新手上路——hadoop2.7.3单机模式环境搭建
目的
本人是一只hadoop新手,本篇文章主要是个人学习hadoop的学习笔记,内容是搭建单机模式下hadoop2.7.3开发环境。
搭建环境及所需软件
VMWare 12(64位),ubuntu-16.04(64位),hadoop2.7.3.tar
Hadoop简介
Hadoop是Apache开源组织的一个分布式计算框架,可以在大量廉价硬件设备组成的集群上运行应用程序,并未应用程序提供一组稳定可靠的接口,旨在构建一个具有高可靠性和良好扩展性的分布式系统。Hadoop的核心是HDFS(Hadoop Distributed File System),Mapreduce和Hbase,他们分别是Google云计算核心技术GFS,Mapreduce和Bigtable的开源实现。
Hadoop的运行模式
Hadoop集群有三种运行模式,分别为单机模式,伪分布式模式和完全分布式模式。
- 单机模式
单机模式是Hadoop的默认模式,在该模式下无需任何守护进程,所有程序都在单个JVM上运行,该模式主要用于开发和调试mapreduce的应用逻辑。
- 伪分布式模式
在伪分布式模式下,Hadoop守护进程运行在一台机器上,模拟一个小规模的集群。该模式在单机模式的基础上增加了代码调试的功能,允许你检查NameNode,DataNode,Jobtracker,Tasktracker等模拟节点的运行情况。
- 完全分布式模式
单机模式和伪分布式模式均用于开发和调试的目的,真实Hadoop集群的运行采用的是完全分布式模式。
本篇文章主要是记录Hadoop单机模式的搭建过程,并附上一个wordcount示例检查搭建结果。
Hadoop单机模式安装步骤如下:
一、在Ubuntu下创建hadoop用户组和用户
添加hadoop用户组到系统用户 安装前要做一件事——添加一个名为hadoop的用户到系统用户,专门用来做hadoop测试。
maggie@ubuntu:~$ sudo addgroup hadoop
maggie@ubuntu:~$ sudo adduser --ingroup hadoop hadoop给hadoop用户系统权限
打开/etc/sudoers并修改,插入语句如下图:
maggie@ubuntu:~$ sudo gedit /etc/sudoers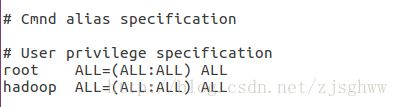
二、安装java
在宿主机上下载JDK,我在官网上下载的是jdk-8u121-linux-x64.rar
在maggie用户下,在/usr/lib目录中建立java安装目录
maggie@ubuntu:~$ cd /usr/lib
maggie@ubuntu:~$ mkdir java将jdk-8u121-linux-x64.rar拷贝纸java目录下,并解压至当前目录,得到文件及jdk1.8.0_121
maggie@ubuntu:~$ tar -xzvf jdk1.8.0_121编辑配置文件,添加环境变量,打开/etc/profile,添加如下内容:
maggie@ubuntu:~$ tar -xzvf jdk1.8.0_121
执行命令使修改文件生效
maggie@ubuntu:~$ source /etc/profile查看安装情况
maggie@ubuntu:~$ java -version
至此,JDK安装完毕。
三、安装hadoop2.7.3
在宿主机上下载hadoop软件,我下载的是hadoop-2.7.3.tar.gz,并将其复制到ubuntu /home/maggie/Downloads
当前用户为maggie,切换用户为hadoop,并且在/usr/lib目录下创建hadoop安装目录
maggie@ubuntu:~$ su hadoop
maggie@ubuntu:~$ /home/maggie$ cd /usr/lib
hadoop@ubuntu:/usr/lib$ mkdir hadoop
将hadoop压缩包直接解压到hadoop安装目录,得到文件夹hadoop-2.7.3
hadoop@ubuntu:/usr/lib$ cd /home/maggie/Downloads
hadoop@ubuntu:/home/maggie/Downloads$ tar -xzvf hadoop-2.7.3.tar.gz /usr/lib/hadoop设置hadoop-env.sh(java 安装路径)
进入该文件目录
hadoop@ubuntu:/home/maggie/Downloads$ cd /usr/lib/hadoop/hadoop-2.7.3/etc/hadoop里面有如下文件:
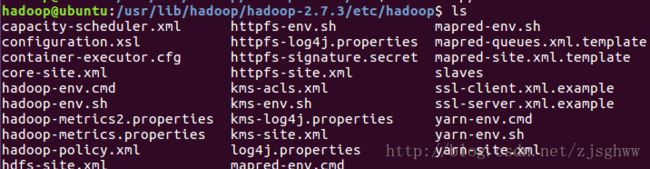
编辑目标文件:
hadoop@ubuntu:/usr/lib/hadoop/hadoop-2.7.3/etc/hadoop$ vi hadoop-env.sh加入下面的内容(根据实际路径):

推出vi编辑,并且让添加的环境变量立即生效
hadoop@ubuntu:/usr/lib/hadoop/hadoop-2.7.3/etc/hadoop$ source hadoop-env.sh至此,hadoop的单机模式已经安装成功!
下面运行一下wordcount程序试验一下
在hadoop-2.7.3目录中新建input文件夹
hadoop@ubuntu:/usr/lib/hadoop/hadoop-2.7.3$ mkdir input把该目录下/etc/hadoop中的所有文件都拷贝到input文件夹中
hadoop@ubuntu:/usr/lib/hadoop/hadoop-2.7.3$ cp /usr/lib/hadoop/hadoop-2.7.3/etc/hadoop/* input运行wordcount程序,并将结果保存在output中由于我所下载的hadoop软件中没有自带的hadoop example jar包,所以需要自行下载。我在宿主机中下载了hadoop-examples-1.2.1.jar,下载链接http://www.java2s.com/Code/Jar/h/Downloadhadoopexamples121jar.htm, 然后将其复制在/usr/lib/hadoop/hadoop-2.7.3目录下

hadoop@ubuntu:/usr/lib/hadoop/hadoop-2.7.3$ hadoop jar hadoop-examples-1.2.1.jar wordcount input outputmapreduce过程如下图所示(一部分):

hadoop@ubuntu:/usr/lib/hadoop/hadoop-2.7.3$ cat output得到wordcount程序运行结果(一部分):

至此,wordcount示例程序运行完成!