视频插值--Video Frame Interpolation via Adaptive Separable Convolution
Video Frame Interpolation via Adaptive Separable Convolution
ICCV2017
https://github.com/sniklaus/pytorch-sepconv
本文将视频插帧看作一个局部分离卷积,对输入帧使用一组 1D 核。 这么做可以极大的减少参数量,加快速度。
formulates frame interpolation as local separable convolution over input frames using pairs of 1D kernels.
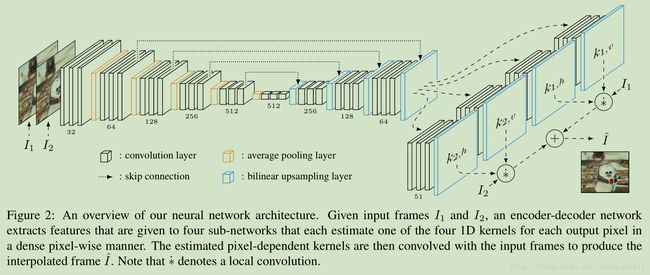
在CVPR2017那篇文章中 作者使用 一个CNN网络来估计2D 的卷积核, estimate spatially-adaptive convolution kernels for each output pixel and convolve the kernels with the input frames to generate a new frame。这些卷积核同时考虑运动估计和 re-sampling。 对于 large motion,就需要 large kernels。 这样参数量和计算量都上升了。
例如对每个输出像素 CVPR2017 那篇文献输出 两个 41×41 kernels,对于一张 1080p 图像的合成, the output kernels alone will require 26 GB of memory
当我们采用了separable convolution, For a 1080p video frame, using separable kernels that approximate 41 × 41 ones only requires 1.27 GB
3 Video Frame Interpolation
对于视频插帧问题采用 adaptive convolution approach的话可以表示为如下公式:

K1、K2 是一对 2D convolution kernels,P 1 (x,y) and P 2 (x,y) are the patches centered at (x,y) in I1 and I2
To capture large motion, large-size kernels are required,文献【36】使用 used 41 × 41 kernels
it is difficult to estimate them at once for all the pixels of a high-resolution frame simultaneously, due to the large amount of parameters and the limited memory
Our method addresses this problem by estimating a pair of 1D kernels that approximate a 2D kernel
our method reduces the number of kernel parameters from n*n to 2n for each kernel.
Loss function 这里我们考虑两类损失函数:第一类是 L1 per-pixel color difference,第二类 L_F loss functions that this work explores is perceptual loss, which has often been found effective in producing visually pleasing images

Visual comparison among frame interpolation methods
Evaluation on the Middlebury benchmark

With a Nvidia Titan X (Pascal), our system is able to interpolate a 1280 × 720 frame in 0.5 seconds as well as a 1920 × 1080 frame in 0.9 seconds. Training our network takes about 20 hours using four Nvidia Titan X (Pascal)