贵师大-大数据实训项目-笔记
我们要做什么:
目标:电商网站+电商网站后台管理系统+大数据分析+数据可视化
思路:按照数据的采集,数据的存储,数据分析处理,数据可视化
逻辑图:
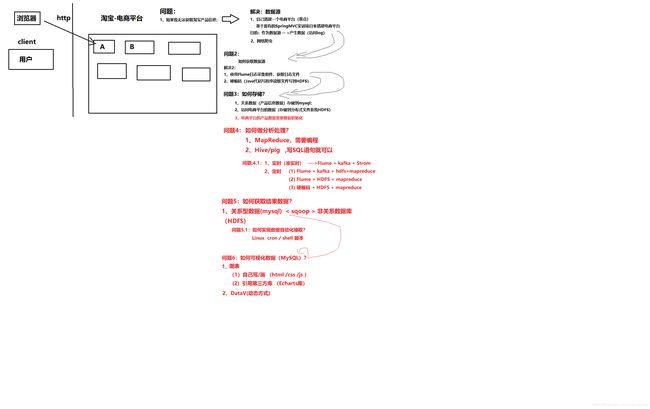
(*)注意:实训教室:6506
一、数据的采集
1、电商后台管理系统:Spring MVC就是后台管理系统
保证Spring MVC 实训项目运行起来
(*)eclipse 是否支持Java EE
(*)eclipse上是否已经配置Tomcat
(*)maven环境是否正常()
(*)需要手动打开MySQL命令行,在里面create database xxxxx;


2、电商网站(作为日志生产的地方) :
(1)使用HBuilder来开发编写商品首页index.html

(2)编写商品的详情页面
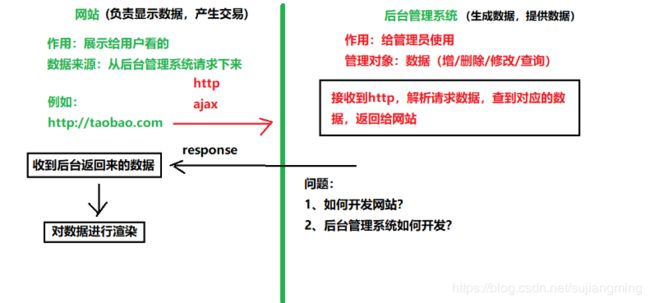
3、 电商网站和电商后台管理系统之间的关系

4、代码如何部署
(1)动静态分离部署介绍
静态资源---->HTML页面 -->Huilder编写 --->html/csss/js 复制到nginx的安装目录下,由nginx负责管理
动态资源---->动态资源 ---->eclipse 编写 ----> 打包成war ,部署到Tomcat中
好处:解耦,修改静态资源不会影响动态资源,反之,亦然。
(2)Nginx上部署静态资源即电商网站
1)Nginx是什么?
Nginx是一款轻量级的Web服务器、反向代理服务器,由于它的内存占用少,启动极快,
高并发能力强,在互联网项目中广泛应用。
下基本上说明了当下流行的技术架构,其中Nginx有点入口网关的味道。

(*)什么是正向代理?
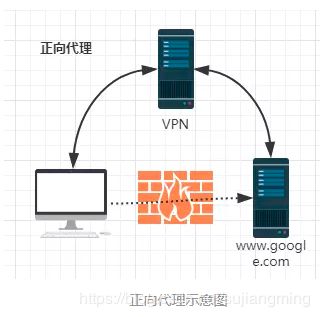
由于防火墙的原因,我们并不能直接访问谷歌,那么我们可以借助VPN来实现,
这就是一个简单的正向代理的例子。这里你能够发现,正向代理“代理”的是客户端,
而且客户端是知道目标的,而目标是不知道客户端是通过VPN访问的。
(*)什么是反向代理?
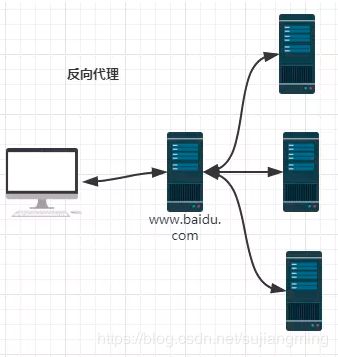
当我们在外网访问百度的时候,其实会进行一个转发,代理到内网去,这就是所谓的反向代理,
即反向代理“代理”的是服务器端,而且这一个过程对于客户端而言是透明的。
2)Nginx工作模式
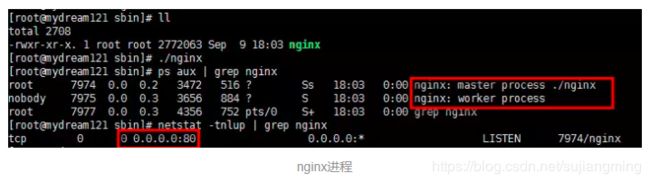
Nginx的Master-Worker模式

启动Nginx后,其实就是在80端口启动了Socket服务进行监听,如图所示,Nginx涉及Master进程和Worker进程。
3)Nginx如何使用?
a、window版本 (最新版本 nginx-1.15.12)
(*)解压运行
cd c:\
unzip nginx-1.15.12.zip
cd nginx-1.15.12
start nginx
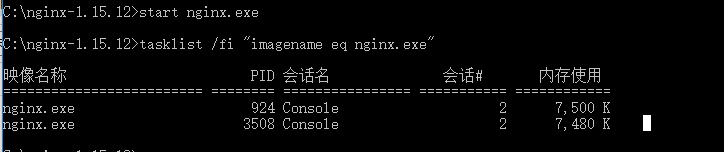
(*)查看进程
C:\nginx-1.15.12>tasklist /fi "imagename eq nginx.exe"
Image Name PID Session Name Session# Mem Usage
=============== ======== ============== ========== ============
nginx.exe 652 Console 0 2 780 K
nginx.exe 1332 Console 0 3 112 K
b、Linux版本
(注意:因我们虚拟机使用的是x86_64 64为的CentOS7操作系统作为服务器,需要使用源码编译方式)
(*)安装,编写nginx的脚本文件nginx_install.sh ,执行 vi nginx_install.sh,添加如下信息:
#!/bin/bash
yum install -y gcc
#install pcre
yum install -y pcre-static.x86_64
#install nginx
tar -zvxf /tools/nginx-1.15.12.tar.gz -C /training/
cd /training/nginx-1.15.12
./configure --prefix=/training/nginx --without-http_gzip_module
make && make install
#set .bash_profile
echo '#nginx' >> ~/.bash_profile
echo 'export PATH=$PATH:/training/nginx/sbin' >> ~/.bash_profile
source ~/.bash_profile
(*) 给nginx_install.sh赋予可执行的权限
chmod 774 nginx_install.sh
(*)编写启动nginx的脚本nginx_start.sh,执行 vi nginx_start.sh添加如下内容:
#!/bin/bash
cd /training/nginx/sbin
./nginx
(*)编写停止nginx脚本,执行vi nginx_stop.sh ,添加如下内容:
#!/bin/bash
cd /training/nginx/sbin
./nginx -s stop
(*)执行安装命令,并启动nginx,进入~目录下,即执行cd ~,然后执行 ./nginx_install.sh
./nginx_start.sh
(*)验证nginx是否启动成功:netstat -anop|grep nginx ,如下图所示即表示ok了
![]()
或者在window笔记本上,打开浏览器输入http://虚拟机的ip或者主机名,
例如我的虚拟机ip是:192.168.215.131,那么输入http://192.168.215.131,回车,如下图即成功

如果你已经配置了主机名和ip地址映射关系,则可以直接在浏览器里面输入主机名即可
2)上传电商网站OnlineShop文件夹到/training/nginx/html/目录下,将OnlineShop文件夹重命名为shop
使用 软件上传,在软件上面对OnlineShop文件夹重命名为shop或者使用如下命令重命名:
软件上传,在软件上面对OnlineShop文件夹重命名为shop或者使用如下命令重命名:
mv OnlineShop shop
3)修改nginx配置文件nginx.conf,执行vi /training/nginx/conf/nginx.conf,修改如下内容:


修改完毕,记得保存退出哈

3)部署电商网站到nginx下
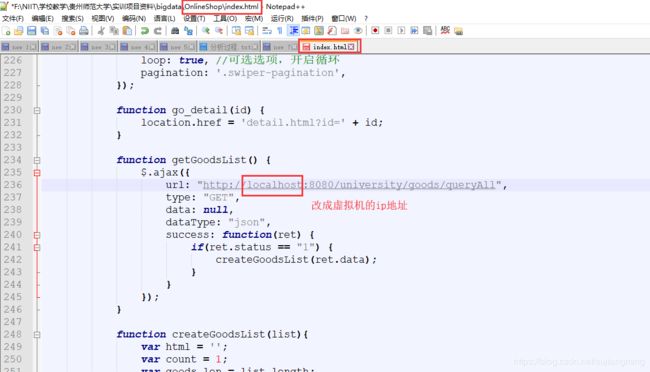
(*)进入到OnlineShop目录下,找到index.html,detail.html,将里面的localhost改成虚拟机的地址
(*)在window笔记本上,打开浏览器输入http://虚拟机的ip/shop/

(4)Tomcat的安装
(*)下载tomcat-8.5.40,到官网上下
(*)安装tomcat
1)、上传tomcat到/tools目录下
2)、解压:tar -zvxf apache-tomcat-8.5.40.tar.gz -C /training/
3)、配置环境变量 vi ~/.bash_profile
#tomcat
export PATH=$PATH:/training/apache-tomcat-8.5.40/bin
4)、生效:
source ~/.bash_profile
5)、启动
startup.sh
6)、验证,在浏览器输入: http://192.168.215.131:8080/
或者在命令行里面输入:netstat -anop|grep 8080 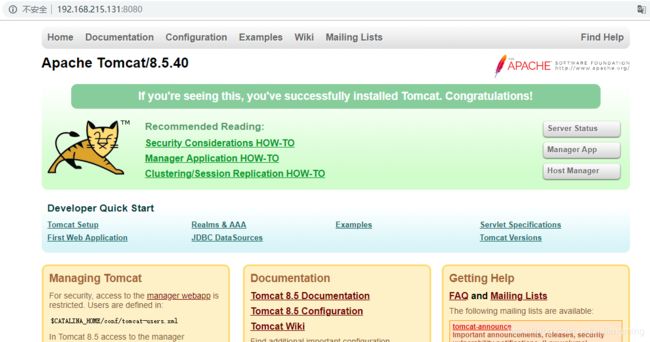
清空日志:
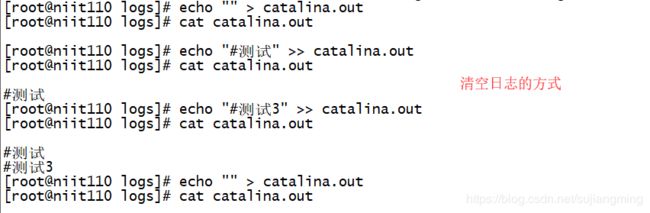
(5)部署电商后台管理系统(注意:虚拟机中安装有MySQL5.7)
(*)打开eclipse,找到你的university项目hibernate.properties
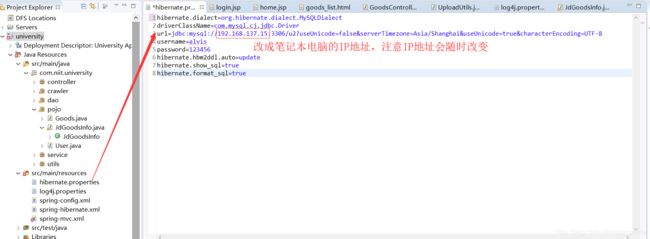
(*) 修改hibernate.properties文件,只需要修改url后面的localhost改成虚拟机的ip地址,如在虚拟机中输入ifconfig,找到如下红色框所示:

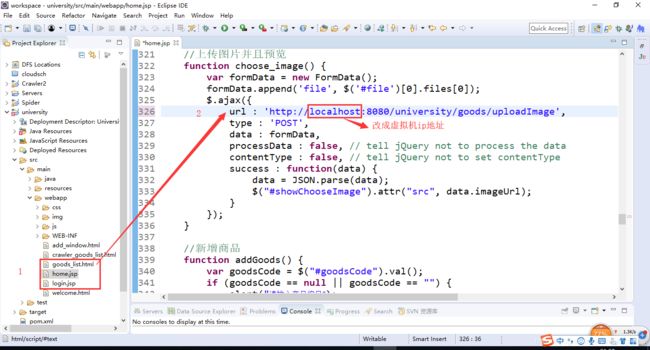
(*)在university项目下,找到home/login/university_list html页面,将里面的localhost改成你虚拟机的ip地址
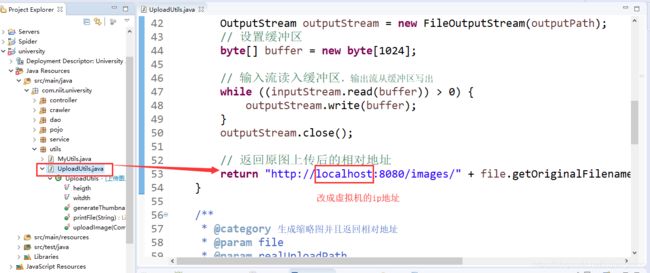
(*)在university项目下,找到UploadUtils.java类,把里面的localhost部分改成虚拟机的ip地址
(*)在eclipse中将代码打成war,并导出来

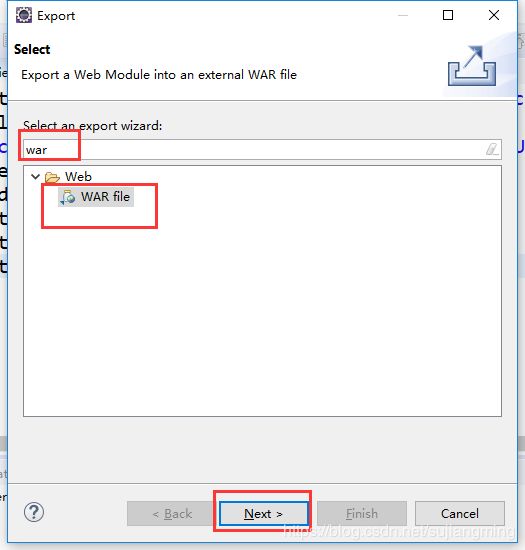
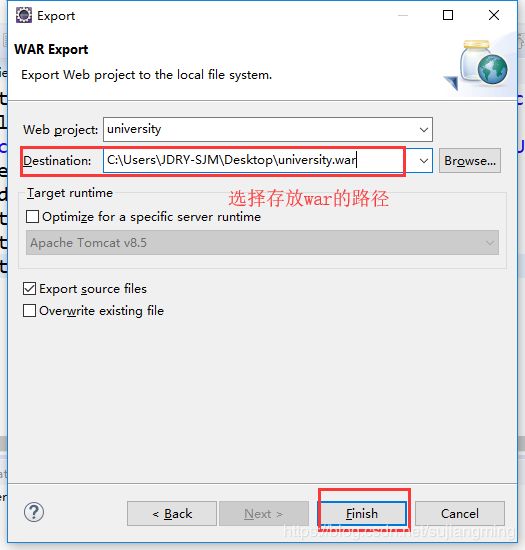
(*)将war包上传到/training/apache-tomcat-8.5.40/webapps目录下
(*)浏览器中访问:http://192.168.215.131:8080/university

5、解决Windows访问虚拟机Tomcat很慢以及后台系统无法登陆或者出现500错误的问题
修改步骤:
(1)、hibernate.properties
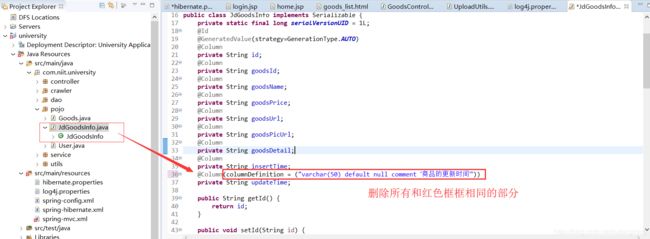
(2)、修改JdGoodsInfo.java
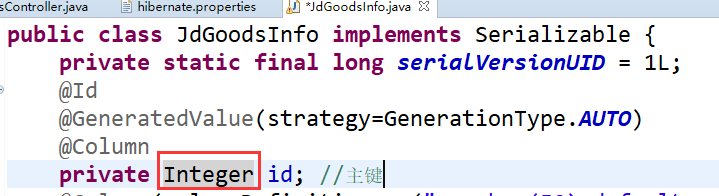
(3)、修改spring-hibernate.xml
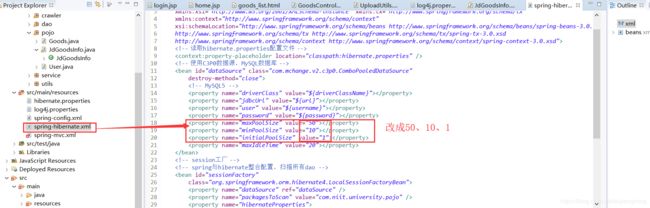
(4)、最重要的是修改MySQL8.0以上版本的数据库的权限
第一、在MySQL命令行里面,修改密码的加密方式
set @validate_password_mixed_case_count=0;
set @validate_password_number_count=3;
set @validate_password_special_char_count=0;
set @validate_password_length=3;
第二、在MySQL里面创建新的database,例如数据库名称为u2
create database u2;
第三、创建新的用户
create user 'alvis'@'%' identified by '123456';
第四、给新的用户授权
grant all privileges on u2.* to 'alvis'@'%';
flush privileges;
解决 MySQL 5.7 中 Your password does not satisfy the current policy requirements. 问题
1、set global validate_password_policy=0;
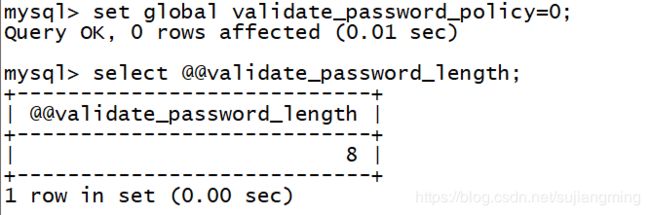
2、set global validate_password_length=1;
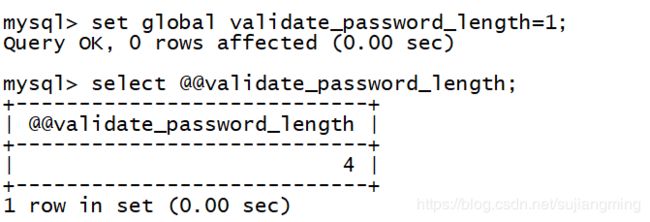
3、set global validate_password_mixed_case_count=2;

4、alter user 'root'@'localhost' identified by '123456';
下面是修改完成后的截图
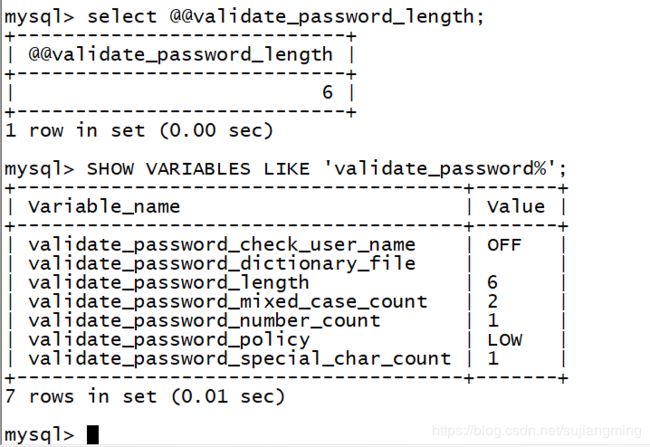
mysql> SHOW VARIABLES LIKE 'validate_password%';
+--------------------------------------+-------+
| Variable_name | Value |
+--------------------------------------+-------+
| validate_password_check_user_name | OFF |
| validate_password_dictionary_file | |
| validate_password_length | 6 |
| validate_password_mixed_case_count | 2 |
| validate_password_number_count | 1 |
| validate_password_policy | LOW |
| validate_password_special_char_count | 1 |
+--------------------------------------+-------+
7 rows in set (0.01 sec)
(5)、修改上传图片的路径,改成动态生成图片的方式
(*)部署上线时需要修改:GoodsController.java类里面的 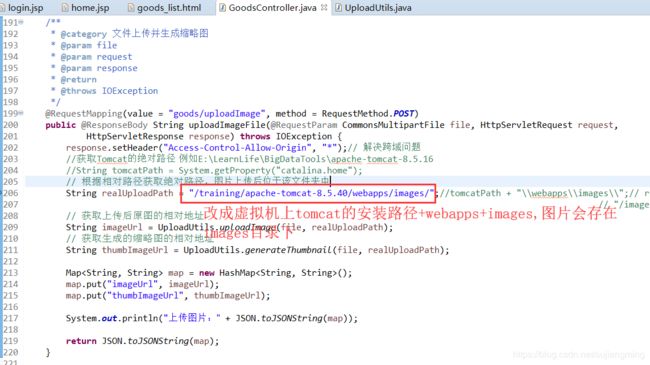

(6)、修改MySQL数据库默认的最大的连接数
(1)、如果你使用的是window中的MySQL,则修改my.ini
(该文件一般位于C:\ProgramData\MySQL\MySQL Server 8.0)

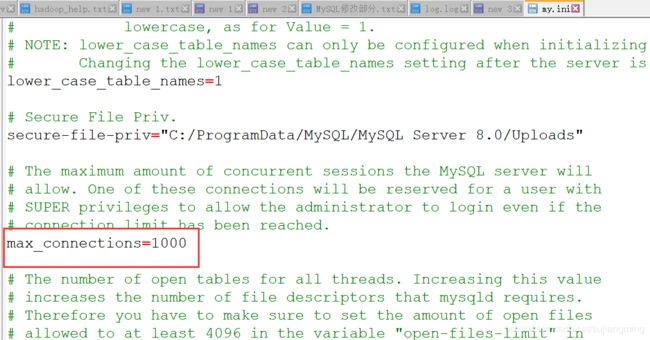
(2)、如果你使用的是Linux中的MySQL,则修改user表的中的最大连接数字段
在MySQL的命令行或Navicat中修改:
update user set max_connections=1000 where user = 'root';
6、AB压力测试,模拟生成用户访问日志数据
ab使用方式:
格式:ab [options] [http://]hostname[:port]/path
参数很多,一般我们用 -c 和 -n 参数就可以了
ab -n 1000 -c 100 https://www.baidu.com/ #注意这里最后的斜杠一定要加
-n 表示测试请求数目
-c 表示并发度
-t timelimit 测试时间限制,单位秒
-s timeout 每个请求时间限制,单位秒
-v verbosity 日志输出级别,可以选择1, 2等,调试使用
-T content-type POST/PUT接口的content-type
-p postfile POST请求发送的数据文件
安装方式:
(方式一)在Linux安装ab压测工具
安装:
yum install -y httpd
注意:因安装nginx它会占用80端口,所以我们需要修改:
修改ab默认的80端口为其他未被占用的端口
vi /etc/httpd/conf/httpd.conf
将Listen 80 ---->改成 Listen 81

#启动服务
systemctl enable httpd
systemctl start httpd
#查看状态
systemctl status httpd
httpd -v
编写脚本:注意以下实现了两种方式,任意选择其中一种即可
脚本编写方式1:使用(shuf -i 1-10000 -n 1)产生随机数的方式,vi ab_test.sh ,添加如下脚本内容:

脚本编写方式2:使用echo $RANDOM产生随机数的方式,vi ab_test.sh ,添加如下脚本内容:

(方式二)在window上安装ab压力测试工具
安装:
(1)下载ab压力测试工具,并解压到对应的目录
(2)安装
编写脚本:注意 需要在ab压力测试工具安装目录下,新建test.bat文件,添加如下内容:
方式一:固定请求数和并发数
@echo off
FOR /F %%i in (url.txt) do ab -n 10000 -c 100 %%i
Pause
方式二:随机请求数和固定并发数
@ECHO off
ECHO AB Start Test
SET /a _rand=(%RANDOM%*500/32768)+1
FOR /F %%i in (url.txt) do ab -n %_rand% -c 100 %%i
Pause
ECHO AB End Test
执行test.bat脚本,进行ab压测:

测试结果分析:

吞吐率(Requests per second),缩写RPS,是服务器并发处理能力的量化描述,单位是reqs/s,指的是某个并发用户数下单位时间内处理的请求数。某个并发用户数下 单位时间内能处理的最大的请求数,称之为最大吞吐率。
性能测试得到的最重要的指标就是QPS(Query per second),每秒查询率,qps相当于最大吞吐率。反映了接口的并发承受能力,也就是系统的峰值性能。如果对接口的调 用超过了这一限制,就要考虑提升硬件或者做一些优化了。
日志:

7、网络爬虫编写
请查看笔记名称为:网络爬虫:爬取京东本周热卖商品基本信息存入MySQL
注意事项:下图红色部分的需要修改成MySQL所在虚拟机的的用户名密码

部署后台管理系统出现问题的解决思路:
0、部署前确保项目上正常运行
1、检查数据库的连接地址是否是虚拟机中的地址
2、检查各种jsp/html页面的中的ajax部分的url地址是否是虚拟机的ip地址
3、检查虚拟机中MySQL数据库是否给予了当前你所使用的用户操作权限
4、检查虚拟机网络和宿主机网络是否相互ping通
5、检查虚拟机中MySQL的字符集是否是utf-8,不是则需要修改数据库的字符集
6、检查虚拟机中MySQL数据库中是否已经创建了university数据库,没有则需要手动创建
7、当你在虚拟机中部署了后台程序,需要到MySQL中修改t_jd_goods表的中goodsDetail字段的数据类型为text类型
8、检查虚拟机中mysql的数据库中的最大连接数是否是1000
9、针对500错误
(*)Chrome里面F12
(*)检查代码--定位到错误的地方
(*)确保你的请求路径正确
(*)检查数据库表的生成方式
pojo/User.java
pojo/Goods.java
pojo/JdGoods.java
(*)hibernate.properties
(*)查看MySQL的日志
/var/mysql/logs
报错:Access Deny "root@localhost" ---》权限问题
报错方式:"university.t_university_user" --->数据库不存在,事先需要创建
10、404问题
配置文件问题:
src/main/resources/
hibernate.properties --> #注释内容
spring-*.xml --->
maven依赖没有Deployment Assembly
项目有红色感叹号
问题原因是:
maven依赖有jar的missing ---> Project update 复选框勾选force
jdk:1.5 --->jdk1.8
tomcat-7 ---> 移除掉
二、数据的存储
1、安装Hadoop伪分布环境 (请参考我的博客)
(*)结构 --> 主从结构 -->NameNode --->DataNode
(*)Hadoop的分布式文件系统HDFS
(1)shell ----》 如何利用hadoop shell编写脚本
(2)Java api ---》编程HDFS 操作文件系统
(3)web console ---》管理页面,可视化的界面
(*)Hadoop分布式计算MapReduce
思想:大任务---》小任务
任务Task的编程:
Job = mapper + reducer
(*)预先分析日志处理流程
日志:


2、安装Flume日志采集组件
a)、安装
1).上传flume到/tools目录下
2).解压
tar -zvxf apache-flume-1.7.0-bin.tar.gz -C /training/
3).环境变量
export FLUME_HOME=/training/apache-flume-1.7.0-bin
export PATH=$PATH:$FLUME_HOME/bin
4).将hadoop-2.7.3安装路径下的依赖的jar导入到/apache-flume-1.7.0-bin/lib下:
share/hadoop/common/hadoop-common-2.7.3.jar
share/hadoop/common/lib/commons-configuration-1.6.jar
share/hadoop/common/lib/hadoop-auth-2.7.3.jar
share/hadoop/hdfs/hadoop-hdfs-2.7.3.jar
share/hadoop/common/lib/htrace-core-3.1.0-incubating.jar
share/hadoop/common/lib/common-io-2.4.jar
5)、验证
bin/flume-ng version
b)、配置Flume HDFS Sink:
在/training/apache-flume-1.7.0-bin/conf/新建一个flume-hdfs.conf
添加如下内容:
# define the agent
a1.sources=r1
a1.channels=c1
a1.sinks=k1
# define the source
#上传目录类型
a1.sources.r1.type=spooldir
a1.sources.r1.spoolDir=/training/nginx/logs/flumeLogs
#定义自滚动日志完成后的后缀名
a1.sources.r1.fileSuffix=.FINISHED
#根据每行文本内容的大小自定义最大长度4096=4k
a1.sources.r1.deserializer.maxLineLength=4096
# define the sink
a1.sinks.k1.type = hdfs
#上传的文件保存在hdfs的/flumeLogs目录下
a1.sinks.k1.hdfs.path = hdfs://niit110:9000/flumeLogs/%y-%m-%d/%H/%M/%S
a1.sinks.k1.hdfs.filePrefix=access_log
a1.sinks.k1.hdfs.fileSufix=.log
a1.sinks.k1.hdfs.batchSize=1000
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.writeFormat= Text
# roll 滚动规则:按照数据块128M大小来控制文件的写入,与滚动相关其他的都设置成0
#为了演示,这里设置成500k写入一次
a1.sinks.k1.hdfs.rollSize= 512000
a1.sinks.k1.hdfs.rollCount=0
a1.sinks.k1.hdfs.rollInteval=0
#控制生成目录的规则:一般是一天或者一周或者一个月一次,这里为了演示设置10秒
a1.sinks.k1.hdfs.round=true
a1.sinks.k1.hdfs.roundValue=10
a1.sinks.k1.hdfs.roundUnit= second
#是否使用本地时间
a1.sinks.k1.hdfs.useLocalTimeStamp=true
#define the channel
a1.channels.c1.type = memory
#自定义event的条数
a1.channels.c1.capacity = 500000
#flume事务控制所需要的缓存容量1000条event
a1.channels.c1.transactionCapacity = 1000
#source channel sink cooperation
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
注意:(*)需要先在/training/nginx/logs/创建flumeLogs
(*)需要在hdfs的根目录/下创建flumeLogs
c)、修改conf/flume-env.sh(该文件事先是不存在的,需要复制一份)
复制:
cp flume-env.template.sh flume-env.sh
设置JAVA_HOME:
export JAVA_HOME = /training/jdk-1.8.0.171
修改默认的内存:
export JAVA_OPTS="-Xms1024m -Xmx1024m -Xss256k -Xmn2g -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:-UseGCOverheadLimit"
c)、启动flume
(1)测试数据:把 /training/nginx/logs/access.log 复制到
/training/nginx/logs/flumeLogs/access_201904251200.log
(2)、启动
在/training/apache-flume-1.7.0-bin目录下,执行如下命令进行启动:
bin/flume-ng agent --conf ./conf/ -f ./conf/flume-hdfs.conf --name a1 -Dflume.root.logger=INFO,console
(3)、到Hadoop的控制台http://niit110:50070
/flumeLogs 查看有没有数据
3、编写Linux脚本,实现/training/nginx/logs/access.log日志的自动滚动到flumeLogs目录下
a)、在~目录下新建rollingLog.sh,并添加如下内容:
#!/bin/bash
#定义日期格式
dataformat=`date +%Y-%m-%d-%H-%M`
#复制access.log并重命名
cp /training/nginx/logs/access.log /training/nginx/logs/access_$dataformat.log
host=`hostname`
sed -i 's/^/'${host}',&/g' /training/nginx/logs/access_$dataformat.log
#统计日志文件行数
lines=`wc -l < /training/nginx/logs/access_$dataformat.log`
#将格式化的日志移动到flumeLogs目录下
mv /training/nginx/logs/access_$dataformat.log /training/nginx/logs/flumeLogs
#清空access.log的内容
sed -i '1,'${lines}'d' /training/nginx/logs/access.log
#重启nginx , 否则 log can not roll.
kill -USR1 `cat /training/nginx/logs/nginx.pid`
b)、
4、测试
5、安装Sqoop数据转换组件 (请参考我的笔记)
三、数据的分析处理
(*)、MapReduce的编程分析

(*)、MapReduce的编程演示
1、创建Java工程
2、导入Hadoop的依赖包
3、写代码
4、运行
命令:hadoop jar log.jar /flumeLogs/19-04-26/00/29/50/* /output/flume01/
输入:
输出:

四、数据的可视化
(*)sqoop的安装与配置
(*)sqoop的基本操作
1、从hdfs中将数据(MR结果数据)导入到MySQL中
1)、在MySQL中新建一张表t_result,用于存放MapReduce分析结果
2)、在虚拟机中执行导入命令
sqoop export --connect jdbc:mysql://192.168.215.131:3306/university --username root --password 123456 --input-fields-terminated-by '\t' --table t_mr_result --export-dir /output/flume01

2、将MySQL的数据在后台管理系统中展现出来(需要编程)
1)编写一个页面 ,用来展示分析的结果信息
(*)用 echart来实现数据可视化
(*)echarts操作方式
1) 到官网上下载echarts.min.js
2)将echarts.min.js引入到工程中
3)初始化myChart,添加option
2)编写Java代码:Spring MVC
五、集成测试
(*)流程的梳理
压测->爬虫->flume采集日志->HDFS存储->MapReduce分析->sqoop将结果数据导出-->MySQL-->编程实现数据库可视化
详细的流程:
采用MapReduce来分析access.log
1、将acces.log采集到HDFS分布式文件系统上 --->Flume日志采集组件
2、编写MapReduce程序对access.log进行分析 --->Hadoop安装配置
3、将MR分析的结果数据导出到MySQL中进行存储 --->sqoop组件
4、编写可视化的页面以及逻辑代码 (部署在tomcat)
5、实现整个系统的集成测试
1)手动执行压测数据,执行脚本ab_test.sh
2)滚动日志文件rollFlume.sh (flumeLogs)
3)MapReduce程序运行(hadoop jar xxxx /input/ /output/ )脚本:mr.sh
4) sqoop导出数据到mysql的脚本 sqoop_to_mysql.sh
6、测试上线
(*)流程整合
目的:基于Spring MVC 使用Hadoop stack 分析电商日志系统
即分析电商日志access.log,将结果显示在后台关系系统中
内容:电商网站 + 后台管理系统(包括网络爬虫) + 大数据分析处理 + 大数据可视化
步骤:
0、电商网站的演示
风格-主题
1、后台管理系统的演示
管理界面-思路-编码
2、网络爬虫的演示
数据初始化
3、数据准备------》商品的具体页面
该步骤需要通过Java代码编程将MySQL中t_goods表查询出所有商品,
并组装成具体的商品详情页面
http://192.168.215.131/shop/detail.html?id=402857036a2748ed016a274bf4180002
http://192.168.215.131/shop/detail.html?id=402857036a2748ed016a274bf4180002
http://192.168.215.131/shop/detail.html?id=402857036a2831e0016a28a87e980000
http://192.168.215.131/shop/detail.html?id=402857036a50d33d016a50eb334b0000
http://192.168.215.131/shop/detail.html?id=402857036a50d33d016a50ed0af70001
http://192.168.215.131/shop/detail.html?id=402857036a554aac016a554cdbd30000
http://192.168.215.131/shop/detail.html?id=402857036a554aac016a554db88f0001
4、数据生成 ---》生成access.log日志,
如何生成?
---通过ab压测 --->模拟大量的用户访问商品详情页面 --> 增加access.log
该步骤需要执行一个脚本:
ab_test.sh
5、数据采集
将/training/nginx/logs/access.log 滚动到
/training/nginx/logs/flumeLogs/下
该步骤需要执行一个脚本:
rollingLog.sh
6、数据分析
402857036a2748ed016a274bf4180002 3335
402857036a2831e0016a28a87e980000 8553
402857036a50d33d016a50eb334b0000 5571
402857036a50d33d016a50ed0af70001 6340
402857036a554aac016a554cdbd30000 1960
402857036a554aac016a554db88f0001 4092
该步骤需要执行一个脚本:
exec_mr.sh
7、数据处理
将mr分析的结果通过sqoop导出到MySQL表(t_mr_result)
sqoop_to_mysql.sh
8、数据可视化
将MySQL中的结果数据通过echart图表展示出来
讲解如何通过Java程序控制Linux上的脚本
1、思路:模拟用户通过SSH2协议登录到Linux服务器中
2、步骤:
1)明确执行脚本的方式
例如:
sh /root/ab_test.sh
2)写Java代码
(1)添加maven依赖
(2)写RemoteExecuteCommand.java
package com.niit.university.utils;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.io.UnsupportedEncodingException;
import org.apache.commons.lang.StringUtils;
import ch.ethz.ssh2.Connection;
import ch.ethz.ssh2.Session;
import ch.ethz.ssh2.StreamGobbler;
/**
* @category 远程执行linux的shell script
*
* @author JDRY-SJM
*/
public class RemoteExecuteCommand {
// 字符编码默认是utf-8
private static String DEFAULTCHART = "UTF-8";
private Connection conn;
private String ip;
private String userName;
private String userPwd;
public static volatile RemoteExecuteCommand instance;
private RemoteExecuteCommand() {
this.ip = "192.168.215.131";
this.userName = "root";
this.userPwd = "subenjiang";
}
public static RemoteExecuteCommand getInstance() {
if (instance == null) {
synchronized (RemoteExecuteCommand.class) {
if (instance == null) {
instance = new RemoteExecuteCommand();
}
}
}
return instance;
}
/**
* @category 远程登录linux的主机
*
* @author JDRY-SJM
* @since V0.1
* @return 登录成功返回true,否则返回false
*/
public Boolean login() {
boolean flg = false;
try {
conn = new Connection(ip);
conn.connect();// 连接
flg = conn.authenticateWithPassword(userName, userPwd);// 认证
} catch (IOException e) {
e.printStackTrace();
}
return flg;
}
/**
* @category 远程执行shll脚本或者命令
* @param cmd 即将执行的命令
* @return 命令执行完后返回的结果值
* @since V0.1
*/
public String execute(String cmd) {
String result = "";
try {
if (login()) {
Session session = conn.openSession();// 打开一个会话
session.execCommand(cmd);// 执行命令
result = processStdout(session.getStdout(), DEFAULTCHART);
// 如果为得到标准输出为空,说明脚本执行出错了
if (StringUtils.isBlank(result)) {
result = processStdout(session.getStderr(), DEFAULTCHART);
}
conn.close();
session.close();
}
} catch (IOException e) {
e.printStackTrace();
}
return result;
}
/**
* @category 远程执行shell脚本或者命令
* @param cmd 即将执行的命令
* @return 命令执行成功后返回的结果值,如果命令执行失败,返回空字符串,不是null
* @since V0.1
*/
public String executeSuccess(String cmd) {
String result = "";
try {
if (login()) {
Session session = conn.openSession();// 打开一个会话
session.execCommand(cmd);// 执行命令
result = processStdout(session.getStdout(), DEFAULTCHART);
conn.close();
session.close();
}
} catch (IOException e) {
e.printStackTrace();
}
return result;
}
/**
* @category 解析脚本执行返回的结果集
* @author JDRY-SJM
* @param in 输入流对象
* @param charset 编码
* @since V0.1
* @return 以纯文本的格式返回
*/
private String processStdout(InputStream in, String charset) {
InputStream stdout = new StreamGobbler(in);
StringBuffer buffer = new StringBuffer();
;
try {
BufferedReader br = new BufferedReader(new InputStreamReader(stdout, charset));
String line = null;
while ((line = br.readLine()) != null) {
buffer.append(line + "\n");
}
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
return buffer.toString();
}
public static void setCharset(String charset) {
DEFAULTCHART = charset;
}
public Connection getConn() {
return conn;
}
public void setConn(Connection conn) {
this.conn = conn;
}
public String getIp() {
return ip;
}
public void setIp(String ip) {
this.ip = ip;
}
public String getUserName() {
return userName;
}
public void setUserName(String userName) {
this.userName = userName;
}
public String getUserPwd() {
return userPwd;
}
public void setUserPwd(String userPwd) {
this.userPwd = userPwd;
}
}
3)测试
写测试用例
package university;
import com.niit.university.utils.RemoteExecuteCommand;
public class Main {
public static void main(String[] args) {
execShellScript();
}
public static void execShellCmd() {
RemoteExecuteCommand rec = RemoteExecuteCommand.getInstance();
String reString = rec.execute("ls -al /root/");
System.out.println(reString);
}
public static void execShellScript() {
RemoteExecuteCommand rec = RemoteExecuteCommand.getInstance();
String reString = rec.execute("sh /root/ab_test.sh");
System.out.println(reString);
}
}
4)添加到真正需要使用的地方(controller)
/**
* @category 查询所有的商品
* @param request
* @param response
* @return
*/
@RequestMapping("goods/initABTestData")
public @ResponseBody String initABTestData(HttpServletRequest request, HttpServletResponse response) {
response.setHeader("Access-Control-Allow-Origin", "*");// 解决跨域问题
// 1、执行查询操作,即将MySQL数据库中商品查询出来
List
// 2、组装结果数据返回给页面
Map
if (list == null || list.size() == 0) {
result.put("message", "目前还没有任何商品,请先添加商品");
result.put("status", "0");
return JSON.toJSONString(result);
}
String str = "";
for (Goods goods : list) {
// 192.168.215.131这个虚拟机上的ip地址
str += "http://192.168.215.131/shop/detail.html?id=" + goods.getId() + "\n";
}
System.out.println(str);
FileWriter writer;
try {
writer = new FileWriter("/root/url.txt");
writer.write(str);
writer.flush();
writer.close();
} catch (IOException e) {
e.printStackTrace();
}
result.put("message", "查询成功");
result.put("status", "1");
result.put("data", list);
return JSON.toJSONString(result);
}
/**
* @category AB压测生成用户访问数据
* @param request
* @param response
* @return
*/
@RequestMapping("goods/dataGeneration")
public @ResponseBody String dataGeneration(HttpServletRequest request, HttpServletResponse response) {
// 1、构造返回前端页面的map对象
Map
// 2、使用SSH2登录远程Linux服务器,执行shell脚本
String execResultStr = RemoteExecuteCommand.getInstance().execute("sh /root/ab_test.sh");
if (!"".equals(execResultStr)) {
map.put("message", "生成用户访问数据成功~");
map.put("status", "1");
map.put("data", execResultStr);
return JSON.toJSONString(map);
}
map.put("message", "生成用户访问数据失败~");
map.put("status", "0");
map.put("data", "生成用户访问数据失败~");
return JSON.toJSONString(map);
}
/**
* @category 数据的采集即用户访问日志被滚动到FlumeLogs目录下
* @param request
* @param response
* @return
*/
@RequestMapping("goods/dataAcquisition")
public @ResponseBody String dataAcquisition(HttpServletRequest request, HttpServletResponse response) {
// 1、构造返回前端页面的map对象
Map
// 2、使用SSH2登录远程Linux服务器,执行shell脚本
String execResultStr = RemoteExecuteCommand.getInstance().executeSuccess("sh /root/rollingLog.sh");
if (!"".equals(execResultStr)) {
map.put("message", "数据采集成功~");
map.put("status", "1");
map.put("data", execResultStr);
return JSON.toJSONString(map);
}
map.put("message", "数据采集失败~");
map.put("status", "0");
map.put("data", "数据采集失败~");
return JSON.toJSONString(map);
}
/**
* @category Flume实现数据存储到HDFS
* @param request
* @param response
* @return
*/
@RequestMapping("goods/dataStorage")
public @ResponseBody String dataStorage(HttpServletRequest request, HttpServletResponse response) {
// 1、构造返回前端页面的map对象
Map
// 2、使用SSH2登录远程Linux服务器,执行shell脚本
String execResultStr = RemoteExecuteCommand.getInstance().executeSuccess("sh /root/flume_to_hdfs.sh");
if (!"".equals(execResultStr)) {
map.put("message", "数据存储成功~");
map.put("status", "1");
map.put("data", execResultStr);
return JSON.toJSONString(map);
}
map.put("message", "数据存储失败~");
map.put("status", "0");
map.put("data", "数据存储失败~");
return JSON.toJSONString(map);
}
/**
* @category 数据的分析即执行MapReduce程序
* @param request
* @param response
* @return
*/
@RequestMapping("goods/dataAnalysis")
public @ResponseBody String dataAnalysis(@RequestParam Map
//0、获取需要的分析的是HDFS哪一个目录下的数据
String path = param.get("path");
//1、拿到前端输入的HDFS的路径写入到Linux下mr_input_path.txt文件中
FileWriter writer;
try {
writer = new FileWriter("/root/mr_input_path.txt");
writer.write(path);
writer.flush();
writer.close();
} catch (IOException e) {
e.printStackTrace();
}
// 3、使用SSH2登录远程Linux服务器,执行shell脚本
String execResultStr = RemoteExecuteCommand.getInstance().executeSuccess("sh /root/exec_mr.sh");
// 4、构造返回前端页面的map对象
Map
if (!"".equals(execResultStr)) {
map.put("message", "数据分析成功~");
map.put("status", "1");
map.put("data", execResultStr);
return JSON.toJSONString(map);
}
map.put("message", "数据分析失败~");
map.put("status", "0");
map.put("data", "数据分析失败~");
return JSON.toJSONString(map);
}
/**
* @category 将MapReduce程序分析结果抽取到MySQL中
* @param request
* @param response
* @return
*/
@RequestMapping("goods/dataSqoop")
public @ResponseBody String dataSqoop(@RequestParam Map
//0、获取需要的分析的是HDFS哪一个目录下的数据
String path = param.get("path");
//1、拿到前端输入的HDFS的路径写入到Linux下result_path.txt文件中
FileWriter writer;
try {
writer = new FileWriter("/root/result_path.txt");
writer.write(path);
writer.flush();
writer.close();
} catch (IOException e) {
e.printStackTrace();
}
// 3、使用SSH2登录远程Linux服务器,执行shell脚本
String execResultStr = RemoteExecuteCommand.getInstance().executeSuccess("sh /root/sqoop_to_mysql.sh");
// 4、构造返回前端页面的map对象
Map
if (!"".equals(execResultStr)) {
map.put("message", "结果数据抽取成功~");
map.put("status", "1");
map.put("data", execResultStr);
return JSON.toJSONString(map);
}
map.put("message", "结果数据抽取失败~");
map.put("status", "0");
map.put("data", "结果数据抽取失败~");
return JSON.toJSONString(map);
}
5)脚本内容
(*)ab_test.sh
##开始
#(shuf -i 1-10000 -n 1) > requests.log
#(shuf -i 1-500 -n 1) > concurrent.log
for i in $(cat url.txt) ##循环读取url.txt中的地址
do
(shuf -i 1-10000 -n 1) > requests.log
(shuf -i 1-500 -n 1) > concurrent.log
##将测试的结果写入到test_ab.log
ab -n $(cat requests.log) -c $(cat concurrent.log) $i ###>> test_ab.log &
done
#结束
(*)rollingLog.sh
#!/bin/bash
#定义日期格式
dataformat=`date +%Y-%m-%d-%H-%M-%S`
#复制access.log并重命名
cp /training/nginx/logs/access.log /training/nginx/logs/access_$dataformat.log
host=`hostname`
sed -i 's/^/'${host}',&/g' /training/nginx/logs/access_$dataformat.log
#统计日志文件行数
lines=`wc -l < /training/nginx/logs/access_$dataformat.log`
#将格式化的日志移动到flumeLogs目录下
mv /training/nginx/logs/access_$dataformat.log /training/nginx/logs/flumeLogs
#清空access.log的内容
sed -i '1,'${lines}'d' /training/nginx/logs/access.log
#重启nginx , 否则 log can not roll.
kill -USR1 `cat /training/nginx/logs/nginx.pid`
##返回给服务器信息
ls -al /training/nginx/logs/flumeLogs/
(*)flume_start.sh
#!/bin/bash
/training/apache-flume-1.7.0-bin/bin/flume-ng agent -c /training/apache-flume-1.7.0-bin/conf/ -f /training/apache-flume-1.7.0-bin/conf/flume-hdfs.conf -n a1 -Dflume.root.logger=INFO,console
(*)flume_stop.sh
#!/bin/bash
JAR="flume"
#停止flume函数
echo "begin stop flume process.."
num=`ps -ef|grep java|grep $JAR|wc -l`
echo "当前已经启动的flume进程数:$num"
if [ "$num" != "0" ];then
#正常停止flume
ps -ef|grep java|grep $JAR|awk '{print $2;}'|xargs kill
echo "进程已经关闭..."
else
echo "服务未启动,无须停止..."
fi
(*)flume_to_hdfs.sh
#!/bin/bash
#先停止正在启动的flume
./flume_stop.sh
#用法:nohup ./start-dishi.sh >output 2>&1 &
nohup ./flume_start.sh > nohup_output.log 2>&1 &
echo "启动flume成功……"
(*)exec_mr.sh
#执行MapReduce程序
dataformat=`date +%Y-%m-%d-%H-%M-%S`
/training/hadoop-2.7.3/bin/hadoop jar log.jar $(cat mr_input_path.txt) /output/result/$dataformat
/training/hadoop-2.7.3/bin/hdfs dfs -cat /output/result/$dataformat/part-r-00000 > mr_result.txt
echo $(cat mr_result.txt)
(*)sqoop_to_mysql.sh
#!/bin/bash
/training/sqoop-1.4.6/bin/sqoop export \
--connect jdbc:mysql://192.168.215.131:3306/university \
--username root \
--password 123456 \
--input-fields-terminated-by '\t' \
--table t_mr_result \
--export-dir $(cat result_path.txt)
(*)如果你使用flume没有将数据存储到HDFS分布式文件系统上,请改写flume_to_hdfs.sh 脚本进行存储
写入如下内容:
#!/bin/bash
#先停止正在启动的flume
#./flume_stop.sh
#用法:nohup ./start-dishi.sh >output 2>&1 &
#nohup ./flume_start.sh > nohup_output.log 2>&1 &
#echo "启动flume成功……"
#提示信息
echo "开始上传文件到HDFS分布式文件系统……"
dataformat=`date +%Y-%m-%d-%H-%M-%S`
echo $dataformat
/training/hadoop-2.7.3/bin/hdfs dfs -mkdir /flumeLogs/$dataformat
/training/hadoop-2.7.3/bin/hdfs dfs -put /training/nginx/logs/flumeLogs/*.log /flumeLogs/$dataformat/
echo "结束上传文件到HDFS分布式文件系统……"
rm -rf /training/nginx/logs/flumeLogs/*
/training/hadoop-2.7.3/bin/hdfs dfs -lsr /flumeLogs/
六、项目要求
1、后台管理页面不能我的一样
2、网站界面的不能使用界面风格
3、爬虫可以使用京东的网站
4、nginx、tomcat、flume、sqoop、hadoop各自作用
5、重点突出Hadoop内容
6、重点突出大数据采集、存储、分析处理、可视化的过程
7、各类脚本及命令知晓
七、开源的爬虫项目
网站: http://www.geccocrawler.com/tag/sysc/
GitHub: https://github.com/xtuhcy/gecco