Hadoop-2.7.3平台环境搭建
一、实验环境安装及配置
1、操作系统安装
根据计算机是32位还是64位机,选择安装不同的操作系统(Ubuntu、CentOS、RedHat)都可以,服务器为DELL PowerEdge R720, 配置为两个物理CPU(Intel Xeon E5-2620 V2 2.10GHZ,每个CPU含6个内核,共12个内核),32G内存,8T硬盘,4个物理网卡。服务器安装VMWare esxi6.0.0操作系统,虚拟化整个服务器环境。客户端使用VMWare VSphere clinent6.0.0将服务器划分为4个虚拟机,每个虚拟机的配置为3内核CPU,8G内存,2T硬盘,1个物理网卡,每个虚拟机安装ubuntu-16.04.1-server-amd64操作系统。安装Ubuntu的过程中基本上一路按回车键,选择默认配置就可以了,只是在硬盘配置的选择上,不能按默认的配置,需要根据实际情况选择磁盘上的一个分区,还是使用整个磁盘作为一个分区,具体情况根据机器磁盘的分区情况,按照安装过程中的提示完成。安装过程中使用hadoop作为默认的用户名,密码为123。
使用hadoop作为默认用户名,系统会在/Home目录下建立hadoop目录作为用户的主目录,hadoop-2.7.3.tar.gz包,将解压到该目录下。
系统安装完毕后,使用hadoop用户登录到系统,输入命令 sudo passwd root,根据提示设置root用户的密码(先输入hadoop用户的密码,再输入两遍root用户的设置密码),就可以用root用户登录系统了。虽然可以用sudo完成大多数root用户的功能,但特殊情况还是需要具有最高权限的 root用户登录后进行操作为好,如设置网卡的配置等等。
2、软件环境安装
运行hadoop平台需要java jdk,ssh及jps,都可以使用apt-get install命令直接通过网络安装。用root用户登录后,输入java –version命令,系统会提示需要安装的java jdk包,根据实际情况,选择对应的安装包。实验过程中选择安装的jdk包为default-jdk,在命令提示符下输入命令:apt-get install default-jdk后,系统会通过网络下载jdk包,然后自动安装。通过网络安装的前提条件是系统可以上网,由于服务器连接在一个24口的路由器上(路由器本身可以上网),故系统在安装的过程中,对网卡进行了自动配置,通过dhcp的方式获得IP 地址,然后通过路由器上网。至于如何通过配置网卡,使用静态的内部IP地址上网,将在网络配置中详细解释。在命令提示符下输入 apt-get installssh,安装ssh,输入apt-get install jps 安装jps(具体是那个包,记得不是很清楚),可以直接输入jps,然后根据提示选择安装的包。
3.网络环境配置
规划的网络配置为
| 主机名 |
IP地址 |
用途 |
| datanode1 |
192.168.1.151 |
Namenode,Datanode |
| datanode2 |
192.168.1.152 |
Datanode |
| datanode3 |
192.168.1.153 |
Datanode |
| datanode4 |
192.168.1.154 |
Datanode |
编辑位于每个节点的/etc/network目录下的interfaces文件,在#The primary interface 节点下输入以下的内容:
auto ens160
iface ens160 inetstatic
address 192.168.X.X(规划的 IP地址)
gateway 192.168.1.1
netmask 255.255.255.0
broadcast 255.255.255.255
编辑每个节点的/etc/resolvconf/resolv.conf.d/base文件,输入以下内容:
nameserver 202.103.24.68
注意resolv.conf.d目录不能直接进入,需要从上一级目录进入(同networking 命令,不能在/etc/init.d目录中执行,必须在上一级目录执行一样,或在init.d目录输入./networking执行,是什么原因,目前还不明白)。设置DNS服务器地址,具体的DNS服务器地址,根据实际情况设定,可以设置多个DNS服务器地址。注意不能直接修改/etc/resolv.conf文件,该文件会在每次重启后被重置,从而导致DNS解析无效。(注:以上为较老版本的Ubuntu配置DNS的做法,新版的Ubuntu直接在interfaces文件中加入dns-nameservers202.103.24.68即可)。
设置hosts文件:hadoop平台使用计算机主机名来识别集群中的计算机,故集群中的每个节点,都需要设置hosts文件,以便相互访问。
每个节点的hosts文件内容全部一样,均为:
127.0.0.1 localhost
192.168.1.151 datanode1
192.168.1.152 datanode2
192.168.1.153 datanode3
192.168.1.154 datanode4
若新加入一个节点,则需要修改每个节点的hosts文件。hosts文件中的127.0.1.1那一行,一定要去掉。
4.设置ssh无密码访问
Hadoop平台的每个节点之间通过ssh协议进行通讯,故需要在集群中配置ssh无密码访问。具体配置步骤为:
1) 在datanode1 以hadoop用户身份登录系统。
2) 用ssh datanode2连接datanode2,连接后,输入exit命令退出,系统会在/home/hadoop目录下生产一个.ssh 的隐藏目录。
3) 输入ssh-keygen -t rsa 命令(一路按回车键,保证密码为空),会在.ssh目录下生成id_rsa,id_rsa.pub两个文件(公钥和私钥)。
4) 输入 cp id_rsa.pub authorized_keys 生成登录用的公钥文件。
5) 输入命令ssh datanode2测试是否可以无密码登录本机。
6) 使用scp ./ssh/id_rsa hadoop@ datanode2:/home/hadoop/.ssh
scp./ssh/id_rsa.pub hadoop@ datanode2:/home/hadoop/.ssh
scp./ssh/ authorized_keys hadoop@ datanode2:/home/hadoop/.ssh
将文件复制到datanode2的.ssh目录中,以同样的方式复制到datanode3及datanode4的.ssh目录中。
7) 测试datanode1,datanode2,datanode3,datanode4相互之间可以用ssh无密码登录,这一步必须成功,否则无法搭建Hadoop集群平台。
二、 Hadoop集群平台的搭建1、安装 hadoop软件
hadoop的软件升级非常快,官方文档的支持很欠缺,故网络中的一些配置和安装过程都需要根据安装的版本进行调整。若是32位的计算机,最好安装hadopp-2.4.1以前的版本,因为该版本前,hadoop自带的本地库是32位的。(本地库为解压后的目录lib/native中的libhadoop.so.1.0.0、libhdfs.so.0.0.0文件 ),hadoop-2.5.0以后,hadoop的自带的本地库为64位的。用
filelibhadoop.so.1.0.0
命令查看文件属性,显示Intel 386,则是32为,若显示X86-64,则为64位。本次安装在虚拟机上的为hadoop-2.7.3版本,hadoop自带的本地库为64位。
选定好要安装的hadoop版本后,在官方镜像网站下载相应的安装包,下面以在datandoe1上安装和配置hadoop-2.7.3 为例,说明hadoop的安装及配置过程。注意所有操作均以hadoop用户的身份登录系统。
1) 安装hadoop-2.7.3
a. 将下载的hadoop-2.7.3.tar.gz文件 copy到U盘,插入usb接口。
b. 执行sudo fdisk –l 命令,查看U盘的设备号,一般为/dev/sdb1。
c. 执行sudo mkdir /mnt/usb命令,建立挂载U盘的目录。
d. 执行 sudo mount /dev/sdb1/mnt/usb,挂载U盘。
e. 执行cp /mnt/usb/hadoop-2.7.3.tar.gz ~/,copy安装包到主目录。
f. 执行 tar –xzvf hadoop-2.7.3解压软件包到 hadoop-2.7.3目录。
2) 配置.bashrc文件
运行hadoop软件需要配置一些环境变量,在.bashrc文件的尾部添加以下内容。
export HADOOP_HOME=/home/hadoop/hadoop-2.7.3
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export JRE_HOME=/usr/lib/jvm/java-8-openjdk-amd64/jre
export HBASE_HOME=/home/hadoop/hbase-1.2.3
export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib:$HADOOP_HOME/lib/native:$HBASE_HOME/lib:$CLASSPATH
exportPATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HBASE_HOME/bin
export LD_LIBRARY_PATH=$HADOOP_HOME/lib/native
#export HADOOP_ROOT_LOGGER=DEBUG,console
本行为设置执行命令时,是否显示debug信息,若要知道命令的执行过程中有什么错误,非常有用,一般情况下,注释掉)。
配置完成后,登出hadoop,再次以hadoop登录,使用env命令查看环境变量是否配置成功。
3)建立hadoop必须的目录
在hadoop-2.7.3目录下建立执行一下命令,建立以下目录。
mkdir tmp
mkdir hdfs
mkdir hdfs/name
mkdir hdfs/data
mkdir mapred
mkdir mapred/system
mkdir mapred/local
这些目录在后续的配置文件中,会出现。
3) 配置core-site.xml文件
在hadoop-2.7.3/etc/hadoop目录下的core-site.xml文件中输入以下内容:
<configuration>
<property>
<name>io.native.lib.availablename>
<value>truevalue>
property>
<property>
<name>fs.default.namename>
<value>hdfs://datanode1:9000value>
<final>truefinal>
property>
<property>
<name>hadoop.native.libname>
<value>truevalue>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/home/hadoop/hadoop-2.7.3/tmpvalue>
property>
configuration>
4) 配置hdfs-site.xml文件
在hadoop-2.7.3/etc/hadoop目录下的hdfs-site.xml文件中输入以下内容:
<configuration>
<property>
<name>dfs.namenode.name.dirname>
<value>file:///home/hadoop/hadoop-2.7.3/hdfs/namevalue>
<final>truefinal>
property>
<property>
<name>dfs.datanode.data.dirname>
<value>file:///home/hadoop/hadoop-2.7.3/hdfs/datavalue>
<final>truefinal>
property>
<property>
<name>dfs.replicationname>
<value>3value>
property>
<property>
<name>dfs.permissions.enabledname>
<value>falsevalue>
property>
configuration>
5) 配置mapred-site.xml文件
若目录中无此文件,则cp mapred-site.xml.templatemapred-site.xml,生成该文件。
<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
<property>
<name>mapreduce.jobtracker.addressname>
<value>datanode1:9001value>
<final>truefinal>
property>
<property>
<name>mapreduce.jobtracker.system.dirname>
<value>file:///home/hadoop/hadoop-2.7.3/mapred/systemvalue>
<final>truefinal>
property>
<property>
<name>mapreduce.cluster.local.dirname>
<value>file:///home/hadoop/hadoop-2.7.3/mapred/localvalue>
<final>truefinal>
property>
configuration>
6) 配置yarn-site.xml
在hadoop-2.7.3/etc/hadoop目录下的yarn-site.xml文件中输入以下内容:
<configuration>
<property>
<name>yarn.resourcemanager.hostnamename>
<value>datanode1value>
property>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.classname>
<value>org.apache.hadoop.mapred.ShuffleHandlervalue>
property>
configuration>
7) 配置hadoop-env.sh文件
在etc/hadoop目录中的文件尾部,输入以下内容
export HADOOP_IDENT_STRING=$USER
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export HADOOP_HOME=/home/hadoop/hadoop-2.7.3
export HADOOP_PID_DIR=/home/hadoop/pids
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_SECURE_DN_PID_DIR=${HADOOP_PID_DIR}
exportPATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
8) 配置slaves文件
在slaves文件中输入以下内容(hadoop-2.X.X之后,没有masters文件)
datanode1
datanode2
datanode3
datanode4
9) 初始化hadoop
执行 hadoop namenode –format格式化namenode,注意,若多次格式化namenode,则会造成namenode或datanode不能启动,原因是两者的uuid由于重新格式化后,出现了不一致。出现这种情况,删除tmp及hdfs目录后,重新格式化namenode,再次启动hadoop,问题一般可以得到解决。
10) 复制文件到集群中其它的节点
使用 scp 命令,将datanode1主目录下的.bashrc、hadoop-2.7.3/etc/hadoop目录下的hadoop-env.sh、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml这几个文件复制到集群中的每个节点上。(前提,集群中各个节点的java-jdk、hadoop-2.7.3的安装路径和datanode1上一致)。
11) 启动hadoop
使用start-dfs.sh ,start-yarn.sh启动hadoop软件(停止为stop-dfs.sh、stop-yarn.sh)。若启动成功,在Datanode1上运行jps,显示:
Jps
DataNode
SecondaryNameNode
ResourceManager
NodeManager
NameNode
在集群中的其它节点中运行jps显示:
Jps
DataNode
NodeManager
在 datanode1上执行 hdfs dfsadmin –report 命令,若配置成功,则显示1个namenode和4个datanode的信息(注意Datanode1也是一个datanode)。
在同一个网络的PC机上的浏览器中输入http://192.168.1.151:8088则出现如下图所示的界面:

点击Nodes出现以下界面:

显示有四个节点在运行。
在浏览器中输入http://192.168.1.151:50070出现以下界面:
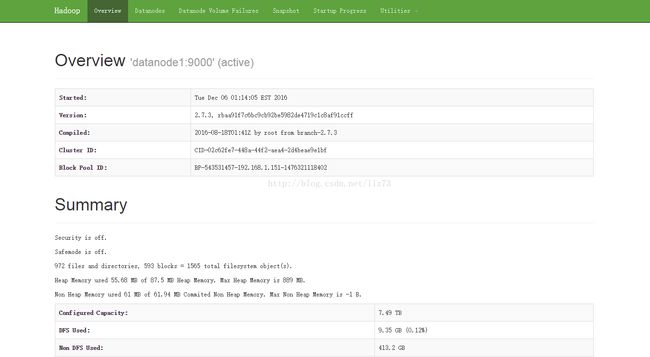
点击DataNodes出现以下界面。

三、 mapreduce测试
1、执行 hdfs dfs –mkdir /input在hdfs文件系统中建立input目录
2、执行 hdfs dfs –copyFromLocal ~/hadoop-2.7.3/etc/hadoop /input 将本地etc/hadoop的配置文件copy到hdfs文件系统的/input目录中。注意观察文件的复制个数是和hdfs-site.xml文件中dfs.replication节的设置一致。
3、在hadoop-2.7.3的目录中运行:
hadoop jar
~/hadoop-2.7.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jarwordcount /input /output
WordCount为mapreduce 的一个示例程序,用于统计/input目录中所有文件的单词个数,并将结果存储在/output目录中。观察程序运行的过程及在浏览器中观察任务在各个节点的分配过程。
4)、运行完成后,使用 hdfs dfs –cat /output/* 查看单词的统计结果。
#! /bin/bash