Intellij IDEA使用Maven搭建spark开发环境(scala)
如何一步一步地在Intellij IDEA使用Maven搭建spark开发环境,并基于scala编写简单的spark中wordcount实例。
1.准备工作
首先需要在你电脑上安装jdk和scala以及开发工具Intellij IDEA,本文中使用的是win7系统,环境配置如下:
jdk1.7.0_15
scala2.10.4
scala官网下载地址:http://www.scala-lang.org/download/
如果是windows请下载msi安装包。
这两个可以在官网上下载jdk和scala的安装包就可以直接双击安装包运行安装即可。注意:如果以后是在本地编写好spark代码然后上传到spark集群上去运行的话,请一定保持两者的开发环境一致,不然会出现很多错误。
Intellij IDEA
在官网上下载一般选择右下角的Community版本,下载地址https://www.jetbrains.com/idea/download/#section=windows
2.在Intellij IDEA中安装scala插件
安装好Intellij IDEA并进入idea的主界面
(1)找到右下角的Configure选项中Plugins并打开 
(2)点击左下角Browse repositories… 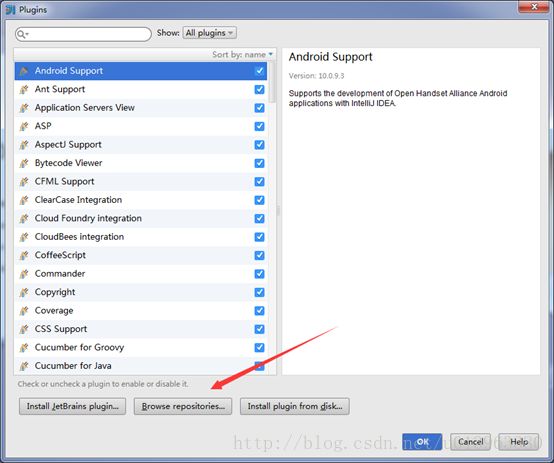
(3)在搜索框里搜scala,出现相对于的Scala插件,这里面我的已经安装完成了,没安装的会显示install的字样以及相对于的版本,这里面不建议在线安装插件,建议根据Updated 2014/12/18去下载离线的scala插件,比如本文中的IDEA Updated日期是2014/12/18然后找到对应的插件版本是1.2.1,下载即可。下面是scala插件的离线下载地址。 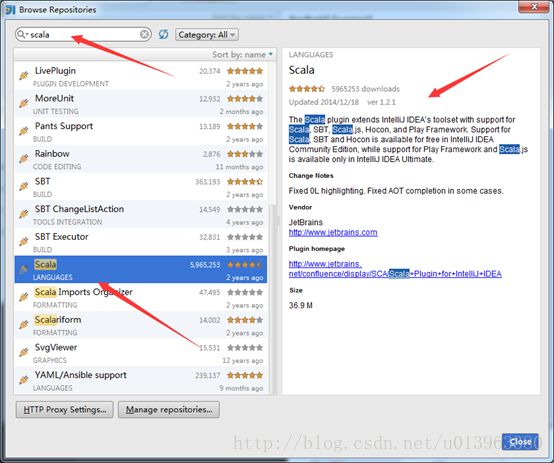
scala插件离线下载地址:https://plugins.jetbrains.com/plugin/1347-scala
然后根据Update日期去找Intellij IDEA对应得scala插件,不同版本的IDEA对应的scala插件不一样,请务必下载对应的scala插件否则无法识别。 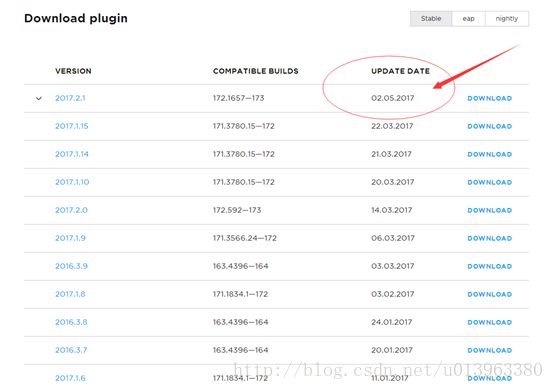
(4)离线插件下载完成后,将离线scala插件通过如下方式加入到IDEA中去:点击Install plugin from disk…,然后找到你scala插件的zip文件的本机磁盘位置,点ok即可 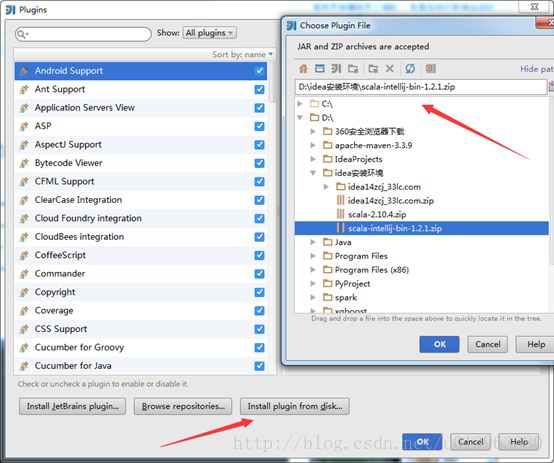
到这里,在Intellij IDEA中安装scala插件的步骤已经全部完成。接下来用IDEA来构建一个Maven工程,用来搭建spark开发环境。
3.Intellij IDEA通过Maven搭建spark环境
(1)打开IDEA新建一个maven项目,如下图:
注意:按照我步骤顺序即可。
注意:如果是第一次利用maven构建scala开发spark环境的话,这里面的会有一个选择scala SDK和Module SDK的步骤,这里路径选择你安装scala时候的路径和jdk的路径就可以了。 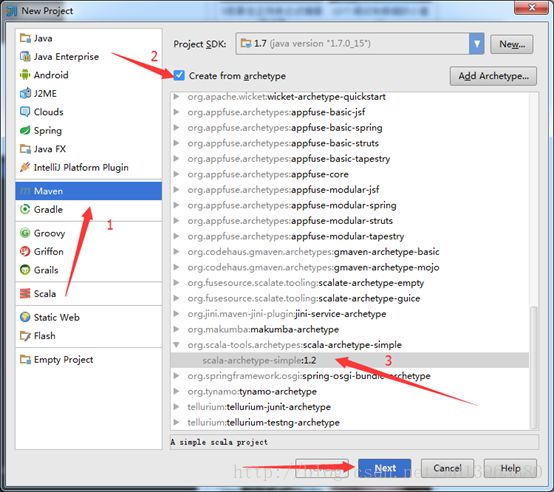
(2)填写GroupId和ArtifactId这里我就随便写了个名字,如下图,点Next。 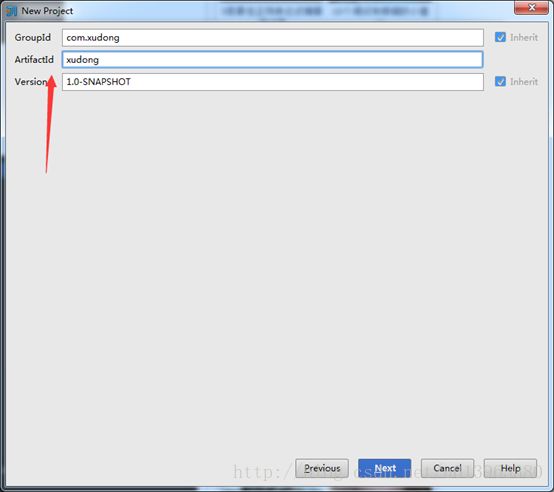
(3)第三步很重要,首先是你的Intellij IDEA里有Maven,一般的新版本都会自带maven,而且maven的目录在IDEA安装路径下plugins下就能找到,然后再Maven home directory地址中填写maven相对应的路径,本文中的IDEA版本比较老,是自己下的Maven安装上的(不会的可以百度下,很简单,建议使用新的IDEA,不需要自己下载maven)。然后这里面的User settings file是你maven路径下conf里面的settings.xml文件,勾选上override即可,这里面的Local repository路径可以不用修改,默认就好,你也可以新建一个目录。点击Next。
注意:截图的时候忘了,把Local repository前面的override也勾选上,不然构建完会报错,至少我的是这样。 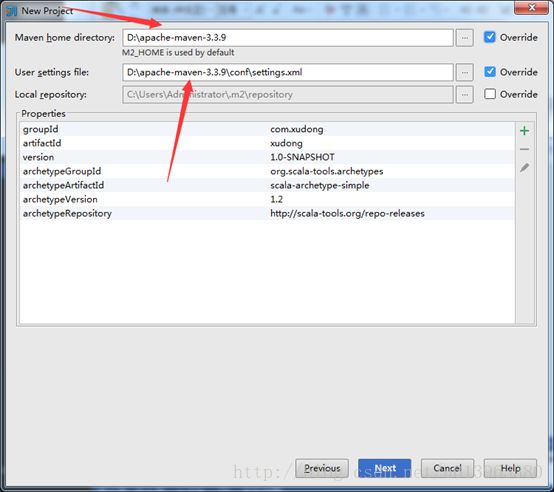
(4)填写自己的项目名,随意即可。点击finish。 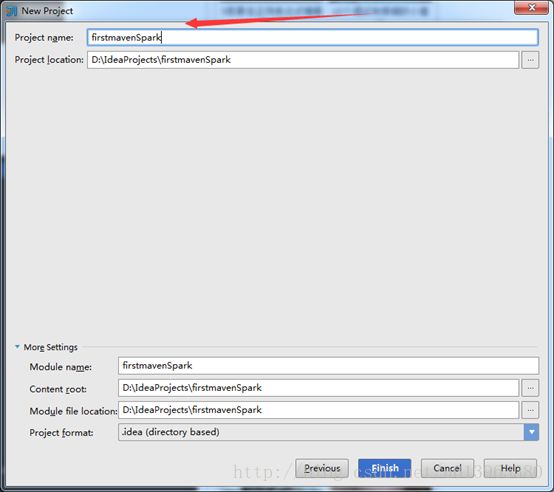
(5)到这里整个流程已经结束,完成后会显示如下界面:
右上角的import需要点击一下即可。 
(6)接下来在pom.xml文件中加入spark环境所需要的一些依赖包。以代码的方式给出,方便复制。
这里是我的pom文件代码,请各位自行按照自己的需要删减或添加依赖包。
//注意这里面的版本一定要对应好,我这里的spark版本是1.6.0对应的scala是2.10,因为我是通过spark-core_${scala.version}是找spark依赖包的,前些日子有个同事按照这个去搭建,由于版本的不一样最后spark依赖包加载总是失败。请大家自行检查自己的版本
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0modelVersion>
<groupId>com.xudonggroupId>
<artifactId>xudongartifactId>
<version>1.0-SNAPSHOTversion>
<properties>
<project.build.sourceEncoding>UTF-8project.build.sourceEncoding>
<spark.version>1.6.0spark.version>
<scala.version>2.10scala.version>
<hadoop.version>2.6.0hadoop.version>
properties>
<dependencies>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-core_${scala.version}artifactId>
<version>${spark.version}version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-sql_${scala.version}artifactId>
<version>${spark.version}version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-hive_${scala.version}artifactId>
<version>${spark.version}version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-streaming_${scala.version}artifactId>
<version>${spark.version}version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-clientartifactId>
<version>2.6.0version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-streaming-kafka_${scala.version}artifactId>
<version>${spark.version}version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-mllib_${scala.version}artifactId>
<version>${spark.version}version>
dependency>
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
<version>5.1.39version>
dependency>
<dependency>
<groupId>junitgroupId>
<artifactId>junitartifactId>
<version>4.12version>
dependency>
dependencies>
<repositories>
<repository>
<id>centralid>
<name>Maven Repository Switchboardname>
<layout>defaultlayout>
<url>http://repo2.maven.org/maven2url>
<snapshots>
<enabled>falseenabled>
snapshots>
repository>
repositories>
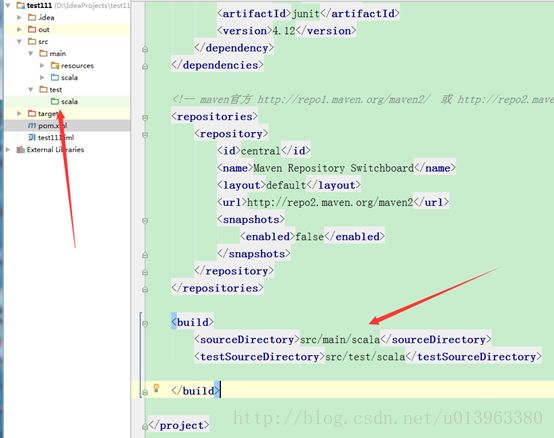
<build>
<sourceDirectory>src/main/scalasourceDirectory>
<testSourceDirectory>src/test/scalatestSourceDirectory>
build>
project>这里要注意下几个小问题:
这里面会有src/main/scala和src/test/scala需要你自己在对应项目目录下构建这两个文件夹路径,若不构建会报错。
到这里,基于scala的一个spark开发环境就基本结束了。接下来,用scala编写一个spark的简单示例,wordcount程序,如果有的同学编写过MapReduce一定会很熟悉。
4.Spark简单示例Wordcount
src/main/scala文件夹下,右键新建Package,输入package的名字,我这里是com.xudong然后新建Scala class, 然后输入名字将类型改为object,如下图: 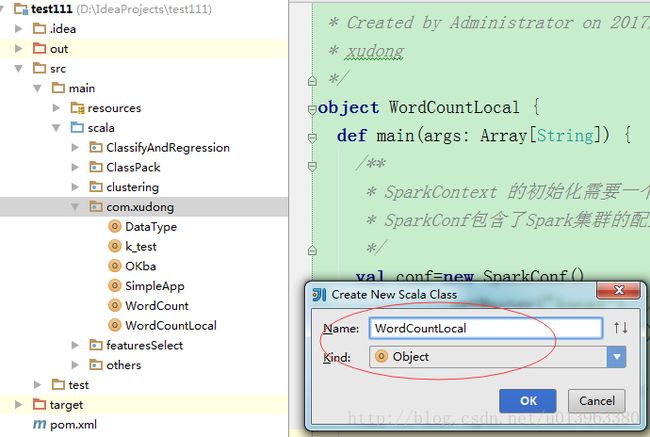
补充:
如果一开始没有在项目中加入scala的SDK,这个时候,新建Scala class会发现没有这个选项,这个时候你新建一个File文件,然后名字随便取一个,后缀改成 .scala* ,点ok后文件中空白区会显示没有scala的SDK,这个时候你点击提示信息就可以添加本地的scala SDK(提前你的电脑上已经安装了scala,这个时候它会自动的去识别SDK),以后新建Scala class就有这个选项,直接新建即可。*
创建完然后编写wordcount代码,代码如下(并注释了相关的解释):
package com.xudong
import org.apache.spark.mllib.linalg.{Matrices, Matrix}
import org.apache.spark.{SparkContext, SparkConf}
/**
* Created by Administrator on 2017/4/20.
* xudong
*/
object WordCountLocal {
def main(args: Array[String]) {
/**
* SparkContext 的初始化需要一个SparkConf对象
* SparkConf包含了Spark集群的配置的各种参数
*/
val conf=new SparkConf()
.setMaster("local")//启动本地化计算
.setAppName("testRdd")//设置本程序名称
//Spark程序的编写都是从SparkContext开始的
val sc=new SparkContext(conf)
//以上的语句等价与val sc=new SparkContext("local","testRdd")
val data=sc.textFile("e://hello.txt")//读取本地文件
data.flatMap(_.split(" "))//下划线是占位符,flatMap是对行操作的方法,对读入的数据进行分割
.map((_,1))//将每一项转换为key-value,数据是key,value是1
.reduceByKey(_+_)//将具有相同key的项相加合并成一个
.collect()//将分布式的RDD返回一个单机的scala array,在这个数组上运用scala的函数操作,并返回结果到驱动程序
.foreach(println)//循环打印
}
}
创建数据集hello.txt测试文档如下: 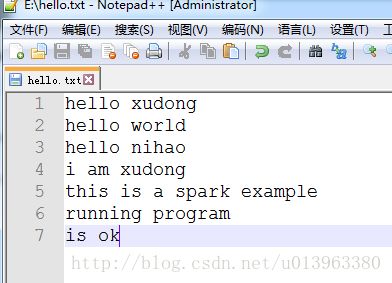
启动本地spark程序,然后输出结果,可以在控制台查看结果: 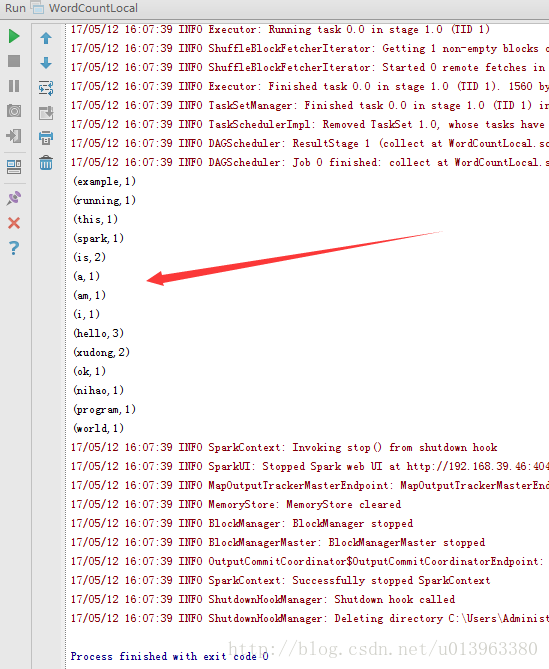
如果能正确的打印出结果,说明spark示例运行成功。
到这里,Intellij IDEA使用Maven构建spark开发环境已经完全结束,如果有疑问或者本文档有什么错误,请指出,不甚感激。
有关如何在本地将spark程序打包上传到spark集群,然后在spark集群里面去运行,后面会另写博客介绍。