深入分析Java Web技术内幕读书笔记(一)浅析Web请求过程
随着
Web技术的快速发展,互联网的网络架构已经从传统的C/S架构转变为B/S架构,B/S架构相较于传统的C/S架构,有诸多优点,例如:提供了统一的操作方式,简化了用户的学习成本;便捷的开发方式大大提高了开发者的开发效率;遵循统一的HTTP请求协议,开发运营维护十分方便。
一、B/S网络架构简单概述
B/S网络架构采用的是统一的应用层协议HTTP来进行数据的交互,与传统的C/S应用采用的长连接交互方式不同,B/S应用是无状态的短连接的通信方式。也就是说,一次请求对应一次响应,响应结束后,本次通信也就结束了,这种方式可以满足大数据量的用户的访问需求,节约了物理资源。
我们最常见的操作就是在浏览器的地址栏输入一个网络地址,敲击回车键即可在浏览器容器上看到服务器返回来的内容,但是,在敲击回车键之后,客户端到服务端都具体完成了哪些操作,才能将数据以最美的状态呈现在我们的面前,这个也是需要了解一下的。
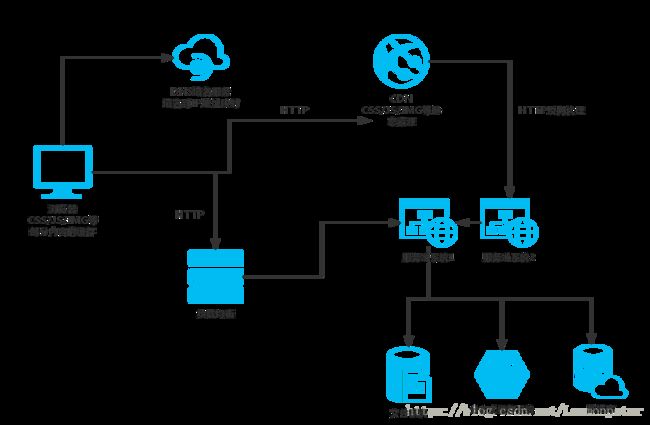
根据上图来简单解释一下当用户输入完网络地址和敲击回车键之后,浏览器和服务器都做了些什么动作:
-
当用户在浏览器的地址栏输入了
www.csdn.net之后,首先浏览器将请求DNS服务器,请求DNS服务器解析当前URL,匹配当前URL对应的实际IP地址,当配到IP地址,浏览器向这个IP地址发送get请求,远程服务器接收到请求之后,将用户需要的数据返回给用户。 -
在实际的服务端,往往伴随着很多复杂的业务逻辑,服务器有很多台,但是具体有哪一台服务器来提供服务,往往是由负载均衡设备来均衡分配。还有一点就是用户请求的数据也许是一个文件,那么服务器就需要访问文件系统,获取指定文件,也许用户需要的资源在缓存系统中已经缓存了,那么服务器优先访问缓存文件,也许用户需要的数据直接存储在数据库中,那么服务器就需要访问数据库系统,获取数据。
-
当浏览器接收到服务器返回的数据后,解析发现有许多静态资源是存储在
CDN上,那么将再次向CDN服务器发送HTTP请求,那么CDN又将会处理这些请求,流程和上面的类似。至于这里面的更多细节,都会影响最终的数据完整返回。
那么对于一个完整的B/S应用,不管网络架构如何变化,它应该始终需要遵循一些基本原则:
-
每一个资源存在互联网的某一个角落,访问该资源,需要使用唯一的一个
URL来描述其位置; -
资源的访问与交互都需要基于
HTTP协议,这样才可以与远程服务器正确地打招呼; -
需要使用浏览器来还原数据,客户端拿到数据以后,数据的展示一般都需要浏览器来进行渲染还原。
二、如何发起一个请求
发起HTTP请求最常见的方式就是在浏览器地址栏输入URL,敲击回车键就发起了一个HTTP请求,比如在地址栏输入www.csdn.net,敲击回车键之后很快浏览器就接收到了服务器返回的数据并渲染完毕,以最佳的方式将数据还原,这是一种最基本的发起请求的方式。还有稍微复杂一点的方式,那就是自己组装HTTP请求头和请求体,也可以实现脱离浏览器发起HTTP请求。对于发起HTTP请求,其实和服务器建立Socket连接区别不大,只不过outputStream.write方法输出的二进制数据格式要符合HTTP规范。在浏览器和服务器建立Socket连接之前,必须要执行的一个动作就是解析URL的域名,获取域名对应的IP地址,在根据这个地址和默认的80端口建立起Socket连接,然后在获取URL中的参数组成一个get请求,使用outputStream.write方法发送到目标服务器,服务器等待inputStream.read方法读入参数并执行处理逻辑,然后返回数据后断开连接。
对于复杂一点的HTTP请求,我们完全可以根据HTTP的规范来自己组装请求头和请求体,从而实现模仿浏览器发起请求。下面的代码是借助hutool工具包来发起一个post请求。
private String post(HeaderModel headerModel, Object params) {
return HttpRequest.post("http://" + headerModel.getHost() + headerModel.getRestfulUrl())
.header("Method", headerModel.getMethod())
.header("URL", headerModel.getRestfulUrl())
.header("Host", headerModel.getHost())
.header("Content-Type", headerModel.getContentType())
.header("Content-Length", headerModel.getContentLength())
.body(JSONUtil.parse(params)).execute().body();
}
这里是我在项目中封装了一个私有方法,传入的参数是请求头模型和参数模型,请求头模型中可以提供host,RESTful API,method等信息,请求参数体直接通过JSONUtil转换为json字符串,然后直接发起post请求。当然,这里使用的是hutool工具包的发起请求的方法,还有较为出名的HttpClient也可以做到从代码层面处理HTTP请求。
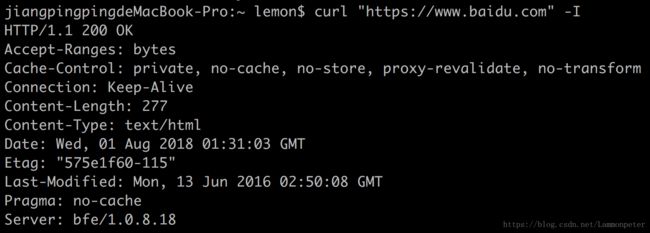
在linux系统中,还可以通过命令行来发起请求,例如curl "https://www.baidu.com",可以返回百度首页页面的HTML数据,由于不是使用浏览器发起的请求,所以这些数据无法正常解析从而展示百度首页。当然linux中还有wget命令可以实现发起文件下载的请求,可以轻松轻松从互联网下载文件。
如果需要查看本次访问的HTTP头的信息,在命令后面加上-I即可:
三、分析常见的HTTP信息
常常与B/S网络架构打交道的开发者,都需要对HTTP有一定的了解,HTTP是B/S网络架构的精髓,想要理解HTTP,那么首先得熟悉HTTP Header,HTTP Header基本上是控制了用户访问互联网资源的命脉,比如访问资源的位置,访问的方式,解析响应内容的解码方式,内容的获取是否优先从缓存中获取等等。当响应头中检测到404状态码,浏览器就会渲染出页面丢失或者不存的提示信息等。HTTP Header通常分为四部分,分别是:General Headers, Request Headers, Response Headers, Entity Headers。查看这些基本的消息头,可以使用浏览器自带的控制台对其进行查看。
表1-1 :常见的General Header
| 通用头 | 说明 | 示例 |
|---|---|---|
| Request URL | 请求的URL | https://www.baidu.com/ |
| Request Method | 请求方法 | GET |
| Status Code | 状态码 | 200 |
| Remote Address | 远程IP地址 | 111.13.100.91:443 |
| Referrer Policy | 来源协议 | unsafe-url |
关于上面的各个通用头的示例值,往往有多种,比如Request Method还有POST、PUT等方法,Status Code还有403、404、500等状态码,Referrer Policy还有no-referrer、origin等来源协议。通过浏览器自带的控制台可以查看这些基本信息:
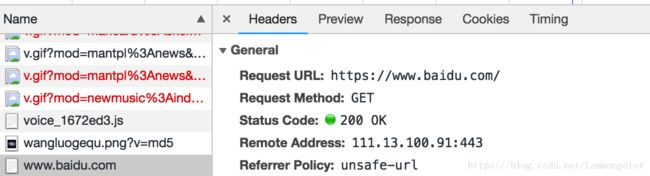
表1-2:常见的Request Headers
| 请求头 | 说明 | 示例 |
|---|---|---|
| Accept | 用于指定客户端可接收的内容 | text/html,application |
| Accept-Charset | 用于指定客户端接收的字符集 | UTF-8 |
| Accept-Encoding | 用于可接收的内容编码 | gzip, deflate, br |
| Accept-Language | 用于指定一种自然语言 | zh-cn |
| Host | 用于指定被请求的资源的主机和端口号 | www.baidu.com |
| User-Agent | 浏览器将本机系统、浏览器等属性作为值传递给服务器 | Mozilla/5.0… |
| Cookie | 一般存储一些与服务器交互的基本凭证信息 | … |
访问百度首页时候的请求头截图如下:
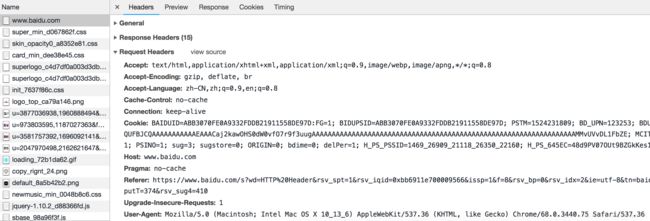
表1-3:常见的Response Header
| 响应头 | 说明 | 示例 |
|---|---|---|
| Server | 远程的服务器名称 | BWS/1.1 |
| Content-Type | 用于指明发送给接收者的实体正文的媒体类型 | text/html;charset=utf-8 |
| Content-Encoding | 与请求报头Accept-Encoding对应,告诉浏览器服务端编码方式 | gzip |
| Content-Language | 与请求报头Accept-Encoding对应,描述了当前资源的采用的自然语言 | zh-cn |
| Content-Length | 指明实体正文的长度 | 128 |
| Keep-Alive | 保持连接的时间 | timeout=5,max=120 |
访问百度首页时候的响应头截图如下:
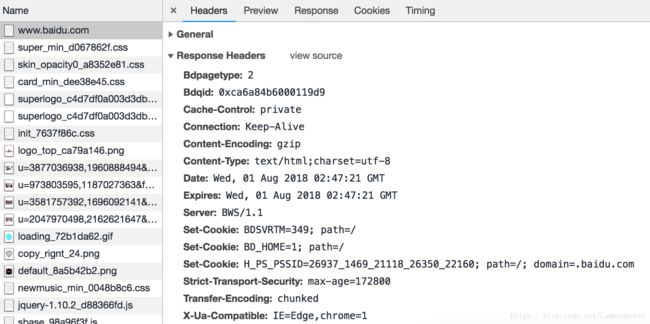
表1-4:常见的HTTP状态码
| 状态码 | 说明 |
|---|---|
| 200 | 客户端请求成功 |
| 302 | 临时跳转,跳转的地址由Location指定 |
| 400 | 服务器无法识别客户端的请求,请求语法错误 |
| 403 | 服务器接收到请求,但是拒绝为客户端提供服务 |
| 404 | 请求资源不存在 |
| 500 | 服务器内部错误 |
四、理解浏览器的缓存机制
浏览器的缓存机制是一个比较复杂且很重要的机制,在实际的使用中往往会提高页面的响应速度,但在开发过程中,往往许多静态资源的修改却不能及时从服务器同步到浏览器,导致开发效率下降。一般来说,在开发过程中如果页面上某些功能没有生效,优先考虑的应该是缓存的原因导致的,所以推荐windows用户按Ctrl+F5组合键来对页面重新发起请求,推荐Mac用户使用Command+Shift+R组合键来强制刷新,使得数据都从服务器获取而不是浏览器缓存中获取。虽然强制刷新是将请求发送到了服务器,但是获取的数据也不一定是最新的,因为某些服务器也会对数据进行缓存,为了提高自身的响应速度,所以为了保证用户获取的最新的数据,可以通过HTTP Header来进行控制。
细心的朋友会发现,使用Ctrl+F5的强制刷新方式和普通的刷新方式,在浏览器的控制台会显示出不同的内容,一般的普通刷新方式,在浏览器的控制台的NetWork一栏里会显示很多请求(大部分静态资源)会显示“from disk cache”,如下图所示:

当强制刷新之后,则不会显示“from disk cache”,如下图所示:
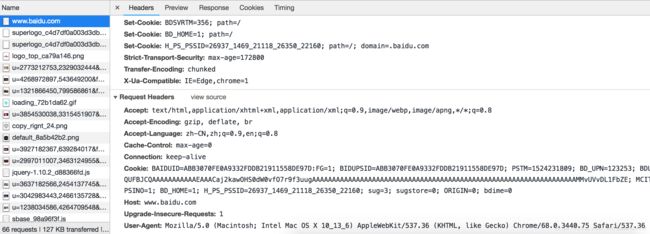
当然,这只是表面现象,其实,普通刷新和强制刷新的区别应该从请求头上来体现。当使用普通刷新的时候,请求头显示如下:
当使用强制刷新的时候,请求头显示如下:
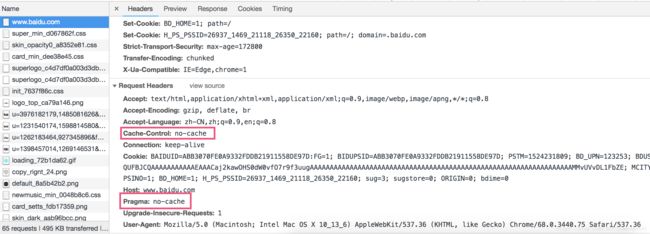
观察这两次刷新发起的请求,第二次请求在请求头中添加了一对键值属性:Pragma:no-cache,并且将Cache-Control的值有max-age=0变成了no-cache,为什么改变了这两个配置项,就可以实现绕过缓存,直接向服务器发起请求?还有那些配置项有类似的作用?
Cache-Control/Pragma
这两个HTTP Head字段起到了控制浏览器和缓存代理服务器的缓存行为,它们作用与请求链和响应链中,使得在缓存行为中必须遵循这两个字段的要求。Cache-Control是最重要的规则。这个字段用于指定所有缓存机制在整个请求/响应链中必须服从的指令。这些指令指定用于阻止缓存对请求或响应造成不利干扰的行为。这些指令通常覆盖默认缓存算法。缓存指令是单向的,即请求中存在一个指令并不意味着响应中将存在同一个指令。Cache-Control的属性值可以配置如下表1-5:
表1-5 Cache-Control字段的可选值
| 可选值 | 说明 |
|---|---|
| Public | 所有内容都将被缓存,在响应头中设置 |
| Private | 内容只设置到私有缓存中,在响应头中设置 |
| no-cache | 所有内容都不会被缓存,可以在请求头和响应头中设置 |
| no-store | 所有内容都不会被缓存到缓存或者Internet临时文件中,在响应头中设置 |
| must-revalidation/proxy-revalidation | 如果缓存内容失效,请求必须发送到服务器/代理以进行重新验证,在请求头中设置 |
| max-age=xxx | 缓存将在xxx秒后失效,这个选项只可在HTTP 1.1中可用,和Last-Modified一起使用时优先级较高,在响应头中设置 |
Pragma字段的作用和Cache-Control有点类似,它也是在HTTP头中包含一个特殊的指令,使相关的服务器遵守该指令,最常用的说就是Pragma:no-cache,他和Cache-Control:no-cache作用是一样的。
Expires
Expires指的是过期时间,由响应头设置,常见的格式是Expires:Thur,02 Aug 2018 09:50:34 GMT,后面跟着一个日期和时间,超过这个值后,缓存就过期了,浏览器在发起请求之前,会检查该值,如果过期,就直接向服务器发起请求。
Last-Modified/Etag
Last-Modified表示资源在服务器上最后的修改时间,静态资源返回到客户端的时候会自动带上这个字段,并指明最后修改时间,动态资源可以由代码来进行控制,比如Servlet提供了一个getLastModified方法来检查某个动态资源是否已经改变,这个字段可以保证当前请求的资源是最新的。一般浏览器在发起请求的时候,会在请求头中多出一个字段,If-Modified-Since:Thur,02 Aug 2018 09:50:34 GMT,检查当前是否最后的修改是不是当前这个时间,如果是,将直接从缓存中获取数据,并返回304状态码,否则将重新发起请求从服务器获取最新数据。
Etag标签是让服务器为每个页面分配一个唯一的编号,然后通过这个编号来辨别当前资源是否是最新的,它比Last-Modified更加灵活,但是有多台后台服务器的时候,服务器要记住所有资源的编号,那就显得有点多余了。
本篇文章简单的分析了一下发起一个HTTP请求的一些细节问题,当然真正的请求肯定不是这般轻描淡写而能表达清楚的,后面的系列文章将继续记录一些细节问题,欢迎关注。
深入分析Java Web技术内幕系列读书笔记文章列表:
深入分析Java Web技术内幕读书笔记(一)浅析Web请求过程
深入分析Java Web技术内幕读书笔记(二)浅析DNS域名解析过程
更多干货分享,欢迎关注我的微信公众号:爪哇论剑(微信号:itlemon)
