爬虫开发python工具包介绍 (4)
本文来自网易云社区
作者:王涛
此处我们给出几个常用的代码例子,包括get,post(json,表单),带证书访问:
Get 请求
@gen.coroutine
def fetch_url():
try:
c = CurlAsyncHTTPClient() # 定义一个httpclient
myheaders = {
"Host": "weixin.sogou.com",
"Connection": "keep-alive",
"Cache-Control": "max-age=0",
"Upgrade-Insecure-Requests": "1",
"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/532.5 (KHTML, like Gecko) Chrome/4.0.249.0 Safari/532.5 ",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"Accept-Encoding": "gzip, deflate",
"Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8"
}
url = "http://weixin.sogou.com/weixin?type=1&s_from=input&query=%E4%BA%BA%E6%B0%91%E6%97%A5%E6%8A%A5&ie=utf8&_sug_=n&_sug_type_="
req = HTTPRequest(url=url, method="GET", headers=myheaders, follow_redirects=True, request_timeout=20, connect_timeout=10,
proxy_host="127.0.0.1",
proxy_port=8888)
response = yield c.fetch(req) # 发起请求
print response.code
print response.body
IOLoop.current().stop() # 停止ioloop线程
except:
print traceback.format_exc()
Fiddler 抓到的报文请求头:
POST JSON数据请求
@gen.coroutine
def fetch_url():
"""抓取url"""
try:
c = CurlAsyncHTTPClient() # 定义一个httpclient
myheaders = {
"Host": "weixin.sogou.com",
"Connection": "keep-alive",
"Cache-Control": "max-age=0",
"Upgrade-Insecure-Requests": "1",
"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/532.5 (KHTML, like Gecko) Chrome/4.0.249.0 Safari/532.5 ",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"Accept-Encoding": "gzip, deflate",
"Content-Type": "Application/json",
"Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8"
}
url = "http://127.0.0.1?type=1&s_from=input&query=%E4%BA%BA%E6%B0%91%E6%97%A5%E6%8A%A5&ie=utf8&_sug_=n&_sug_type_="
body =json.dumps({"key1": "value1", "key2": "value2"}) # Json格式数据
req = HTTPRequest(url=url, method="POST", headers=myheaders, follow_redirects=True, request_timeout=20, connect_timeout=10,
proxy_host="127.0.0.1",proxy_port=8888,body=body)
response = yield c.fetch(req) # 发起请求
print response.code
print response.body
IOLoop.current().stop() # 停止ioloop线程
except:
print traceback.format_exc()
Fiddler 抓到的报文请求头:
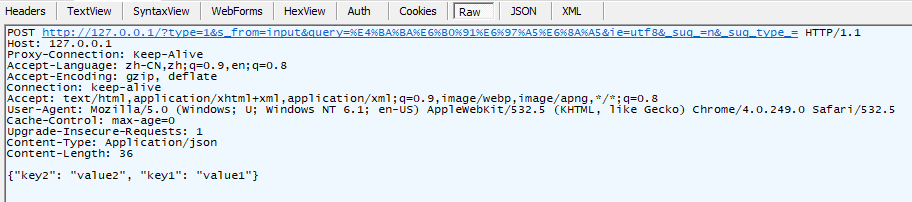
POST Form表单数据请求
@gen.coroutine
def fetch_url():
"""抓取url"""
try:
c = CurlAsyncHTTPClient() # 定义一个httpclient
myheaders = {
"Host": "weixin.sogou.com",
"Connection": "keep-alive",
"Cache-Control": "max-age=0",
"Upgrade-Insecure-Requests": "1",
"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/532.5 (KHTML, like Gecko) Chrome/4.0.249.0 Safari/532.5 ",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"Accept-Encoding": "gzip, deflate",
# "Content-Type": "Application/json",
"Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8"
}
import urllib
url = "http://127.0.0.1?type=1&s_from=input&query=%E4%BA%BA%E6%B0%91%E6%97%A5%E6%8A%A5&ie=utf8&_sug_=n&_sug_type_="
body =urllib.urlencode({"key1": "value1", "key2": "value2"}) # 封装form表单
req = HTTPRequest(url=url, method="POST", headers=myheaders, follow_redirects=True, request_timeout=20, connect_timeout=10,
proxy_host="127.0.0.1",proxy_port=8888,body=body)
response = yield c.fetch(req) # 发起请求
print response.code
print response.body
IOLoop.current().stop() # 停止ioloop线程
except:
print traceback.format_exc()
Fiddler 抓到的报文请求头:
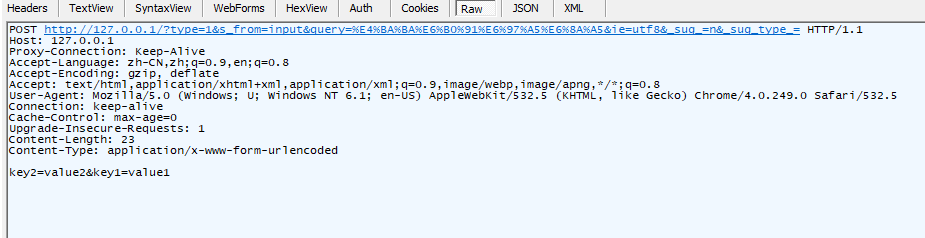
添加证书访问
def fetch_url():
"""抓取url"""
try:
c = CurlAsyncHTTPClient() # 定义一个httpclient
myheaders = {
"Host": "www.amazon.com",
"Connection": "keep-alive",
"Cache-Control": "max-age=0",
"Upgrade-Insecure-Requests": "1",
"User-Agent": ("Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
"AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/68.0.3440.106 Safari/537.36"),
"Accept": ("text/html,application/xhtml+xml,"
"application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8"),
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8"
}
import urllib
url = "https://www.amazon.com/"
req = HTTPRequest(url=url, method="GET", headers=myheaders, follow_redirects=True, request_timeout=20, connect_timeout=10,proxy_host="127.0.0.1",
proxy_port=8888,ca_certs="FiddlerRoot.pem") # 绑定证书
response = yield c.fetch(req) # 发起请求
print response.code
print response.body
IOLoop.current().stop() # 停止ioloop线程
except:
print traceback.format_exc()
Fiddler抓到的报文(说明可以正常访问)
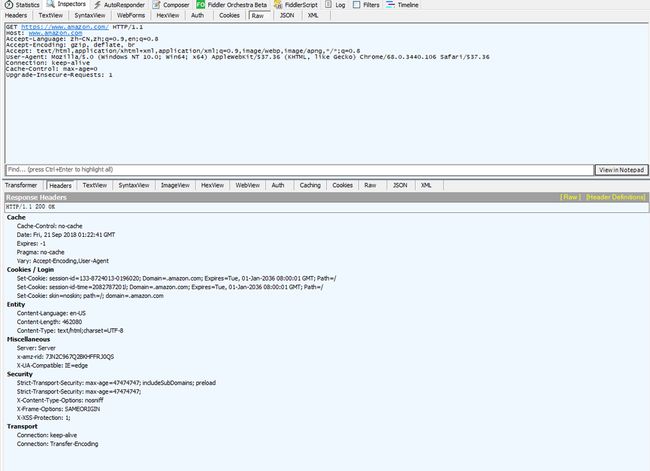
四、总结
抓取量少的时候,建议使用requests,简单易用。
并发量大的时候,建议使用tornado,单线程高并发,高效易编程。
以上给出了requests和Fiddler中常用的接口和参数说明,能解决爬虫面对的大部分问题,包括并发抓取、日常的反爬应对,https网站的抓取。
附上一段我自己的常用抓取代码逻辑:
import randomfrom tornado.ioloop import IOLoopfrom tornado import genfrom tornado.queues import Queue
import random
from tornado.ioloop import IOLoop
from tornado import gen
from tornado.queues import Queue
TASK_QUE = Queue(maxsize=1000)
def response_handler(res):
""" 处理应答,一般会把解析的新的url添加到任务队列中,并且解析出目标数据 """
pass
@gen.coroutine
def url_fetcher_without_param():
pass
@gen.coroutine
def url_fetcher(*args,**kwargs):
global TASK_QUE
c = CurlAsyncHTTPClient()
while 1:
#console_show_log("Let's spider")
try:
param = TASK_QUE.get(time.time() + 300) # 5 分钟超时
except tornado.util.TimeoutError::
yield gen.sleep(random.randint(10,100))
continue
try:
req = HTTPRequest(url,method=,headers=,....) # 按需配置参数
response = yield c.fetch(req)
if response.coe==200:
response_handler(response.body)
except Exception:
yield gen.sleep(10)
continue
finally:
print "I am a slow spider"
yield gen.sleep(random.randint(10,100))
@gen.coroutine
def period_callback():
pass
def main():
io_loop = IOLoop.current()
# 添加并发逻辑1
io_loop.spawn_callback(url_fetcher, 1)
io_loop.spawn_callback(url_fetcher, 2)
io_loop.spawn_callback(url_fetcher_without_param) # 参数是可选的
# 如果需要周期调用,调用PeriodicCallback:
PERIOD_CALLBACK_MILSEC = 10 # 10, 单位ms
io_loop.PeriodicCallback(period_callback,).start()
io_loop.start()
if __name__ == "__main__":
main()
以上,欢迎讨论交流
五、参考:
requests快速入门:http://docs.python-requests.org/zh_CN/latest/user/quickstart.html
requests高级应用:http://docs.python-requests.org/en/master/user/advanced/
什么是CA_BUNDLE:https://www.namecheap.com/support/knowledgebase/article.aspx/986/69/what-is-ca-bundle
如何用requests下载图片:https://stackoverflow.com/questions/13137817/how-to-download-image-using-requests
tornado AsyncHttpClient: https://www.tornadoweb.org/en/stable/httpclient.html
100 Continue状态码:https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Status/100
HTTP认证: https://developer.mozilla.org/en-US/docs/Web/HTTP/Authentication
证书转换: https://www.alibabacloud.com/help/zh/faq-detail/40526.htm
网易云免费体验馆,0成本体验20+款云产品!
更多网易研发、产品、运营经验分享请访问网易云社区。
相关文章:
【推荐】 控制台的艺术(附原理实现)