Pandas DataFrame合并concat、merge,分组GroupBy
合并
1、concat合并
先创建两个dataFrame
import pandas as pd
import numpy as np
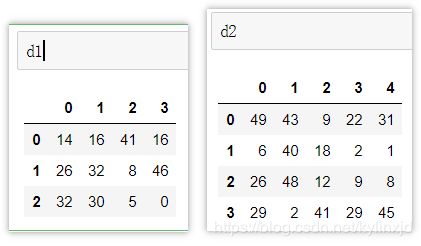
d1 = pd.DataFrame(np.random.randint(0, 50, (3,4)))
d2 = pd.DataFrame(np.random.randint(0, 50, (4,5)))
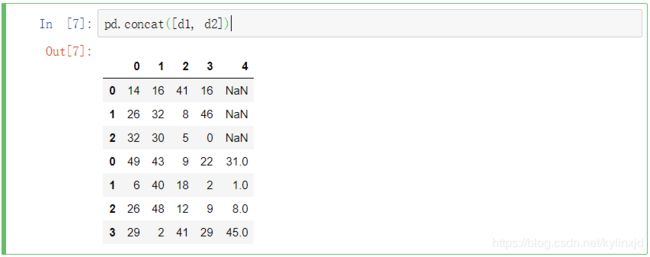
默认按列合并,对应的列合并到一起,缺少的列用nan值填充
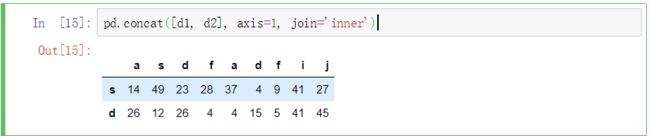
指定axis可以按行合并,缺少的行用nan值填充

指定连接方式
join : inner,只保留相同索引的行或列
outer ,保留所有的行或列
sort=False是取消自动排序

2、merge合并
left ,按左边DataFrame对象的行或列索引合并
right ,按左边DataFrame对象的行或列索引合并
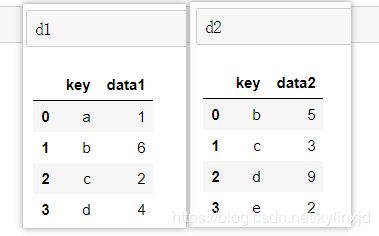
d1 = pd.DataFrame({
'key': list('abcd'),
'data1':[1,6,2,4]
})
d2 = pd.DataFrame({
'key':list('abcd'),
'data2':[5,3,9,2]
})
merge函数的参数
pd.merge(
left,
right,
how='inner', 连接方式
on=None, 指定连接列字段,类似MySQL的外键
left_on=None, 当没有相同的列的时候,同left_on,right_on指定不同的列连接
right_on=None,
left_index=False, 通过行索引连接的时候使用left_index和right_index指定
right_index=False,
sort=False, 默认按行索引排序关闭
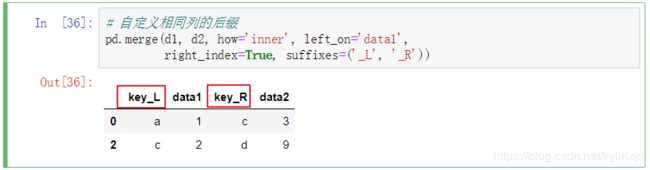
suffixes=('_x', '_y'), 当有多个相同列的时候可以使用suffixes指定后缀以区分
copy=True,
indicator=False,
validate=None,
)
默认连接
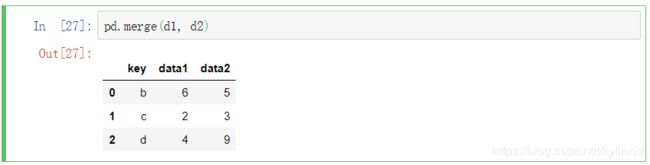
外连接
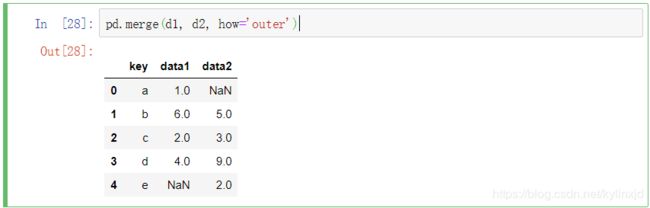
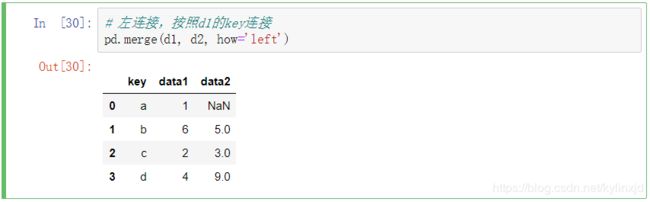
左右连接

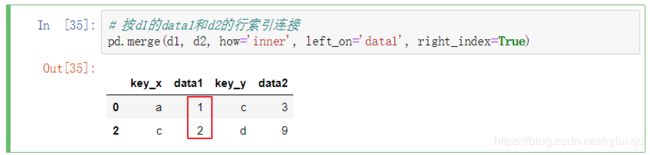
按d1的data1和d2的行索引连接
自定义相同列的后缀
分组
使用groupby分组
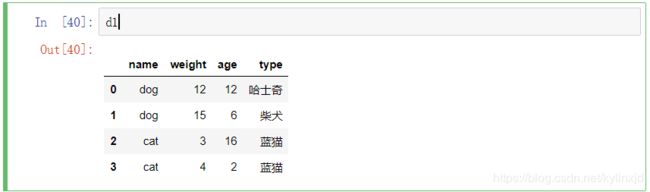
创建一个dataframe
d1 = pd.DataFrame({
'name': ['dog', 'dog', 'cat','cat'],
'weight': [12, 15, 3, 4],
'age':[12,6,16,2],
'type':['哈士奇', '柴犬', '蓝猫', '蓝猫']
})
按name分组

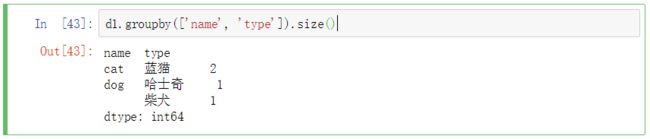
groupby返回的是一个DataFrameGroupBy对象,使用size()来查看每个组的大小

按name和type分组
对分组使用聚合函数
1、求和
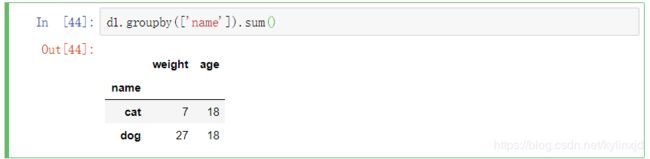
2、求平均值
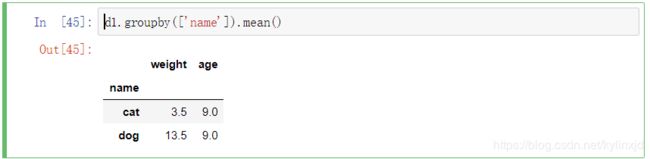
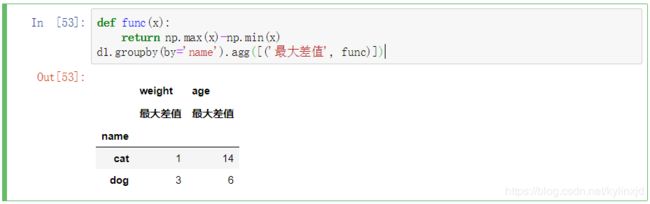
3、求最大值
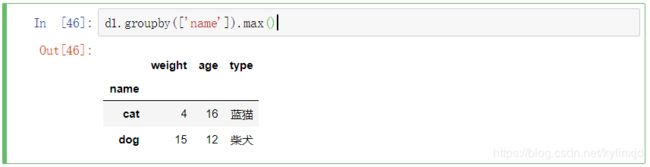
还有 方差 var、标准差std、中位数median等
也可以一次性查看所有的描述统计信息
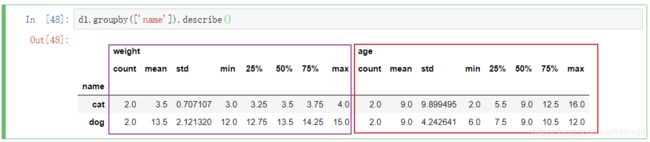
对不同的数据使用不同的函数
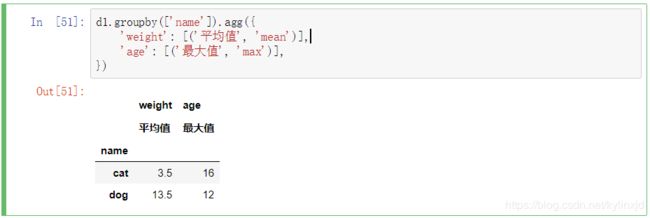
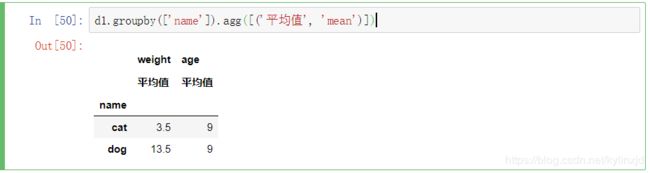
展示时起个别名
自定义聚合函数