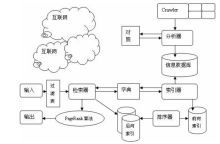
编辑本段工作原理
搜索引擎的基本工作原理包括如下三个过程:首先在互联网中发现、搜集网页信息;同时对信息进行提取和组织建立索引库;再由检索器根据用户输入的查询关键字,在索引库中快速检出文档,进行文档与查询的相关度评价,对将要输出的结果进行排序,并将查询结果返回给用户。
1、抓取网页。每个独立的搜索引擎都有自己的网页抓取程序(spider)。Spider顺着网页中的超链接,连续地抓取网页。被抓取的网页被称之为网页快照。由于互联网中超链接的应用很普遍,理论上,从一定范围的网页出发,就能搜集到绝大多数的网页。
2、处理网页。搜索引擎抓到网页后,还要做大量的预处理工作,才能提供检索服务。其中,最重要的就是提取关键词,建立索引库和索引。其他还包括去除重复网页、分词(中文)、判断网页类型、分析超链接、计算网页的重要度/丰富度等。
3、提供检索服务。用户输入关键词进行检索,搜索引擎从索引数据库中找到匹配该关键词的网页;为了用户便于判断,除了网页标题和URL外,还会提供一段来自网页的摘要以及其他信息。
编辑本段全文搜索引擎
在搜索引擎分类部分我们提到过 全文搜索引擎从网站提取信息建立网页数据库的概念。搜索引擎的自动信息搜集功能分两种。一种是定期搜索,即每隔一段时间(比如Google一般是28天),搜索引擎主动派出“蜘蛛”程序,对一定IP地址范围内的互联网站进行检索,一旦发现新的网站,它会自动提取网站的信息和网址加入自己的数据库。
另一种是提交网站搜索,即网站拥有者主动向搜索引擎提交网址,它在一定时间内(2天到数月不等)定向向你的网站派出“蜘蛛”程序,扫描你的网站并将有关信息存入数据库,以备用户查询。由于近年来搜索引擎索引规则发生了很大变化,主动提交网址并不保证你的网站能进入搜索引擎数据库,因此目前最好的办法是多获得一些外部链接,让搜索引擎有更多机会找到你并自动将你的网站收录。
当用户以关键词查找信息时,搜索引擎会在数据库中进行搜寻,如果找到与用户要求内容相符的网站,便采用特殊的算法——通常根据网页中关键词的匹配程度,出现的位置、频次,链接质量等——计算出各网页的相关度及排名等级,然后根据关联度高低,按顺序将这些网页链接返回给用户。
编辑本段目录索引
与全文搜索引擎相比,目录索引有许多不同之处。
首先,搜索引擎属于自动网站检索,而目录索引则完全依赖手工操作。用户提交网站后,目录编辑人员会亲自浏览你的网站,然后根据一套自定的评判标准甚至编辑人员的主观印象,决定是否接纳你的网站。
其次, 搜索引擎收录网站时,只要网站本身没有违反有关的规则,一般都能登录成功。而目录索引对网站的要求则高得多,有时即使登录多次也不一定成功。尤其象Yahoo!这样的超级索引,登录更是困难。(由于登录Yahoo!的难度最大,而它又是商家网络营销必争之地,所以我们会在后面用专门的篇幅介绍登录Yahoo雅虎的技巧)
此外,在登录搜索引擎时,我们一般不用考虑网站的分类问题,而登录目录索引时则必须将网站放在一个最合适的目录(Directory)。
最后,搜索引擎中各网站的有关信息都是从用户网页中自动提取的,所以用户的角度看,我们拥有更多的自主权;而目录索引则要求必须手工另外填写网站信息,而且还有各种各样的限制。更有甚者,如果工作人员认为你提交网站的目录、网站信息不合适,他可以随时对其进行调整,当然事先是不会和你商量的。
目录索引,顾名思义就是将网站分门别类地存放在相应的目录中,因此用户在查询信息时,可选择关键词搜索,也可按分类目录逐层查找。如以关键词搜索,返回的结果跟搜索引擎一样,也是根据信息关联程度排列网站,只不过其中人为因素要多一些。如果按分层目录查找,某一目录中网站的排名则是由标题字母的先后顺序决定(也有例外)。
目前,搜索引擎与目录索引有相互融合渗透的趋势。原来一些纯粹的全文搜索引擎现在也提供目录搜索,如Google就借用Open Directory目录提供分类查询。而象 Yahoo! 这些老牌目录索引则通过与Google等搜索引擎合作扩大搜索范围(注),在默认搜索模式下,一些目录类搜索引擎首先返回的是自己目录中匹配的网站,如国内搜狐、新浪、网易等;而另外一些则默认的是网页搜索,如Yahoo。
新竞争力通过对搜索引擎营销的规律深入研究认为: 搜索引擎推广是基于网站内容的推广——这就是搜索引擎营销的核心思想。这句话说起来很简单,如果仔细分析会发现,这句话的确包含了搜索引擎推广的一般规律。本文作者在“网站推广策略之内容推广思想漫谈”一文中提出一个观点:“网站内容不仅是大型ICP网站的生命源泉,对于企业网站网络营销的效果同样是至关重要的”。因为网站内容本身也是一种有效的网站推广手段,只是这种推广需要借助于搜索引擎这个信息检索工具,因此网站内容推广策略实际上也就是搜索引擎推广策略的具体应用。
编辑本段百度与谷歌算法区别
查询处理以及分词技术
随着搜索经济的崛起,人们开始越加关注全球各大搜索引擎的性能、技术和日流量。作为企业,会根据搜索引擎的知名度以及日流量来选择是否要投放广告等;作为普通网民,会根据搜索引擎的性能和技术来选择自己喜欢的引擎查找资料;作为技术人员,会把有代表性的搜索引擎作为研究对象。搜索引擎经济的崛起,又一次向人们证明了网络所蕴藏的巨大商机。网络离开了搜索将只剩下空洞杂乱的数据,以及大量等待去费力挖掘的金矿。
但是,如何设计一个高效的搜索引擎?我们可以以百度所采取的技术手段来探讨如何设计一个实用的搜索引擎。搜索引擎涉及到许多技术点,比如查询处理,排序算法,页面抓取算法,CACHE机制,ANTI-SPAM等等。这些技术细节,作为商业公司的搜索引擎服务提供商比如百度,GOOGLE等是不会公之于众的。我们可以将现有的搜索引擎看作一个黑盒,通过向黑盒提交输入,判断黑盒返回的输出大致判断黑盒里面不为人知的技术细节。
查询处理与分词是一个中文搜索引擎必不可少的工作,而百度作为一个典型的中文搜索引擎一直强调其“中文处理”方面具有其它搜索引擎所不具有的关键技术和优势。那么我们就来看看百度到底采用了哪些所谓的核心技术。
我们分两个部分来讲述:查询处理/中文分词。
一、查询处理
用户向搜索引擎提交查询,搜索引擎一般在接受到用户查询后要做一些处理,然后在索引数据库里面提取相关的信息。那么百度在接受到用户查询后做了些什么工作呢?
1、假设用户提交了不只一个查询串,比如“信息检索 理论 工具”。那么搜索引擎首先做的是根据分隔符比如空格,标点符号,将查询串分割成若干子查询串,比如上面的查询就会被解析为:三个子字符串;这个道理简单,我们接着往下看。
2、假设提交的查询有重复的内容,搜索引擎怎么处理呢?比如查询“理论工具理论”,百度是将重复的字符串当作只出现过一次,也就是处理成等价的“理论工具”,而GOOGLE显然是没有进行归并,而是将重复查询子串的权重增大进行处理。那么是如何得出这个结论的呢?我们可以将“理论工具”提交给百度,返回341,000篇文档,大致看看第一页的返回内容。
OK。继续,我们提交给GOOGLE查询“理论工具理论”,在看看返回结果,仍然是那么多返回文档,当然这个不能说明太多问题,那看看第一页返回结果的排序,看出来了吗?顺序完全没有变化,而 GOOGLE 则排序有些变动,这说明百度是将重复的查询归并成一个处理的,而且字符串之间的先后出现顺序基本不予考虑(GOOGLE是考虑了这个顺序关系的)。
3、假设提交的中文查询包含英文单词,搜索引擎是怎么处理的?比如查询”电影BT下载”,百度的方法是将中文字符串中的英文当作一个整体保留,并以此为断点将中文切分开,这样上述的查询就切为,不论中间的英文是否一个字典里能查到的单词也好,还是随机的字符也好,都会当作一个整体来对待。至于为什么,你用查询 “电影dfdfdf下载”看看结果就知道了。当然如果查询中包含数字,也是如此办理。