1.集群安装 - apache原生版[spark2.1 + hadoop2.6 + scala2.11.8 + jdk1.8 + flume1.6 + zookeeper3.4.9 + kafka0.
主要架构
1.flume采集(实现文件采集,并对文件的断点续采,采集崩溃能够接着最后一次索引继续采集)
2.kafka数据接入,flume将采集的数据,传给kafka
3.spark streaming 实时消费,并且要与kafka实现消费高可用,消费数据无丢失,重启程序后消费数据不重复(主要实现spark手动控制kafka消费偏移量,将消费偏移量单独存至外部,来保证计算的高可用)
4.计算结果落地hdfs或者插入数据库(暂时未定)
主要功能实现
1.flume文件采集数据不丢失,断点续采,根据崩溃时的索引,重启程序后能继续采集
2.spark streaming 消费kafka 实现数据零丢失,避免kafka重复消费,spark streaming 手动控制 kafka消费偏移量,将消费偏移量存到zookeeper,来保证消费高可用
第一步 准备工作
1.1 准备安装包
这里使用的是apache原版,在apache官网都能下载到(顺便羡慕一下可以用CM CDH的)
可以事先将这些文件分发到各个服务器,这一步之前肯定要先配置好免key

1.2 配置环境变量
vim /etc/profile
# new config [ scala 2.11.8 + jdk 1.8 + spark 2.1 + hadoop 2.6 + flume 1.6 + zookeeper 3.4.9 + kafka 0.10.2.0 ]
export SCALA_HOME=/home/hadoop1/softs/scala-2.11.8
export JAVA_HOME=/home/hadoop1/softs/jdk-1.8.0_92
export JAVA_LIBRARY_PATH=$HADOOP_HOME/lib/native
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export SPARK_HOME=/home/hadoop1/softs/spark-2.1.0-bin-hadoop2.6
export ZOOKEEPER_HOME=/home/hadoop1/softs/zookeeper-3.4.9
export FLUME_HOME=/home/hadoop1/softs/flume-1.6.0
export KAFKA_HOME=/home/hadoop1/softs/kafka-2.11-0.10.2.0
export HADOOP_HOME=/home/hadoop1/softs/hadoop-2.6.0
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_CMD=$HADOOP_HOME/bin/hadoop
export PATH=$JAVA_HOME/bin: ${SCALA_HOME}/bin:$SPARK_HOME/bin:$SPARK_HOME/sbin:$ZOOKEEPER_HOME/bin:$KAFKA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$FLUME_HOME/bin:$PATH
第二步 安装zookeeper
2.1 修改zookeeper 配置
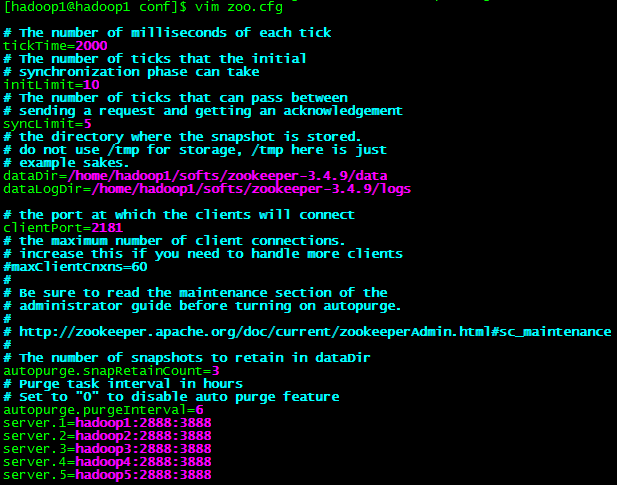
2.2 将修改后的配置文件分发到各个机器

2.3 常见问题id文件不存在

手动创建一个
![]()
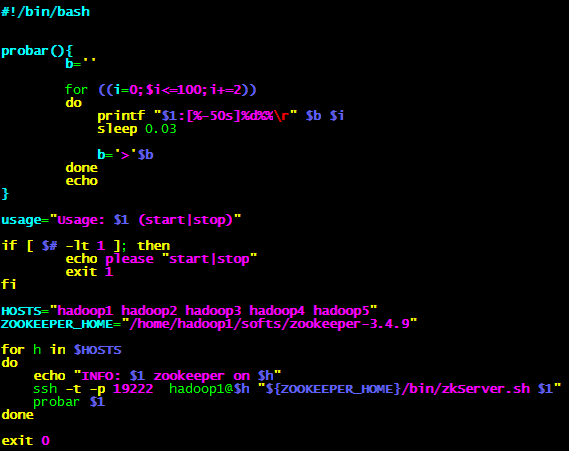
2.4 启动 停止脚本
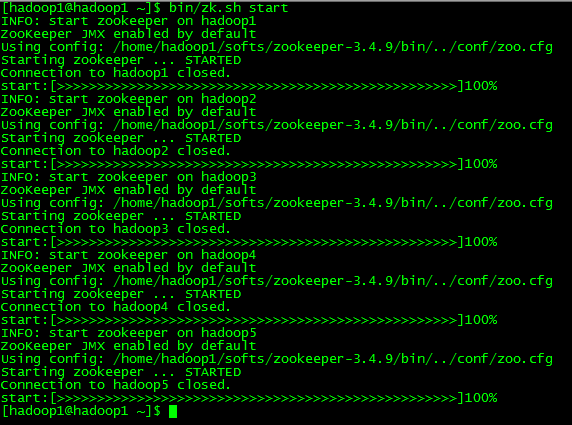
2.5 测试启动
第三步 安装hadoop(hdfs, yarn, ha)
主要是修改几个xml,这个地方因为参数过多,稍有地方写错就会启动不了
Xml文件全在 $HADOOP_HOME/etc/hadoop
3.1 修改hadoop-env.sh配置文件
添加如下信息
export JAVA_HOME=/home/hadoop1/softs/jdk-1.8.0_92
export HADOOP_SSH_OPTS="-p 19222"
export HADOOP_NAMENODE_OPTS=-Xmx2048m
3.2 修改 core-site.xml 配置文件
3.3 修改 hdfs-site.xml 配置文件
3.4 修改mapred-site.xml 配置文件
3.5 修改yarn-site.xml 配置文件
3.6 修改slaves 配置文件
hadoop1
hadoop2
hadoop3
hadoop4
hadoop5
3.7 把修改后的文件分发给各个机器
把修改后的文件分发到其他机器
[hadoop1@hadoop1 softs]$ scp -r hadoop-2.6.0/ hadoop1@hadoop2:/home/hadoop1/softs/ > /dev/null
[hadoop1@hadoop1 softs]$ scp -r hadoop-2.6.0/ hadoop1@hadoop3:/home/hadoop1/softs/ > /dev/null
[hadoop1@hadoop1 softs]$ scp -r hadoop-2.6.0/ hadoop1@hadoop4:/home/hadoop1/softs/ > /dev/null
[hadoop1@hadoop1 softs]$ scp -r hadoop-2.6.0/ hadoop1@hadoop5:/home/hadoop1/softs/ > /dev/null
3.8 格式化 zkfc


3.9 检查ha信息,可以在zookeeper中查看到

3.10 启动 journalname
在hadoop1 hadoop2上启动
[hadoop1@hadoop1 ~]$ hadoop-daemon.sh start journalnode
starting journalnode, logging to /home/hadoop1/softs/hadoop-2.6.0/logs/hadoop-hadoop1-journalnode-hadoop1.out
[hadoop1@hadoop2 hadoop-2.6.0]$ hadoop-daemon.sh start journalnode
starting journalnode, logging to /home/hadoop1/softs/hadoop-2.6.0/logs/hadoop-hadoop1-journalnode-hadoop2.out
3.11 检查进程
[hadoop1@hadoop1 ~]$ jps
31994 JournalNode
30491 QuorumPeerMain
32045 Jps
[hadoop1@hadoop2 hadoop-2.6.0]$ jps
27927 JournalNode
27594 QuorumPeerMain
27978 Jps
3.12 在hadoop1上格式化hdfs
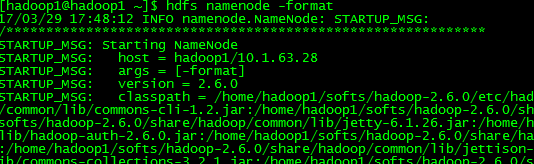

将格式化后master1节点hadoop工作目录中的元数据目录复制到master2节点

初始化完毕后可关闭journalnode(分别在hadoop1,hadoop2上执行)
hadoop-daemon.sh stop journalnode
第四步 启动&停止hadoop
4.1 在hadoop1(master1)启动hdfs

4.2 检查2个nn
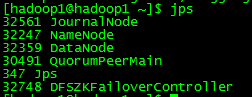
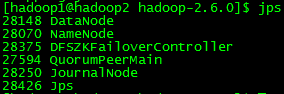
4.3 在hadoop2(master2) 启动yarn

4.4 启动YARN的另一个ResourceManager(在master1执行,用于容灾)
yarn-daemon.sh start resourcemanager
4.5 启动YARN的安全代理(在master2执行)
yarn-daemon.sh start proxyserver
4.6 启动YARN的历史任务服务(在master1执行)
mr-jobhistory-daemon.sh start historyserver
4.7 测试hadoop基本命令

4.8 总结hadoop 启动停止
启动部分
1.启动hdfs
[hadoop1@hadoop1 hadoop]$ start-dfs.sh
Starting namenodes on [hadoop1 hadoop2]
hadoop1: starting namenode, logging to /home/hadoop1/softs/hadoop-2.6.0/logs/hadoop-hadoop1-namenode-hadoop1.out
hadoop2: starting namenode, logging to /home/hadoop1/softs/hadoop-2.6.0/logs/hadoop-hadoop1-namenode-hadoop2.out
hadoop1: starting datanode, logging to /home/hadoop1/softs/hadoop-2.6.0/logs/hadoop-hadoop1-datanode-hadoop1.out
hadoop4: starting datanode, logging to /home/hadoop1/softs/hadoop-2.6.0/logs/hadoop-hadoop1-datanode-hadoop4.out
hadoop5: starting datanode, logging to /home/hadoop1/softs/hadoop-2.6.0/logs/hadoop-hadoop1-datanode-hadoop5.out
hadoop2: starting datanode, logging to /home/hadoop1/softs/hadoop-2.6.0/logs/hadoop-hadoop1-datanode-hadoop2.out
hadoop3: starting datanode, logging to /home/hadoop1/softs/hadoop-2.6.0/logs/hadoop-hadoop1-datanode-hadoop3.out
Starting journal nodes [hadoop1 hadoop2 hadoop5]
hadoop5: starting journalnode, logging to /home/hadoop1/softs/hadoop-2.6.0/logs/hadoop-hadoop1-journalnode-hadoop5.out
hadoop2: starting journalnode, logging to /home/hadoop1/softs/hadoop-2.6.0/logs/hadoop-hadoop1-journalnode-hadoop2.out
hadoop1: starting journalnode, logging to /home/hadoop1/softs/hadoop-2.6.0/logs/hadoop-hadoop1-journalnode-hadoop1.out
Starting ZK Failover Controllers on NN hosts [hadoop1 hadoop2]
hadoop2: starting zkfc, logging to /home/hadoop1/softs/hadoop-2.6.0/logs/hadoop-hadoop1-zkfc-hadoop2.out
hadoop1: starting zkfc, logging to /home/hadoop1/softs/hadoop-2.6.0/logs/hadoop-hadoop1-zkfc-hadoop1.out
2.启动yarn
[hadoop1@hadoop2 ~]$ start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /home/hadoop1/softs/hadoop-2.6.0/logs/yarn-hadoop1-resourcemanager-hadoop2.out
hadoop4: starting nodemanager, logging to /home/hadoop1/softs/hadoop-2.6.0/logs/yarn-hadoop1-nodemanager-hadoop4.out
hadoop1: starting nodemanager, logging to /home/hadoop1/softs/hadoop-2.6.0/logs/yarn-hadoop1-nodemanager-hadoop1.out
hadoop3: starting nodemanager, logging to /home/hadoop1/softs/hadoop-2.6.0/logs/yarn-hadoop1-nodemanager-hadoop3.out
hadoop5: starting nodemanager, logging to /home/hadoop1/softs/hadoop-2.6.0/logs/yarn-hadoop1-nodemanager-hadoop5.out
hadoop2: starting nodemanager, logging to /home/hadoop1/softs/hadoop-2.6.0/logs/yarn-hadoop1-nodemanager-hadoop2.out
启动另一个,保证高可用
[hadoop1@hadoop1 hadoop]$ yarn-daemon.sh start resourcemanager
starting resourcemanager, logging to /home/hadoop1/softs/hadoop-2.6.0/logs/yarn-hadoop1-resourcemanager-hadoop1.out
3.启动yarn的安全代理
[hadoop1@hadoop2 ~]$ yarn-daemon.sh start proxyserver
starting proxyserver, logging to /home/hadoop1/softs/hadoop-2.6.0/logs/yarn-hadoop1-proxyserver-hadoop2.out
4.启动yarn的历史任务服务
[hadoop1@hadoop1 hadoop]$ mr-jobhistory-daemon.sh start historyserver
starting historyserver, logging to /home/hadoop1/softs/hadoop-2.6.0/logs/mapred-hadoop1-historyserver-hadoop1.out
停止部分
1.停止hdfs
[hadoop1@hadoop1 hadoop]$ stop-dfs.sh
17/03/30 09:45:49 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Stopping namenodes on [hadoop1 hadoop2]
hadoop1: stopping namenode
hadoop2: stopping namenode
hadoop4: stopping datanode
hadoop3: stopping datanode
hadoop5: stopping datanode
hadoop1: stopping datanode
hadoop2: stopping datanode
Stopping journal nodes [hadoop1 hadoop2]
hadoop2: stopping journalnode
hadoop1: stopping journalnode
17/03/30 09:46:10 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Stopping ZK Failover Controllers on NN hosts [hadoop1 hadoop2]
hadoop2: stopping zkfc
hadoop1: stopping zkfc
2.停止yarn
[hadoop1@hadoop1 hadoop]$ stop-yarn.sh
stopping yarn daemons
stopping resourcemanager
hadoop4: stopping nodemanager
hadoop1: stopping nodemanager
hadoop2: stopping nodemanager
hadoop5: stopping nodemanager
hadoop3: stopping nodemanager
no proxyserver to stop
3.另外一边ha的也要停
[hadoop1@hadoop2 softs]$ yarn-daemon.sh stop resourcemanager && yarn-daemon.sh stop proxyserver
stopping resourcemanager
stopping proxyserver
4.停yarn的历史服务器
[hadoop1@hadoop1 hadoop]$ mr-jobhistory-daemon.sh stop historyserver
stopping historyserver
第五步 安装spark
主要修改 $SPARK_HOME/conf 中的配置文件
5.1 修改 spark-env.sh 配置文件
export JAVA_HOME=/home/hadoop1/softs/jdk-1.8.0_92
export SCALA_HOME=/home/hadoop1/softs/scala-2.11.8
export HADOOP_HOME=/home/hadoop1/softs/hadoop-2.6.0
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export SPARK_SSH_OPTS="-p 19222"
export SPARK_EXECUTOR_MEMORY=2g
export SPARK_DRIVER_MEMORY=2g
export SPARK_WORKER_CORES=2
export SPARK_WORKER_MEMORY=2g
export SPARK_DAEMON_MEMORY=1g
export SPARK_MASTER_WEBUI_PORT=58080
export SPARK_WORKER_WEBUI_PORT=58081
5.2 修改 slaves 配置文件
hadoop1
hadoop2
hadoop3
hadoop4
hadoop5
5.3 分发给各机器
[hadoop1@hadoop1 softs]$ scp -r spark-2.1.0-bin-hadoop2.6/ hadoop1@hadoop2:/home/hadoop1/softs/ > /dev/null
[hadoop1@hadoop1 softs]$ scp -r spark-2.1.0-bin-hadoop2.6/ hadoop1@hadoop3:/home/hadoop1/softs/ > /dev/null
[hadoop1@hadoop1 softs]$ scp -r spark-2.1.0-bin-hadoop2.6/ hadoop1@hadoop4:/home/hadoop1/softs/ > /dev/null
[hadoop1@hadoop1 softs]$ scp -r spark-2.1.0-bin-hadoop2.6/ hadoop1@hadoop5:/home/hadoop1/softs/ > /dev/null
5.4 启动spark
想要哪台机器当master就在哪台机器的sbin中执行脚本
$SPARK_HOME/sbin/start-all.sh
5.5 测试spark
能出这些基本算正常了,spark安装完毕
该方法是不使用ha的,想用ha,在另外一台想当备用master机器上启动$SPARK_HOME/sbin/start-master.sh
[hadoop1@hadoop4 conf]$ spark-shell
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
17/04/05 10:45:51 WARN metastore.ObjectStore: Version information not found in metastore. hive.metastore.schema.verification is not enabled so recording the schema version 1.2.0
17/04/05 10:45:51 WARN metastore.ObjectStore: Failed to get database default, returning NoSuchObjectException
17/04/05 10:45:54 WARN metastore.ObjectStore: Failed to get database global_temp, returning NoSuchObjectException
Spark context Web UI available at http://10.1.63.39:4040
Spark context available as 'sc' (master = local[*], app id = local-1491360341020).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.1.0
/_/
Using Scala version 2.11.8 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_92)
Type in expressions to have them evaluated.
Type :help for more information.
第六步 安装kafka
6.1 修改配置文件
因为每个id不同的原因,这里建议挨个修改配置文件
kafka主要是修改 $KAFKA_HOME/conf/server.properties 配置文件
需要改的地方,在还不需要调优阶段,就三个
主要是id的修改,在集群中它是唯一的,我这边是有5台机器,那我的id就是
hadoop1 => broker.id=1
hadoop2 => broker.id=2
hadoop3 => broker.id=3
hadoop4 => broker.id=4
hadoop5 => broker.id=5
其他配置参照以下
# id,不能重复,集群中唯一
broker.id=1
# kafka文件存储位置
log.dirs=/home/hadoop1/softs/kafka-2.11-0.10.2.0/kafka-logs
# zookeeper地址,有多个的话,半角逗号分隔
zookeeper.connect=hadoop1:2181,hadoop2:2181,hadoop3:2181,hadoop4:2181,hadoop5:2181
6.2 启动kafka
以这种方式启动kafka应用后,kafka总会莫名其妙的退出。不过我目前是以这种启动的,先凑合用了
kafka-server-start.sh $KAFKA_HOME/config/server.properties &
后来改为这种命令启动:解决了问题
kafka-server-start.sh -daemon $KAFKA_HOME/config/server.properties
启动成功会有以下字样,这里是每台服务器都需要执行
[2017-04-11 17:47:15,797] INFO Result of znode creation is: OK (kafka.utils.ZKCheckedEphemeral)
[2017-04-11 17:47:15,799] INFO Registered broker 4 at path /brokers/ids/4 with addresses: EndPoint(hadoop4,9092,ListenerName(PLAINTEXT),PLAINTEXT) (kafka.utils.ZkUtils)
[2017-04-11 17:47:15,819] INFO Kafka version : 0.10.2.0 (org.apache.kafka.common.utils.AppInfoParser)
[2017-04-11 17:47:15,819] INFO Kafka commitId : 576d93a8dc0cf421 (org.apache.kafka.common.utils.AppInfoParser)
[2017-04-11 17:47:15,821] INFO [Kafka Server 4], started (kafka.server.KafkaServer)
第七步 安装flume
其实flume是属于,要在哪采集,就安装在哪
目前我这的需求有两种
socket采集 文件采集
socket采集可以实现远程采集
文件采集必须在被采集中安装flume程序(或者还有什么远程文件采集的套路,欢迎斧正)
这里主要实现了flume文件断点续采,flume文件采集数据不丢失,采集高可用
作者: https://github.com/ningg/flume-ng-extends-source
7.1 修改配置文件
$FLUME_HOME/conf/ flume-env.sh
flume的安装配置很简单,只需要修一个配置即可
添加JAVA_HOME地址
JAVA_HOME=/home/hadoop1/softs/jdk-1.8.0_92
验证一下

flume安装成功
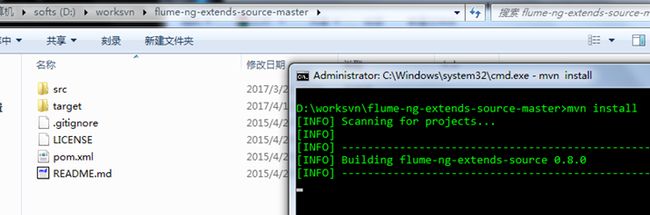
7.2 编译插件
作者是在flume1.5下开发的
我这边亲测flume1.6可以使用
安装flume文件断点续采,flume文件采集数据不丢失 插件
下载工程https://codeload.github.com/ningg/flume-ng-extends-source/zip/master
我用的maven,同样也可以打包(作者好像用的sbt)
7.3 安装插件
我反正下面两步都做了
方法一:标准插件安装 (Recommended Approach),具体步骤:
在${FLUME_HOME}找到目录plugins.d,如果没有找到这一目录,则创建目录${FLUME_HOME}/plugins.d;
在${FLUME_HOME}/plugins.d目录下,创建目录flume-ng-extends-source,并在其下创建lib和libext两个子目录;
将flume-ng-extends-source-x.x.x.jar复制到plugins.d/flume-ng-extends-source/lib目录中;
至此,安装插件后,目录结构如下:
${FLUME_HOME}
|-- plugins.d
|-- flume-ng-extends-source/lib
|-- lib
|-- flume-ng-extends-source-x.x.x.jar
|-- libext
方法二:快速插件安装 (Quick and Dirty Approach),具体步骤:
将flume-ng-extends-source-x.x.x.jar复制到${FLUME_HOME}/lib目录中
7.4 修改配置文件
我这边的需求是flume去采集文件中的日志
实现小时级别的采集
实现断点续采,采集程序挂了,能接着上次采集的索引继续采集
实现采集自动更新,例如2017041118点生成了文件并进行采集,当时间过到19点,目录中生成了2017041119时,采集程序会自动对它进行采集
(本来像在采集阶段实现一次ETL,我记得flume中有个拦截器的功能,但是在这配置了之后感觉貌似不管用,我暂时将过滤的工作放在spark的计算前去做了)
a1.sources = r1
a1.sinks = k1
a1.channels = c1
a1.sources.r1.type = com.github.ningg.flume.source.SpoolDirectoryTailFileSource
a1.sources.r1.spoolDir = /home/hadoop1/testdata/ #采集目录
a1.sources.r1.fileSuffix = .COMPLETED #采集完成的文件,自动加上后缀
a1.sources.r1.deletePolicy = never
a1.sources.r1.ignorePattern = ^$
a1.sources.r1.targetPattern = .*(\\d){4}(\\d){2}(\\d){2}(\\d){2}.* #被采集文件的正则匹配
a1.sources.r1.targetFilename = yyyyMMddHH #支持的时间格式,也支持天级别
a1.sources.r1.trackerDir = .flumespooltail
a1.sources.r1.consumeOrder = oldest
a1.sources.r1.batchSize = 100
a1.sources.r1.inputCharset = UTF-8
a1.sources.r1.decodeErrorPolicy = REPLACE
a1.sources.r1.deserializer = LINE
a1.sinks.k1.type = null #这个地方配置成null,会过滤掉运行的数据INFO信息,运行的INFO还会保留
a1.channels.c1.type = org.apache.flume.channel.kafka.KafkaChannel
a1.channels.c1.capacity = 10000
a1.channels.c1.transactionCapacity = 1000
a1.channels.c1.brokerList = hadoop1:9092,hadoop2:9092,hadoop3:9092,hadoop4:9092,hadoop5:9092
a1.channels.c1.topic = filetest10
a1.channels.c1.zookeeperConnect = hadoop1:2181,hadoop2:2181,hadoop3:2181,hadoop4:2181,hadoop5:2181
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1