TensorFLow 模型在移动端的部署
文章目录
- 一、简介
- 二、整体流程
- 1、环境配置
- 2、从训练模型生成推理模型
- 3、找出 `input_node_names` 和 `output_node_names`
- 4、Freeze 模型
- 5、Optimize 模型
- 6、Visualize and Infer From PB
- (a)、Visualize From PB
- (b)、Infer From PB
- 三、参考资料
一、简介
- 深度学习在图像处理、语音识别、自然语言处理领域的应用取得了巨大成功,但是它通常在功能强大的服务器端进行运算。如果移动终端(比如,手机)通过网络远程连接服务器,也可以利用深度学习技术,但这样可能会很慢,而且只有在设备处于良好的网络连接环境下才行,这样需要把深度学习模型迁移到移动终端。由于移动终端 CPU 和内存资源有限,为了提高运算性能和内存利用率,需要对服务器端的模型进行
量化处理和支持低精度算法。
- Freeze 必要性:
- 使用
tf.train.Saver()会保存程序所需要的全部信息,然而有时候并不需要某些信息。比如:在测试或者离线预测时,只需要知道如何从神经网络的输入层经过前向传播计算得到输出层即可,而不需要类似变量初始化、模型保存等辅助节点。
- 使用
- Freeze 操作:
- 将变量取值(
checkpoint/*.data)和计算图结构(checkpoint/*.meta)分成不同的文件存储有时候也不方便,幸好 TensorFlow 提供了convert_variables_to_constants函数,通过此函数可以将计算图中的变量及其取值通过常量的方式保存,这样变量取值和计算图结构就可以统一存放在一个文件中了 - Const ops store their values as part of the
NodeDef, so if all the Variable weights are converted to Const nodes, then we only need a singleGraphDeffile to hold the model architecture and the weights
- 将变量取值(
- Optimize 工具:
- 为了进一步减少移动终端上模型文件的大小,TensorFlow提供的 Tranform Graph Tool 可以移除前向推断期间未调用的所有节点、优化批量归一化中的乘法操作、对模型文件进行量化处理(Quantized 操作)等。
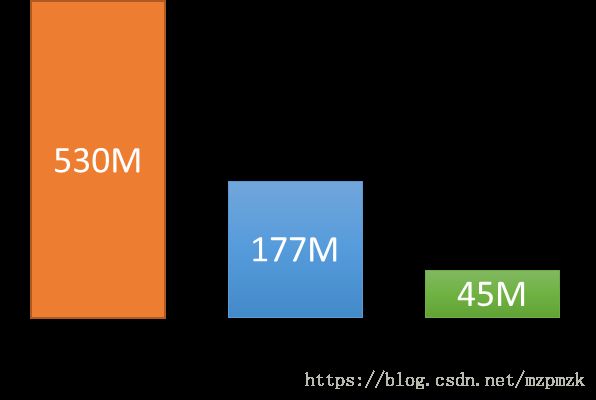
- 先来看一下 AlexNet 经过 Freeze 和 Quantized处理后的文件大小变化:
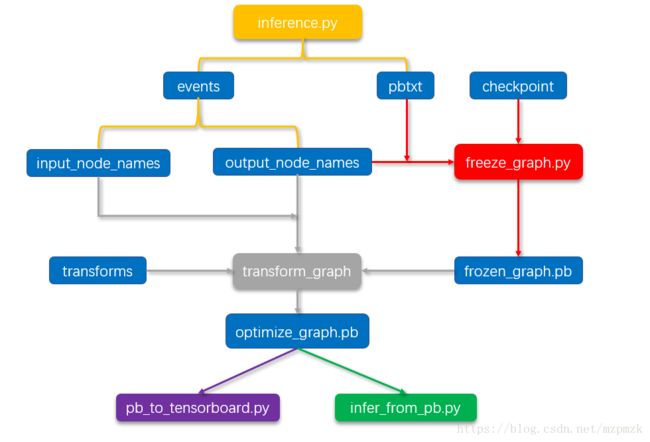
二、整体流程
1、环境配置
- 首先,在 ubuntu 下安装谷歌开源的自动化构建工具 bazel,用于后面的编译
- 然后,从 Github 上下载 tf >=1.5 版本的 tensorflow 源码,可使用其中的工具进行 freeze & optimize
- 安装所需的包
sudo apt-get install pkg-config zip g++ zlib1g-dev unzip python- 下载 Bazel
- 在 Bazel releases page on GitHub 上下载形如
bazel-的文件-installer-linux-x86_64.sh - 修改文件权限并执行安装
chmod +x bazel--installer-linux-x86_64.sh ./bazel--installer-linux-x86_64.sh --user --user标志表示: Bazel 安装在$HOME/bin目录下, 并将.bazelrc安装在$HOME/.bazelrc- 在
~/.bashrc最后添加可执行文件的路径
export PATH="$PATH:$HOME/bin"git clone https://github.com/tensorflow/tensorflow.git
2、从训练模型生成推理模型

- 将 Inference Graph 写入 summary 中去,生成
events文件。注意: 可以在此步先手动去掉一些推理不需要的节点(损失节点、优化节点等)events文件用于从 tensorboard 可视化计算图中找出input_node_names和output_node_namesinput_node_names和output_node_names用于后面的 Freeze 和 Optimize 操作
- 生成文本格式 Inference Graph 的
pbtxt文件- 用于后面的 Freeze 操作
inference.py代码如下所示
# -*- coding: utf-8 -*-
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import os
import tensorflow as tf
from tensorflow.python.framework import graph_io
import model_predict_only_with_color_placeholder as model
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
TIME_STEP = 40
CHAR_LEN = 8
TEST_FILENAME = '川BFJ761蓝_87.jpg'
FLAGS = tf.app.flags.FLAGS
tf.app.flags.DEFINE_integer("height", 48, "The height of image to use. [48]")
tf.app.flags.DEFINE_integer("width", 160, "The width of image to use. [160]")
tf.app.flags.DEFINE_integer("depth", 3, "Dimension of image color. [3]")
tf.app.flags.DEFINE_string("test_dir", "", "Directory of test images.")
tf.app.flags.DEFINE_string("checkpoint_dir", "", "Directory name to save the checkpoints [checkpoint]")
tf.app.flags.DEFINE_string("name", "", "Model name. [4w_grtr_lr0.01_78]")
TRANS_TABLE_REVERSE = {0: "0", 1: "1", 2: "2", 3: "3", 4: "4", 5: "5", 6: "6", 7: "7", 8: "8",
9: "9", 10: "A", 11: "B", 12: "C", 13: "D", 14: "E", 15: "F", 16: "G",
17: "H", 18: "I", 19: "J", 20: "K", 21: "L", 22: "M", 23: "N", 24: "O",
25: "P", 26: "Q", 27: "R", 28: "S", 29: "T", 30: "U", 31: "V", 32: "W",
33: "X", 34: "Y", 35: "Z", 36: "藏", 37: "川", 38: "鄂", 39: "甘",
40: "赣", 41: "贵", 42: "桂", 43: "黑", 44: "沪", 45: "吉", 46: "冀",
47: "津", 48: "晋", 49: "京", 50: "辽", 51: "鲁", 52: "蒙", 53: "闽",
54: "宁", 55: "青", 56: "琼",57: "陕", 58: "苏", 59: "皖", 60: "湘",
61: "新", 62: "渝", 63: "豫", 64: "粤", 65: "云", 66: "浙", 67: "使",
68: "警", 69: "港", 70: "澳", 71: "学", 72: "领", 73: "挂", 74: "蓝",
75: "黄", 76: "白", 77: "特"}
def label_to_str(label):
label = label[0] # extract the first dimension(decoded label)
license_number = ""
for a_char in label:
license_number += TRANS_TABLE_REVERSE[a_char]
return license_number
def main(argv=None):
# read&convert image type
image_filename = os.path.join(FLAGS.test_dir, TEST_FILENAME)
image_raw_data = tf.read_file(image_filename)
img_data = tf.image.decode_jpeg(image_raw_data)
if img_data.dtype != tf.float32:
img_data = tf.image.convert_image_dtype(img_data, dtype=tf.float32)
# image preprocess
img_data = tf.image.resize_images(img_data, [48, 160])
img_data.set_shape([FLAGS.height, FLAGS.width, FLAGS.depth])
image = tf.image.per_image_standardization(img_data)
image = tf.expand_dims(image, 0)
# build the model
Model = model.Model(image)
output_label = Model.decode
init_op = tf.group(tf.global_variables_initializer(), tf.local_variables_initializer())
saver = tf.train.Saver()
with tf.Session() as sess:
sess.run(init_op)
model_path = os.path.join(FLAGS.checkpoint_dir, FLAGS.name)
saver.restore(sess, model_path)
output_label_eval = sess.run(output_label)
# used for finding input_node_names & output_node_names
writer = tf.summary.FileWriter('graphs/', sess.graph)
writer.close()
# used for graph frezee later
graph_io.write_graph(sess.graph, './pbtxt', "temp_input_graph.pbtxt", as_text=True)
# num2plate
license_number = label_to_str(output_label_eval)
print(license_number)
if __name__ == '__main__':
tf.app.run()
3、找出 input_node_names 和 output_node_names
-
第一步中我们已经将计算图写入
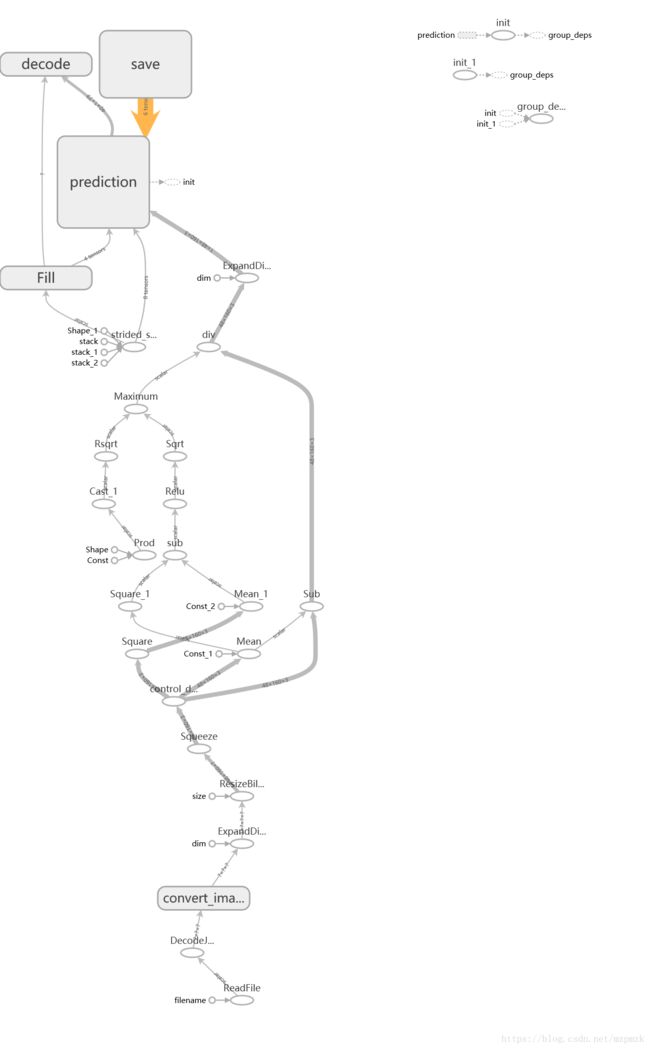
graphs中的events,所以我们只需要在 tf 环境中(conda activate tf) 执行tensorboard --logdir graphs即可 -
先看一下 Freeze 和 Optimize 前的计算图,可以看到还是有很多前向推断不需要的节点(比如,
init、save节点等)
-
输入节点: 选择计算图中的第一个数据输入节点,一般为卷积层的输入(忽略
weights和biases),这里为ExpandDims_1- 注意 1: 可忽略一些预处理过程,因为移动端的应用通常是从传感器获取数据并以数组的形式存储
- 注意 2: 注意一下输入数据的
shape后面Optimize的时候会用到
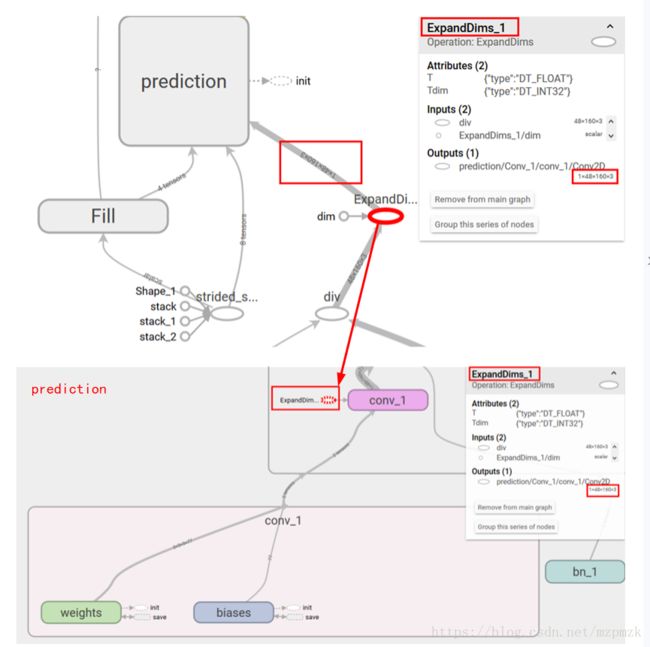
-
输出节点: 选择计算图中最后的输出节点,这里为
decode/SparseToDense- 注意 1: 有时候网络的输出节点不只一个,比如说 MTCNN 检测的输出节点就有三个(分类节点、bbox 回归节点、landmark 预测节点)
- 注意 2: 节点之间以
逗号分割,以字符串的形式传入
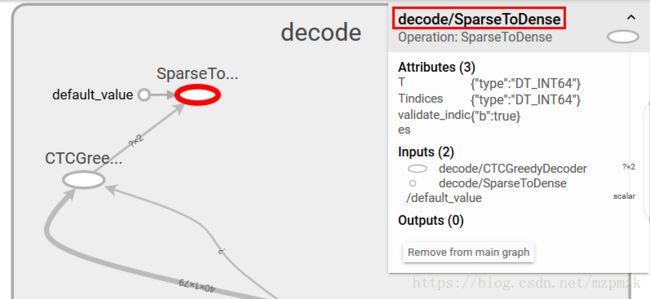
-
另外我们可以使用
summarize_graph检查可能的输入输出节点以及其它信息
# build summarize_graph
bazel build tensorflow/tools/graph_transforms:summarize_graph
# inspect the model and provide guesses about likely input and output nodes, as well as other information
bazel-bin/tensorflow/tools/graph_transforms/summarize_graph --in_graph=temp_input_graph.pbtxt
4、Freeze 模型
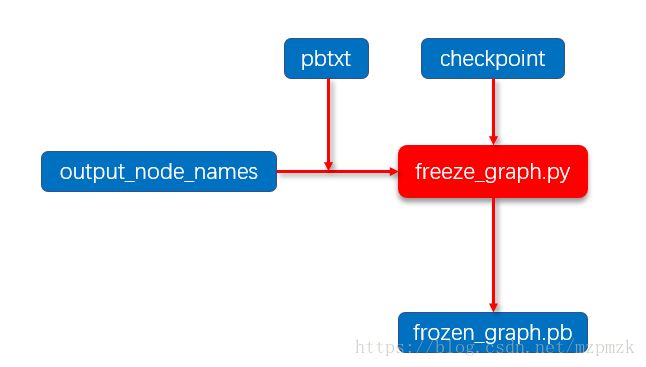
- 结合
checkpoint文件、Inference Graph pbtxt文件以及output_node_names,将计算图中的变量及其取值通过常量的方式保存同时将图中不必要的节点去掉(Freeze 操作),使得变量取值和计算图结构就可以统一存放在一个frozen_graph.pb文件中。- 注意:
output_node_names(以逗号分隔)、checkpoint 只需写到model的prefix即可
# 结合 CheckPoint 文件和 Inference GraphPB 文件,生成 frozen_graph.pb
python freeze_graph.py --input_graph=./pbtxt/temp_input_graph.pbtxt --input_checkpoint=checkpoint/4w_grtr_lr0.01_with_color/4w_grtr_lr0.01_with_color --output_graph=frozen_graph.pb --output_node_names="decode/SparseToDense"
- 只加载计算图中保存的节点
# 只加载计算图中保存的节点
var_list = {}
# 可以读取 checkpoint 文件中保存的所有变量
reader = tf.train.NewCheckpointReader(input_checkpoint)
# 获取所有变量列表,这是一个从变量名到变量维度的字典
var_to_shape_map = reader.get_variable_to_shape_map()
for key in var_to_shape_map:
try:
# 通过张量名称获取张量
tensor = sess.graph.get_tensor_by_name(key + ":0")
except KeyError:
# This tensor doesn't exist in the graph (for example it's
# 'global_step' or a similar housekeeping element) so skip it.
continue
var_list[key] = tensor # 张量名到张量的字典
saver = tf.train.Saver(var_list=var_list)
saver.restore(sess, input_checkpoint)
- Freeze 过后的计算图,可以看出已经去除了很多冗余的节点,但还是有一些冗余的预处理过程是前向推断所不需要的
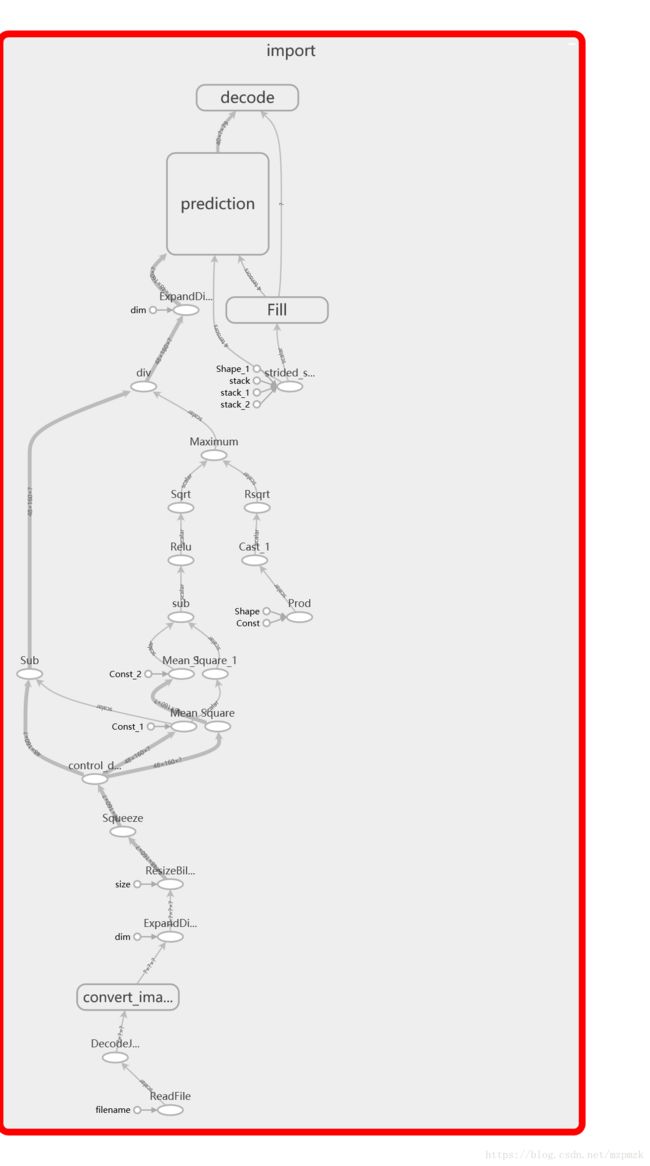
5、Optimize 模型
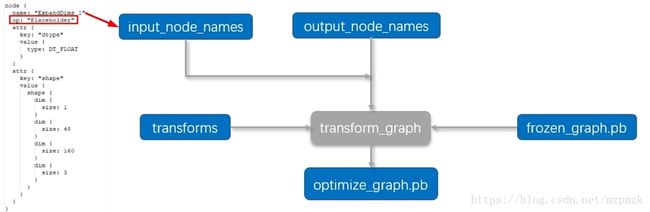
- 使用TensorFlow Tranform Graph Tool 中的
transform_graph对模型进行优化。
- 注意1: 若输入节点不是
Placeholder,系统会自动将其替换为Placeholder节点,后续在infer_from_pb.py中数据的输入直接喂给ExpandDims_1:0即可,这个在infer_from_pb.py程序中会用到- 注意2: 在
transforms中要指定strip_unused_nodes输入数据的类型和形状
"""
removes all of the nodes that aren't called during inference, shrinks expressions that are always constant into single nodes, and optimizes away some multiply operations used during batch normalization by pre-multiplying the weights for convolutions.
"""
# 编译一下相应的工具
bazel build tensorflow/tools/graph_transforms:transform_graph
# 执行优化程序
bazel-bin/tensorflow/tools/graph_transforms/transform_graph \
--in_graph=frozen_graph.pb \
--out_graph=optimized_graph.pb \
--inputs='ExpandDims_1' \
--outputs='decode/SparseToDense' \
--transforms='
strip_unused_nodes(type=float, shape="1,48,160,3")
remove_nodes(op=Identity, op=CheckNumerics)
fold_constants(ignore_errors=true)
fold_batch_norms
fold_old_batch_norms
'
# 执行优化程序(把图像标准化节点写入pb,同时输入变为 3 维)
bazel-bin/tensorflow/tools/graph_transforms/transform_graph \
--in_graph=113w_grtr_half_size_frozen_graph_ud_acc_9818.pb \
--out_graph=113w_grtr_half_size_1line_optimized_graph_ud_acc_9818.pb \
--inputs='Squeeze' \
--outputs='decode/SparseToDense' \
--transforms='
strip_unused_nodes(type=float, shape="24,80,3")
remove_nodes(op=Identity, op=CheckNumerics)
fold_constants(ignore_errors=true)
fold_batch_norms
fold_old_batch_norms
'
# 可选择 quantize_weights、sort_by_execution_order 加入 transforms 对模型进行量化处理、按照执行顺序排列节点等
6、Visualize and Infer From PB

(a)、Visualize From PB
- 使用Tensorflow 转换工具
import_pb_to_tensorboard.py查看最终优化后的 pb 文件计算图模型。
# 读取优化后的 pb 文件,并将其写入 graph summary
python import_pb_to_tensorboard.py --model_dir=optimized_graph.pb --log_dir=logs
# 查看优化后的计算图模型
tensorboard --logdir logs
- 优化过后的计算图如下所示:
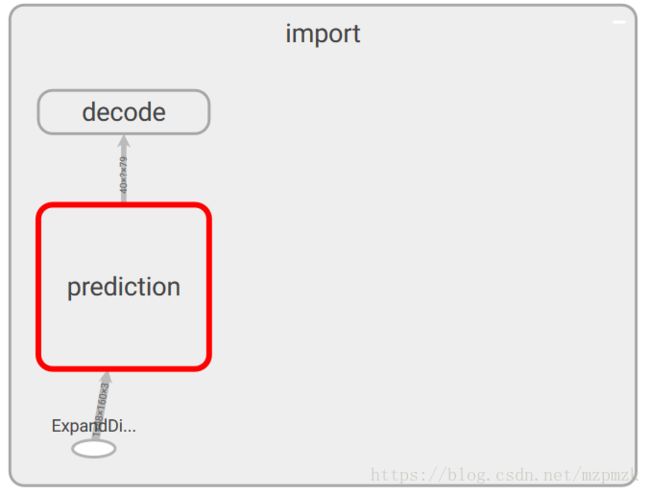
(b)、Infer From PB
- 我们可以直接从优化后的PB文件进行前向推断,代码如下所示。为了方便前端移植验证结果,我们这里可以指定需要获取张量的名称(如:
out_tensor_name),当要验证其它节点时,可以先通过tf.get_default_graph().get_operations()获取所有节点的名称,然后将需要验证的节点的名称替换out_tensor_name即可- 注意:经过
transform_graph处理后系统会自动将节点ExpandDims_1的类型替换为Placeholder,所以我们可以直接将数据的输入喂给ExpandDims_1:0即可
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import tensorflow as tf
from tensorflow.python.platform import gfile
model_path = 'optimized_graph.pb'
input_tensor_name = 'ExpandDims_1:0'
output_tensor_name = 'decode/SparseToDense:0'
TRANS_TABLE_REVERSE = {0: "0", 1: "1", 2: "2", 3: "3", 4: "4", 5: "5", 6: "6", 7: "7", 8: "8",
9: "9", 10: "A", 11: "B", 12: "C", 13: "D", 14: "E", 15: "F", 16: "G",
17: "H", 18: "I", 19: "J", 20: "K", 21: "L", 22: "M", 23: "N", 24: "O",
25: "P", 26: "Q", 27: "R", 28: "S", 29: "T", 30: "U", 31: "V", 32: "W",
33: "X", 34: "Y", 35: "Z", 36: "藏", 37: "川", 38: "鄂", 39: "甘", 40: "赣",
41: "贵", 42: "桂", 43: "黑", 44: "沪", 45: "吉", 46: "冀", 47: "津", 48: "晋",
49: "京", 50: "辽", 51: "鲁", 52: "蒙", 53: "闽", 54: "宁", 55: "青", 56: "琼",
57: "陕", 58: "苏", 59: "皖", 60: "湘", 61: "新", 62: "渝", 63: "豫", 64: "粤",
65: "云", 66: "浙", 67: "使", 68: "警", 69: "港", 70: "澳", 71: "学", 72: "领",
73: "挂", 74: "蓝", 75: "黄", 76: "白", 77: "特"}
def label_to_str(label):
label = label[0] # extract the first dimension(decoded label)
license_number = ""
for a_char in label:
license_number += TRANS_TABLE_REVERSE[a_char]
return license_number
if __name__ == '__main__':
# build inference graph
with tf.Graph().as_default() as g:
with gfile.FastGFile(model_path, 'rb') as f:
graph_def = tf.GraphDef()
graph_def.ParseFromString(f.read())
# 将 graph_def 中保存的图加载到当前图中,并返回指定张量名称的张量
input_tensor, out_tensor = tf.import_graph_def(graph_def,
return_elements=[input_tensor_name, output_tensor_name])
# read&convert image type
image_path_placeholder = tf.placeholder(tf.string, name='image_path')
file_contents = tf.read_file(image_path_placeholder)
image_raw = tf.image.decode_jpeg(file_contents)
if image_raw.dtype != tf.float32:
image_raw = tf.image.convert_image_dtype(image_raw, dtype=tf.float32)
# image preprocess
img_pre = tf.image.resize_images(image_raw, [48, 160])
img_pre.set_shape([48, 160, 3])
img_pre = tf.image.per_image_standardization(img_pre)
image_input = tf.expand_dims(img_pre, 0)
with tf.Session().as_default() as sess:
imgpath = 'test_placeholder/川BFJ761蓝_87.jpg'
img = sess.run(image_input, feed_dict={image_path_placeholder: imgpath})
output_label = sess.run(out_tensor, feed_dict={input_tensor: img})
# f_2 = open('output_value.txt', 'w')
# for op in g.get_operations():
# # print(op.name, op.values())
# node_list.append(str(op.name)[7:] + ':0')
# f_2.write(str(node_list))
# f_2.close()
# num2plate
license_number = label_to_str(output_label)
print(license_number)
三、参考资料
1、https://www.tensorflow.org/mobile/prepare_models
2、https://github.com/tensorflow/tensorflow/tree/master/tensorflow/tools/graph_transforms
3、深度学习利器:TensorFlow在智能终端中的应用
4、http://cv-tricks.com/how-to/freeze-tensorflow-models/
5、https://www.tensorflow.org/extend/tool_developers
6、https://www.tensorflow.org/extend/tool_developers/translated