利用BP神经网络 设计一个三层神经网络解决手写数字的识别问题
文章目录
- 1. 题目描述
- 2. 求解原理
- (1)算法模型
- (2)算法原理
- 3.编程实现
- (1)环境说明
- (2)实验方案
- (3)Python实现
1. 题目描述
设计一个三层神经网络解决手写数字的识别问题。
要求:
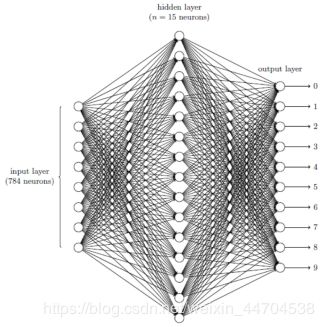
(1)三层神经网络如图:784-15-10结构
(2)使用随机梯度下降算法和MNIST训练数据。
http://yann.lecun.com/exdb/mnist/
2. 求解原理
(1)算法模型
利用BP神经网络,这里有输入层、隐藏层、输出层共三层,包括两个阶段,
- 第一阶段是输入信息的正向传播,其中隐藏层节点的输出为:
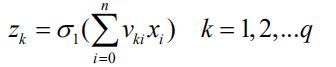
输出层节点的输出:
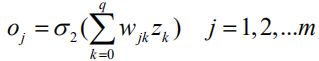
- 第二阶段是误差反向传播阶段
第p个样本的误差:
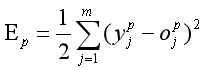
p个样本的总误差:
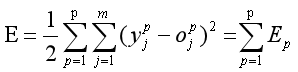
(2)算法原理
BP算法可以描述如下:
(1)工作信号正向传播:输入信号从输入层经隐藏层,传向输出层,在输出端产生输出信号,这是工作信号的正向传播。在信号的向前传递过程中网络的权值是固定不变的,每一层神经元的状态只影响下一层神经元的状态。如果在输出层不能得到期望的输出,则转入误差信号反向传播。正向传播的数学模型为:
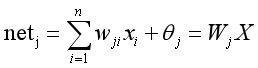
![]()
其中n为样本数,w为权值,θ为偏置,
![]()
为激活函数,这里选择sigmoid函数为激活函数。
(2)误差信号反向传播:网络的实际输出与期望输出之间差值即为误差信号,误差信号由输出端开始逐层向前传播,这是误差信号的反向传播。在误差信号反向传播的过程中,网络的权值由误差反馈进行调节。通过权值的不断修正使网络的实际输出更接近期望输出。
在反向传播中,第p个样本的误差为:
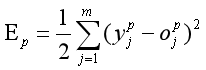
p个样本的总误差:
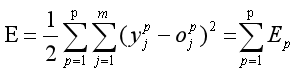
梯度为:
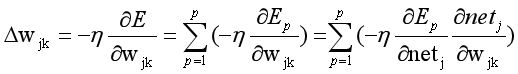
其中:
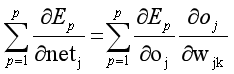
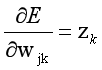
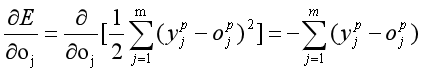
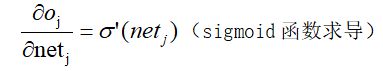
3.编程实现
(1)环境说明
python3.7
tensorflow2.1.0
(2)实验方案
数据来源:
手写数字图片数据集MNIST,它包含了0-9共10种数字的手写图片,每种数字一共7000张图片,采样自不同书写风格的真实手写图片,一共70000张图片,其中60000张图片作为训练集,用来训练模型,剩下的10000图片作为测试集,用来预测或者测试,训练集和测试集共同组成了MNIST数据集。
考虑到手写数字图片包含的信息比较简单,每张图片均被缩放到28 × 28的大小,同时
只保留了灰度信息。这些图片由真人书写,包含了如字体大小、书写风格、粗细等丰富的样式,确保这些图片的分布与真实的手写数字图片的分布尽可能的接近,从而保证了模型的泛化能力。
实验计划和流程:
(1)网络搭建。搭建784-15-10结构的神经网络,激活函数类型为 ReLU。
(2)模型训练。使用交叉熵作为损失函数。
验证和测试:
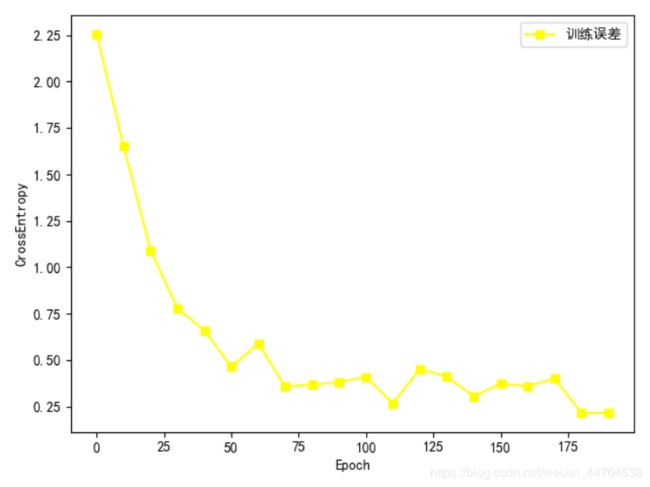
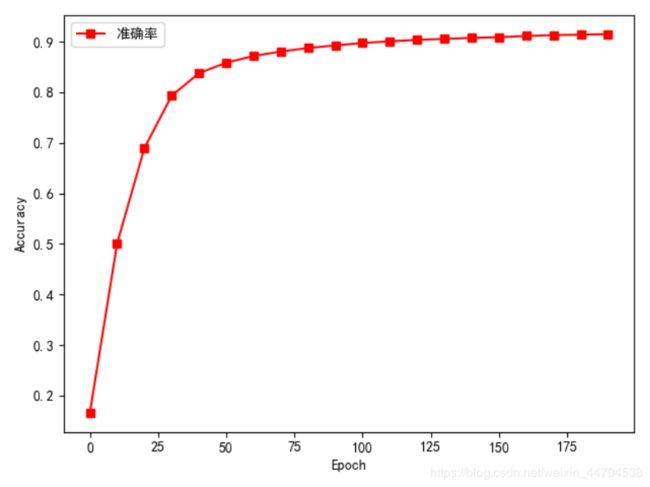
手写数字图片 MNIST 数据集的训练误差曲线如图所示,由于 3 层的神经网络表达能力较强,手写数字图片识别任务相对简单,误差值可以较快速、稳定地下降。其中,把对数据集的所有样本迭代一遍叫作一个Epoch,我们可以在间隔数个 Epoch 后测试模型的准确率等指标,方便监控模型的训练效果。
通过简单的 3 层神经网络,训练固定的 200 个 Epoch 后,我们在测试集上获得了91.59%的准确率。模型的训练误差曲线如图一所示,误差函数为交叉熵,其值越小,模型预测效果就越好。测试准确率曲线如图二所示。
如果使用复杂的神经网络模型,增加数据增强环节,精调网络超参数等技巧,可以获得更高的模型性能。
(3)Python实现
import tensorflow as tf # 导入TF库
from tensorflow import keras # 导入TF子库keras
from tensorflow.keras import layers, optimizers, datasets # 导入Tf子库
import matplotlib.pyplot as plt
def preprocess(x, y):
"""数据处理函数"""
x = 2 * tf.cast(x, dtype=tf.float32) / 255. - 1 # tf.cast函数可以完成精度转换
y = tf.cast(y, dtype=tf.int32)
return x, y
# load_data()函数返回两个元组(tuple)对象,第一个是训练集,第二个是测试集
# 每个tuple的第一个元素是多个训练图片数据的X,第二个元素是训练图片对应的类别数字Y
# 其中X的大小为(60000,28,28),代表了60000个样本,每个样本由28行、28列构成
# 由于是灰度图片,故没有RGB通道;训练集Y的大小为(60000),代表了这60000个样本的标签数字
# 每个样本标签用一个范围为0~9的数字表示。测试集X的大小为(10000,28,28)
(x, y), (x_test, y_test) = datasets.mnist.load_data() # 加载MNIST数据集
print(x.shape, y.shape)
# TensorFlow中加载的MNIST数据图片,数值的范围为[0,255]。在机器学习中间,一般希望数据的范围
# 在0周围的小范围内分布。通过预处理步骤,我们把[0,255]像素范围归一化到[0,1.]区间,在缩放到
# [-1,1]区间,从而有利于模型的训练
# x = 2*tf.convert_to_tensor(x, dtype=tf.float32)/255.-1 # 转换为浮点张量,并缩放到-1~1
# y = tf.convert_to_tensor(y, dtype=tf.int32) # 转换为整型张量
# 处理训练数据
batch_size = 512
train_dataset = tf.data.Dataset.from_tensor_slices((x, y)) # 构建数据集对象
train_dataset = train_dataset.map(preprocess).shuffle(10000).batch(batch_size) # 随机打散,批量训练
# 处理测试数据
test_dataset = tf.data.Dataset.from_tensor_slices((x_test, y_test))
test_dataset = test_dataset.map(preprocess).batch(batch_size)
# 使用TensorFlow的Sequential容器可以非常方便地搭建多层网络
# 利用Sequential容器封装3个网络层,前网络层的输出默认作为下一层的输入
model = keras.Sequential([ # 2个非线性层的嵌套模型
layers.Dense(15, activation='relu'), # 隐藏层1 ,15
layers.Dense(10)]) # 输出层,输出节点为10
# w' = w - lr * grad, 更新网络参数
optimizer = optimizers.Adam(lr=1e-5) # 优化器,加快训练速度
total_epoch = 200 # 迭代次数
def main():
loss_ce = 0.
for epoch in range(total_epoch):
for step, (x, y) in enumerate(train_dataset):
# 模型训练
with tf.GradientTape() as tape: # 构建梯度记录环境
# 打平操作,[b,28,28] => [b,784]
x = tf.reshape(x, (-1, 28 * 28))
# step1. 得到模型输出output [b, 784] => [b, 10]
out = model(x)
# [b] => [b, 10]
y_onehot = tf.one_hot(y, depth=10) # one-hot编码
# 计算交叉熵 [b, 10]
loss_ce = tf.reduce_mean(tf.losses.categorical_crossentropy(y_onehot, out, from_logits=True))
# step3. 自动计算参数的梯度w1, w2, w3, b1, b2, b3
grads = tape.gradient(loss_ce, model.trainable_variables)
optimizer.apply_gradients(zip(grads, model.trainable_variables))
if step % 100 == 0:
print(epoch, step, f'loss_ce: {float(loss_ce)}')
# test
total_correct = 0
total_num = 0
for x, y in test_dataset:
# x:[b,28,28] --> [b,784]
# y:[b]
x = tf.reshape(x, [-1, 28 * 28])
# [b,10]
out = model(x)
# out --> prob [b,10]
prob = tf.nn.softmax(out, axis=1)
# [b,10] --> [b], int32
pred = tf.argmax(prob, axis=1)
pred = tf.cast(pred, dtype=tf.int32)
# pred:[b]
# y:[b]
# correct: [b], True: equal; False: not equal
correct = tf.equal(pred, y)
correct = tf.reduce_sum(tf.cast(correct, dtype=tf.int32))
total_correct += int(correct)
total_num += x.shape[0]
acc = total_correct / total_num
print(epoch, f'test acc: {acc}')
if epoch % 10 == 0:
epoch_plt.append(epoch)
ce_plt.append(loss_ce)
acc_plt.append(acc)
return epoch_plt, ce_plt, acc_plt
if __name__ == '__main__':
epoch_plt, ce_plt, acc_plt = [], [], []
epoch_plt, ce_plt, acc_plt = main()
plt.figure()
plt.plot(epoch_plt, ce_plt, color="yellow", marker='s')
plt.xlabel('Epoch')
plt.ylabel('CrossEntropy')
plt.rcParams['font.sans-serif'] = ['SimHei'] # 显示中文标签
plt.rcParams['axes.unicode_minus'] = False
plt.legend(('训练误差',))
plt.figure()
plt.plot(epoch_plt, acc_plt, color="red", marker='s')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.rcParams['font.sans-serif'] = ['SimHei'] # 显示中文标签
plt.rcParams['axes.unicode_minus'] = False
plt.legend(('准确率',))
plt.show()