SegNet学习笔记(附Pytorch 代码)
SegNet 的应用
SegNet常用于图像的语义分割。什么是语义分割了?,我们知道图像分割大致可以划分为三类,一类是语义分割、一类是实例分割,一类是全景分割,另外还有一些可以归为超像素分割。打个比方,如果是有一群人的沙滩排球这样的一个场景,图像中有一群人,有蓝天,大海,沙滩,还有一些椰子树。语义分割就是将人从这张图中分出来,其他的全部认为是背景;实例分割,就是不仅仅要把人分出来,还要区别不同的人;全景分割就是不仅仅要将人区分出来,而且不同椰子树区分出来,蓝天区分出来,总之不同类别的都区分出来。下图就是SegNet进行分割效果的图

SegNet原理
SegNet网络是最开始明确定义ecoder端和decoder端,它的ecoder端是使用Vgg16,总计使用了Vgg16的13个卷积层,相对于采用比较典型的ecoder用来提取图像特征,SegNet的改进侧重点在于设计优良的decoder端,decoder端将pooling indices技术应用在max pooling过程中来连接encoder的输出做一个非线性的上采样,根据SegNet这篇文章的说明,使用SegNet在计算机消耗资源以及预测分类的准确性上取得较好的平衡。
SegNet相对于全卷积分割网络的重要改进是在pooling indices上,具体体现在encoder和decoder过程中,示例如下。
SegNet 网络结构
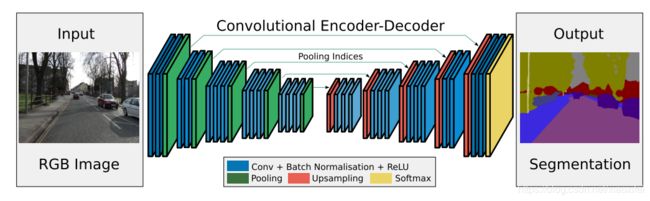
注意看一下,这里相对于Unet是有一个差别的,encoder和decoder之间skip 连接的不是tensor而是文章中所定义的pooling indices
这个图中其他部分比较好理解,根据文章的介绍,pooling过程需要较好的审视,以及upsampling过程。
在encoder端,文章记载使用的是简单的max pooling 2x2的窗宽,步长为2,毫无疑问的是采用max pooling过后的图像会变小,而且按照这样的参数配比,会变为原图的一半,同时,这会增加不变性的东西,就比如大尺度的背景,与之伴随的就是空间分辨率的下降。毫无疑问这种空间分辨率的下降对于边界的勾画是不利的,在文章的论述中,作者认为需要对这种边界信息进行存储保留,比如作者将每一个feature map中每一个pooling 窗口中最大值的localtion记录了下来;简而言之在encoder端口除了常规的conv、bn、maxpooling以外,作者将pooling窗口中的最大值location记录了下来
在decoder端,采用的也是正常的卷积、bn、relu的操作,不同的地方在于最后加上了一个softmax用来整理输出的k个channel的概率图,k是指定的分割类别数目。但是与众不同的地方在于SegNet在上采样过程中使用了在encoder端所获得的pooling indices,用这个来指导上采样过程,而不是同一般的卷积网络那样直接采用了一个卷积过程进行上采样,这样的上采样后的每一个pixel 位置都是上采样前输入图像的一个加权平均。具体情况如下所示

从这里就可以看出,使用indics的上采样,是一个不变input tensor pixel 相对位置的填充,这个也就是所谓的pixel-wise过程,按照论文的记载,这样的做法能够有一定程度的边界信息保留。
我个人的看法
SegNet首先相对于Unet或者其他需要传递feature map的网络来说,一般而言还是能够减少很多decoder模块的权重的,这也就是符合文章作者提到的在计算机消耗和accuracy中取得平衡,虽然我本人并没有在大数据集上进行过SegNet的准确性测试,但是从一些文章来看,大家普遍认为SegNet的预测精准性比较高[1]。但是我并不推荐在医学图像这样精度要求非常严格的领域内使用,相对于pooling indices,直接传送feature map的信息量还是高很多。
代码
class SegNet(nn.Module):
def __init__(self,input_nbr,label_nbr):
super(SegNet, self).__init__()
batchNorm_momentum = 0.1
self.conv11 = nn.Conv2d(input_nbr, 64, kernel_size=3, padding=1)
self.bn11 = nn.BatchNorm2d(64, momentum= batchNorm_momentum)
self.conv12 = nn.Conv2d(64, 64, kernel_size=3, padding=1)
self.bn12 = nn.BatchNorm2d(64, momentum= batchNorm_momentum)
self.conv21 = nn.Conv2d(64, 128, kernel_size=3, padding=1)
self.bn21 = nn.BatchNorm2d(128, momentum= batchNorm_momentum)
self.conv22 = nn.Conv2d(128, 128, kernel_size=3, padding=1)
self.bn22 = nn.BatchNorm2d(128, momentum= batchNorm_momentum)
self.conv31 = nn.Conv2d(128, 256, kernel_size=3, padding=1)
self.bn31 = nn.BatchNorm2d(256, momentum= batchNorm_momentum)
self.conv32 = nn.Conv2d(256, 256, kernel_size=3, padding=1)
self.bn32 = nn.BatchNorm2d(256, momentum= batchNorm_momentum)
self.conv33 = nn.Conv2d(256, 256, kernel_size=3, padding=1)
self.bn33 = nn.BatchNorm2d(256, momentum= batchNorm_momentum)
self.conv41 = nn.Conv2d(256, 512, kernel_size=3, padding=1)
self.bn41 = nn.BatchNorm2d(512, momentum= batchNorm_momentum)
self.conv42 = nn.Conv2d(512, 512, kernel_size=3, padding=1)
self.bn42 = nn.BatchNorm2d(512, momentum= batchNorm_momentum)
self.conv43 = nn.Conv2d(512, 512, kernel_size=3, padding=1)
self.bn43 = nn.BatchNorm2d(512, momentum= batchNorm_momentum)
self.conv51 = nn.Conv2d(512, 512, kernel_size=3, padding=1)
self.bn51 = nn.BatchNorm2d(512, momentum= batchNorm_momentum)
self.conv52 = nn.Conv2d(512, 512, kernel_size=3, padding=1)
self.bn52 = nn.BatchNorm2d(512, momentum= batchNorm_momentum)
self.conv53 = nn.Conv2d(512, 512, kernel_size=3, padding=1)
self.bn53 = nn.BatchNorm2d(512, momentum= batchNorm_momentum)
self.conv53d = nn.Conv2d(512, 512, kernel_size=3, padding=1)
self.bn53d = nn.BatchNorm2d(512, momentum= batchNorm_momentum)
self.conv52d = nn.Conv2d(512, 512, kernel_size=3, padding=1)
self.bn52d = nn.BatchNorm2d(512, momentum= batchNorm_momentum)
self.conv51d = nn.Conv2d(512, 512, kernel_size=3, padding=1)
self.bn51d = nn.BatchNorm2d(512, momentum= batchNorm_momentum)
self.conv43d = nn.Conv2d(512, 512, kernel_size=3, padding=1)
self.bn43d = nn.BatchNorm2d(512, momentum= batchNorm_momentum)
self.conv42d = nn.Conv2d(512, 512, kernel_size=3, padding=1)
self.bn42d = nn.BatchNorm2d(512, momentum= batchNorm_momentum)
self.conv41d = nn.Conv2d(512, 256, kernel_size=3, padding=1)
self.bn41d = nn.BatchNorm2d(256, momentum= batchNorm_momentum)
self.conv33d = nn.Conv2d(256, 256, kernel_size=3, padding=1)
self.bn33d = nn.BatchNorm2d(256, momentum= batchNorm_momentum)
self.conv32d = nn.Conv2d(256, 256, kernel_size=3, padding=1)
self.bn32d = nn.BatchNorm2d(256, momentum= batchNorm_momentum)
self.conv31d = nn.Conv2d(256, 128, kernel_size=3, padding=1)
self.bn31d = nn.BatchNorm2d(128, momentum= batchNorm_momentum)
self.conv22d = nn.Conv2d(128, 128, kernel_size=3, padding=1)
self.bn22d = nn.BatchNorm2d(128, momentum= batchNorm_momentum)
self.conv21d = nn.Conv2d(128, 64, kernel_size=3, padding=1)
self.bn21d = nn.BatchNorm2d(64, momentum= batchNorm_momentum)
self.conv12d = nn.Conv2d(64, 64, kernel_size=3, padding=1)
self.bn12d = nn.BatchNorm2d(64, momentum= batchNorm_momentum)
self.conv11d = nn.Conv2d(64, label_nbr, kernel_size=3, padding=1)
def forward(self, x):
# Stage 1
x11 = F.relu(self.bn11(self.conv11(x)))
x12 = F.relu(self.bn12(self.conv12(x11)))
x1p, id1 = F.max_pool2d(x12,kernel_size=2, stride=2,return_indices=True)
# Stage 2
x21 = F.relu(self.bn21(self.conv21(x1p)))
x22 = F.relu(self.bn22(self.conv22(x21)))
x2p, id2 = F.max_pool2d(x22,kernel_size=2, stride=2,return_indices=True)
# Stage 3
x31 = F.relu(self.bn31(self.conv31(x2p)))
x32 = F.relu(self.bn32(self.conv32(x31)))
x33 = F.relu(self.bn33(self.conv33(x32)))
x3p, id3 = F.max_pool2d(x33,kernel_size=2, stride=2,return_indices=True)
# Stage 4
x41 = F.relu(self.bn41(self.conv41(x3p)))
x42 = F.relu(self.bn42(self.conv42(x41)))
x43 = F.relu(self.bn43(self.conv43(x42)))
x4p, id4 = F.max_pool2d(x43,kernel_size=2, stride=2,return_indices=True)
# Stage 5
x51 = F.relu(self.bn51(self.conv51(x4p)))
x52 = F.relu(self.bn52(self.conv52(x51)))
x53 = F.relu(self.bn53(self.conv53(x52)))
x5p, id5 = F.max_pool2d(x53,kernel_size=2, stride=2,return_indices=True)
# Stage 5d
x5d = F.max_unpool2d(x5p, id5, kernel_size=2, stride=2)
x53d = F.relu(self.bn53d(self.conv53d(x5d)))
x52d = F.relu(self.bn52d(self.conv52d(x53d)))
x51d = F.relu(self.bn51d(self.conv51d(x52d)))
# Stage 4d
x4d = F.max_unpool2d(x51d, id4, kernel_size=2, stride=2)
x43d = F.relu(self.bn43d(self.conv43d(x4d)))
x42d = F.relu(self.bn42d(self.conv42d(x43d)))
x41d = F.relu(self.bn41d(self.conv41d(x42d)))
# Stage 3d
x3d = F.max_unpool2d(x41d, id3, kernel_size=2, stride=2)
x33d = F.relu(self.bn33d(self.conv33d(x3d)))
x32d = F.relu(self.bn32d(self.conv32d(x33d)))
x31d = F.relu(self.bn31d(self.conv31d(x32d)))
# Stage 2d
x2d = F.max_unpool2d(x31d, id2, kernel_size=2, stride=2)
x22d = F.relu(self.bn22d(self.conv22d(x2d)))
x21d = F.relu(self.bn21d(self.conv21d(x22d)))
# Stage 1d
x1d = F.max_unpool2d(x21d, id1, kernel_size=2, stride=2)
x12d = F.relu(self.bn12d(self.conv12d(x1d)))
x11d = self.conv11d(x12d)
return x11d
def load_from_segnet(self, model_path):
s_dict = self.state_dict()# create a copy of the state dict
th = torch.load(model_path).state_dict() # load the weigths
# for name in th:
# s_dict[corresp_name[name]] = th[name]
self.load_state_dict(th)
参考文献
[1]. A Review on Deep learining Techniques Applied to Semantic Segmentation
SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation