“GANs之父”Goodfellow 38分钟视频亲授:如何完善生成对抗网络?(上)
编者按:深度学习顶级盛会NIPS于今年12月初在巴塞罗那举行,相信有很多人都无法参加。不过,有另一个AI盛会却是全世界所有人都能参加的,叫做“AI WITH THE BEST”,已于今年9月在网络世界里召开。演讲嘉宾有100多人,其中就有“GANs之父”Ian Goodfellow。这个会议由于是网络播出,所以有完整录像,雷锋网对比Ian Goodfellow在NIPS的演讲内容,二者十分相仿,故在此将此次会议的视频搬运给大家,并附上中文图文详解(PS:本文由亚萌和三川共同编辑完成)。
原文视频连接(英文):https://www.leiphone.com/news/201612/eAOGpvFl60EgFSwS.html
大家好,先自我介绍一下,我叫Ian Goodfellow,我是OpenAI的一名研究员。OpenAI是一个非盈利性组织,致力于把通用性的人工智能变成一种安全的方法,并且造福于全人类。
我今天将给大家讲一下生成对抗网络(Generative Adversarial Networks),简称“GANs”。

什么是对抗生成网络(GANs)?
生成对抗网络是一种生成模型(Generative Model),其背后最基本的思想就是从训练库里获取很多的训练样本(Training Examples),从而学习这些训练案例生成的概率分布。
一些生成模型可以给出概率分布函数定义的估测,而另一些生成模型可以给你全新的样本,这些新样本来自于原有生成训练库的概率分布。
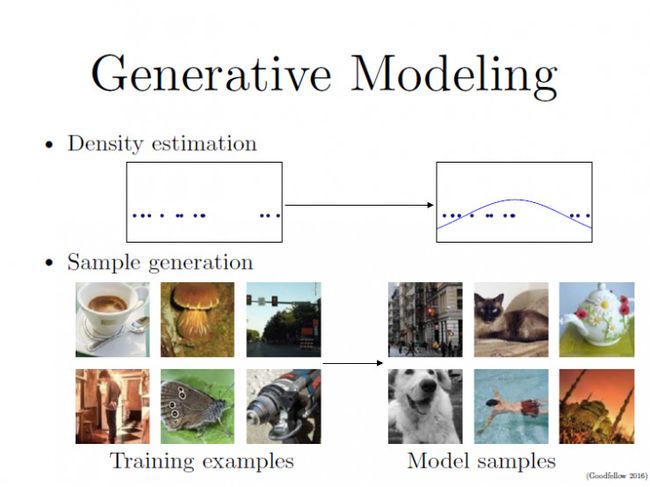
PPT最底下一排图片来自于ImageNet的数据库,左边是训练图片,右边我们可以看作是一个理想的生成模型所产生的照片(实际上右边的照片依然是从ImageNet库里选取的,我们的系统目前还没有成熟到可以生成这种真实感)。
GANs的方法,就是让两个网络相互竞争“玩一个游戏”。
其中一个叫做生成器网络( Generator Network),它不断捕捉训练库里真实图片的概率分布,将输入的随机噪声(Random Noise)转变成新的样本(也就是假数据)。
另一个叫做判别器网络(Discriminator Network),它可以同时观察真实和假造的数据,判断这个数据到底是不是真的。
所以整个训练过程包含两步,(在下图里,判别器用 D 表示,生成器用 G 表示,真实数据库样本用 X 表示,噪声用 Z 表示)。
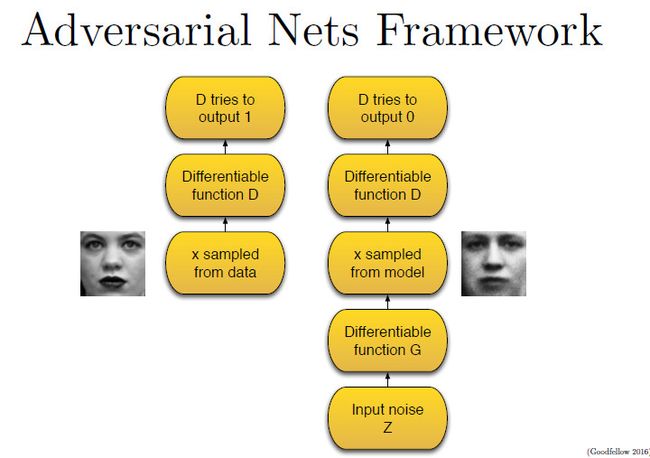
第一步,只有判别器D参与(上面左图)。
我们把X样本输入可微函数D里运行,D输出0-1之间的某个值,数值越大意味着X样本是真实的可能性越大。在这个过程中,判别器D尽可能使输出的值靠近1,因为这一阶段的X样本就是真实的图片。
第二步,判别器D和生成器G都参与(上面右图)。
我们首先将噪声数据Z喂给生成器G,G从原有真实图像库里学习概率分布,从而产生假的图像样本。然后,我们把假的数据交给判别器D。这一次,D将尽可能输入数值接近于0,这代表着输入数据Z是假的。
所以这个过程中,判别器D相当于一个监督情况下的二分类器,数据要么归为1,要么归为0。
与传统神经网络训练不一样的且有趣的地方,就是我们训练生成器的方法不同。生成器一心想要“骗过”判别器。使用博弈理论分析技术,我们可以证明这里面存在一种均衡。
DCGANs:深度卷积生成对抗网络
现代GANs架构基于一篇名为“ Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks ”(简称DCGANs)的论文,作者是 Alec Radford、Luke Metz和Soumith Chintala。(链接:https://arxiv.org/pdf/1511.06434.pdf)
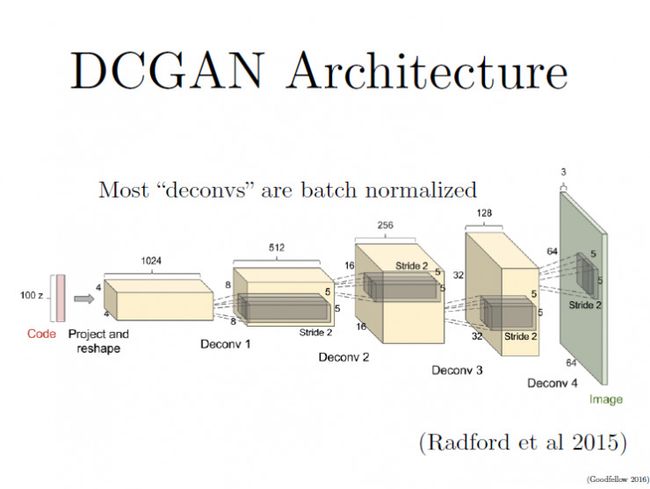
DCGANs的基本架构就是使用几层“反卷积”(Deconvolution)网络。“反卷积”类似于一种反向卷积,这跟用反向传播算法训练监督的卷积神经网络(CNN)是类似的操作。
CNN是将图像的尺寸压缩,变得越来越小,而反卷积是将初始输入的小数据(噪声)变得越来越大(但反卷积并不是CNN的逆向操作,这个下面会有详解)。
如果你要把卷积核移动不止一个位置, 使用的卷积滑动步长更大,那么在反卷积的每一层,你所得到的图像尺寸就会越大。
这个论文里另一个重要思想,就是在大部分网络层中使用了“批量规范化”(batch normalization),这让学习过程的速度更快且更稳定。另一个有趣的思想就是,如何处理生成器里的“池化层”(Pooling Layers),传统CNN使用的池化层,往往取区域平均或最大来压缩表征数据的尺寸。
在反卷积过程中,从代码到最终生成图片,表征数据变得越来越大,我们需要某个东西来逐渐扩大表征的尺寸。但最大值池化(max-pooling)过程并不可逆,所以DCGANs那篇论文里,并没有采用池化的逆向操作,而只是让“反卷积”的滑动步长设定为2或更大值,这一方法确实会让表征尺寸按我们的需求增大。
这其中有些想法来自于早期的一篇论文“全卷积网络”(Striving for Simplicity: The All Convolutional Net,链接 https://arxiv.org/abs/1412.6806),大家可以看一看。
DCGANs非常擅长生成特定Domain里的小图片,这里是一些生成的“卧室"图片样本。这些图片分辨率不是很高,但是你可以看到里面包含了门、窗户、棉被、枕头、床头板、灯具等卧室常见物品。

向量空间运算
我们在生成网络里随意输入一些噪声值,这些值解码成一些“戴眼镜的男人”的图片。我们将这些代码取平均值,便得到如下图最左一的“戴眼镜的男人”的图片,这是一个“平均图片”(Average Image)。
我们使用同样的过程,产生图中的“男人”(左二)和“女人”(左三)的图片。

而你可以在这些图片(向量空间)之间做运算。
“戴眼镜的男人”-“男人”+“女人”=“戴眼镜的女人”
这则加减运算里,辅以解码一些变量,最终得出了最右边一系列“戴眼镜的女人”图片。
这十分类似语言模型,单词向量(Word Embedding)之间也具有有趣的代数关系。例如,
“王后”-“女性”+“男性”=“国王”
向量运算是可行的,这一点令人印象深刻,因为我们确实需要解码经过运算生成的向量,然后得到每个像素都是有意义的图片。
在单词向量里,我们从运算中得到的新向量,只需要与之前的某个向量靠近就行。这个过程,并不需要解码成一种“真实世界体验”。而在我们图片的向量运算里,可以将运算结果映射到真实世界当中。
训练GANs难点:“模型崩溃”及其解决方法
训练GANs的一个难点,就在于会出现“模型崩溃”(Mode Collapse):生成的所有样本都在一个点上(样本相同),这是训练GANs经常遇到的失败现象。

我们训练GANs,起初让判别器的输出值最大化(尽量接近1),然后让生成器输出值最小化(尽量接近0),那么一切都没问题。但是,如果我们把顺序调一下,先最小化生成器输出值,然后再最大化判别器输出值,那么一切都会崩掉(这在循环训练的时候会发生)。
针对这个,我们可以采用的解决方法是minibatch GAN,给生成器增加一些额外的“特征”(Feature),让原始数据分成一波波的小批量样本,从而保证每一批数据的多样性。我们将里面用到的特征称为“小批量特征”(Minibatch Feature)。
如果这些“特征”测量的是样本之间的间距,那么通过这一点,判别器就能检测到生成器是否将要崩溃。小批量样本更加接近真实,且每个样本的间距是正确的,就不会让生成器产生只映射到一个点的图像。“小批量”的理念来自于OpenAI研究员Tim Salimans在2016年提交给NIPS的一篇论文。
使用“小批量特征”会大大提升GANs训练效果。我们用很多数据库来检验这一方法,其中的一个数据库就是CIFAR 10,这里面包括10中不同类别的物体,有鸟、飞机、汽车、货车、马等等,图片像素为32x32。

如上图所示,左边是训练数据,这些图片都很小,而且质量不高;右边是生成器产生的样本,其中有些样本展示的物体辨识度还可以,比如马、汽车、船等等。生成样本里大约40%只是一些由颜色和纹理构成的难以名状的一团,但是剩下的确实包含了一些有意义的物体图像。
我们也把 minipatch GANs放到更大的ImageNet数据库里,里面图像的分辨率是128x128,且包含数千种物体,难度大得多。尤其是发生我们前面提到的“模型崩溃”问题时,训练过程更难。

上面左边的图,来自于ImageNet,你或许会发现这些图比之前CIFAR 10的图片质量高很多,这是因为空间幅度(Spatial Extent)大约在每个方向上都扩展了4倍。这里面的物体类别繁多,甚至有一些连人类都无法准确归类,比如这当中有一格小图里包含了一个“瓦屋顶”,我就不太能确定这要归为“瓦”、“屋顶”还是“房子”?
所以,需要意识到的一点就是,这里要捕捉的多样性太多了。
右边的组图里,是我们训练minipatch GAN生成的样本图,其中真的有一些图片包含了可识别的物体。比如左上角的图,看起来像是一只胖狗,你也可以看到狗的脸、猫脸、眼睛等图形散布在各个样本里。但是,大部分图展示的内容并不协调,它们看起来像是毕加索或达利风格的画,只是一些纹理和图形的堆砌,并不是有机的构成。
我们从中精挑细选了一些比较好的样本图(Cherry-Picked Results),从中我们看到GAN做的事情是比较有用的,但是仍然有很多不足。
下面左上角的一张图的构成不错,这像是一个狗妈妈,旁边依偎着一只狗宝宝,两只狗望向同一个方向。但是你可以发现,这张图里的场景并不是3D的,而且跟前面的狗相比,后边的背景图并没有展现出什么意义。

最上面一排的中间图,看起来就像是一只巨型蜘蛛,而我认为之前的训练库里没有什么与此类似的东西。

很多次,我们常常发现,系统无法将纹理与形状合理地整合起来,这是一种模型过分概括(overgeneralization)的案例。
我们经常遇到的问题就是,这里面完全没有3D的立体构成,比如底部一排左三图片,狗的面部不错,狗的毛发展现的很好,但是总体上,这像是一块平铺在地上的狗皮(而不是立体的狗),就像是从正上方垂直看下来,我们称之为“正交投影”。在这个案例里,模型根本不知道如何做透视。

我们知道卷积网络可以计数的,在一些应用里,我们需要将图片里的地址数字进行转录,这就要求我们知道数字里包含了多少数位(Digits)。但看起来,如果你不明确训练神经网络如何计数,那么它自己是不会自动学习计数方法的。
最右下角的图,看起来像是一只美洲豹或黑猫的脸,但是这张图里包含的“脸”太多了。似乎神经网络知道需要有眼睛、嘴和鼻子来构成脸,但是它并不清楚到底一张脸要包含几个眼睛、嘴和鼻子,也不知道这些器官要正确放在什么位置。

GANs的应用:“文本转图像”(Text to Image)
我们可以用GANs做很多应用,其中一种就是“文本转图像”(Text to Image)。在Scott Reed等人的一篇论文里(Generative Adversarial Text to Image Synthesis,链接 https://arxiv.org/abs/1605.05396)。GANs根据输入的信息产生了相关图像,我到目前为止谈到的GANs还只是从学习训练库里的概率分布,随机产生图像,而不是像Scott Reed这样根据特定输入语句来产生特定图像。
在这篇新论文里,GANs增强了,输入了额外的描述信息,告诉它们应该要产生什么样的图像。
也就是说,生成器里输入的不仅是随机噪声,还有一些特定的语句信息。所以判别器不仅要区分样本是否是真实的,还要判定其是否与输入的语句信息相符。
这里是他们的实验结果,左上角的图里有一些鸟,鸟的胸脯和鸟冠是是粉色,主羽和次羽是黑色,与所给语句描述的信息相符。

但是我们也看到,仍然存在“模型崩溃”问题,在右下角的黄白花里,确实产生了白色花瓣和黄色花蕊的花朵,但它们多少看起来是在同一个方向上映射出来的同一朵花,它们的花瓣数和尺寸几乎相同。
所以,模型在输出的多样性方面还有些问题,这需要解决。但可喜的地方在于,输入的语句信息都比较好的映射到产生的图像样本中。
有趣的GANs 图像生成应用
在Indico和Facebook发布了他们自己的DCGAN代码之后,很多人开发出他们自己的、有趣的GANs应用。有的生成新的花朵图像,还有新动漫角色。我个人最喜欢的,是一个能生成新品种精灵宝可梦的应用。

在一个 Youtube 视频,你会看到学习过程:生成器被迫去学习怎么骗过判别器,图像逐渐变得更真实。有些生成的宝可梦,虽然它们是全新的品种,看上去就像真的一样。这些图像的真实感并没有一些专业学术论文里面的那么强,但对于现在的生成模型来说,不经过任何额外处理就能得到这样的结果,已经非常不错了。
超分辨率
一篇最近发表的论文,描述怎么利用GANs进行超分辨率重建(Super-Resolution)。我不确定这能否在本视频中体现出来,因为视频清晰度的限制。基本思想是,你可以在有条件的GANs里,输入低分辨率图像,然后输出高分版本。使用生成模型的原因在于,这是一个约束不足(underconstrained)的问题:对于任何一个低分辨率图像,有无数种可能的高分辨率版本。相比其他生成模型,GANs特别适用超分辨率应用。因为GANs的专长就是创建极有真实感的样本。它们并不特别擅长做概率函数密度的估测,但在超分辨率应用中,我们最终关心的是输出高分图像,而不是概率分布。

(从左到右分别为:图1、2、3、4)
上面展示的四幅图像中,最左边的是原始高分图像(图1),剩下的其余三张图片都是通过对图片的降采样(Down Sample)生成的。我们把降采样得到的图片用不同的方法进行放大,以期得到跟原始图像同样的品质。
这些方法有很多种,比如我们用双三次插值(Bicubic Interpolation)方式,生成的图像(图2)看起来很模糊,且对比度很低。另一个深度学习方法SRResNet(图3)的效果更好,图片已经干净了很多。但若采用GANs重建的图片(图4),有着比其它两种方式更低的信噪比。虽然我们直观上觉得图3看起来更清晰,事实上它的信噪比更高一些。GANs在量化矩阵(Quantitative Matrix)和人眼清晰度感知两方面,都有很好的表现。
视频后18分钟答疑部分详见链接:http://blog.csdn.net/love666666shen/article/details/75108902
(PS:在视频的后半段,主要是Ian Goodfellow回答网友的提问,雷锋网(公众号:雷锋网)将据此编辑成第2篇文章,后续将发布。)