无参考质量评估在视频增强的进展与应用

无参考质量评估在许多无法取得参考信息的实际系统中应用广泛且十分重要,本文整理自腾讯音视频实验室的高孟平在LiveVideoStackCon 2019上海大会中的分享,详细介绍了腾讯音视频实验室团队如何以客观的无参考质量评价,闭环指导视频增强演算法的适配,达到最佳的人眼视觉喜好效果。
文 / 高孟平
整理 / LiveVideoStack

大家好,我是来自腾讯音视频实验室的高孟平,本次与大家分享的主题是无参考质量评估在视频增强的进展与应用,无参考质量评估在许多无法取得参考信息的实际系统中应用广泛且十分重要,在演讲中将借由腾讯丽影视频服务平台的实践经验,分享如何以客观的无参考质量评价,闭环指导视频增强演算法的适配,达到最佳的人眼视觉喜好效果。面向以人眼视觉为标准,从事图像或视频增强的演算法工程师们,希望可以从中激发新的想法,并一起推动无参考质量评估在人眼视觉的更多应用。
1. Why Non-Reference Quality
Assessment?

大家可能对有参考质量评估有一定了解,某些有参考评价在应用上会有所限制,甚至在视频增强领域会存在不适应性,因此在第一阶段内容里会提到腾讯在无参考质量评估方面投入的原因以及想要去解决的一些问题,同时也会为大家列举几个在业界常用的有参考/无参考、传统学习/ 深度学习的质量评估方案。第二阶段会为大家介绍目前腾讯在使用的无参考质量评价,运用Rank Learning基于深度学习解决视频清晰度的打分方案。最后会对未来技术发展可能性和可能会遇到的挑战做一些总结。
1.1 Tencent Liyin
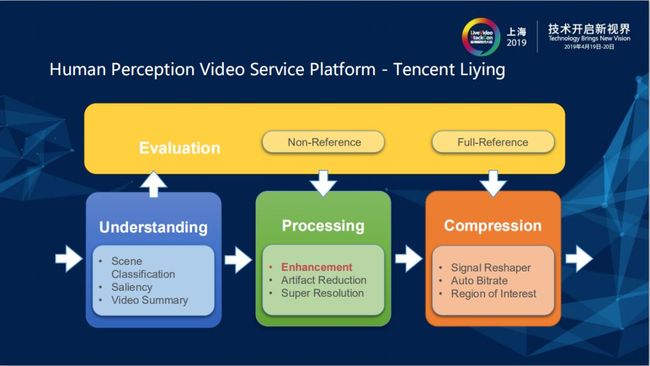
最近腾讯音视频实验室推出的人眼感知视频服务平台Tencent Liying把视频服务分为以下几个部分,分别为视频理解、视频处理、视频编解码/传输和质量评估。Enhancement是指视频处理中的视频增强(视频超分、清晰度增强、降噪等)部分,视频处理过程中如果有引入视频增强的操作,传统的全参考评价都没办法反映出视频修复增强的效果,因为全参考评价的设计指标就是与原视频无限接近才能够达到满分,这样不能反映人眼主观的MOS (Mean Opinion Score) 分数。
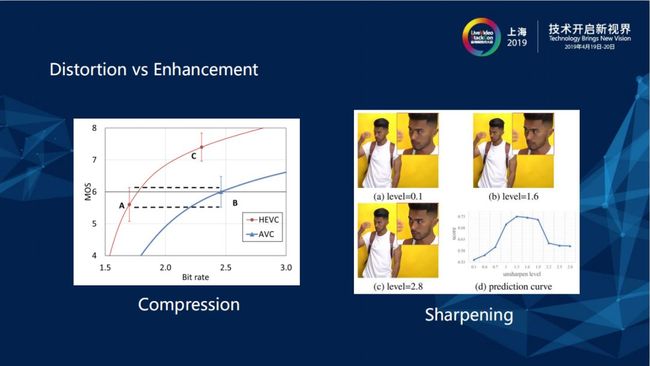
过去如果用编码衡量,参考上图中左图单调下降的编码曲线,码率越低的情况下人眼可识别的视频质量就越差,但视频增强在右图中锐度增强的评价却类似二次曲线,网络上所有的视频在进行很小一部分的视频增强操作之后,MOS值和人眼的感觉会上升,但锐度过多之后容易产生卡通效应,同时噪声也会被放大,整体呈现的效果与视频编码的单调曲线不同。
1.2 Quality Assessment by Types

要解决编码和锐度所带来的一系列问题,依照单调曲线来看,编码自然是越接近原视频越好,对视频破坏少一点分数也会相应高一些,但是对于锐度来说,锐度程度越高用户越喜欢,锐度的grading值不能反映人眼Quality Assessment,在视频增强里这是一个完全不一样的领域,所以要引入一些不同的参考质量评估方法。
上图列了几个视频评估的方法分类,第一类是Full Reference (FR) vs Non Reference (NR),即有/无参考质量评估,Non Reference在应用场景中应用比例较高。第二类是基于参考评价分为Traditional vs Deep Learning (DL),传统方法譬如信号处理PS3R,人的感官对于结构化更加敏感,透过人眼的喜好度进行MOS评分让打分机制进行学习,是通过Deep Learning (DL)实现。第三类根据打分分为Distortion Generic vs General (Enhancement Included)、Coarse Grain vs Fine Grain和Image (IQA) vs Video (VQA)。Distortion Generic加了许多的噪声破坏(单调破坏),由于在其中某些东西是一直上升到MOS到达一定程度后又呈现下降趋势,所以目前很少能看到Distortion Generic的训练集。质量评估可以作为产品上线后的监督,也可以介入闭环的开发过程评估演算法。Image (IQA) vs Video (VQA)区别在图像和视频部分。
1.3 WaDIQAM(NR)
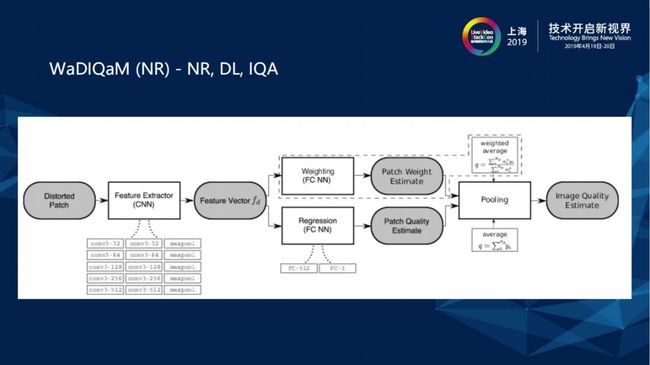
上图中有关Non Reference (NR)、Deep Learning (DL)、Image (IQA)图像质量评估可以看到,进来一张图通常会取N个Patch,每个块通过CNN深度学习网络找到Image 的feature,之后针对每个块的权重和特征来学习它的位置以及在质量评估中的比例(Patch Weight Estimate),Patch Quality Estimate是通过CNN抽取feature之后做 Regression,再通过线性回归得出MOS分数,最后将Patch Weight Estimate和Patch Quality Estimate做一个结合得到Image Quality Estimate。
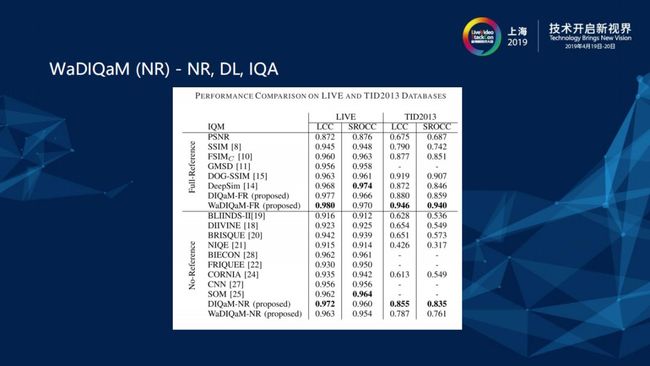
LIVE和TID2013是两个主观评价的训练集,包含各式各样的图片、Destruction和打分,LCC和SROCC是关于质量评估的两个指标,LCC是通过相关性和准确性衡量算法性能,SROCC是通过单调顺序性衡量算法性能,这两个指标越接近1越好。Non Reference (NR)Wa方法的表现还算不错,而且有对应的Full Reference (FR)版本,在大家的理解上普遍存在Non Reference (NR)方法比Full Reference (FR)稍差的概念。
1.4 DeepVQA
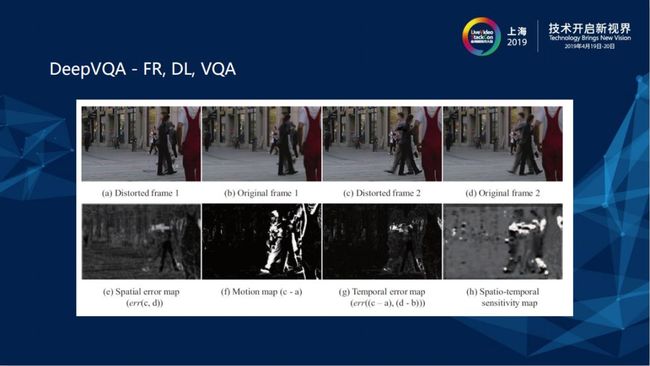
DQA相较于IQA多了一些时域上的信息,由上图可知,上层两张frame图是压缩破坏前的Original frame,下层显示的是压缩破坏后的图片,有frame1和frame2的motion map,所以是存在时域上的特征。
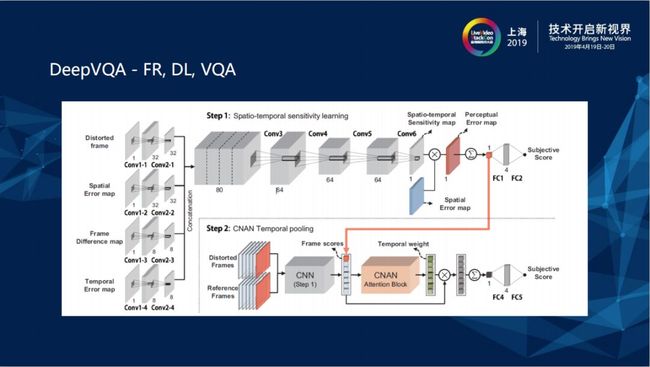
在网络里相当于是把四个东西concatenate在一起,它有衡量IQA输入的Distorted Image,也有motion上的Distortion 可以把frame1和frame2相减,它把Temporal Error map传输进去,也不止是把破坏过的图像传入进去,它是Full Reference (FR)但也把Reference 时域上的差距传进去建构CNN,最后得到Subjective Score。真正测试时会通过上层已经经过训练的网络,再通过某个Temporal weight和pooling把时域上的信息抽取出来。
2.Non-Reference Sharpness Assessor Using Rank Learning

腾讯音视频实验室的目标很明确,就是能够给具有视频增强能力的服务做一个符合人眼效果的打分。
2.1 RankIQA[ICCV 17]

团队的base是ICCV在2017年的paper RankIQA,RankIQA是一个Non Reference (NR)、Deep Learning (DL)的IQA,它主要解决了收集资料的成本问题。RankIQA希望用越少越好的资料使得Deep Learning网路不会出现训练集太少不好收敛的状况。它解决的方法是基于一组美学较好的训练集,交由机器去产生一连串的单调破坏,将原始图片用不同的失真方法结合不同的失真强度进行失真,这样得到大量不同程度失真的图片。rankings形成两两组合,传入孪生网络,然后得到高级特征(可以认为是quality score)进行比较,计算出loss,然后反向传播。但这样得到的结果还是不能与人眼打分效果相比,所以RankIQA在模型训练好后,取孪生网络的一支去跟将人眼的MOS分数再进行一次学习,这样相比传统方法所需的资料量将大大减少。
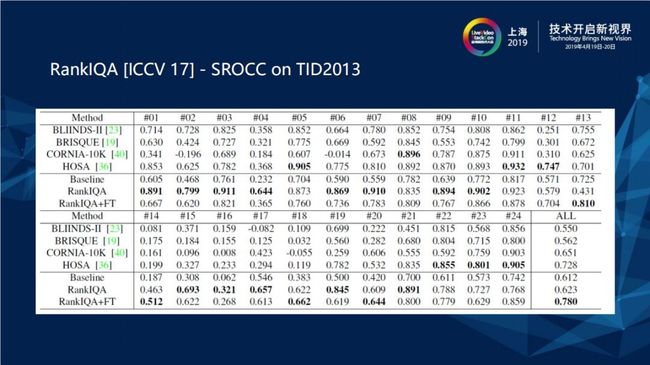
上图为RankIQA[ICCV 17] - SROCC在TID2013资料集上的表现。论文中提出在某些数据集上甚至超越了Full Reference (FR) 的方法。
2.2 NR Sharpness Assessor Using Rank Learning

团队借用了RankIQA的想法,解决了Label Shortage Problem的问题,通过这个方式可以产生大量的数据集,学习到不同程度的破坏,但团队也在此基础上完善了RankIQA对于非单调性破坏的问题,使用Data Set Preparation AVA的professional图片资料集,在对这个资料集进行一轮的资料清洗之后,找到professional认为最佳的锐度和blur等,之后再在这上面做锐化和blurring两方向的处理,学到最佳的锐度图形是在哪里。团队在工程上将Ranking Loss和L1 Regression Loss结合,孪生网络在训练过程中使用Ranking Loss,而在与人眼评判二次学习时使用L1 Regression Loss,后来发现在二次学习前引入Ranking Loss的话对PLCC和SRCC的分数会更有帮助。Patch存在很多问题,一张图在测试时通常会做十遍取平均值,但在商业化后希望一张图无论执行多少次得到的评判结果都是唯一的,因此改用Mobilenet + FCN。

在团队没有解决FCN的问题时,也是用了一些Patch来构建孪生网络,每一个Patch都有不同的分数,后续还需要进行一些微调和融合。
2.3 Fully Convolutional MobileNet
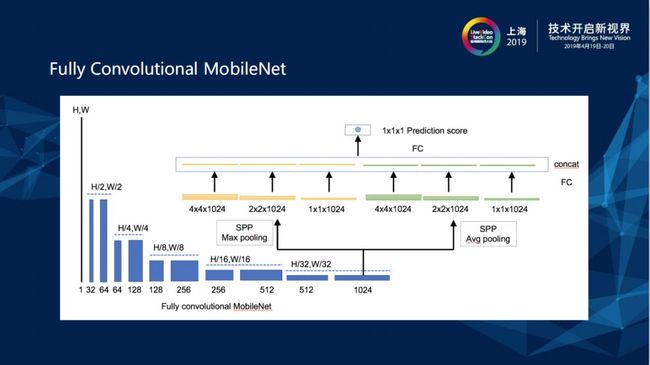
Fully Convolutional MobileNet 的好处是整张图在处理过程中不进行Patch直接Convolutional,有点像图像超分辨率或者一些视频处理模块的网络概念。
2.4 NR Sharpness Assessor PLCC / SRCC Performance
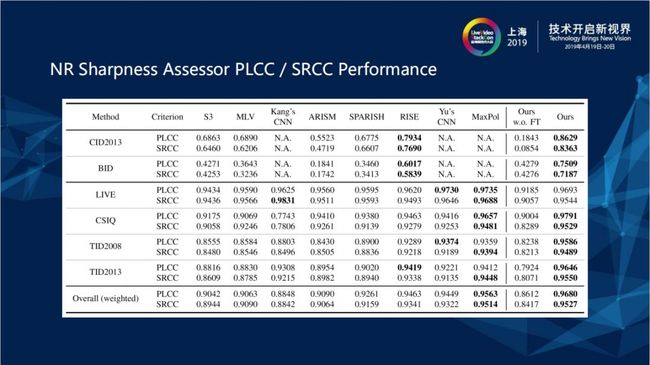
上图最右边是不同主观MOS打分训练集和测试集的Performance,左边BID、LIVE和TID2013是比较常见的训练集,横轴表示各个不同的质量评估打分。
2.5 NR Sharpness Scores

上图最下方的评分,例如左图一中0.847是Sharpness Scores打出的分数,括号中0.5是人眼评判的结果,人眼评判的结果大概范围为0.5-0.7之间,L0是针对同一个视频去做不同程度的锐化,锐化过度人眼就会判定为不佳的图像质量,人对视频曲线增强不是单调曲线上升或下降。

上图的视频源属于Monotonically Decreasing,越对视频增加锐化,人眼对视频的判定就会越差。从字体也可以看出中间和右边图像比较锐利,在播放时人眼可以明显感受到字体本身太过锐利。
2.6 NR Sharpness Assessor Applications

无参考的视觉评价在视频修复和增强方面可以提供一个评估标准,在设计这个视频平台时的唯一消费者都是人,无论对视频如何进行压缩、处理和储存,只要没有人看就没有达到技术所满足的效果。所以下一代的视频平台标准就是人眼视觉,有参考视觉评价有非常好的参考效果,但是它并没有办法完全反映消费者的感觉。另外无参考的视觉评价对于视频演算法的开发也有很大的帮助。
3.Future Work and Challenges


透过数据源的增加可能会比人工拟合SVN模型更具有未来演进能力,所以团队还是希望建构一个以Deep Learning为基础架构,在未来能够不断进步改善的质量频估架构,但是从IQA到VQA,每帧图片都是抽帧图片去做IQA评估,然后计算平均值最后得到视频的分数。未来如何评估人眼的运动遮蔽效应、VQA Temporal info pooling该怎么做、算法加速的问题如何解决,这些都是团队未来要努力的方向。
视频增强不只有锐度还包括降噪和去压缩失真,UGC/PGC视频经过不断地转发本身带有非常多的压缩失真,在有很多可以反映人眼评估要求的指标之后如何最终达到质量评估指标,而不只是清晰度评估指标和锐度评估指标。
另外在细粒度的增强上面也需要不断地演进,不只是监控线上系统稳定性,而是希望这个指标将来可以细粒度到不断地指导演算法的微调。
以上就是腾讯音视频实验室团队在未来会努力的方向。
扩展阅读
一站式体验腾讯云音视频及融合通信技术
360度无死角解析腾讯音视频及融合通信技术,包括:基础编音视频编解码、音视频AI、视频云平台架构、终端技术、海外技术架构、技术开源策略等最新最权威的官方信息。

LiveVideoStackCon 2019北京 音视频技术大会 初版日程现已上线,扫描图中二维码或点击【阅读原文】了解大会最新日程。