模型压缩论文解读1:(MobileNets解读)Efficient Convolutional Neural Networks for Mobile ...
一、番外说明
大家好,我是小P,今天给大家带来深度模型压缩经典文献MobileNets的解读,关于轻量化模型的介绍,资料齐全。
此外,对“目标检测/模型压缩/语义分割”感兴趣的小伙伴,欢迎加入QQ群 813221712 讨论交流,进群请看群公告!
点击链接加入群聊【Object Detection】:https://jq.qq.com/?_wv=1027&k=5kXCXF8
二、资料推荐
注:为方便下载,部分资源已上传百度网盘,点击即可下载,若网盘失效,望告知!
①论文原著下载:https://pan.baidu.com/s/1KaOZgoIJ1-Qn2NdVjz1nnA
②中英对照翻译:https://pan.baidu.com/s/157USvAuZMtJMPFv5NXtGag
③官方源码地址:https://github.com/Zehaos/MobileNet
④其他版本代码:https://github.com/marvis/pytorch-mobilenet
三、基础知识
1、卷积原理理解
数字图像是一个二维的离散信号,对数字图像做卷积操作其实就是利用卷积核(卷积模板)在图像上滑动,将图像点上的像素灰度值与对应的卷积核上的数值相乘,然后将所有相乘后的值相加作为卷积核中间像素对应的图像上像素的灰度值,并最终滑动完所有图像的过程。

这张图可以清晰的表征出整个卷积过程中一次相乘后相加的结果:该图片选用3*3的卷积核,卷积核内共有九个数值,所以图片右上角公式中一共有九行,而每一行都是图像像素值与卷积核上数值相乘,最终结果-8代替了原图像中对应位置处的1。这样沿着图片一步长为1滑动,每一个滑动后都一次相乘再相加的工作,我们就可以得到最终的输出结果。除此之外,卷积核的选择有一些规则:
1)卷积核的大小一般是奇数,这样的话它是按照中间的像素点中心对称的,所以卷积核一般都是3x3,5x5或者7x7。有中心了,也有了半径的称呼,例如5x5大小的核的半径就是2。
2)卷积核所有的元素之和一般要等于1,这是为了原始图像的能量(亮度)守恒。其实也有卷积核元素相加不为1的情况,下面就会说到。
3)如果滤波器矩阵所有元素之和大于1,那么滤波后的图像就会比原图像更亮,反之,如果小于1,那么得到的图像就会变暗。如果和为0,图像不会变黑,但也会非常暗。
4)对于滤波后的结构,可能会出现负数或者大于255的数值。对这种情况,我们将他们直接截断到0和255之间即可。对于负数,也可以取绝对值。
上述二维卷积的动态过程可以表示为下图所示:

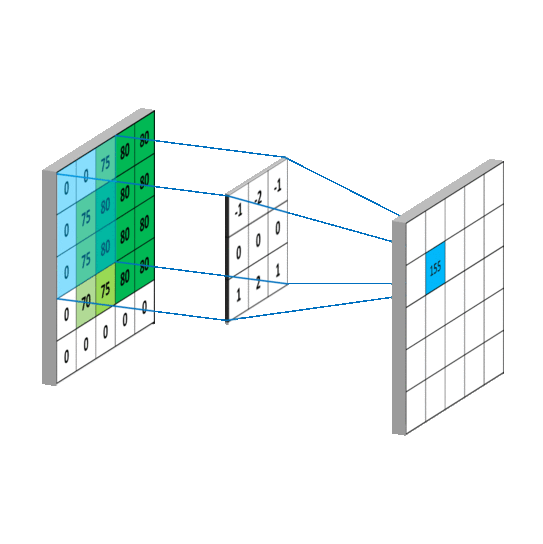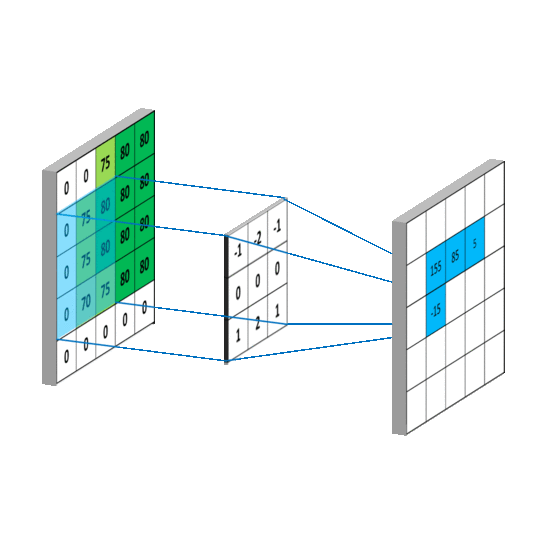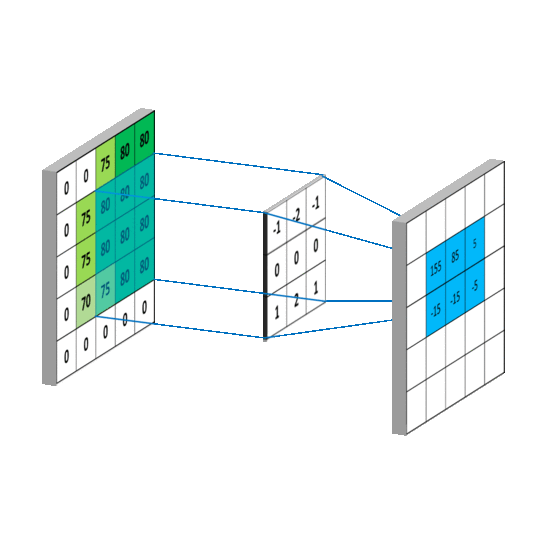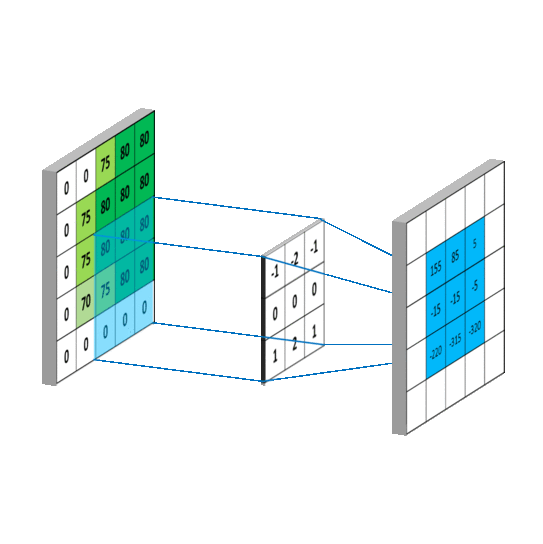
同样可以观测三维卷积的动态过程:

如上图所示:输入特征图的维度为5×5×3,其中5×5表示特征图的空间尺寸(width,height),3表示特征图的深度信息,也就是通道数,使用卷积核为3×3×3×2,左边的3×3表示进行二维卷积运算的卷积核的尺寸,由3×3=9个数构成一个二维矩阵式的卷积核,右边的3对应输入特征图的深度(通道数),2为卷积运算后的输出通道数。
注意(敲黑板)
①该层卷积层的参数量为:3×3×3×2=54,该卷积核分为2组,每一组的尺寸为3×3×3
②在输入特征图的深度维度上的每个二维矩阵上的卷积过程相当于滤波,然后对滤波过后的结果进行求和相当于跨通道的信息融合,所以一个标准卷积的过程兼有滤波和融合的效果。
2、常用的模型压缩的方法
这个知识点比较宽,想要详细理解的参考 https://www.cnblogs.com/kexinxin/p/9858743.html
四、论文解读
1、本文的应用背景
①、DNN模型的总体设计趋势是越来越深,越来越复杂,过大的模型和算力需求阻碍了模型向移动应用端移植的步伐。
②、在诸如机器人、自动驾驶汽车和增强现实等许多现实应用中需要在计算有限的平台上及时地执行识别任务。
③、许多关于轻量化网络的论文只关注模型大小但不考虑速度(模型小的不一定运算量就少)
2、本文亮点
①、使用深度可分离卷积替换了原来的标准卷积,训练了模型MobileNets,在许多公开数据集上取得了不错的效果。深度可分离卷积其实并不是本文所提出的。
②、引入了两个超参数:宽度系数和分辨率系数,宽度系数在每层均匀地稀疏网络,分辨率系数通过控制输入网络图像的分辨率大小降低网络的运算成本。
③、将上述两点应用到了不同的实际应用中,做了丰富的实验(咱们写论文其实也可以堆很多的实验,增加工作量 \笑哭)
3、论文核心内容
第一点:MobileNet的网络架构
这个没什么好说的,直接看图,有个直观的了解即可
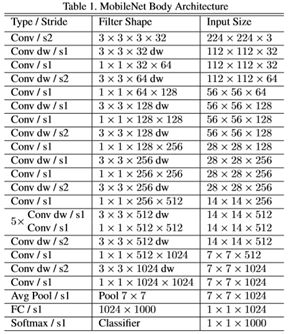
第二点:如何将将标准卷积分解为“深度卷积+1×1的逐点卷积”
主体思想:MobileNet模型基于深度可分离卷积,这是一种因式分解的卷积形式,它将标准卷积分解为深度卷积和称为逐点卷积的1×1卷积。
对于MobileNets,深度卷积将单个滤波器应用于每个输入通道。 然后,逐点卷积应用1×1卷积来组合输出的深度卷积【通道信息融合】。
标准卷积可以在一个步骤中完成滤波并将输入组合成一组新的输出。 深度可分离卷积将其分成两层,一个用于滤波的单独层和一个用于组合的单独层。



标准卷积层(图a所示)以DF×DF×M维度的特征图F作为输入并生成DK×DK×N的特征图G
其中DF是方形输入特征图的空间宽度和高度,M是输入通道的数量(输入深度)
DK是方形输出特征图的空间宽度和高度,N是输出通道的数量(输出深度)
图(a)中标准卷积的计算量为:
图(b)(c)表示将图(a)的标准卷积分解的 “深度卷积” 和 “1×1卷积”
其中图(b)的深度卷积为输入特征图DF×DF×M的每一个通道(深度)应用二维卷积运算,得到DK×DK大小的特征图,一共M个(此时是一个输入通道对应一个输出通道,没有融合)
图(b)中深度卷积的计算量为:
图(c)表示将图(b)深度卷积后得到的DK×DK×M的特征图应用1×1×M的卷积进行跨通道的信息融合,一共应用N次,所以图(c)中卷积核的尺寸为1×1×M×N,生成的特征图的尺寸为DK×DK×N
图(c)中1×1卷积的计算量为:
注意:图片来自论文,其中公式有误,上式的DF应该为DK,将上式带如下面的(5)也要变化
综合b和c,两步总的计算量为:
分解后的卷积的运算量占原先标准卷积运算量的比率为:

可以看出,经过图(b)的深度卷积和图(c)的1×1卷积,处理DF×DF×M的特征图时,能和图(a)的标准卷积得到同样的输出特征图DK×DK×N,而且完成了同样的功能(滤波+信息融合)
下面举一个实际例子演示上述分解过程
特别感谢:以下部分图片和内容引自博主:DFann 地址:https://blog.csdn.net/u011974639/article/details/79199306
原博主的图实在画得太美妙了,手残的我尝试了N次后只能放弃 ????????????

黑色的输入为(6,6,3)与第n 个卷积核对应,每个通道对应每个卷积核通道卷积得到输出,最终输出为2+0+1=3。(这是常见的卷积操作,注意这里卷积核要和输入的通道数相同,即图中表示的3个通道~)
对于深度分离卷积,把标准卷积(4,4,3,5)分解为:
深度卷积部分:大小为(4,4,1,3),作用在输入的每个通道上,输出特征映射为(3,3,3)
逐点卷积部分:大小为(1,1,3,5),作用在深度卷积的输出特征映射上,得到最终输出为(3,3,5)
例中深度卷积卷积过程示意图如下:

输入有3个通道,对应着有3个大小为(4,4,1)的深度卷积核,卷积结果共有3个大小为(3,3,1),我们按顺序将这卷积按通道排列得到输出卷积结果(3,3,3)。
相比之下计算量减少了:
4×4×3×5 转为了4×4×1×3+1×1×3×5 ,即参数量为原来的:

同样的可以计算运算量变为原来的:
6 × 6 × 3 × 4 × 4 + 3 × 3 × 3 × N 6 × 6 × 3 × 4 × 4 × N \frac{6×6×3×4×4+3×3×3×N}{6×6×3×4×4×N} \quad 6×6×3×4×4×N6×6×3×4×4+3×3×3×N
注意:
①、如果输出通道N为1时反而增加了计算量,但实际情况中往往输出通道不为1
②、MobileNet使用可分离卷积减少了8到9倍的计算量,只损失了一点准确度。
③、在MobileNet中,标准卷积后接的BN和RELU激活函数经分解后在深度卷积和1×1卷积后面均有,如图所示:

第三点:超参数宽度系数α的使用
虽然MobileNet基础架构已经很小且延迟很低,但是很多时候特定用例或应用程序可能要求模型更小更快。 为了构造这些更小且计算量更小的模型,我们引入了一个非常简单的参数α,称为宽度系数。 宽度系数α的作用是在每层均匀地稀疏网络。 对于给定的层和宽度系数α,输入通道M的数量变为αM,输出通道的数量N变为αN。
引入宽度系数α后计算量变为:
其中α∈(0,1],典型值为1,0.75,0.5和0.25.α= 1是基础的MobileNet,α<1的时候构建更简化的MobileNets。宽度乘数具有降低计算成本和参数数量的效果,参数量大致减少为1/α2。
第三点:超参数分辨率系数β的使用
降低神经网络计算成本的第二个超参数是分辨率系数ρ。 将其应用于输入图像,并且每个层的内部表示随后减少相同的倍数。 在实践中,通过设置输入图像的分辨率隐式地设置ρ。引入β后计算量变为:
中ρ∈(0,1),通常是隐式设置的,网络的输入分辨率通常为224,192,160或128.ρ= 1是基本的MobileNet,ρ<1是减少计算的MobileNets。分辨率系数能降低计算成本ρ2倍。
4、实验分析
实验一:模型的选择
使用深度分类卷积的MobileNet与使用标准卷积的MobileNet之间对比:

从上图可以看出:MobileNet的精度仅降低了1%,但运算量几乎变为1/9,参数量也变为1/8
下图进一步比较了使用宽度系数简化模型与将MobileNet中的5层14×14×512 的深度可分离卷积去除来浅化模型的结果:

可以看出:使用宽度系数α得到的模型比直接浅化得到的模型精度更高,参数量和运算量也更少。
实验二:关于宽度系数α和分辨率系数β的实验
表6显示了使用宽度系数α后缩小的MobileNet架构的准确性,计算和大小权衡。 精度随着α的减小平滑下降,直到在α= 0.25时由于结构太小而下降很多。

表7显示了通过使用不同分辨率系数β训练具有降低的输入分辨率MobileNets的精度,计算量和参数大小的权衡。 精度在分辨率降低时平滑下降。

为了更详尽地说明问题,还对宽度系数α和分辨率系数β之间不同组合地实验进行了比较,结果见下图:


其中阿尔法取值:α ∈ {1,0.75,0.5,0.25},β取值:{224,192,160,128}
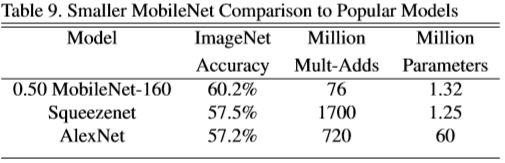
随后将MobileNet与VGG和GoogleNet进行了比较,同时用使用宽度系数和分辨率系数得到地模型与SqueezeNet和AlexNet进行了比较,实验结果见下表,不多赘述:

实验三:细粒度识别实验
在Stanford Dogs数据集上训练MobileNet进行细粒度识别。从网上收集了更大但嘈杂的训练集。 使用嘈杂的网络数据预先训练细粒度识别狗的模型,然后在Stanford Dogs训练集上微调模型。Stanford Dogs测试集的结果见表10.MobileNet几乎可以在大大减少计算量和模型尺寸的情况下实现不错的结果。

实验四:大规模地理定位
PlaNet是做大规模地理分类任务,我们使用MobileNet的框架重新设计了PlaNet,对比如下:

PlaNet模型拥有5200万个参数和57.4亿个乘加操作。 MobileNet模型只有1300万个参数,通常是网络主体300万个参数,最终层1000万个参数和58万个乘加操作。 如表格11所示,与PlaNet相比,MobileNet版本的性能略有下降,但是更紧凑。 而且,它仍然极大地优于Im2GPS。
实验五:Face Attributes实验
MobileNet的框架技术可用于压缩大型模型,在Face Attributes任务中,我们验证了MobileNet的蒸馏(distillation )技术的关系,蒸馏的核心是让小模型去模拟大模型,而不是直接逼近Ground Label:

将蒸馏技术的可扩展性和MobileNet技术的精简性结合到一起,最终系统不仅不需要正则技术(例如权重衰减和退火等),而且表现出更强的性能。
实验六:关于目标检测的实验
在表13中,MobileNet与以VGG和Inception V2 为骨干网络的Faster-RCNN 和SSD 框架进行了比较。 在我们的实验中,SSD使用300作为输入分辨率(SSD 300)进行评估,并将Faster-RCNN与300和600作为输入分辨率(Faster RCNN 300,Faster-RCNN 600)进行比较。 Faster-RCNN模型每个图像评估300个RPN提议框。 这些模型在COCO train + val上训练,拿出了8k的minival,并在minival上进行评估。 对于这两个框架,MobileNet实现了与其相当的结果,但是计算复杂性和模型大小相当少。

实验七:Face Embeddings实验
为了构建移动FaceNet模型,我们使用蒸馏来训练,从而使得FaceNet和MobileNet的输出在训练数据上的平方差最小。 可以在表14中看到, MobileNet的模型非常小。

五、源码推荐
参考网站 https://github.com/Zehaos/MobileNet 进行实验即可
六、致谢:
https://github.com/Zehaos/MobileNet
https://blog.csdn.net/u011974639/article/details/79199306
https://www.jianshu.com/p/854cb5857070
https://blog.csdn.net/t800ghb/article/details/78879612