CVPR 2020丨图像超清化+老照片修复技术,拯救你所有的模糊、破损照片

编者按:也许你曾从橱柜里翻出家人们压箱底的老照片,而它们已经泛黄发脆,甚至有些褪色;也许你在拍照时不慎手抖,只好把糊成一片的照片都丢进“最近删除”。而微软亚洲研究院在计算机视觉顶会 CVPR 2020 发表的两项黑科技——基于纹理 Transformer 模型的图像超分辨率技术,和以三元域图像翻译为思路的老照片修复技术,将能让这些照片奇迹般地恢复如初。同时,图像超分别率技术将于近期上线 PowerPoint,未来也将有更多图像修复技术集成进微软 Office 产品中。
从古老的胶片照相机到今天的数码时代,人类拍摄和保存了大量的图片信息,但这些图片不可避免地存在各种不同程度的瑕疵。将图片变得更清晰、更鲜活,一直是计算机视觉领域的重要话题。而无论是尘封多年的泛黄老照片、旧手机拍摄的低清晰度照片,还是你不慎手抖拍糊的照片,微软亚洲研究院在计算机视觉顶会 CVPR 2020 发表的两项黑科技,都能让它们重现光彩。
第一项技术是图像超分辨率技术,即从低分辨率图像中恢复出自然、清晰的高分辨率图像。与先前盲猜图片细节的方法不同,我们引入一张高分辨率参考图像来指引整个超分辨率过程。高分辨率参考图像的引入,将图像超分辨率问题由较为困难的纹理恢复/生成转化为了相对简单的纹理搜索与迁移,使得超分辨率结果在指标以及视觉效果上有了显著的提升。
进一步,我们提出老照片修复技术。与其他图片修复任务相比,这是一项更为困难的任务——老照片往往同时含有多种瑕疵,如褶皱、破损、胶片噪声、颜色泛黄,也没有合适的数据集来模拟如此复杂的退化。为此,我们将问题规划为三元域图片翻译,训练得到的模型可以很好地泛化到实际老照片,并取得惊艳的修复效果。

万物皆可 Transformer:
基于纹理 Transformer 模型的
图像超分辨率技术
Transformer 结构被广泛应用于自然语言处理任务,取得了显著的成果,然而其在图像生成领域中鲜有应用。针对于图像超分辨率问题,微软亚洲研究院创新性地提出了一种基于纹理 Transformer 模型的图像超分辩率方法(TTSR),取得了显著的效果。该模型可以有效地搜索与迁移高清的纹理信息,最大程度地利用了参考图像的信息,并正确地将高清纹理迁移到生成的超分辨率结果当中,解决纹理模糊和纹理失真的问题。
纹理 Transformer 模型
如图1所示,微软亚洲研究院提出的纹理 Transformer 模型包括:可学习的纹理提取器模块(Learnable Texture Extractor)、相关性嵌入模块(Relevance Embedding)、硬注意力模块(Hard Attention)、软注意力模块(Soft Attention)。以下分别针对上述四个模块展开介绍。

图1:本文提出的纹理 Transformer 模型
可学习的纹理提取器。对于纹理信息的提取,目前主流的方法是将图像输入到预训练好的 VGG 网络中,提取中间的一些浅层特征作为图像的纹理信息。然而,这种方式有明显的缺陷。
首先,VGG 网络的训练目标是以语义为导向的图像类别标签,其高层级的语义信息与我们所需要的低层级的纹理信息有着很大的差异。因此,以 VGG 模型中间层的特征作为纹理特征是值得商榷的。
其次,对于不同的任务,所需要提取的纹理信息是有差别的,使用预训练好并且固定权重的 VGG 网络是缺乏灵活性的。对此,我们在纹理 Transformer 中提出了一种可学习的纹理提取器。该纹理提取器是一个浅层的卷积神经网络,随着 Transformer 的训练,该提取器也在训练过程中不断更新自己的参数。该设计使得我们的纹理特征提取器能够提取到最适合图像生成任务的纹理信息,为后面的纹理搜索与迁移提供了很好的基础,进而更加有利于高质量结果的生成。
相关性嵌入模块。如图1所示,与传统的 Transformer 一样,本文提出的纹理 Transformer 同样具有 Q、K、V 要素。
其中 Q 为 Query,代表从低分辨率提取出的纹理特征信息,用来进行纹理搜索;K 为 Key,代表高分辨率参考图像经过先下采样再上采样得到的与低分辨率图像分布一致的图像的纹理信息,用来进行纹理搜索;V为 Value,代表原参考图像的纹理信息,用来进行纹理迁移。
对于 Q 和 K,本文提出了一个相关性嵌入模块来建立低分辨率输入图像和参考图像之间的关系。具体的,该模块将 Q 和 K 分别像卷积计算一样提取出特征块,然后以内积的方式计算 Q 和 K 中的特征块两两之间的相关性。内积越大的地方代表两个特征块之间的相关性越强,可迁移的高频纹理信息越多。反之,内积越小的地方代表两个特征块之间的相关性越弱,可迁移的高频纹理信息越少。
相关性嵌入模块会输出一个硬注意力图和一个软注意力图。其中,硬注意力图记录了对 Q 中的每一个特征块,K 中对应的最相关的特征块的位置;软注意力图记录了这个最相关的特征块的具体相关性,即内积大小。这两个图分别会应用到硬注意力模块和软注意力模块中。
硬注意力模块。在硬注意力模块中,我们利用硬注意力图中所记录的位置,从 V 中迁移对应位置的特征块,进而组合成一个迁移纹理特征图 T。T 的每个位置包含了参考图像中最相似的位置的高频纹理特征。T 随后会与骨干网络中的特征进行通道级联,并通过一个卷积层得到融合的特征。
软注意力模块。在软注意力模块中,上述融合的特征会与软注意力图进行对应位置的点乘。基于这样的设计,相关性强的纹理信息能够赋予相对更大的权重;相关性弱的纹理信息,能够因小权重得到抑制。因此,软注意力模块能够使得迁移过来的高频纹理特征得到更准确的利用。
跨层级特征融合
传统 Transformer 通过堆叠使得模型具有更强的表达能力,然而在图像生成问题中,简单的堆叠很难产生很好的效果。因此,本文为了进一步提升模型对参考图像信息的提取和利用,有针对性地提出了跨层级的特征融合机制。
我们将所提出的纹理Transformer 应用于 x1、x2、x4 三个不同的层级,并将不同层级间的特征通过上采样或带步长的卷积进行交叉融合。通过上述方式,不同粒度的参考图像信息会渗透到不同的层级,从而使得网络的特征表达能力增强,提高生成图像的质量。

图2:多个纹理 Transformer 跨层级堆叠模型
训练损失函数
本文的训练损失函数由三部分组成,分别为重建损失,对抗训练损失和感知损失,具体如下式所示:

重建损失。本文选取 L1 作为重建损失函数,相对于 L2,L1 可以得到更加清晰的结果图像,具体如下式所示:

对抗训练损失。相对于重建损失函数要求生成图像逐像素与原始图像一致,对抗训练损失函数相对约束较弱,仅要求生成图像与原始图像分布一致,进而能生成更加清晰、真实的纹理,其具体计算过程如下式所示:

感知损失。感知损失是施加在特定的预训练网络的特征空间中的一种特殊的“重建损失”。本文的感知损失分为两部分,第一部分选取了 VGG 网络作为结果图像与原始图像的特征提取网络;另一部分,选取了文中训练得到的纹理提取器网络作为结果图像的特征提取网络,与迁移特征T进行约束,具体如下式所示:
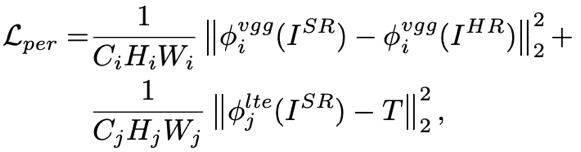
实验结果与分析
本文在 CUFED5、Sun80、Urban100、Manga109 数据集上针对文中提出的方法(TTSR)进行了量化的比较,具体如表1所示。
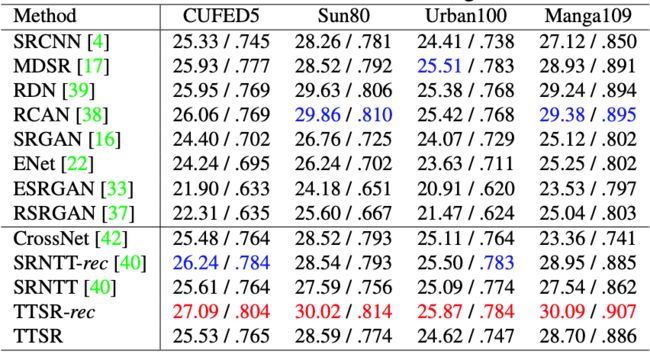
表1:本文提出的 TTSR 与现有方法在不同数据集上的量化比较结果
另一方面,本文还进行了用户调查,证实我们提出的方法在超过 90% 数据上取得了更好的结果,进一步证实了本文提出方法的有效性,具体如图3所示。
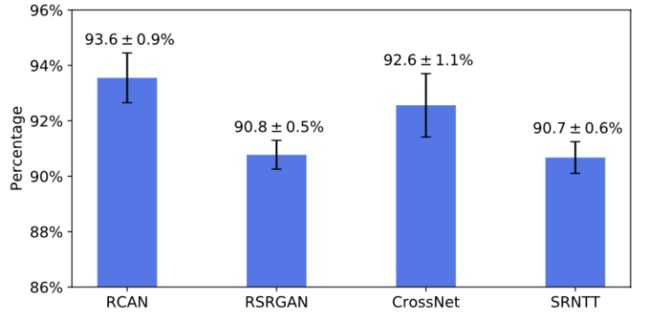
图3:用户调查结果
图4展示了本文提出的方法(TTSR)与现有的方法在不同数据集上的视觉比较结果,可以发现本文提出的方法显著领先于其他方法的结果。
图4:本文提出的 TTSR 与现有方法在不同数据集上的视觉比较结果
关于本文更多的技术细节,欢迎关注论文 “Learning Texture Transformer Network for Image Super-Resolution”。相关的代码和预训练模型将于近期公布在 GitHub 上。
论文链接:https://arxiv.org/abs/2006.04139
照片时空穿梭,
AI 技术助力老照片修复
最近,一段由 AI 修复的清朝北京影像在社交平台大火,视频修复后的老北京街头栩栩如生,让人仿佛置身于那个年代。相比于此前简单的依次应用去噪、去模糊等修复方法,微软亚洲研究院的研究员们提出了专门针对老照片或电影修复的端到端的神经网络处理方法,达到了目前最高质量的照片修复效果。该研究成果将在 CVPR 2020 发表口头报告。

图5:常见的老照片瑕疵非常复杂,包括破损、折痕、模糊、胶片噪声、泛黄等等。
与一般图像修复不同的是,老照片中往往包含多种瑕疵(如图5),且不同年代的图片由于摄影技术的不同,其畸变类型有着显著差异。这使得在合成数据集上训练得到的模型难以适应于实际老照片的修复。
与常见图片修复依赖配对监督信号不同,我们将老照片修复问题定义为在三个图片域之间的图片翻译(triplet domain translation):实际待修复老照片(X)、合成图像(R)以及无瑕疵高质量目标域图片(Y) 分别视为三个图片域,我们希望学习得到 X→Z 的映射(如图6)。其中,合成图片与目标域图片形成配对关系。

图6:三元域图像翻译框架(triplet domain translation)。X 为真实老照片域,R 为合成图片, Z 为无瑕疵高质量图片。
若直接利用合成数据集以及目标域图片的配对关系,训练得到的模型难以泛化到对真实老照片的处理。于是我们提出,将老照片与合成照片映射到同一个隐空间当中(Z_X ≈Z_R),之后通过学习隐空间映射 T_Z,将畸变图片映射到目标域图片的隐空间,即 Z_Y。该三元域图片翻译框架对于我们的真实照片修复有着若干优势。
首先,合成图片视觉上与真实老照片较为接近,二者的分布有着一定重叠,因而我们可以较容易地将它们映射到同一隐空间。在共有隐空间做图像修复,可以大大提高修复网络对于真实照片的泛化能力。
其次,相较于 CycleGAN 等无监督翻译方法,我们的半监督学习图片修复充分利用了合成数据集的配对监督,从而实现对真实老照片的高质量修复。
我们采用如图7的网络结构来实现三元域图像翻译。具体地,我们提出用两个变分自编码器(variational autoencoder,VAE)来分别得到两个隐空间 Z_X(≈Z_R)和Z_Y。第一个自编码器(VAE1)学习重建真实图片与合成图片,并在中间用一个对抗学习的判别网络将两种输入的隐空间对齐到同一空间。这里我们采用变分编码器而不是普通的自编码器,这是因为变分编码器假设隐空间满足高斯先验(Gaussian prior),因而图片的隐空间编码更为紧凑,两种输入域的分布更容易被拉近。
类似的,我们用第二个自编码器 VAE2 得到高质量目标图片的隐空间编码。之后,我们固定两个 VAE 的编解码器,利用合成图片与目标图片的显式配对关系(标识为红色框),学习一个额外的隐空间映射(蓝色虚线),以实现对图片的修复。

图7:老照片修复网络框架
此外,我们注意到老照片的瑕疵可以归类为局部损伤以及广泛性损伤。局部损伤有照片破损、污渍、划痕、褶皱等等,往往照片含有内容上的损坏,需要网络利用全局语义信息来实现修复;广泛性损伤指图片模糊、胶片噪声、颜色泛黄等整张照片均匀程度受到影响,修复仅需图片局部信息。
因而,我们的隐空间修复网络采用局部-全局视野融合,其中全局支路采用 nonlocal 模块大大增强处理视野。我们对局部破损图片建立了数据集,训练网络预测破损区域,该破损区域显式的送入 nonlocal 模块,并设置模块感受野为非破损区域(论文中称为 partial nonlocal 模块)。
至此,网络可以像修复合成图片一样,高质量的复原实际老照片。在我们的方法中,我们另外抠出照片中人脸部分,在人脸数据集上训练网络进一步优化人脸的细节。
我们将该方法和先前方法在实际照片上进行了对比。如图8所示,我们的方法达到了最真实、自然、清晰的修复结果。而这也在用户调查中得到了进一步验证。在若干组主观对比中,我们的方法有64.86%的几率被用户青睐。

图8:与不同种基线方法的对比
下面我们呈现更多的照片处理结果,该方法针对不同年代的图片均有理想的修复效果。

我们也收集了一些好莱坞影星的老照片进行了修复处理,让大家一睹明星们年少时的风采。


更多老照片修复的技术细节请详见我们的 CVPR 2020 论文 “Bringing Old Photo Back to Life” 。
论文链接:https://arxiv.org/abs/2004.09484
微软亚洲研究院有着更多类似的有趣的技术。在此前的 CVPR 论文中,我们就曾提出黑白视频的自动上色技术。下面是一段对电影的上色结果。
论文链接:https://arxiv.org/abs/1906.09909
本文介绍的图像超分别率技术将于近期上线 PowerPoint,未来也将会有更多图像修复相关的技术集成进微软 Office 的多项产品之中。相信我们在图片修复方面的努力,以及这一系列技术的融合将为我们感知的世界赋予更多的美好。
END

备注:超分辨率

超分辨率交流群
图像视频超分辨率,可见光、红外、遥感超分辨率等技术,
若已为CV君其他账号好友请直接私信。
我爱计算机视觉
微信号:aicvml
QQ群:805388940
微博知乎:@我爱计算机视觉
网站:www.52cv.net

在看,让更多人看到 