机器学习之Ensemble(一些推导与理解)
集成学习,其实就是通过构建并结合多个学习器来完成学习任务。 前面刚学的随机森林就是一种集成学习方法,随机森林就是由多个分类器,比如决策树,SVM等集合而成的一种模型。
本文借助了李宏毅机器学习笔记,主要是想用通俗易懂的语言来解释相关概念,并且使自己掌握得更加牢靠!!
集成学习主要分为串行的Boosting和并行的Bagging,以及Stacking,下面将依次介绍。
目录
- 一、Bagging
- 1.复习bias和variance
- 2.引出bagging
- 3.bagging的思想
- 4、决策树与随机森林
- 二、Boosting
- 1.Boosting的框架
- 2.互补的分类器
- 3.AdaBoost
- 1.定义错误率
- 2.调整权值
- 3.整合所有分类器
- 1.Uniform weight
- 2.Non-uniform weight
- 4.AdaBoost的推导
- 5.AdaBoost的有趣现象
- 4.Gradient Boosting
- 三、Stacking
一、Bagging
1.复习bias和variance
给出一个前提:当一个模型越复杂时,它的拟合能力就会越强,也更容易产生过拟合。
偏差是指在不同训练集上训练得到的所有模型的平均性能和最优模型的差异,可以用来衡量模型的拟合能力;而方差描述的是同一个算法在不同数据集上的预测值和所有数据集上的平均预测值之间的关系(可以想象成算法的稳定性如何)。
简单来说呢,偏差就是描述一个模型的学习能力,比如我在训练集上表现很好;而方差描述的是一个模型的稳定性,比如我换一组数据,那么该模型是否还能有稳定的表现呢?
所以,当模型的复杂度增加时,模型的拟合能力得到增强,偏差便会减小,但很有可能会由于拟合过度,从而对数据扰动更加敏感,导致方差增大。
因此,对于一个简单的模型,我们会有比较大的bias,因为它学习能力弱爆了,连训练集都不能很好的拟合,但是有比较小的 variance;如果是复杂的模型,我们则是比较小的bias以及比较大的variance。
2.引出bagging
那怎么解决一个比较复杂的模型方差大偏差小的问题呢?答案就是bagging。
bagging的思想就是我们从多个训练集上训练得到多个模型,然后把所有的模型集合起来,做一个平均的处理,这样方差便往往不会那么大了。
3.bagging的思想
假设有训练集有N个样本。
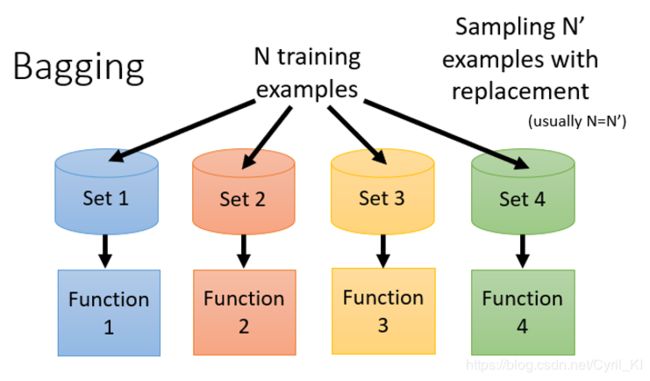
- 从训练集中抽出 N ′ N^{'} N′个样本,注意这里是有放回抽样,也就是你取样一个标记好输入输出,然后再将它放进去,抽取下一个样本。
- 重复步骤1,我们得到多个数据集set1,set2…。
- 对每一个数据集,我们都用一个复杂的模型对其进行学习,得到多个function。
接下来在testing的时候,就把testing data放到每一个function里面,再把得出来的结果做平均(回归)或者投票(分类),通常来说表现(variance比较小)都比之前的好,这样就不容易产生过拟合。
当一个模型的方差较大,而偏差较小时,为了减小方差,我们就可以使用bagging的策略。
4、决策树与随机森林
决策树就是一种非常容易过拟合的模型。 对于决策树,这个前面已经讲过了,随机森林就是bagging的典型代表。具体请参考:
机器学习之决策树与随机森林
前面我们也提到,假设用bagging来处理决策树时,如果每次都选择全部样本,也就是 N ′ = N N^{'}=N N′=N,并且,在每一次选择生成新结点时,我们考虑了所有的特征,那么这种比较传统的“随机森林”方法得到的每棵树其实都差不多,效果并不好,之所以叫“传统的随机森林”,是因为它并没有做到真正的随机。
真正的随机是随机地限制一些特征或者样本不能用,这样就能保证就算用同样的dataset,每次产生的决策树也会是不一样的,然后把所有的决策树的结果都集合起来,就会得到随机森林。
OOB error:

假设我们有 x 1 , x 2 , x 3 , x 4 x^1,x^2,x^3,x^4 x1,x2,x3,x4四个样本,我们在训练f1这个特征,也就是我们生成子结点算信息增益的时候,没有考虑 x 3 , x 4 x^3,x^4 x3,x4这两个样本,在训练f4时,我们没考虑 x 1 , x 3 x^1,x^3 x1,x3两个样本,所以在训练f1和f4的时候我们没有用到样本 x 3 x^3 x3,那么我们就可以用f1和f4 bagging的结果来测试 x 3 x^3 x3,其他几组同样如此,最后把每一组的测试结果取平均error,这个结果就是OBB error。
我们需要知道,做bagging并不会使模型变得更加fit data,我们只是让模型变得更加“圆滑”,方差更小。
二、Boosting
前面讲的决策树,拟合能力过于强大,容易发生过拟合,这个时候我们就需要使用bagging策略来使得模型对不同数据处理后误差的方差变得小一点,也就是更加稳定一点。
而Boosting,则是针对一个学习能力弱的模型,该模型不能很好拟合训练集的数据。
1.Boosting的框架
- 首先我们找到一个学习能力比较弱的分类器模型 f 1 ( x ) f_{1}(x) f1(x)。
- 寻找另一个分类器模型 f 2 ( x ) f_{2}(x) f2(x)来辅助 f 1 ( x ) f_{1}(x) f1(x),这里要注意的是,二者不能太相似, f 2 ( x ) f_{2}(x) f2(x)是来弥补 f 1 ( x ) f_{1}(x) f1(x)的能力的,来做到一些它不能做到的事情。
- 找到另一个分类器 f 3 ( x ) f_{3}(x) f3(x)来弥补 f 2 ( x ) f_{2}(x) f2(x)。
- 如此不断重复下去,最后再将所有的分类器合在一起,就可以得到一个在训练集上拟合很好的新模型。
观察上面的框架,我们可以发现,怎么找到一个分类器,让它跟前一个分类器互补,是Boosting的关键所在。 同时我们也发现训练模型是有顺序的,我们必须先找到 f 1 ( x ) f_{1}(x) f1(x)才能找到 f 2 ( x ) f_{2}(x) f2(x),这也是串行二字的由来,而作为对比,bagging是没有顺序的,随机森林里所有树都是可以同时进行训练的。
2.互补的分类器
分类器不同,那么其训练集自然是不同的,那怎么得到不同的data set呢?第一个方法跟bagging类似,采用重采样也就是有放回抽样的方式来产生不同的data set。
第二个方法是采用改变权重的方式来生成新的数据集。我们以我们最熟悉的二分类问题来举例。假设一个训练集: ( x 1 , y 1 ^ , u 1 ) , ( x 2 , y 2 ^ , u 2 ) , ( x 3 , y 3 ^ , u 3 ) {(x^1,y\hat{1},u_{1}),(x^2,y\hat{2},u_{2}),(x^3,y\hat{3},u_{3})} (x1,y1^,u1),(x2,y2^,u2),(x3,y3^,u3),u为权重,假设三者权重都是1,我们改变三者权重分别为1,3.8,2.7,就相当生成了一个新的data set。原先的损失函数为:
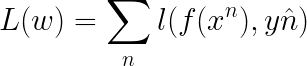
当我们给每一个样本都加上权重之后,新的损失函数为:

从新的损失函数我们可以看出,如果一个样本的权重较大,那么在训练的时候它就会被多考虑一点。
3.AdaBoost
AdaBoost的策略是:我们先得到一个学习能力较弱的 f 1 ( x ) f_{1}(x) f1(x),接下来要找一组与 f 1 ( x ) f_{1}(x) f1(x)互补的 f 2 ( x ) f_{2}(x) f2(x),那么我们就可以先找到一个新的训练集,让原来的 f 1 ( x ) f_{1}(x) f1(x)在这个上面的拟合能力很烂,然后再用这个训练集来训练产生新的 f 2 ( x ) f_{2}(x) f2(x),这样 f 2 ( x ) f_{2}(x) f2(x)就与 f 1 ( x ) f_{1}(x) f1(x)互补了。。。。真会玩。那么我们该如何找到这个可以让 f 1 ( x ) f_{1}(x) f1(x)表现很烂的训练集呢?
1.定义错误率
假设我们有一组训练数据如下所示:
( x 1 , y 1 ^ , u 1 ) , ( x 2 , y 2 ^ , u 2 ) , ( x 3 , y 3 ^ , u 3 ) , . . . , ( x n , y n ^ , u n ) {(x^1,y\hat{1},u_{1}),(x^2,y\hat{2},u_{2}),(x^3,y\hat{3},u_{3}),...,(x^n,y\hat{n},u_{n})} (x1,y1^,u1),(x2,y2^,u2),(x3,y3^,u3),...,(xn,yn^,un),我们定义错误率为:
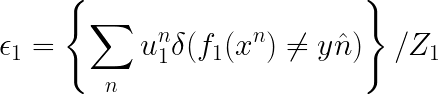
其中 Z 1 = ∑ n u 1 n Z1=\sum_{n}^{}u_{1}^{n} Z1=∑nu1n。上述错误率并不只是简单的考虑分类正确与否,还要考虑一个样本的权重如何,比如该分类器分错了一个权重较大的样本,另一个分类器分错了一个权重较小的样本,那么我们应认为前者的错误率明显是高于后者的。
举一个实例:

刚开始所有样本权重都相同,那么刚开始错误率就为0.25,我们把分错的那一个样本的权重加大,最后错误率也就变大了,变成了0.5,也就是说一开始的分类器 f 1 ( x ) f_{1}(x) f1(x)在新的训练集上表现就变得更烂了,用新的训练集训练产生新的分类器 f 2 ( x ) f_{2}(x) f2(x),那么二者就是互补的。
2.调整权值
好了我们知道如何产生新的分类器了,产生的关键就是调整权值。其实做法很简单:对于第一笔训练数据我们需要将它的样本都调整权值,使得 f 1 ( x ) f_{1}(x) f1(x)在上面的表现变烂即可。给定一个参数d1>1,我们将 f 1 ( x ) f_{1}(x) f1(x)分类错的样本的权值都乘上d1,而分类对的样本的权值都除以d1,这样一番操作之后, f 1 ( x ) f_{1}(x) f1(x)在上面的错误率肯定就会上升了,变成0.5即可。 为啥是0.5?后面会给出证明。
简单推导一下:
当权值由u1乘上(分类错误)或者除以一个系数d1(分类正确)后, f 1 ( x ) f_{1}(x) f1(x)在上面的错误率变成0.5,那么求和的那个式子,我们根据是否分类正确,把它拆成两部分,如上图所示,一系列推导之后可以得到d1的表达式。最后再用d1按照上述思想处理一下data set中各个样本的权重,就可以得到一个让 f 1 ( x ) f_{1}(x) f1(x)恶心的数据集,用此数据集训练得到的 f 2 ( x ) f_{2}(x) f2(x)就可以说是与 f 1 ( x ) f_{1}(x) f1(x)互补了。然后在对新的数据集作出相同处理,得到让 f 2 ( x ) f_{2}(x) f2(x)恶心的数据集,来训练得到 f 3 ( x ) f_{3}(x) f3(x),以此类推。
有时候我们对 d t d_{t} dt取对数,得到 α t \alpha_{t} αt如下所示:
![]()
这样,我们在更新权值的时候,就统一用乘的形式。对于判断错误的样本,乘上 e x p ( α t ) exp(\alpha_{t}) exp(αt),否则乘上 e x p ( − α t ) exp(-\alpha_{t}) exp(−αt)。
3.整合所有分类器
一般有两种方式进行整合。
1.Uniform weight
简单来说就是把所有分类器对一个样本的训练结果相加,看结果是正的还是负的,正的就代表class 1,负的代表class 2。但这样很显然不是最合理的,因为每个分类器都是不一样的,有好有坏,可能有的分类器就是垃圾,效果不是很好,那么它对最终结果的影响我们应当去减小;而对于分类表现较好的分类器应该增加在最终结果中所占的比例。
2.Non-uniform weight
Non-uniform weight就是解决了Uniform weight存在的问题,在每一个分类器前面都乘上一个权重值,最后再相加。这里的权重为:
![]()
错误率越大,权重越小。
4.AdaBoost的推导
我们要证明,随着我们的分类器越来越多,组合之后得到的合成分类器对训练集的拟合会越来也好,也就是错误率会越来越小!


5.AdaBoost的有趣现象
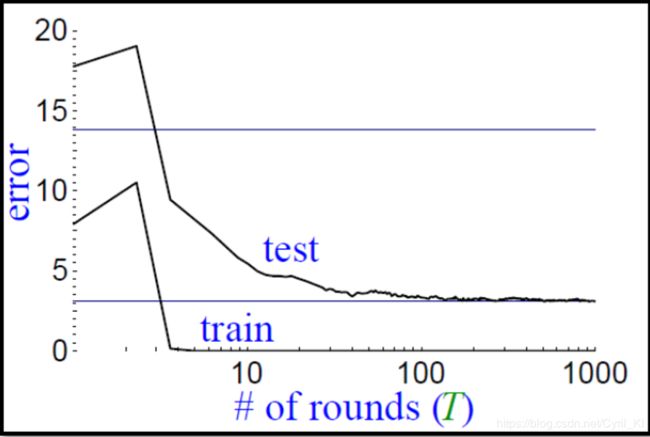
我们可以看到,当我们大概用5个不同的分类器组合之后,合成的分类器在训练集上的错误率就已经降为0了!!!再往后错误率不变,也就是说模型在训练集上已经不能学到什么新的东西了,但是奇怪的是,在测试集上的错误率依然还在下降。
我们定义:
![]()
g ( x ) g(x) g(x)就是上文证明过程中的 g ( x ) g(x) g(x),即:
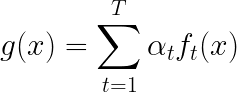
我们希望margin的两部分同号,因为同号才表示分类正确,但现在我们不仅仅只是希望它们同号,而是希望它们的成绩越大越好,为什么呢?比如说标签是+1,g(x)只是0.0001,很小,那么就很容易分类错误。
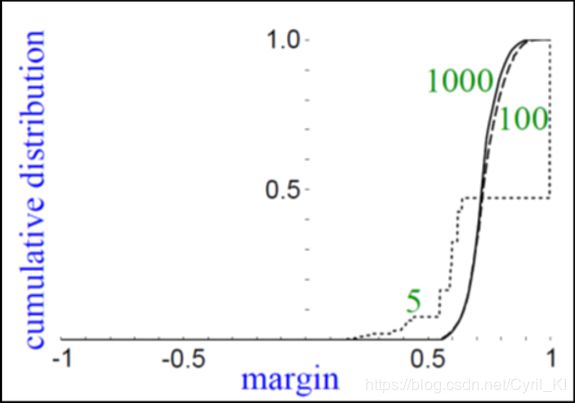
当只有5个分类器结合时,margin如虚线所示,1000时如实线所示。可以看到,虽然分类器大于5之后模型对训练集的错误率不再改变,但是呢,margin是在增加的。而增加margin可以使得模型更加具有鲁棒性,因此在测试集上的表现依旧会变得更好!
如果对margin理解地不是很好,可以参考SVM中的margin定义及其意义:
机器学习之SVM(Hinge Loss+Kernel Trick)原理推导与解析
为什么margin会增加?
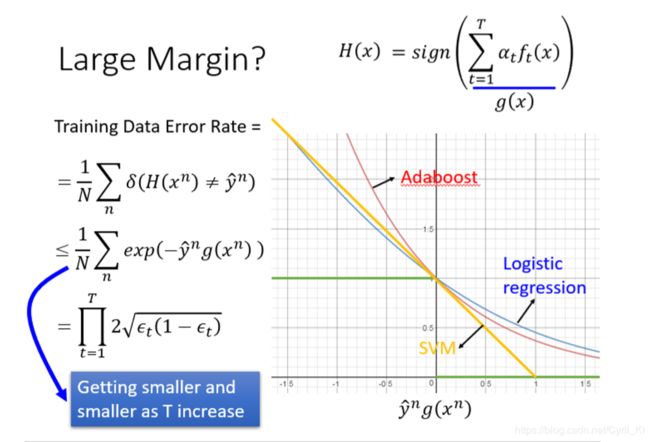
红色的线就是AdaBoost的目标函数,从图中可以看出AdaBoost在横坐标为0后,margin依旧能不断增大。
4.Gradient Boosting
Gradient Boosting是Boosting更泛化的一个版本,可以运用在多个场合。

T表示最终有多少个分类器。每次我们都需要找到一个新的 f t ( x ) f_{t}(x) ft(x)和 α t \alpha_{t} αt来提升 g t − 1 ( x ) g_{t-1}(x) gt−1(x), g t − 1 ( x ) g_{t-1}(x) gt−1(x)是指前t-1模型共同作用的模型。寻找到新的 f t ( x ) f_{t}(x) ft(x)和 α t \alpha_{t} αt后让并让它参与到对最终结果的决策当中去,并且我们要保证加进去之后效果必须更好才行。
那么我们怎么才能找到一个新的 f t ( x ) f_{t}(x) ft(x)和 α t \alpha_{t} αt使得它加进去之后效果更好呢?怎么评价加入后产生的 g t ( x ) g_{t}(x) gt(x)效果更好??根据机器学习的思想,我们可以对每一个模型 g t ( x ) g_{t}(x) gt(x)定义一个损失函数为:
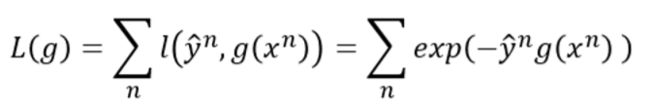
这里的 l l l可以是前面学到的交叉熵,或者Square Error等等,这里我们不采用比较常规的,而是采用如上图的损失函数。从定义我们可以看出来:当 y n ^ y\hat{n} yn^与 g ( x n ) g(x^n) g(xn)同号并且他们的乘积越大时,损失函数就越小。
使损失函数最小,我们很容易想到梯度下降法,根据梯度下降法,L是g的函数,我们可以让L对g求导,然后乘以一个learning rate,并让当前的g减去这个乘积,最后赋值给新的g,最后寻求到一个g可以使得L最小。 即:

那么关键就是求导了。g是一个函数,L也是一个函数,函数怎么对函数求导呢?这里好像涉及到泛函的概念了,博主本人现在也只是大二的水平,只学过简单的高数线代概率论!!! 感觉有点难以解释,干脆我们就把g当成一个参数吧。。。
如果不从梯度下降的方面去解释,而从Boosting的角度去解释,那么表达式就是这样的:
![]()
这个比较好理解,前面AdaBoost已经解释过了,这里就不再解释了,这里再放下这张图:
把两种思路一比较,我们可以发现红框框里面的两部分,作为向量,方向应该是相同的,即 f t ( x ) f_{t}(x) ft(x)的方向与上面那个偏微分向量方向应该是一样的。假设把g看出一个参数,根据L的表达式以及复合函数的求导法则,我们可以得到两个红框框中间的表达式。即 f t ( x ) f_{t}(x) ft(x)的方向要尽可能的和那个求导结果的方向一致。
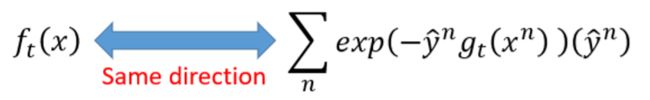
关于向量,其实我们可以把 f t ( x ) f_{t}(x) ft(x)看成一个无穷多维的向量,但是当样本数据量一定时,它就是有限的向量,也就是把每一个样本代入 f t ( x ) f_{t}(x) ft(x),得到很多输出,这些输出组成了一个向量。 那该怎么定义两个向量的一致性呢??啊啊啊啊,好像有点迷糊。
书上的方法是用内积,其实也很好理解的,如果两个向量方向越一致,那么它们的每一维度至少正负号是要相同的,暂时不考虑大小一致。也就是说两个向量方向越一致,那么它们的内积也就越大。 于是我们就可以得到以下表达式:
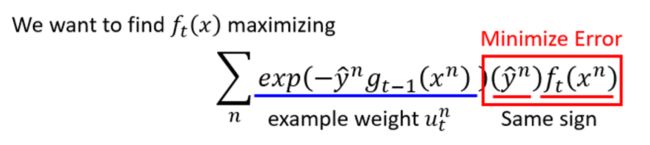
直接求inner product然后maximize它就行了。 对于上面这个式子,该怎么理解? y n ^ y\hat{n} yn^与 f t ( x n ) f_{t}(x^n) ft(xn)自然是要same sign的,也就是说同号才能使得该表达式最大,至于前面那部分表达式,我们可以看成是一个权重值。
对于那个权值,把与 g t − 1 ( x n ) g_{t-1}(x^n) gt−1(xn)表达式带进去,我们可以得到以下结果:
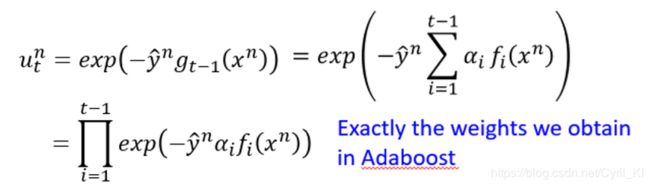
然后我们惊奇地发现,这个weight竟然就是AdaBoost的weight, 前面的推导再看一下:
所以在AdaBoost里面,找一个弱的分类器 f t ( x ) f_{t}(x) ft(x)的时候,就相当于用梯度下降法更新参数,然后使得损失变小。
接下来就是寻找learning rate,也就是 α t \alpha_{t} αt。这里利用的方法是固定已经找到的 f t ( x ) f_{t}(x) ft(x),然后穷举所有的 α t \alpha_{t} αt,来使得损失函数最小。具体求解方法就是求得L对 α t \alpha_{t} αt的导数然后置为0,具体就不再推了。。。能力有限。这里给出老师的推导过程:

事实上,最后也不出所料地发现, α t \alpha_{t} αt呢,也等于AdaBoost里面的 α t \alpha_{t} αt。
所以,AdaBoost其实可以想象成在做梯度下降,只是这里在对函数求导。 之所以最后推导出的结果一样,是因为刚开始我们选择了那个损失函数的缘故:
假如换成了其它的损失函数,我们就可以得到不一样的AdaBoost。
三、Stacking
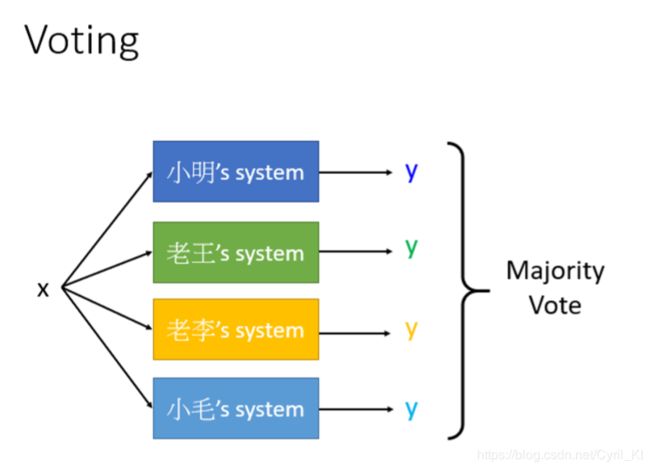
比如我们得到了四个模型,现在要将它们整合到一起,这个其实前面AdaBoost也讲过,也就是少数服从多数的选择,很多个模型都认为样本x属于class 1,那么我们就认为这个样本就是属于class 1的。 但是前面我们也说过了,可能有的模型就是很垃圾那种,在最终决策的时候,你不能赋予这个比较垃圾的模型跟一个比较好的模型一样的地位。于是呢,就提出了Stacking的思想:
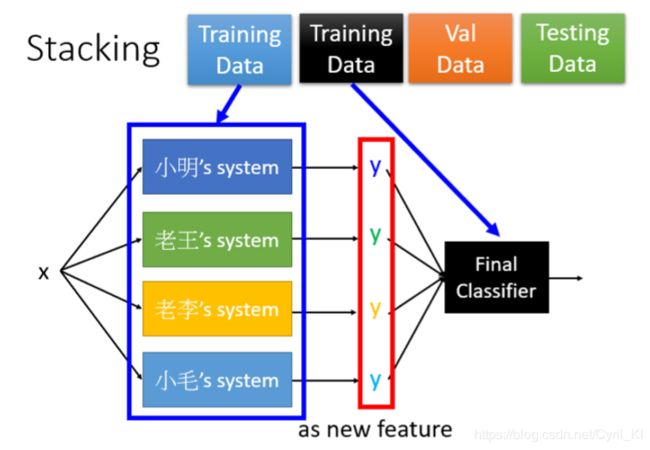
我们可以把多个分类器的输出y,作为一组新的特征输入到一个分类器当中,比如一个逻辑回归(不需要太复杂的模型),然后得到最终的分类结果。而stacking的思想就是,我们要把原先训练 f t ( x ) f_{t}(x) ft(x)的那些training data拿出来一部分来学习最终的那个分类器,比如说逻辑回归。为什么要这么做?因为 f t ( x ) f_{t}(x) ft(x)里面,可能有那种什么都没做但是拟合程度依然很高的模型,比如只是单纯输出原来训练数据集的标签,但是根本没有训练,用训练过这种模型的数据,再来训练最终的分类器,那么分类器就会认为上述这种垃圾模型是很好的,这显示是不对的。