
I.前言
前两天转了章大的zeppelin系列教程(以下简称“教程”),我也好好的研究学习了一波。
我曾无数次鼓吹基于Jupyter的应用,也相信在未来数据分析领域,他会有自己的一席之地. 对话式的管家服务,真是谁用谁知道...
以下内容摘自“教程”:
下面是Zeppelin和Flink的故事。
Flink问:虽然我提供了多种语言支持,有SQL,Java,Scala还有Python,但是每种语言都有自己的入口,用户很难多种语言混着用。比如在sql-client中只能运行Sql,不能写UDF,在pyflink shell里,只能用python的udf,不能用scala和java的udf。有没有谁能帮我把这些语言全部打通。
Zeppelin答:我可以。
Flink问:我的一个很大的使用场景是实时大屏,但是我一个人办不到,往往需要借助第三方存储,还需要前端开发,有没有谁能让用户不用写前端代码就实现实时大屏
Zeppelin答:我可以。
Flink问:我的Sql已经很强大了,但是用户在sql-client里不能写comment,而且不支持运行多条sql语句,有谁能帮我把这些功能补齐下。
Zeppelin答:我可以。
Flink问:好多初学者说要跑一个flink job实在是太难了,好多东西需要配置,还要学习各种命令行,有没有谁能让用户更容易得提交和管理Flink Job。
Zeppelin答:我可以。
Flink问:Flink Job提交目前只能一个个提交,一个job跑完跑另外一个,有些用户想并行执行多个Flink Job,谁能帮我搞定这个需求?
Zeppelin答:我可以。
Flink问:我有丰富的connector,但是用户每次都要把connector打包到uber jar里,或者copy到flink的lib下,但是这样会把各种connector jar混在一起,容易发生冲突,很难管理,有谁能提供一个干净点的方案?
Zeppelin答:我可以。
**
II.填坑
Zepplin 0.9版本虽然已经做的足够出色了,但是还是有很多隐含的条件(坑),对新人还是不那么友好的,我在研习“教程”的时候,也就稍微总结了一下:
版本:
目前zepplin 0.9 preview 整合flink,只能使用 Apache Flink 1.10.1 for Scala 2.11 ,不能使用scala2.12
环境:
实验的话,需要在linux下尝试,windows是不支持,尽管他都有windows下的启动脚本.
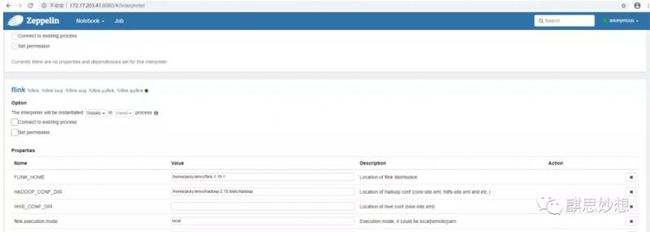
FLINK_HOME
在interpret里设置FLINK_HOME,指向你的Flink,切记1.10.1 scala2.11版本
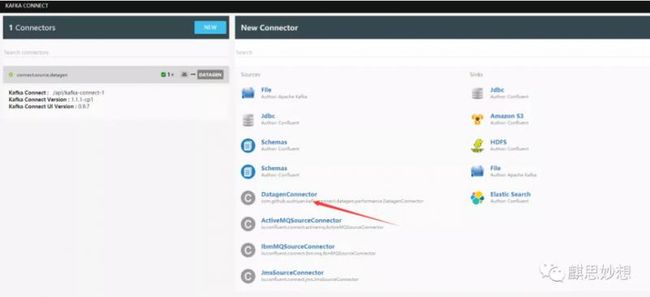
Kafka Connect Datagen
使用提供的docker镜像来做kafka集群,提供数据,安装docker不在这里说了,可能启动正常,但是没有datagenconnector
说明,docker-compose.yml里这两句没起作用
- ./plugins:/tmp/connect-plugins
- ./data:/tmp/data
执行下面语句就ok了。
setenforce 0
另外,默认配置里
KAFKA_ADVERTISED_LISTENERS: 'PLAINTEXT://broker:9092'
CONNECT_BOOTSTRAP_SERVERS: '192.168.16.3:9092'
可能不生效,使用下面语句,找到broker的ip,替换broker
docker exec -it ID/NAMES ip addr
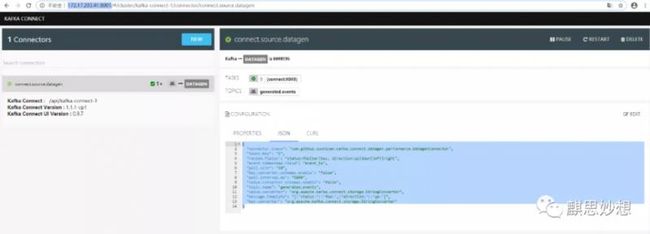
创建kafka connector时,使用官方语句可能不太好事,可以使用UI即本机IP:8000 来进行配置,原文提供的 connect.source.datagen.json 也有些不太好使,我修改了一下,如下:
{
"connector.class": "com.github.xushiyan.kafka.connect.datagen.performance.DatagenConnector",
"tasks.max": "1",
"random.fields": "status:foo|bar|baz, direction:up|down|left|right",
"event.timestamp.field": "event_ts",
"poll.size": "10",
"key.converter.schemas.enable": "false",
"poll.interval.ms": "5000",
"value.converter.schemas.enable": "false",
"topic.name": "generated.events",
"value.converter": "org.apache.kafka.connect.storage.StringConverter",
"message.template": "{"status":"foo","direction":"up"}",
"key.converter": "org.apache.kafka.connect.storage.StringConverter"
}
如下图所示
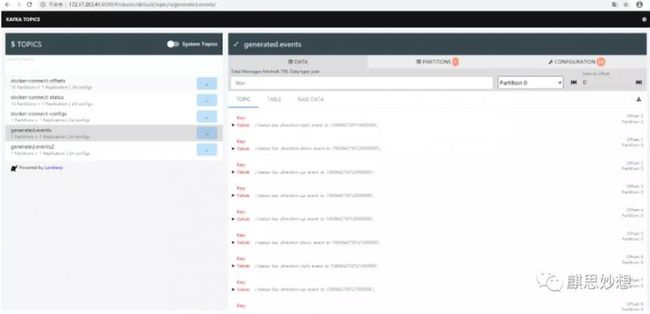
可以在Topic UI里可以看到数据,就证明这里配置ok了
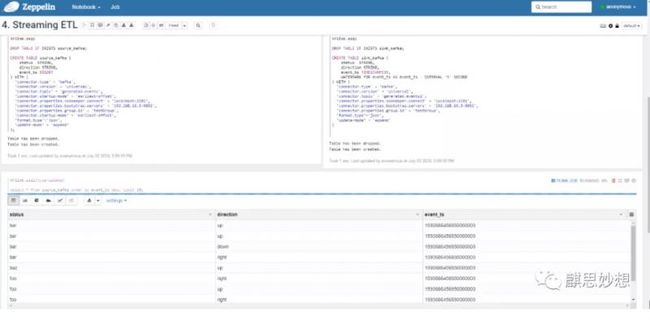
Streaming ETL
记住先执行:
%flink.conf # You need to run this paragraph first before running any flink code. flink.execution.packages org.apache.flink:flink-connector-kafka_2.11:1.10.1,org.apache.flink:flink-connector-kafka-base_2.11:1.10.1,org.apache.flink:flink-json:1.10.1
上面的坑都填好了,就能愉快的玩耍了
感谢 章大 在钉钉群里耐心的解答。
目前只踩到这里,继续加油,奥利给!!!
本文由博客群发一文多发等运营工具平台 OpenWrite 发布