的顶点涂上颜色,子集 U 里的顶点都涂上红色,子集 V 里的顶点都涂上蓝色。
- 开始遍历这个图的所有顶点,想象一下手里握有红色和蓝色的画笔,每次交替地给遍历当中遇到的顶点涂上颜色。
- 如果这个顶点还没有颜色,那就给它涂上颜色,然后换成另外一支画笔。
- 下一个顶点,如果发现这个顶点已经涂上了颜色,而且颜色跟我手里画笔的颜色不同,那么表示这个顶点它既能在子集 U 里,也能在子集 V 里。
- 所以,它不是一个二部图。
注意这个graph的输入形式,一共有graph.length个顶点
public boolean isBipartite(int[][] graph) {
int n = graph.length;
int[] color = new int[n];
//0蓝色, 1红色, -1未着色
Arrays.fill(color, -1);
for (int start = 0; start < n; ++start) {
if (color[start] == -1) {
Stack<Integer> stack = new Stack<Integer>();
//未着色的顶点入栈, 然后涂色
stack.push(start);
//将第一个顶点涂成蓝色
color[start] = 0;
while (!stack.empty()) {
Integer node = stack.pop();
//graph[i]表示图中与节点i相连的所有节点
for (int nei: graph[node]) {
//未着色的顶点入栈, 然后涂色
if (color[nei] == -1) {
stack.push(nei);
// ^代表异或运算, 0^1=1, 1^1=0
// 如果结点是蓝色,就把相邻结点涂成红色。或者相反。
// 编程技巧, 跟 1 异或运算
color[nei] = color[node] ^ 1;
} else if (color[nei] == color[node]) {
return false;
}
}
}
}
}
return true;
}
深度优先搜索(栈实现)(Depth-First Search / DFS)
深度优先搜索,从起点出发,从规定的方向中选择其中一个不断地向前走,直到无法继续为止,然后尝试另外一种方向,直到最后走到终点。就像走迷宫一样,尽量往深处走。
DFS 解决的是连通性的问题,即,给定两个点,一个是起始点,一个是终点,判断是不是有一条路径能从起点连接到终点。起点和终点,也可以指的是某种起始状态和最终的状态。问题的要求并不在乎路径是长还是短,只在乎有还是没有。有时候题目也会要求把找到的路径完整的打印出来。
例题分析一:二维迷宫
给定一个二维矩阵代表一个迷宫,迷宫里面有通道,也有墙壁,通道由数字 0 表示,而墙壁由 -1 表示,有墙壁的地方不能通过,那么,能不能从 A 点走到 B 点。A最开始也是0

递归实现:
boolean dfs(int maze[][], int x, int y) {
// 第一步:判断是否找到了B
if (x == B[0] && y == B[1]) {
return true;
}
// 第二步:标记当前的点已经被访问过
maze[x][y] = -1;
// 第三步:在四个方向上尝试
for (int d = 0; d < 4; d++) {
int i = x + dx[d], j = y + dy[d];
// 第四步:如果有一条路径被找到了,返回true
if (isSafe(maze, i, j) && dfs(maze, i, j)) {
return true;
}
}
// 付出了所有的努力还是没能找到B,返回false
return false;
}
非递归实现:
boolean dfs(int maze[][], int x, int y) {
// 创建一个Stack
// 编程技巧 stack 中存的是 Integer[] 的类型
Stack<Integer[]> stack = new Stack<>();
// 将起始点压入栈,标记它访问过
stack.push(new Integer[] {x, y});
maze[x][y] = -1;
while (!stack.isEmpty()) {
// 取出当前点
Integer[] pos = stack.pop();
x = pos[0]; y = pos[1];
// 判断是否找到了目的地
if (x == B[0] && y == B[1]) {
return true;
}
// 在四个方向上尝试
for (int d = 0; d < 4; d++) {
int i = x + dx[d], j = y + dy[d];
if (isSafe(maze, i, j)) {
stack.push(new Integer[] {i, j});
maze[i][j] = -1;
}
} //for
} //while
return false;
}
递归实现:
- 代码看上去很简洁;
- 实际应用中,递归需要压入和弹出栈,栈深的时候会造成运行效率低下。
非递归实现:
- 栈支持压入和弹出;
- 栈能提高效率。
算法复杂度分析
举例:利用 DFS 在迷宫里找一条路径的复杂度。迷宫是用矩阵表示。
实践复杂度:
把迷宫看成是邻接矩阵。假设矩阵有 M 行 N 列,那么一共有 M × N 个顶点,因此时间复杂度就是 O(M × N)。
空间复杂度:
DFS 需要堆栈来辅助,在最坏情况下,得把所有顶点都压入堆栈里,所以它的空间复杂度是 O(V),即 O(M × N)。
例题分析二:利用 DFS 去寻找最短的路径
解题思路:
思路 1:暴力法。
寻找出所有的路径,然后比较它们的长短,找出最短的那个。此时必须尝试所有的可能。因为 DFS 解决的只是连通性问题,不是用来求解最短路径问题的。
思路 2:优化法。
一边寻找目的地,一边记录它和起始点的距离(也就是步数)。
从某方向到达该点所需要的步数更少,则更新。
从各方向到达该点所需要的步数都更多,则不再尝试。
代码实现:
void solve(int maze[][]) {
// 从 A 到 B
// 第一步. 除了 A 之外,将其他等于 0 的地方用 MAX_VALUE 替换
// B 点也初始化为了 MAX_VALUE
for (int i = 0; i < maze.length; i++) {
for (int j = 0; j < maze[0].length; j++) {
if (maze[i][j] == 0 && !(i == A[0] && j == A[1])) {
maze[i][j] = Integer.MAX_VALUE;
}
}
}
// 第二步. 进行优化的DFS操作
dfs(maze, A[0], A[1]);
// 第三步. 看看是否找到了目的地
if (maze[B[0]][B[1]] < Integer.MAX_VALUE) {
print("Shortest path count is: " + maze[B[0]][B[1]]);
} else {
print("Cannot find B!");
}
}
void dfs(int maze[][], int x, int y) {
// 第一步. 判断是否找到了B
if (x == B[0] && y == B[1]) return;
// 第二步. 在四个方向上尝试
for (int d = 0; d < 4; d++) {
int i = x + dx[d], j = y + dy[d];
// 判断下一个点的步数是否比目前的步数+1还要大
if (isSafe(maze, i, j) && maze[i][j] > maze[x][y] + 1) {
// 如果是,就更新下一个点的步数,并继续DFS下去
// 在这里MAX_VALUE被更新了
maze[i][j] = maze[x][y] + 1;
dfs(maze, i, j);
}
}
}
注意:之前的题目只要找到了一个路径就返回,这里我们必须尽可能多的去尝试,直到找到最短路径。
当程序运行完毕之后,矩阵的最终结果如下:
2, 1, A, 1, 2, 3
3, 2, -1, 2, 3, 4
4, 3, -1, 3, 4, 5
5, 4, -1, -1, 5, 6
6, -1, 8, 7, 6, 7
7, 8, 9, 8, 7, -1
可以看到,矩阵中每个点的数值代表着它离 A 点最近的步数。
LeetCode 22 题:括号生成
数字 n 代表生成括号的对数,请你设计一个函数,用于能够生成所有可能的并且 有效的 括号组合。
示例:
输入:n = 3
输出:[
"((()))",
"(()())",
"(())()",
"()(())",
"()()()"
]
参考题解:
回溯算法(深度优先遍历)+ 广度优先遍历 + 动态规划
方法一:深度优先遍历
我们以 n = 2 为例,画树形结构图。方法是 “做减法”。
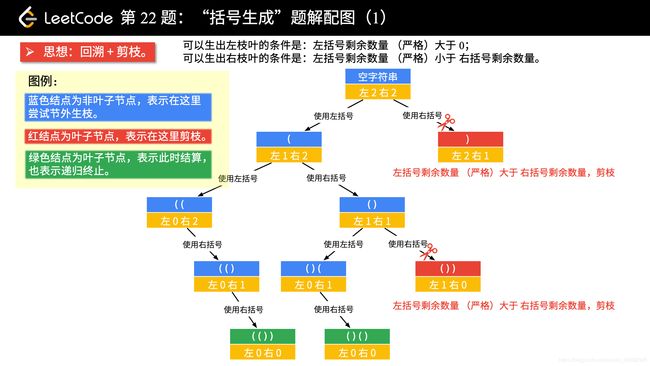
画图以后,可以分析出的结论:
- 当前左右括号都有大于 0 个可以使用的时候,才产生分支;
- 产生左分支的时候,只看当前是否还有左括号可以使用;
- 产生右分支的时候,还受到左分支的限制,右边剩余可以使用的括号数量一定得在严格大于左边剩余的数量的时候,才可以产生分支;
- 在左边和右边剩余的括号数都等于 0 的时候结算。
Java代码:
import java.util.ArrayList;
import java.util.List;
public class Solution {
// 做减法
public List<String> generateParenthesis(int n) {
List<String> res = new ArrayList<>();
// 特判
if (n == 0) {
return res;
}
// 执行深度优先遍历,搜索可能的结果
dfs("", n, n, res);
return res;
}
/**
* @param curStr 当前递归得到的结果
* @param left 左括号还有几个可以使用
* @param right 右括号还有几个可以使用
* @param res 结果集
*/
private void dfs(String curStr, int left, int right, List<String> res) {
// 因为每一次尝试,都使用新的字符串变量,所以无需回溯
// 在递归终止的时候,直接把它添加到结果集即可,注意与「力扣」第 46 题、第 39 题区分
if (left == 0 && right == 0) {
res.add(curStr);
return;
}
// 剪枝(如图,左括号可以使用的个数严格大于右括号可以使用的个数,才剪枝,注意这个细节)
if (left > right) {
return;
}
if (left > 0) {
dfs(curStr + "(", left - 1, right, res);
}
if (right > 0) {
dfs(curStr + ")", left, right - 1, res);
}
}
}
方法二:广度优先遍历
广度优先遍历,得程序员自己编写结点类,显示使用队列这个数据结构。深度优先遍历的时候,就可以直接使用系统栈,在递归方法执行完成的时候,系统栈顶就把我们所需要的状态信息直接弹出,而无须编写结点类和显示使用栈。
读者可以通过比较:
1、广度优先遍历;
2、自己使用栈编写深度优先遍历;
3、使用系统栈的深度优先遍历(回溯算法)。
来理解 “回溯算法” 作为一种 “搜索算法” 的合理性。
import java.util.ArrayDeque;
import java.util.ArrayList;
import java.util.Deque;
import java.util.LinkedList;
import java.util.List;
import java.util.Queue;
public class Solution {
class Node {
/**
* 当前得到的字符串
*/
private String res;
/**
* 剩余左括号数量
*/
private int left;
/**
* 剩余右括号数量
*/
private int right;
public Node(String str, int left, int right) {
this.res = str;
this.left = left;
this.right = right;
}
}
public List<String> generateParenthesis(int n) {
List<String> res = new ArrayList<>();
if (n == 0) {
return res;
}
Queue<Node> queue = new LinkedList<>();
queue.offer(new Node("", n, n));
while (!queue.isEmpty()) {
Node curNode = queue.poll();
if (curNode.left == 0 && curNode.right == 0) {
res.add(curNode.res);
}
if (curNode.left > 0) {
queue.offer(new Node(curNode.res + "(", curNode.left - 1, curNode.right));
}
if (curNode.right > 0 && curNode.left < curNode.right) {
queue.offer(new Node(curNode.res + ")", curNode.left, curNode.right - 1));
}
}
return res;
}
}
方法三:动态规划
参见文章:
LeetCode温习-----(6)动态规划
广度优先搜索(Breadth-First Search / BFS)
广度优先搜索,一般用来解决最短路径的问题。和深度优先搜索不同,广度优先的搜索是从起始点出发,一层一层地进行,每层当中的点距离起始点的步数都是相同的,当找到了目的地之后就可以立即结束。
广度优先的搜索可以同时从起始点和终点开始进行,称之为双端 BFS。这种算法往往可以大大地提高搜索的效率。
例题分析一:运用广度优先搜索的算法在迷宫中寻找最短的路径
从起始点 A 出发,类似于涟漪,一层一层地扫描,避开墙壁,同时把每个点与 A 的距离或者步数标记上。当找到目的地的时候返回步数,这个步数保证是最短的。
代码实现:
void bfs(int[][] maze, int x, int y) {
// 创建一个队列queue,将起始点A加入队列中
Queue<Integer[]> queue = new LinkedList<>();
queue.add(new Integer[] {x, y});
// 只要队列不为空就一直循环下去
while (!queue.isEmpty()) {
// 从队列的头取出当前点
Integer[] pos = queue.poll();
x = pos[0]; y = pos[1];
// 从四个方向进行BFS
for (int d = 0; d < 4; d++) {
int i = x + dx[d], j = y + dy[d];
if (isSafe(maze, i, j)) {
// 记录步数(标记访问过)
maze[i][j] = maze[x][y] + 1;
// 然后添加到队列中
queue.add(new Integer[] {i, j});
// 如果发现了目的地就返回
if (i == B[0] && j == B[1]) return;
}
}
}
}
算法分析
同样借助图论的分析方法,假设有 V 个顶点,E 条边。
时间复杂度:
-
邻接表
每个顶点都需要被访问一次,时间复杂度是 O(V);相连的顶点(也就是每条边)也都要被访问一次,加起来就是 O(E)。因此整体时间复杂度就是O(V+E)。 -
邻接矩阵
V 个顶点,每次都要检查每个顶点与其他顶点是否有联系,因此时间复杂度是O(V2)。
举例:在迷宫里进行 BFS 搜索。
解法:用邻接矩阵。假设矩阵有 M 行 N 列,那么一共有 M×N 个顶点,时间复杂度就是 O(M×N)。
空间复杂度:
需要借助一个队列,所有顶点都要进入队列一次,从队列弹出一次。在最坏的情况下,空间复杂度是 O(V),即 O(M×N)。
例题分析二:最多允许打通 3 堵墙
例题:假设从起始点 A 走到目的地 B 的过程中,最多允许打通 3 堵墙,求最短的路径的步数。(这个题目可以扩展到允许打通任意数目的墙。)
解题思路:
思路 1:暴力法。
- 首先枚举出所有拆墙的方法.
假设一共有 K 堵墙在当前的迷宫里,最多允许拆 3 堵墙,有四种情况:不拆,只拆一堵墙、两堵墙、三堵墙。组合方式如下。
C(K, 0) + C(K, 1) + C(K, 2) + C(K, 3) = 1 + K + K ×(K - 1) / 2 + K× (K - 1) ×(K - 2) / 6
上式复杂度为 K 的 3 次方,如果允许打通墙的数量是 w,那么就是 K 的 w 次方。
- 分别进行 BFS,整体的时间复杂度就是 O(n2×Kw),从中找到最短的那条路径。
很显然,该方法非常没有效率。
思路 2:
一、将 BFS 的数量减少。
- 在不允许打通墙的情况下,只有一个人进行 BFS 搜索,时间复杂度是 n2;
- 允许打通一堵墙的情况下,分身为两个人进行 BFS 搜索,时间复杂度是 2×n2;
- 允许打通两堵墙的情况下,分身为三个人进行 BFS 搜索,时间复杂度是 3×n2;
- 允许打通三堵墙的情况下,分身为四个人进行 BFS 搜索,时间复杂度是 4×n2。
二、解决关键问题。
- 如果第一个人又遇到了一堵墙,那么他是否需要再次分身呢?不能。
- 第一个人怎么告诉第二个人可以去访问这个点?把这个点放入到队列中。
- 如何让 4 个人在独立的平面里搜索?利用一个三维矩阵记录每个层面里的点。
只需要 4 个人去做 BFS,整体的时间复杂度就是 4 倍的 BFS。
// w: 最多允许打通 w 堵墙
int bfs(int[][] maze, int x, int y, int w) {
// 初始化
int steps = 0, z = 0;
// 利用队列来辅助BFS
Queue<Integer[]> queue = new LinkedList<>();
queue.add(new Integer[] {x, y, z});
//加入了一个 null,这是使用 BFS的一个小技巧,用来帮助我们计算当前遍历了多少步数。
queue.add(null);
// 三维的 visited 记录各层平面中每个点是否被访问过
// 允许打通 w 堵墙的情况下,分身为 w+1 个人进行 BFS 搜索,时间复杂度是 (w+1)×n2。
boolean[][][] visited = new boolean[N][N][w + 1];
visited[x][y][z] = true;
// 只要队列不为空就一直循环
while (!queue.isEmpty()) {
Integer[] pos = queue.poll();
if (pos != null) {
// 取出当前点
x = pos[0]; y = pos[1]; z = pos[2];
// 如果遇到了目的地就立即返回步数
if (x == B[0] && y == B[1]) {
return steps;
}
// 朝四个方向尝试
for (int d = 0; d < 4; d++) {
int i = x + dx[d], j = y + dy[d];
if (!isSafe(maze, i, j, z, visited)) {
continue;
}
// 如果在当前层遇到了墙,尝试打通它
int k = getLayer(maze, w, i, j, z);
if (k >= 0) {
// 如果能打通墙,就在下一层尝试
visited[i][j][k] = true;
queue.add(new Integer[] {i, j, k});
}
}
} else {
steps++;
//队不空的时候再加入一个null
if (!queue.isEmpty()) {
queue.add(null);
}
}
} //while
return -1;
}
注意:
- 初始化队列的时候,除了把在第一层里的起始点 A 加入到队列中,还加入了一个 null,这是使用 BFS的一个小技巧,用来帮助我们计算当前遍历了多少步数。
- 其中,利用 getLayer 函数判断是否遇到了墙壁,以及是否能打通墙壁到下一层。
- 最后,如果当前点是 null,表明已经处理完当前的步数,继续下一步。
getLayer 函数的代码实现如下。
// w: 最多允许打通 w 堵墙
// z: 当前在第几层
int getLayer(int[][] maze, int w, int x, int y, int z) {
if (maze[x][y] == -1) {
return z < w ? z + 1 : -1;
}
return z;
}
getLayer的思想很简单,如果当前遇到的是一堵墙,那么看打通的墙壁个数是否已经超出了规定,如果没有,就继续打通它,否则返回-1。另外,如果当前遇到的不是一堵墙,就继续在当前的平面里进行 BFS。
有向无环图 单源最短路径 Dijstra算法
被度小满的笔试题虐了,回顾一下Dijstra算法,高连生老师课上讲过
参考文章:
图解最短路径之迪杰斯特拉算法(Java实现)
public class DijstraAlgorithm {
//不能设置为Integer.MAX_VALUE,否则两个Integer.MAX_VALUE相加会溢出导致出现负权
public static int MaxValue = 100000;
public static void main(String[] args) {
Scanner input = new Scanner(System.in);
System.out.println("请输入顶点数和边数:");
//顶点数
int vertex = input.nextInt();
//边数
int edge = input.nextInt();
int[][] matrix = new int[vertex][vertex];
//初始化邻接矩阵
for (int i = 0; i < vertex; i++) {
for (int j = 0; j < vertex; j++) {
matrix[i][j] = MaxValue;
}
}
for (int i = 0; i < edge; i++) {
System.out.println("请输入第" + (i + 1) + "条边与其权值:");
int source = input.nextInt();
int target = input.nextInt();
int weight = input.nextInt();
matrix[source][target] = weight;
}
//单源最短路径,源点
int source = input.nextInt();
//调用dijstra算法计算最短路径
dijstra(matrix, source);
}
public static void dijstra(int[][] matrix, int source) {
//最短路径长度
int[] shortest = new int[matrix.length];
//判断该点的最短路径是否求出
int[] visited = new int[matrix.length];
//存储输出路径
String[] path = new String[matrix.length];
//初始化源节点
shortest[source] = 0;
visited[source] = 1;
//初始化输出路径
for (int i = 0; i < matrix.length; i++) {
path[i] = new String(source + "->" + i);
}
for (int i = 1; i < matrix.length; i++) {
int min = Integer.MAX_VALUE;
int index = -1;
for (int j = 0; j < matrix.length; j++) {
//已经求出最短路径的节点不需要再加入计算并判断加入节点后是否存在更短路径
if (visited[j] == 0 && matrix[source][j] < min) {
min = matrix[source][j];
index = j;
}
}
//更新最短路径
shortest[index] = min;
visited[index] = 1;
//更新从index跳到其它节点的较短路径
for (int m = 0; m < matrix.length; m++) {
if (visited[m] == 0 && matrix[source][index] + matrix[index][m] < matrix[source][m]) {
matrix[source][m] = matrix[source][index] + matrix[index][m];
path[m] = path[index] + "->" + m;
}
}
} //for int i
//打印最短路径
for (int i = 0; i < matrix.length; i++) {
if (i != source) {
if (shortest[i] == MaxValue) {
System.out.println(source + "到" + i + "不可达");
} else {
System.out.println(source + "到" + i + "的最短路径为:"
+ path[i] + ",最短距离是:" + shortest[i]);
}
}
}
} //dijstra
}
朴素Dijkstra的时间复杂度是O(n2)。最外层循环不可避免,循环n次,内层循环主要有两个:
①寻找用来优化的点O(n);
②进行松弛操作,松弛每一个点O(n)。
那么,我们主要优化的就是“寻找用来优化的点“,原来需要一个时间复杂度为O(n)的循环,用了优先队列后,就直接用优先队列取出离起点路径最短的点,时间复杂度为O(logn)。
所以,堆优化的总时间复杂度是O(nlogn)。
度小满2020笔试编程题


package duxiaoman;
import java.util.Arrays;
import java.util.Comparator;
import java.util.PriorityQueue;
import java.util.Scanner;
public class Main2 {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
int n=sc.nextInt();
int a=sc.nextInt();
int b=sc.nextInt();
int c=sc.nextInt();
int[] ai = new int[n + 1];
for(int i=1;i<=n;i++){
ai[i]=sc.nextInt();
}
boolean vis[]=new boolean[n+1];
long dis[]=new long[n+1];
Arrays.fill(dis,0x3f3f3f3f3f3f3f3fL);
//计算答案的最大值就是 1直接到终点
long ans=a+(n-ai[1])*1L*c;
dis[1]=0;
//迪杰斯特拉+堆优化
//花费最少城市的优先级最高
PriorityQueue<Node> que = new PriorityQueue<Node>(
Comparator.comparingLong(o -> o.len)
);
que.add(new Node(1,0));
while(!que.isEmpty()){
Node node = que.poll();
//如果找到了目标城市
if(node.cur==n){
ans=Math.min(ans,node.len);
break;
}
//如果优先队列取出的城市已经访问过
if(vis[node.cur])
continue;
//这时找到的城市就是: 没访问过+花费最少
vis[node.cur]=true;
for(int i=2;i<=n;i++){
if(vis[i])
continue;
int cur=node.cur;
long cost=0;
if(ai[cur]<i){
cost=1L*(i-ai[cur])*c;
} else {
cost=1L*(ai[cur]-i)*b;
}
//迪杰斯特拉的松弛操作
//此时原始城市是1,cur是中间城市,用来更新城市1到城市i的最短距离
if(dis[i]>node.len+cost+a){
// 大于最大值,就不考虑了,剪枝策略
if(node.len+cost+a>=ans)
continue;
dis[i]=node.len+cost+a;
que.add(new Node(i,dis[i]));
}
}
} //while
System.out.println(ans);
}
static class Node{
public Node(int cur, long len) {
this.cur = cur;
this.len = len;
}
int cur;
long len;
}
}