简洁明了的tensorflow2.0教程——CNN卷积网络的实现(cifar10数据集)
CNN
通过本文你能了解到基本的卷积神经网络概念还有理论基础,通过使用keras编写一个简单的CNN模型我们可以实现对cifar10数据集的分类,掌握tensorflow搭建卷积神经网络的技巧,废话不多说,进入正文。相关代码还有数据集在我的github,链接https://github.com/JohnLeek/Tensorflow-study:,需要的自取,day4开头的部分为本节博客源码,觉得不错的可以给个star。
一、卷积神经网络结构和相关概念(参考维基百科)
因为卷积神经我网络概念很多,因为我侧重实现,这里我不做展开,我收集了部分博客,对卷积的理论没有储备的可以参考如下的博客:
1、CNN笔记:通俗理解卷积神经网络:https://blog.csdn.net/v_JULY_v/article/details/51812459
2、卷积神经网络(CNN)详解https://zhuanlan.zhihu.com/p/47184529
这两篇文章很详细的介绍了卷积神经网络相关概念,随后的代码中我们会用到,我也会给出注释,方便理解。
二、数据集准备
这里我们使用cifar10数据集,下面对cifar10数据集做个简单介绍,参考博客为:https://blog.csdn.net/DaVinciL/article/details/78793067,
CIFAR-10数据集由10类32x32的彩色图片组成,一共包含60000张图片,每一类包含6000图片。其中50000张图片作为训练集,10000张图片作为测试集。
CIFAR-10数据集被划分成了5个训练的batch和1个测试的batch,每个batch均包含10000张图片。测试集batch的图片是从每个类别中随机挑选的1000张图片组成的,训练集batch以随机的顺序包含剩下的50000张图片。不过一些训练集batch可能出现包含某一类图片比其他类的图片数量多的情况。训练集batch包含来自每一类的5000张图片,一共50000张训练图片。
下图显示的是数据集的类,以及每一类中随机挑选的10张图片:

tensorflow2.0下载数据集准备,使用如下代码即可完成下载。
cifar10 = tf.keras.datasets.cifar10但是需要科学上网,这里我提前准备好数据集了,大家在我的github下载好了放到我截图中的位置即可。

二、tensenflow2.0中关于卷积相关函数简介
1、数据集加载函数
cifar10 = tf.keras.datasets.cifar10(x_train,y_trian),(x_test,y_test) = cifar10.load_data()
这里我们使用tf中keras模块加载数据集,最后会返回两个元组,一个为训练集,一个为测试集,函数为load_data()
2、Conv2D
tf.keras.layers.Conv2D(
filters, kernel_size, strides=(1, 1), padding='valid', data_format=None,
dilation_rate=(1, 1), activation=None, use_bias=True,
kernel_initializer='glorot_uniform', bias_initializer='zeros',
kernel_regularizer=None, bias_regularizer=None, activity_regularizer=None,
kernel_constraint=None, bias_constraint=None, **kwargs
)该函数将创建一个卷积核,这里我只使用filters(卷积核),kerel_size(卷积核大小),strides(步长),padding(全零填充,valid表示不使用全零填充,same表示使用全零填充)
2、BatchNormalization
tf.keras.layers.BatchNormalization(
axis=-1, momentum=0.99, epsilon=0.001, center=True, scale=True,
beta_initializer='zeros', gamma_initializer='ones',
moving_mean_initializer='zeros', moving_variance_initializer='ones',
beta_regularizer=None, gamma_regularizer=None, beta_constraint=None,
gamma_constraint=None, renorm=False, renorm_clipping=None, renorm_momentum=0.99,
fused=None, trainable=True, virtual_batch_size=None, adjustment=None, name=None,
**kwargs
)该函数为披标准化函数,作用为:加速收敛、控制过拟合,可以少用或不用Dropout和正则、降低网络对初始化权重不敏感、允许使用较大的学习率。
3、Activation
tf.keras.layers.Activation(
activation, **kwargs
)指定当前神经网络层激活函数,这里我们使用relu激活函数,
4、MaxPool2D
tf.keras.layers.MaxPool2D(
pool_size=(2, 2), strides=None, padding='valid', data_format=None, **kwargs
)最大池化函数,pool_size(池化层大小),strides(步长),padding(是否使用全零填充,valid表示不使用全零填充,same表示使用全零填充)
5、Dropout
tf.keras.layers.Dropout(
rate, noise_shape=None, seed=None, **kwargs
)该函数用来随机舍弃神经元,防止训练过程中出现过拟合情况,我们只用rate
总结:在搭建卷积神经网络过程中我们使用到了如下的口诀,CBAPD,分别对应tf函数为Conv2D,BatchNormalization,Activation,MaxPool2D,Dropout,请记住,卷积就是特征提取器,在下边的代码中我们会遵循CBAPD来实现一个卷积神经网络
三、基础卷积神经网络实现
这里我们要搭建一个这样结构的卷积神经网络,CBAPD,CBA,CBAPD,全连接层(128*128*10)
1.我们首先加载数据集
cifar10 = tf.keras.datasets.cifar10
(x_train,y_trian),(x_test,y_test) = cifar10.load_data()2、归一化处理
运用归一化处理能够加快神经网络收敛速度
x_train,x_test = x_train/255.0,x_test/255.03、搭建卷积模型(重点)
这里我们不同于我之前的博客,我们使用类的方式来搭建CNN,随后的博客中也只需要更改3中的卷积模块即可实现功能。
这里我们指定一个类,继承自tf.keras.Model
class Baseline(Model):然后弄一个初始化函数
def __init__(self):再实现父类的init方法
super(Baseline,self).__init__()完整代码如下
class Baseline(Model):
def __init__(self):
super(Baseline,self).__init__()
self.c1 = Conv2D(filters=6,kernel_size=(5,5),padding="same")#卷积层
self.b1 = BatchNormalization()#BN层
self.a1 = Activation("relu")
self.p1 = MaxPool2D(pool_size=(2,2),strides=2,padding="same")#池化层
self.d1 = Dropout(0.2)
self.c2 = Conv2D(filters=12,kernel_size=(5,5),padding="same")
self.b2 = BatchNormalization()
self.a2 = Activation("relu")
self.c3 = Conv2D(filters=24,kernel_size=(5,5),padding="same")
self.b3 = BatchNormalization()
self.a3 = Activation("relu")
self.p3 = MaxPool2D(pool_size=(2,2),strides=2,padding="same")
self.d3 = Dropout(0.2)
self.flatten = Flatten()
self.f1 = Dense(128,activation="relu")
self.d4 = Dropout(0.2)
self.f2 = Dense(128,activation="relu")
self.d5 =Dropout(0.2)
self.f3 = Dense(10,activation="softmax")结合CBAPD是不是显得很清晰呢,到这里我们完成了网络结构的搭建,现在我们还要过一遍前向传播
我们使用call函数来表示
def call(self,x):
x = self.c1(x)
x = self.b1(x)
x = self.a1(x)
x = self.p1(x)
x = self.d1(x)
x = self.c2(x)
x = self.b2(x)
x = self.a2(x)
x = self.c3(x)
x = self.b3(x)
x = self.a3(x)
x = self.p3(x)
x = self.d3(x)
x = self.flatten(x)
x = self.f1(x)
x = self.d4(x)
x = self.f2(x)
x = self.d5(x)
y = self.f3(x)
return y4.、训练过程参数配置
这里可以参考我之前的这篇博客,细节讲解全在里边了https://blog.csdn.net/JohnLeeK/article/details/106423634
1、指定学习率,优化器等
model.compile(optimizer = tf.keras.optimizers.Adam(
learning_rate = 0.001,beta_1 = 0.9,beta_2 = 0.999#自定义动量,adam和学习率,也是为了提高准确率
),
loss = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics = ["sparse_categorical_accuracy"]
)断点续训:
checkpoint_save = "./checkpoinCNNBase/Baseline.ckpt"
if os.path.exists(checkpoint_save+".index"):
print("---------------load the model----------------------")
model.load_weights(checkpoint_save)
cp_callback = tf.keras.callbacks.ModelCheckpoint(
filepath = checkpoint_save,
save_weights_only = True,
save_best_only = True
)3、将数据喂入神经网络
history = model.fit(
x_train,y_trian,batch_size = 2048,epochs = 300,validation_data = (x_test,y_test),
validation_freq = 1,callbacks = [cp_callback]
)4、打印网络结构
model.summary()5、保存权重
file = open("./cifar10_weights.txt","w")
for v in model.trainable_variables:
file.write(str(v.name)+"\n")
file.write(str(v.shape)+"\n")
file.write(str(v.numpy())+"\n")
file.close()6、绘制准确率和损失函数并保存
acc = history.history["sparse_categorical_accuracy"]
val_acc = history.history["val_sparse_categorical_accuracy"]
loss = history.history["loss"]
val_loss = history.history["val_loss"]
plt.subplot(1,2,1)
plt.plot(acc,label = "Training Acc")
plt.plot(val_acc,label = "Validation Acc")
plt.title("Training and Validation Acc")
plt.legend()
plt.subplot(1,2,2)
plt.plot(loss,label = "Training Loss")
plt.plot(val_loss,label = "Validation Loss")
plt.title("Trainning and Validation Loss")
plt.legend()
plt.savefig("./day4_cifar1_baseline")四、结果展示
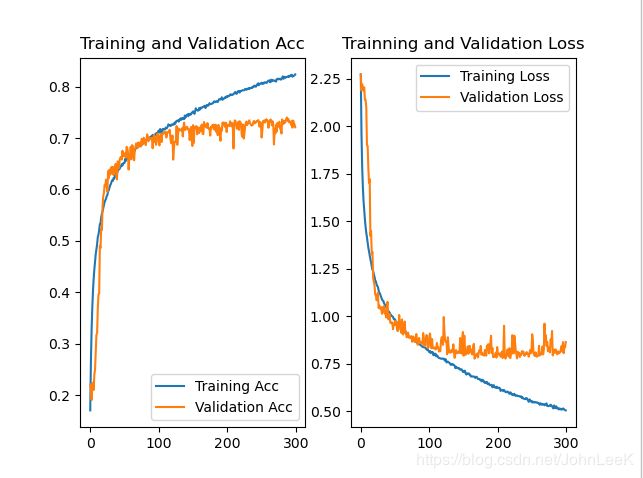
这里 可以看到在经过300轮的训练之后我们的神经网络,对cifar10数据集的分类准确率能达到80%以上,但是我们还可以发现80%并不是最优的结果,从图中观察可以发现准确率曲线没有趋于平滑,还有上升的趋势,原因如下:
1.我训练次数偏少只训练了300轮,对于当前网络模型并未达到最优解
2.我并未对神经网络结构进行优化,卷积层数较少,特征提取能力较弱
3.全连接层偏少分类预测率较低
这里还请大家思考如何调参使得分类准确率可以进一步上升,随后的博客中我会复现LNet5,VGG16,InceptionNet,ResNet这些经典的卷积神经网络,大家可以发现对cifar10数据集的分类会不停的上升,更改的地方也只有class BaseLine部分,有疑问的地方欢迎评论,最后你要是觉得我这篇博客写的不错麻烦在github给star吧,谢谢啦!