何恺明 PointRend:Image Segmentation as Rendering 论文解析,代码开源
精彩内容
FAIR(何恺明新作) PointRend:将图像分割视为渲染(Rendering) 《PointRend: Image Segmentation as Rendering》 作者(豪华)团队:Facebook人工智能实验室(Alexander Kirillov/吴育昕/何恺明/RossGirshick)。
原文公号链接:AI深度视线
传送门:
https://github.com/facebookresearch/detectron2/tree/master/projects/PointRend
1引言

摘要:我们提出了一种新的方法,可以对物体和场景进行有效的高质量图像分割。通过将经典的计算机图形方法模拟为有效渲染,同时像素标注任务面临着过采样和欠采样的挑战,我们开发了图像分割作为渲染问题的独特视角。从这个角度出发,我们提出了PointRend(基于点的渲染)神经网络模块:该模块基于迭代细分算法在自适应选择的位置执行基于点的分割预测。通过在现有最新模型的基础上构建,PointRend可以灵活地应用于实例和语义分割任务。尽管可以实现该总体思想的许多具体实现,但我们表明,简单的设计已经可以实现出色的结果。定性地,PointRend在先前方法过度平滑的区域中输出清晰的对象边界。从数量上讲,无论是实例还是语义分割,PointRend都在COCO和Cityscapes上产生了有效的性能提升。
先来一组和Mask-RCNN的效果对比感受一下:
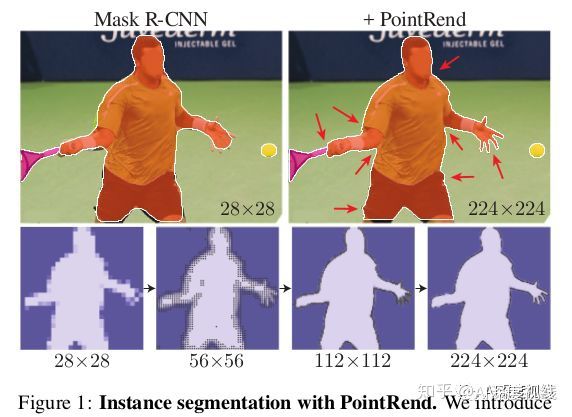

2主要思路
将计算机视觉中(对象和/或场景的)图像分割模拟为计算机图形学中的图像渲染(Rendering)。在计算机视觉中,我们可以把图像分割看作是一个连续实体的占用图,而分割是从预测标签的规则网格中“渲染”出来。该实体编码在网络的特征映射中,可以通过插值在任意点进行访问。一个参数化的函数,通过这些内插的逐点特征表示被训练来预测占用率。
PointRend模块接受一个或多个C通道数的定义在规则网格上的典型CNN特征图,规格网络大小通常是4或16倍像素大小,而输出不同分辨率的规格网格下K个类别的标签预测。对于实例分割,PointRend将应用于每个区域。它通过对一组选定点进行预测来以从粗到精的方式计算Mask。对于语义分割,可以将整个图像视为一个区域来处理。具体过程如下图所示。
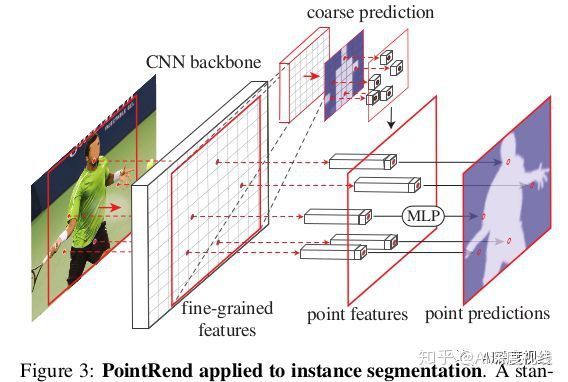
一个PointRend模块包括三部分。
1.point selection strategy:用于inference和traing的点选择
该方法的核心思想是灵活自适应地选择图像平面上的点来预测分割标签。直观地说,这些点应该更密集地位于高频区域附近,例如物体边界,类似于射线追踪中的反混叠问题。我们产生了推理和训练的想法。
- inference推理
通过仅在与其邻域有显著不同的位置进行计算,该方法可用于有效地渲染高分辨率图像(例如,通过光线跟踪)。对于所有其他位置,通过对已经计算的输出值(从粗网格开始)进行插值来获得值。
对于每个区域,我们以粗到精的方式迭代地“渲染”输出蒙版。在规则网格上的点上进行最粗糙级别的预测(例如,通过使用标准的粗糙分段预测头)。在每次迭代中,PointRend使用双线性插值对其先前预测的分段进行上采样,然后在此较密集的网格上选择N个最不确定的点(例如,对于二进制掩码,概率最接近0.5的那些)。然后,PointRend为这N个点中的每一个点计算特征,并预测它们的标签。重复该过程,直到将分段上采样到所需的分辨率为止。

- training
在训练过程中,PointRend还需要选择一些点,以在这些点上构建用于训练point head的逐点(point-wise)特征。原则上,点选择策略可以类似于推理inference中使用的细分策略。但是,细分引入了一系列步骤,这些步骤对于通过反向传播训练神经网络不太友好。取而代之的是,为了训练,我们使用基于随机采样的非迭代策略。
采样策略在特征图上选择N个点进行训练。它旨在使用三个原理将选择偏向不确定区域,同时还保留一定程度的均匀覆盖。对于训练和推理选择,N的值可以不同。
(i)过度生成:我们通过从均匀分布中随机采样kN个点(k> 1)来过度生成候选点。(ii)重要抽样:通过对所有kN个点的粗略预测值进行插值并计算任务特定的不确定性估计,我们将重点放在具有粗略预测的点上。从kN个候选中选择最不确定的βN个点(β∈[0,1])。(iii)覆盖范围:从均匀分布中采样剩余的(1-β)N点。我们用不同的设置来说明此过程,并将其与常规的网格选择进行比较,如下图所示。
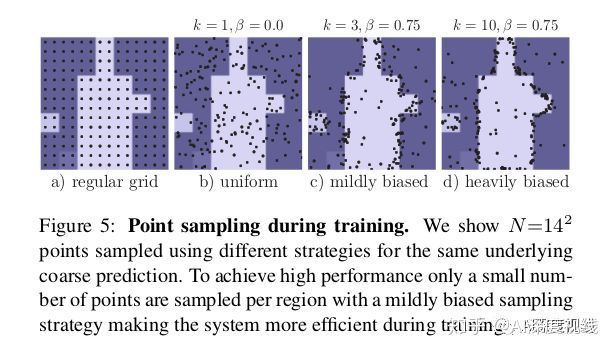
在训练时,预测和损失函数仅在N个采样点上计算(除粗略分割外),这比通过细分步骤进行反向传播更简单,更有效。这种设计类似于在Faster R-CNN系统中对RPN + Fast R-CNN的并行训练,其推理是顺序的。
2. Point-wise Representation:逐点表示
PointRend通过组合(例如,级联)两种特征类型(细粒度和粗略预测特征)在选定点上构造逐点特征,如下所述。
- 细粒度特征
为了允许PointRend呈现精细的分割细节,我们从CNN特征图中提取每个采样点的特征向量。 因为一个点是“实值2D坐标”,所以我们按照标准做法对特征图执行双线性插值,以计算特征向量。 可以从单个特征图中提取特征(例如,ResNet中的res2);也可以按照Hypercolumn方法,从多个特征图(例如res2到res5)中提取并连接它们。
- 粗预测特征
细粒度的特征可以解析细节,但在两个方面也有不足:
首先,它们不包含特定区域的信息,因此,两个实例的边界框重叠的相同点将具有相同的细粒度特征。但是,该点只能位于一个实例之中。 因此,对于实例分割的任务,其中不同的区域可能针对同一点预测不同的标签,因此需要其他区域特定的信息。
其次,取决于用于细粒度特征的特征图,这些特征可能只包含相对较低级别的信息(例如,我们将对res2使用DeepLabV3)。 因此,需要有更多具有上下文和语义信息的特征。
基于这两点考虑,第二种特征类型是来自网络的粗分割预测,例如表示k类预测的区域(box)中每个点的k维向量。通过设计,粗分辨率能够提了更加全局的上下文信息,而通道则传递语义类别。这些粗略的预测与现有架构的输出相似,并且在训练过程中以与现有模型相同的方式进行监督。例如,在mask R-CNN中,粗预测可以是一个轻量级的7×7分辨率Mask头的输出。
3. point head
给定每个选定点的逐点特征表示,PointRend使用简单的多层感知器(MLP)进行逐点分割预测。这个MLP在所有点(和所有区域)上共享权重,类似于图卷积或PointNet。由于MLP会预测每个点的分割标签,因此可以通过特定任务的分割loss进行训练。
3实验结果
- 网络设计
实验使用ResNet-50+ FPN 的Mask-Rcnn作backbone。 Mask-RCNN中的默认head是region-wise FCN,用“ 4×conv”表示,作为用来与本文网络进行比较的基准网络。
为了计算粗略预测,我们用重量更轻的设计替换4×conv Mask头,该设计类似于Mask R-CNN的box head产生7×7Mask预测。具体来说,对于每个边界框,我们使用双线性插值从FPN的P2层提取14×14特征图。这些特征是在边界框内的规则网格上计算的(此操作可以看作是RoIAlign的简单版本)。接下来,我们使用具有256个输出通道步幅为2的 2×2卷积层,后跟ReLU, 将空间大小减小到7×7。最后,类似于Mask R-CNN的box head,用两个带1024宽的隐藏层的MLP为K类分别产生7×7的Mask预测。ReLU用于MLP的隐藏层,并且Sigmoid激活函数应用于输出。
PointRend:在每个选定点上,使用双线性插值从粗预测头的输出中提取K维特征向量,PointRend还从FPN的P2级别插值256维特征向量,步长为4。这些粗预测和细粒度特征向量是串联在一起的,我们使用具有256个通道的3个隐藏层的MLP在选定点进行K类别预测。在MLP的每个层中,我们用K个粗预测特征补充到256个输出通道中,作为下一层输入向量。在MLP中使用ReLU,并将Sigmoid激活函数应用于输出。
- 实验结果(秀肌肉)
与Mask-Rcnn对比:

不同输出分辨率及计算量:

PointRend反混叠:

大模型、长时训练:

实例分割和语义分割:

