Precision and recall
原文转载于: http://en.wikipedia.org/wiki/Precision_and_recall
In pattern recognition and information retrieval, precision (also called positive predictive value) is the fraction of retrieved instances that are relevant, while recall (also known as sensitivity) is the fraction of relevant instances that are retrieved. Both precision and recall are therefore based on an understanding and measure of relevance. Suppose a program for recognizing dogs in scenes from a video identifies 7 dogs in a scene containing 9 dogs and some cats. If 4 of the identifications are correct, but 3 are actually cats, the program's precision is 4/7 while its recall is 4/9. When a search engine returns 30 pages only 20 of which were relevant while failing to return 40 additional relevant pages, its precision is 20/30 = 2/3 while its recall is 20/60 = 1/3.
In statistics, if the null hypothesis is that all and only the relevant items are retrieved, absence of type I and type II errors corresponds respectively to maximum precision (no false positives) and maximum recall (no false negatives). The above pattern recognition example contained 7 − 4 = 3 type I errors and 9 − 4 = 5 type II errors. Precision can be seen as a measure of exactness or quality, whereas recall is a measure of completeness or quantity.
In simple terms, high recall means that an algorithm returned most of the relevant results, while high precision means that an algorithm returned substantially more relevant results than irrelevant.
Contents
[hide]- 1 Introduction
- 2 Definition (information retrieval context)
- 2.1 Precision
- 2.2 Recall
- 3 Definition (classification context)
- 4 Probabilistic interpretation
- 5 F-measure
- 6 Limitations as goals
- 7 See also
- 8 Sources
- 9 External links
Introduction
As an example, in an information retrieval scenario, the instances are documents and the task is to return a set of relevant documents given a search term; or equivalently, to assign each document to one of two categories, "relevant" and "not relevant". In this case, the "relevant" documents are simply those that belong to the "relevant" category. Recall is defined as the number of relevant documents retrieved by a search divided by the total number of existing relevant documents, while precision is defined as the number of relevant documents retrieved by a search divided by the total number of documents retrieved by that search.
In a classification task, the precision for a class is the number of true positives (i.e. the number of items correctly labeled as belonging to the positive class) divided by the total number of elements labeled as belonging to the positive class (i.e. the sum of true positives and false positives, which are items incorrectly labeled as belonging to the class). Recall in this context is defined as the number of true positives divided by the total number of elements that actually belong to the positive class (i.e. the sum of true positives and false negatives, which are items which were not labeled as belonging to the positive class but should have been).
In information retrieval, a perfect precision score of 1.0 means that every result retrieved by a search was relevant (but says nothing about whether all relevant documents were retrieved) whereas a perfect recall score of 1.0 means that all relevant documents were retrieved by the search (but says nothing about how many irrelevant documents were also retrieved).
In a classification task, a precision score of 1.0 for a class C means that every item labeled as belonging to class C does indeed belong to class C (but says nothing about the number of items from class C that were not labeled correctly) whereas a recall of 1.0 means that every item from class C was labeled as belonging to class C (but says nothing about how many other items were incorrectly also labeled as belonging to class C).
Often, there is an inverse relationship between precision and recall, where it is possible to increase one at the cost of reducing the other. Brain surgery provides an obvious example of the tradeoff. Consider a brain surgeon tasked with removing a cancerous tumor from a patient’s brain. The surgeon needs to remove all of the tumor cells since any remaining cancer cells will regenerate the tumor. Conversely, the surgeon must not remove healthy brain cells since that would leave the patient with impaired brain function. The surgeon may be more liberal in the area of the brain she removes to ensure she has extracted all the cancer cells. This decision increases recall but reduces precision. On the other hand, the surgeon may be more conservative in the brain she removes to ensure she extracts only cancer cells. This decision increases precision but reduces recall. That is to say, greater recall increases the chances of removing healthy cells (negative outcome) and increases the chances of removing all cancer cells (positive outcome). Greater precision decreases the chances of removing healthy cells (positive outcome) but also decreases the chances of removing all cancer cells (negative outcome).
Usually, precision and recall scores are not discussed in isolation. Instead, either values for one measure are compared for a fixed level at the other measure (e.g. precision at a recall level of 0.75) or both are combined into a single measure, such as their harmonic mean the F-measure, which is the weighted harmonic mean of precision and recall (see below), or the Matthews correlation coefficient, which is the geometric mean of the regression coefficients Informedness (DeltaP') and Markedness (DeltaP).[1][2] Accuracy is a weighted arithmetic mean of Precision and Inverse Precision (weighted by Bias) as well as a weighted arithmetic mean of Recall and Inverse Recall (weighted by Prevalence).[1] Inverse Precision and Recall are simply the Precision and Recall of the inverse problem where positive and negative labels are exchanged (for both real classes and prediction labels). Recall and Inverse Recall, or equivalently true positive rate and false positive rate, are frequently plotted against each other as ROC curves and provide a principled mechanism to explore operating point tradeoffs. Outside of Information Retrieval, the application of Recall, Precision and F-measure are argued to be flawed as they ignore the true negative cell of the contingency table, and they are easily manipulated by biasing the predictions.[1] The first problem is 'solved' by using Accuracy and the second problem is 'solved' by discounting the chance component and renormalizing toCohen's kappa, but this no longer affords the opportunity to explore tradeoffs graphically. However, Informedness and Markedness are Kappa-like renormalizations of Recall and Precision,[3] and their geometric mean Matthews correlation coefficientthus acts like a debiased F-measure.
Definition (information retrieval context)
In information retrieval contexts, precision and recall are defined in terms of a set of retrieved documents (e.g. the list of documents produced by a web search engine for a query) and a set of relevant documents (e.g. the list of all documents on the internet that are relevant for a certain topic), cf. relevance.
Precision
In the field of information retrieval, precision is the fraction of retrieved documents that are relevant to the search:
Precision takes all retrieved documents into account, but it can also be evaluated at a given cut-off rank, considering only the topmost results returned by the system. This measure is called precision at n or P@n.
For example for a text search on a set of documents precision is the number of correct results divided by the number of all returned results.
Precision is also used with recall, the percent of all relevant documents that is returned by the search. The two measures are sometimes used together in the F1 Score (or f-measure) to provide a single measurement for a system.
Note that the meaning and usage of "precision" in the field of Information Retrieval differs from the definition of accuracy and precision within other branches of science and technology.
Recall
Recall in information retrieval is the fraction of the documents that are relevant to the query that are successfully retrieved.
For example for text search on a set of documents recall is the number of correct results divided by the number of results that should have been returned
In binary classification, recall is called sensitivity. So it can be looked at as the probability that a relevant document is retrieved by the query.
It is trivial to achieve recall of 100% by returning all documents in response to any query. Therefore, recall alone is not enough but one needs to measure the number of non-relevant documents also, for example by computing the precision.
Definition (classification context)
For classification tasks, the terms true positives, true negatives, false positives, and false negatives (see also Type I and type II errors) compare the results of the classifier under test with trusted external judgments. The terms positive andnegative refer to the classifier's prediction (sometimes known as the expectation), and the terms true and false refer to whether that prediction corresponds to the external judgment (sometimes known as the observation). This is illustrated by the table below:
| actual class (observation) |
||
|---|---|---|
| predicted class (expectation) |
tp (true positive) Correct result |
fp (false positive) Unexpected result |
| fn (false negative) Missing result |
tn (true negative) Correct absence of result |
|
Precision and recall are then defined as:[4]
Recall in this context is also referred to as the True Positive Rate or Sensitivity, and precision is also referred to as Positive predictive value (PPV); other related measures used in classification include True Negative Rate and Accuracy.[4] True Negative Rate is also called Specificity.
Probabilistic interpretation
It is possible to interpret precision and recall not as ratios but as probabilities:
- Precision is the probability that a (randomly selected) retrieved document is relevant.
- Recall is the probability that a (randomly selected) relevant document is retrieved in a search.
Note that the random selection refers to a uniform distribution over the appropriate pool of documents; i.e. by randomly selected retrieved document, we mean selecting a document from the set of retrieved documents in a random fashion. The random selection should be such that all documents in the set are equally likely to be selected.
Note that, in a typical classification system, the probability that a retrieved document is relevant depends on the document. The above interpretation extends to that scenario also (needs explanation).
Another interpretation for precision and recall is as follows. Precision is the average probability of relevant retrieval. Recall is the average probability of complete retrieval. Here we average over multiple retrieval queries.
F-measure
A measure that combines precision and recall is the harmonic mean of precision and recall, the traditional F-measure or balanced F-score:
This is also known as the 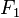 measure, because recall and precision are evenly weighted.
measure, because recall and precision are evenly weighted.
It is a special case of the general ![]() measure (for non-negative real values of
measure (for non-negative real values of 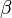 ):
):
Two other commonly used 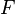 measures are the
measures are the 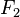 measure, which weights recall higher than precision, and the
measure, which weights recall higher than precision, and the ![]() measure, which puts more emphasis on precision than recall.
measure, which puts more emphasis on precision than recall.
The F-measure was derived by van Rijsbergen (1979) so that ![]() "measures the effectiveness of retrieval with respect to a user who attaches times as much importance to recall as precision". It is based on van Rijsbergen's effectiveness measure
"measures the effectiveness of retrieval with respect to a user who attaches times as much importance to recall as precision". It is based on van Rijsbergen's effectiveness measure ![]() . Their relationship is
. Their relationship is ![]() where
where ![]() .
.