Scala与Java语言的差异
1、源文件后缀名
Java:.java
Scala:.scala
2、变量
Java:
int param1 = 100;
int param2
Scala:
格式:
var VariableName : DataType [= Initial Value]
示例:
var param1: String = "Hello Scala"
var param2 = "hello scala" // 编译器会根据值来推断参数类型
var param3: String // 局部变量必须初始化,如果要定义这种未初始化的必须放在abstract class或trait中
// var param4 // 这是不允许的
局部变量必须初始化,如果要定义这种未初始化的必须放在abstract class或trait中
def hello(): Unit ={
var param1: String = "Hello Scala"
var param2 = "hello scala"
// var param3: String // 这是不允许的,局部变量必须初始化
// var param4 // 这是不允许的
}
abstract class Example {
var param1: String = "Hello Scala"
var param2 = "hello scala"
var param3: String // 这是允许的
// var param4 // 这是不允许的
}
trait TraitExample{
var param1: String = "Hello Scala"
var param2 = "hello scala"
var param3: String // 这是允许的
// var param4 // 这是不允许的
}
3、常量
Java:
final int param = 100;
Scala:
在Scala中要多使用val,减少使用var。
val param = 100 // 编译器会根据值来推断参数类型
val param1: Int = 100
// val param2: Int // 这是不允许的
如果定义了常量,初始化工作又不想在声明时做,那么要把它们写到abstract class或trait中:
abstract class Example {
val param2: Int
}
trait TraitExample{
val param2: Int
}
4、函数定义
Java:
修饰符 返回值类型 方法名([类型 参数]){
...
方法体
...
return 返回值;
}
java的方法必须写在类里:
class Demo{
public int add(int a,int b){
return a+b;
}
}
Scala:
def 函数名([参数:类型]):返回值类型 = { 函数体 }
没有返回值可以定义为Unit,或者省略(包括=号,但是有返回值的话,等号一定不能省去),建议不要省略。
如:
// 推荐
def add(a: Int, b: Int): Int = {
a + b
// 或
// return a + b
}
// 不指定返回值类型,就要告编译器推断
def add(a: Int, b: Int) = {
a + b
// 或
// return a + b
}
// 使用了return语句,就必须指定返回值类型
def add(a: Int, b: Int): Int = {
// a + b
// 或
return a + b
}
// 返回值为Unit
def f(): Unit ={
println("hello")
}
def f1()={
println("hello world")
}
def f2(){
println("hello world @@@")
}
// 没有参数的话,也可以把括号去掉
def f1: Unit={
println("hello world")
}
def f1={
println("hello world")
}
def f1{
println("hello world")
}
// 调用函数时,甚至连括号都不用加
object HelloScala {
def f1: Unit={
println("hello world")
}
def f2={
println("hello world")
}
def f3{
println("hello world")
}
def main(args: Array[String]): Unit = {
println(University.getStudentNo)
println(University.getStudentNo)
f1
f2
f3
}
}
Scala函数会将最后出现的变量作为return的值。
使用return必须显式指定返回类型,但会使Scala失去推断返回值类型的能力。
必须使用return的代码往往意味着存在“多路径返回”的问题,即return存在多个条件分支中,并借助return中断返回的特性来处理分支。「不建议这么做」,因为可读性不好
因此,当发现不得不使用return的时候,应该重新审视下流程是否应该改写,过多的嵌套循环是否能拆分成多个函数递归,lambda等形式。
5、for循环
Java:
int num[] = {1,2,3,4,5};
for (int a:num) {
System.out.println(a);
}
for (int a = 0; a<3; a++) {
System.out.println("重要事情说三遍");
}
Scala:
for(i <- 1 to 5){
println(i)
}
for(i <- 1.to(5)){
println(i)
}
for(i <- 1 to 3; a <- 1 to 3){
println(s"${i}#${a}")
}
for(i <- 1 to 5; a <- 1 to 6; b <- 1 to 7){
println(s"${i}#${a}#${b}")
}
在Scala中for循环比Java的有更高级的形态,可以在for表达式中定义生成器、定义 变量、定义过滤器:
生成器for…yield:for循环迭代会将列表中的所有元素进行遍历,yield会产生一个值 ,这个值被循环记录下来,当循环结束 后,会返回所有yield的值组成的集合,返回集合的类型与被遍历的集合类型是一致。
case class Person(name: String, isMale: Boolean, children: Person *)
def main(args: Array[String]): Unit = {
val lauren = Person("Lauren",false)
val rocky = Person("Rocky",true)
val vivian = Person("Vivian",false,lauren,rocky)
val persons = List(lauren,rocky,vivian)
// 定义一个变量userName = person.name
// 实现一个过滤器 if ! person.isMale
// yield是生成器
val forResult = for{person <- persons; userName = person.name; if ! person.isMale; child <- person.children} yield(userName,child.name)
println(forResult)
// 或者
val forResult1 = for(person <- persons; userName1 = person.name; if ! person.isMale; child <- person.children) yield(userName1,child.name)
println(forResult1)
val forResult2 = for(person <- persons; userName2 = person.name; if ! person.isMale; child <- person.children) yield{
(userName2,child.name)
}
println(forResult2)
}
val nums = List(1, 2, 3, 4, 5)
val forYieldResult = for (num <- nums) yield {
println("hello yield")
(num, num * 10, num * 100)
}
println(forYieldResult)
6、异常处理
Java:
try{
// 程序代码
}catch(异常类型1 异常的变量名1){
// 程序代码
}catch(异常类型2 异常的变量名2){
// 程序代码
}finally{
// 程序代码 无论是否发生异常,finally 代码块中的代码总会被执行。
}
示例代码:
FileReader f = null;
try {
f = new FileReader("input.txt");
}catch(FileNotFoundException ex) {
System.out.println("Missing file exception");
}catch (IOException ex){
System.out.println("IO Exception");
} finally{
if(f != null){
f.close();
}
System.out.println("finally block execute");
}
Scala:
与Java不同,Scala使用case进行模式匹配来捕获异常。在catch里用case语句对抛出的异常进行匹配。
try {
// 程序代码
} catch {
case 异常的变量名1: 异常类型1 =>
case 异常的变量名2: 异常类型2 => {
}
} finally {
// 程序代码 无论是否发生异常,finally 代码块中的代码总会被执行。
}
示例代码 :
var f:FileReader = null
try {
f = new FileReader("input.txt")
} catch {
case ex: FileNotFoundException =>{
println("Missing file exception")
}
case ex: IOException => {
println("IO Exception")
}
}finally {
if(f != null){
f.close()
}
println("finally block execute")
}
7、数据类型
Java:
一、基本数据类型:
| 类型 | 位宽度 |
|---|---|
| byte | 8 |
| short | 16 |
| int | 32 |
| long | 64 |
| float | 32 |
| double | 64 |
| char | 16 |
| boolean | 8 |
二、引用数据类型:
类,接口,数组
Scala:
Scala数据类型都是对象,Scala没有java中的原生类型。在Scala中是可以对数字等基础类型调用方法的。
| 类型 | 位宽度 |
|---|---|
| Byte | 8 |
| Short | 16 |
| Int | 32 |
| Long | 64 |
| Float | 32 |
| Double | 64 |
| Char | 16 |
| Boolean | 8 |
| String | 字符序列 |
| Unit | 表示无值,和其他语言中void等同。用作不返回任何结果的方法的结果类型。Unit只有一个实例值,写成()。 |
| Null | null 或空引用 |
| Nothing | Nothing类型在Scala的类层级的最低端;它是任何其他类型的子类型。 |
| Any | Any是所有其他类的超类 |
| AnyRef | AnyRef类是Scala里所有引用类(reference class)的基类 |
8、Scala 元组Tuple
Java:
Java没有元组
Scala :
与列表一样,元组也是不可变的,但与列表不同的是元组可以包含不同类型的元素。元组的值是通过将单个的值包含在圆括号中构成的。和Array数组不同的是,数组的索引是从0开始的,但元组是从1开始的。例如:
val tuple = (100,"Java","Scala","Spark")
println(tuple._1)
println(tuple._2)
println(tuple._3)
println(tuple._4)
val tuple1:(Int,String,String,String) = (100,"Java","Scala","Spark")
println(tuple1._1)
println(tuple1._2)
println(tuple1._3)
println(tuple1._4)
// 使用模式匹配来获取元组的值
val (a:Int,b:String,c:String,d:String) = (101,"Java","Scala","Spark")
println(a)
println(b)
println(c)
println(d)
val (aa,bb,cc,dd) = (102,"Java","Scala","Spark")
println(aa)
println(bb)
println(cc)
println(dd)
// 如果元组中的元素并不是每一个元素都需要,那么可以在不需要的位置上使用"_"占位符
val (aaa,_,ccc,_) = (102,"Java","Scala","Spark")
println(aaa)
println(ccc)
9、数组
Java:
dataType[] arrayRefVar; // 首选的方法
// 或
dataType arrayRefVar[]; // 效果相同,但不是首选方法
示例:
// 定义数组
double[] myList = new double[3]; // 首选
double myList1[] = new double[3];
myList[0] = 5.6;
myList[1] = 4.5;
myList[2] = 3.3;
myList1[0] = 5.6;
myList1[1] = 4.5;
myList1[2] = 3.3;
// 定义并初始化数组
double[] myList2 = {1.9, 2.9, 3.4};
double myList3[] = {1.9, 2.9, 3.4};
Scala:
Scala数组分为定长数组和可变数组。
// 定长数组
val myList:Array[Double] = new Array[Double](3)
val myList1 = new Array[Double](3)
myList(0) = 5.6
myList(1) = 4.5
myList(2) = 3.3
myList1(0) = 5.6
myList1(1) = 4.5
myList1(2) = 3.3
// 定义并初始化数组
val myList2:Array[Double] = Array(1.9, 2.9, 3.4)
val myList3 = Array(1.9, 2.9, 3.4) // myList3编译器会自己推断
// 可变数组
val b:ArrayBuffer[Double] = new ArrayBuffer[Double]()
// b(0) = 1.1 // 可变数组没有申请到空间这样访问会出错的
// b(1) = 1.2
b += 1.3
b += (3.3,5.5,6.6)
b ++= Array(7.7,8.8,9.9) // 这里必须用++=
println(b)
b(0) = 1.1
b(1) = 1.2
println(b)
b.insert(0,88) // 前提是下标要存在,否则会报数组越界异常
println(b)
b.trimEnd(1) // 删除最后一个元素
println(b)
b.remove(1) // 删除索引为1的元素
println(b)
println(b.toArray) // 将可变数组转换为定长数组
10、多维数组
Java:
多维数组可以看成是数组的数组,比如二维数组就是一个特殊的一维数组,其每一个元素都是一个一维数组。
第一种初始化方法:直接为每一维分配空间,如:
String str[][] = new String[3][4];
第二种初始化方法:从最高维开始,分别为每一维分配空间
String s[][] = new String[2][];
** Scala**:
多维数组一个数组中的值可以是另一个数组,另一个数组的值也可以是一个数组。矩阵与表格是我们常见的二维数组。
var s:Array[Array[String]] = Array.ofDim(3,4)
var ss = Array.ofDim[String](3,4)
var sss = new Array[Array[String]](2) // 包含2个元素,每个元素都是一个数组
s(1)(1) = "Hello world"
println(s(1)(1))
// sss(1)(1) = "Bye bye" 这是不行的,因为有一维还没有分配空间
sss(1) = new Array[String](4)
sss(1)(1) = "Bye bye"
println(sss(1)(1))
11、从本地文件中读取文本行
Java:
import java.io.*;
public class Main {
public static void main(String[] args) {
try {
FileReader fileReader = new FileReader("/home/wong/Desktop/html/test.txt");
BufferedReader bufferedReader = new BufferedReader(fileReader);
while (bufferedReader.read() != -1) {
System.out.print(bufferedReader.readLine());
}
fileReader.close();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
Scala:
import scala.io.Source
object HelloScala {
def main(args: Array[String]): Unit = {
val file = Source.fromFile("/home/wong/Desktop/html/test.txt")
for(line <- file){
print(line)
}
file.close()
}
}
12、读取网页文件
Java:
import java.io.*;
import java.net.HttpURLConnection;
import java.net.URL;
import java.nio.charset.StandardCharsets;
public class Main {
public static void main(String[] args) {
try {
// 获得打开的Http链接
HttpURLConnection connection = (HttpURLConnection)(new URL("Http://www.baidu.com").openConnection());
// 获得打开的Http链接的输入流
InputStreamReader inputStreamReader = new InputStreamReader(connection.getInputStream(), StandardCharsets.UTF_8);
// 把输入流缓存一下,方便等一下,可以一行一行拿出数据来
BufferedReader bufferedReader = new BufferedReader(inputStreamReader);
while (bufferedReader.read() != -1) {
System.out.print(bufferedReader.readLine());
}
bufferedReader.close();
inputStreamReader.close();
connection.disconnect();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
Scala:
import scala.io.Source
object HelloScala {
def main(args: Array[String]): Unit = {
val file = Source.fromURL("http://www.baidu.com")
for(line <- file){
print(line)
}
file.close()
}
}
13、写本地文件
Java:
import java.io.*;
public class Main {
public static void main(String[] args) {
try {
FileWriter fileWriter = new FileWriter("/home/wong/Desktop/scalaFile.txt");
for(int i = 1; i < 11; i++){
fileWriter.write(String.valueOf(i));
}
fileWriter.close();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
Scala:
import java.io.{File, PrintWriter}
object HelloScala {
def main(args: Array[String]): Unit = {
val fileWriter = new PrintWriter(new File("/home/wong/Desktop/scalaFile.txt"))
for(i <- 1 to 10){fileWriter.print(i)} // 将值写入文件
fileWriter.close()
}
}
14、集合之Map
Java:
Map<String, String> map = new HashMap<String, String>();
// 插入元素
map.put("key1", "value1");
// 获取元素
String value = map.get("key1");
// 移除元素
map.remove("key1");
// 清空map
map.clear();
// Map 遍历
// 初始化数据
Map<String, String> map1 = new HashMap<String, String>();
map1.put("key1", "value1");
map1.put("key2", "value2");
// 增强for循环遍历
// 使用keySet()遍历
for (String key : map1.keySet()) {
System.out.println(key + " :" + map1.get(key));
}
// 其实业界更提倡使用entrySet
for (Map.Entry<String,String> entry : map1.entrySet()) {
System.out.println(entry.getKey() + " :" + entry.getValue());
}
// 迭代器遍历
// 使用keySet()遍历
Iterator<String> iterator = map1.keySet().iterator();
while (iterator.hasNext()){
String key = iterator.next();
System.out.println(key + " :" + map1.get(key));
}
// 使用entrySet()遍历
Iterator<Map.Entry<String,String>> iterator1 = map1.entrySet().iterator();
while (iterator1.hasNext()) {
Map.Entry<String, String> entry = iterator1.next();
System.out.println(entry.getKey() + " :" + entry.getValue());
}
// Map 排序:HashMap、Hashtable、LinkedHashMap排序
Map<String, String> map2 = new HashMap<String, String>();
map2.put("b", "b");
map2.put("a", "c");
map2.put("c", "a");
// 通过ArrayList构造函数把map.entrySet()转换成list
List<Map.Entry<String, String>> list = new ArrayList<Map.Entry<String, String>>(map2.entrySet());
// 通过比较器实现比较排序
list.sort(new Comparator<Map.Entry<String, String>>() {
@Override
public int compare(Map.Entry<String, String> mapping1, Map.Entry<String, String> mapping2) {
return mapping1.getKey().compareTo(mapping2.getKey());
}
});
for (Map.Entry<String, String> mapping : list) {
System.out.println(mapping.getKey() + " :" + mapping.getValue());
}
// TreeMap排序,TreeMap默认按key进行升序排序,如果想改变默认的顺序,可以使用比较器
Map<String,String> map3 = new TreeMap<>(new Comparator<String>() {
@Override
public int compare(String o1, String o2) {
// 降序排序
return o2.compareTo(o1);
}
});
map3.put("2", "b");
map3.put("1", "c");
map3.put("3", "a");
for (Map.Entry<String,String> entry : map3.entrySet()) {
System.out.println(entry.getKey() + " :" + entry.getValue());
}
// 按value排序
TreeMap<String,String> map4 = new TreeMap<>();
map4.put("5", "1");
map4.put("7", "3");
map4.put("6", "2");
List<Map.Entry<String,String>> list1 = new ArrayList<>(map4.entrySet());
list1.sort(new Comparator<Map.Entry<String, String>>() {
@Override
public int compare(Map.Entry<String, String> o1, Map.Entry<String, String> o2) {
return o1.getValue().compareTo(o2.getValue());
}
});
for (Map.Entry<String,String> entry : map4.entrySet()) {
System.out.println(entry.getKey() + " :" + entry.getValue());
}
Scala:
Scala分为不可变Map和可变Map
// 不可变Map
val map = Map("key1" -> "value1")
val result = for((k,v) <- map) yield (k,v+"Haha")
println(map)
println(result)
// 获取元素
println(map("key1"));
// 可变Map
// 可变map可以修改、增加、删除
val mutableMap = scala.collection.mutable.Map("scala" -> 10, "Hadoop" -> 11)
// 修改
mutableMap("scala") = 100
println(mutableMap("scala"))
// 增加
mutableMap += ("key1" -> 88)
println(mutableMap("key1"))
println(mutableMap)
// 删除
mutableMap -= "scala"
println(mutableMap)
// 遍历
for((key,v) <- mutableMap){
println(v)
}
15、访问修饰符
Java:
java的访问修饰符:public、protected、private,也可以缺省(即不带访问修饰符)。
| 修饰符 | 可见性 |
|---|---|
| public | 所有可见 |
| protected | 在子类可见、同一包中的类可见、本类内可见 |
| private | 类内部可见 |
| default(缺省) | 同一包中的类可见、本类内可见 |
java没有存储类型修饰符。
Scala:
Scala 访问修饰符基本和Java的一样,分别有:public、protected、private。如果没有指定访问修饰符,默认情况下,Scala 对象的访问级别都是 public。
Scala 中的 private 限定符,比 Java 更严格,在嵌套类情况下,外层类甚至不能访问被嵌套类的私有成员。
| 修饰符 | 可见性 |
|---|---|
| public(默认) | 所有可见,没有指定任何的修饰符,默认为 public。成员在任何地方都可以被访问。 |
| protected | 在子类可见、本类内可见。Protected成员的访问比 java 更严格一些。它只允许在子类中被访问。而在java中,用protected关键字修饰的成员,除了在子类可以访问,还可以被同一个包里的其他类访问。 |
| private | 类内部可见 ,用 private 关键字修饰,带有此标记的成员仅在包含了成员定义的类或对象内部可见,同样的规则还适用内部类。 |
Public
class Outer{
class Inner{
def f(): Unit ={
println("f")
}
class InnerMost{
f() // 正确
}
new InnerMost // 如果构造函数是不带参的,可以省去括号
}
(new Inner).f() // 正确因为 f() 是 public
}
Protected
class Super{
protected def f(): Unit ={
println("f")
}
class Sub extends Super{
f() // 保护成员只可以在子类中被访问
}
class Inner{
f() // 正确
(new Super).f() // 正确
}
}
class Outer{
(new Super).f() // 错误
}
object MyScala {
def main(args: Array[String]): Unit = {
val base = new Super
val outer = new base.Inner
}
}
Private
class Outer{
class Inner{
private def f(): Unit ={
println("f")
}
class InnerMost{
f() // 正确
}
}
(new Inner).f() // 错误
}
16、作用域保护
Scala中,访问修饰符可以通过使用限定词强调。格式为:
private[x]
或
protected[x]
这里的x指代某个所属的包、类或单例对象。如果写成private[x],读作"这个成员除了对[…]中的类或[…]中的包中的类及它们的伴生对像可见外,对其它所有类都是private。
这种技巧在横跨了若干包的大型项目中非常有用,它允许你定义一些在你项目的若干子包中可见但对于项目外部的客户却始终不可见的东西。
package rocket{
package navigation{
private[rocket] class MyNavigator{
private[this] var speed: Int = 200
protected[navigation] def start(): Unit ={
println("hello")
}
class Journey {
private[MyNavigator] val distance: Int = 100
}
}
}
package launch{
import navigation._
object Vehicle{
private[launch] val guide = new MyNavigator
}
}
}
上述例子中,类MyNavigator被标记为private[rocket]就是说这个类对包含在rocket包里的所有的类和对象可见。
比如说,从Vehicle对象里对Navigator的访问是被允许的,因为对象Vehicle包含在包launch中,而launch包在rocket中,相反,所有在包rocket之外的代码都不能访问类Navigator。private[this]要求比较严格,只能被包含定义的同一个对象访问。
protected[x]与private[x]意思相同,即类里的protected[x]修饰符允许类的所有子类及修饰符所属的包、类、对象X访问带有些标记的定义。如上例 start()方法能被class MyNavigator的所有子类和包含在navigation的所有代码访问。
17、类
类是对象的抽象,而对象是类的具体实例。类是抽象的,不占用内存,而对象是具体的,占用存储空间。类是用于创建对象的蓝图,它是一个定义包括在特定类型的对象中的方法和变量的软件模板。我们可以使用 new 关键字来创建类的对象。
Java:
class Point{
private int x;
private int y;
public Point(int xc,int yc){
x = xc;
y = yc;
}
public void move(int dx,int dy){
x = x + dx;
y = y + dy;
System.out.println("x的坐标点:"+x);
System.out.println("y的坐标点:"+y);
}
}
public class Main {
public static void main(String[] args) throws IOException {
Point pt = new Point(10,20);
pt.move(30,50);
}
}
Scala:
Scala中的类不声明为public,一个Scala源文件中可以有多个类。Scala也是使用 new 来实例化类的。
class Point(xc: Int, yc: Int){
var x: Int = xc
var y: Int = yc
def move(dx: Int, dy: Int): Unit ={
x = x + dx
y = y + dy
println(s"x的坐标点:${x}")
println(s"x的坐标点:${y}")
}
}
object MyScala {
def main(args: Array[String]): Unit = {
val pt = new Point(10,20)
pt.move(30,50)
}
}
18、属性的getter、setter方法
Java:
class Person{
private String name;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}
Scala:
class Person {
private var name = null
def getName: String = name
def setName(name: String): Unit = {
this.name = name
}
}
19、 继承
Java:
class Point{
int x;
int y;
public Point(int xc, int yc){
this.x = xc;
this.y = yc;
}
public void move(int dx, int dy){
x = x + dx;
y = y + dy;
System.out.println("坐标("+x+","+y+")");
}
}
class Location extends Point{
private int z;
public Location(int xc, int yc,int zc){
super(xc,yc);
this.z = zc;
}
public void move(int dx,int dy, int dz){
x = x + dx;
y = y + dy;
z = z + dz;
System.out.println("坐标("+x+","+y+","+z+")");
}
@Override
public void move(int dx,int dy){
super.move(dx,dy);
System.out.println("Hello world");
}
}
public class Main {
public static void main(String[] args) throws IOException {
Location location = new Location(10,20,30);
location.move(10,20);
location.move(10,20,30);
}
}
Scala:
Scala继承一个基类跟Java很相似, 但我们需要注意以下几点:
1、重写一个非抽象方法必须使用override修饰符。重写字段也必须用override修饰符
2、在子类中重写超类的抽象方法时,不需要使用override关键字。
3、只有主构造函数才可以往基类的构造函数里写参数。
下面这个类class Point继承自AnyRef,AnyRef继承处自Any类,Any类是Scala整个层级的根节点。
class Point(xc: Int, yc: Int) {
var x: Int = xc
var y: Int = yc
def move(dx: Int, dy: Int): Unit ={
x = x + dx
y = y + dy
println(s"坐标(${x},${y})")
}
}
class Location( val xc: Int, val yc: Int, val zc: Int) extends Point(xc,yc){
var z: Int = zc
def move(dx: Int, dy: Int, dz: Int): Unit ={
x = x + dx
y = y + dy
z = z + dz
println(s"坐标(${x},${y},${z})")
}
override def move(dx: Int, dy: Int): Unit = {
super.move(dx,dy)
println(s"hello world:${dx},${dy}")
}
}
object MyScala {
def main(args: Array[String]): Unit = {
var location = new Location(10,20,30)
location.move(10,20)
location.move(10,20,30)
}
}
Scala 使用 extends 关键字来继承一个类。实例中 Location 类继承了 Point 类。Point 称为父类(基类),Location 称为子类。
override def move 为重写了父类的move方法。
继承会继承父类的所有属性和方法,Scala 只允许继承一个父类。
Scala类还可以这样定义,如果它只有一些属性,没有方法的话:
class H(var name: String) // 完全可以不要大花括号
object HelloScala {
def main(args: Array[String]): Unit = {
var h = new H("Tom")
println(h.name)
}
}
20、抽象类
Java:
abstract class AbsTeacher{
private String name;
public AbsTeacher(String name){
this.name = name
}
abstract void teach();
abstract int salary();
}
实现抽象类:
class MathTeacher extends AbsTeacher{
private String name;
public MathTeacher(String name){
super(name);
}
@Override
void teach() {
}
@Override
int salary() {
return 0;
}
}
Scala:
abstract class AbsTeacher(var name: String) {
def teach(): Unit
def salary: Int
}
实现抽象类:
class MathTeacher(val name: String) extends AbsTeacher(name) {
private val name = null
override def teach(): Unit = {
}
override def salary = 0 // 方法体如果比较简单,是可以去掉括号的
}
21、构造函数
Java:
定义一个与类名相同的方法来当作构造器
class Student{
private String name;
private int age;
private String gender;
public Student(String name,int age){
this.name = name;
this.age = age;
}
public Student(String name,int age,String gender){
this(name,age);
this.gender = gender;
}
}
Scala:
Scala中的构造器相较于Java比较特殊,分为两种:主构造器,从构造器。
在Scala中,不需要像Java一样在类中定义一个与类名相同的方法来当作构造器。
主构造器的参数列表写在类名的后面,而构造器的内容,则直接写在类定义里面,所以说,一个Scala类里面,除了方法和字段的定义以外的代码,全都是主构造器的内容。
除了主构造器外,Scala中还有从构造器,用于使用和主构造器不同的参数来初始化对象。从构造器的定义,都以def this开始。
class Student(var name: String, var age: Int) {
private var gender = _ // _是个占位符,说明等一下就会被赋值
def this(name: String, age: Int, gender: String) {
this(name, age)
this.gender = gender
}
}
注意:如果Scala类中主构造器不指定访问修饰符,默认为public。如果指定为priavte,则只允许类本身访问,防止外部实例化,如
class Student private(var name: String, var age: Int) {
private var gender = _ // _是个占位符,说明等一下就会被赋值
def this(name: String, age: Int, gender: String) {
this(name, age)
this.gender = gender
}
}
// 可以通过次构造函数来实例化
object MyScala {
def main(args: Array[String]): Unit = {
var stu = new Student("hell",30,"male")
}
}
22、内部类、外部类
Java:
class Outer{
private String name;
public Outer(String name){
this.name = name;
}
public class Inner{ // 内部类
private int num;
public Inner(int num){
this.num = num;
}
public void show(){
System.out.println(name+":"+this.num);
}
}
}
public class Main {
public static void main(String[] args) throws IOException {
Outer outer = new Outer("Tom");
Outer.Inner inner = outer.new Inner(77);
inner.show();
}
}
Scala:
class Outer(var name: String) {
class Inner(var num: Int) {
def show(): Unit = {
System.out.println(name + ":" + this.num)
}
}
}
object MyScala {
def main(args: Array[String]): Unit = {
val outer = new Outer("Tom")
val inner = new outer.Inner(77)
inner.show()
}
}
或者给外部函数起个名:
class Outer(var name: String) { outAname => // 给外部函数起个名
def foo(): Unit ={
println("hello world")
}
class Inner(var num: Int) {
def show(): Unit = {
System.out.println(name + ":" + this.num)
foo()
outAname.foo()
}
}
}
23、单例对象
Java:
class University{
private static int studentNo = 0;
public static int getStudentNo(){
studentNo += 1;
return studentNo;
}
}
public class Main {
public static void main(String[] args) {
System.out.println(University.getStudentNo());
System.out.println(University.getStudentNo());
}
}
Scala:
在 Scala 中,没有像Java中的静态方法和静态字段,Scala使用object对象来实现相同的效果。
Scala的object 对象和Scala的类的区别是,object对象不能带参数。
object University {
private var studentNo = 0
def getStudentNo: Int = {
studentNo += 1
studentNo
}
}
object HelloScala {
def main(args: Array[String]): Unit = {
println(University.getStudentNo)
println(University.getStudentNo)
}
}
伴生对象就像Java类中的静态类。
当单例对象与某个类共享同一个名称时,它被称作是这个类的伴生对象:companion object。必须在同一个源文件里定义类和它的伴生对象。类被称为是这个单例对象的伴生类:companion class。类和它的伴生对象可以互相访问其私有成员。
object University {
private var studentNo = 0
def getStudentNo: Int = {
studentNo += 1
studentNo
}
def hi(): Unit ={
var d = new University
println(d.number) // 调用类的私有成员
}
}
class University{
var id = University.studentNo // 调用伴生类的私有成员
private var number: Int = 0
def aClass(number: Int): Unit = {
this.number += number
}
}
测试:
object HelloScala {
def main(args: Array[String]): Unit = {
println(University.getStudentNo)
println(University.getStudentNo)
University.hi()
}
}
24、trait特质
trait特质是Scala中代码复用的重要单元,特质封装了方法和字段的定义 ,在Scala语言中,和Java不同的是,Scala提供特质而不是接口,特质可以同时拥有抽象方法和具体方法,类可以实现多个特质。
Java:
interface IMyLogger{
void log(String msg);
default String getEventType(String tpe){
return tpe;
}
static void sayHi(){
System.out.println("Hello world");
}
}
interface IMyMachine{
void start();
void stop();
}
class MyLogger implements IMyLogger,IMyMachine{
@Override
public void log(String msg) {
System.out.println(msg);
}
@Override
public void start() {
System.out.println("start machne");
}
@Override
public void stop() {
System.out.println("stop machne");
}
}
public class Main {
public static void main(String[] args) throws IOException {
MyLogger myLoogger = new MyLogger();
myLoogger.log("There is something wrong");
System.out.println(myLoogger.getEventType("NO_DATA"));
myLoogger.start();
myLoogger.stop();
IMyLogger.sayHi();
}
}
Scala:
以上java代码对应的Scala代码:
object IMyLogger {
def sayHi(): Unit = {
System.out.println("Hello world")
}
}
trait IMyLogger {
def log(msg: String): Unit
def getEventType(tpe: String): String = tpe
}
trait IMyMachine {
def start(): Unit
def stop(): Unit
}
class MyLogger extends IMyLogger with IMyMachine {
override def log(msg: String): Unit = {
System.out.println(msg)
}
override def start(): Unit = {
System.out.println("start machne")
}
override def stop(): Unit = {
System.out.println("stop machne")
}
}
object MyScala {
def main(args: Array[String]): Unit = {
val myLoogger = new MyLogger
myLoogger.log("There is something wrong")
System.out.println(myLoogger.getEventType("NO_DATA"))
myLoogger.start()
myLoogger.stop()
IMyLogger.sayHi()
}
}
类实现的多个特质之间用with连接。
25、特质继承特质
Java:
interface IMyLogger{
void log(String msg);
default String getEventType(String tpe){
return tpe;
}
static void sayHi(){
System.out.println("Hello world");
}
}
interface IMyMachine extends IMyLogger{
void start();
void stop();
}
class MyLogger implements IMyMachine{
@Override
public void log(String msg) {
System.out.println(msg);
}
@Override
public void start() {
System.out.println("start machne");
}
@Override
public void stop() {
System.out.println("stop machne");
}
}
public class Main {
public static void main(String[] args) throws IOException {
MyLogger myLoogger = new MyLogger();
myLoogger.log("There is something wrong");
System.out.println(myLoogger.getEventType("NO_DATA"));
myLoogger.start();
myLoogger.stop();
IMyLogger.sayHi();
}
}
Scala:
object IMyLogger {
def sayHi(): Unit = {
System.out.println("Hello world")
}
}
trait IMyLogger {
def log(msg: String): Unit
def getEventType(tpe: String): String = tpe
}
trait IMyMachine extends IMyLogger {
def start(): Unit
def stop(): Unit
}
class MyLogger extends IMyMachine {
override def log(msg: String): Unit = {
System.out.println(msg)
}
override def start(): Unit = {
System.out.println("start machne")
}
override def stop(): Unit = {
System.out.println("stop machne")
}
}
object MyScala {
def main(args: Array[String]): Unit = {
val myLoogger = new MyLogger
myLoogger.log("There is something wrong")
System.out.println(myLoogger.getEventType("NO_DATA"))
myLoogger.start()
myLoogger.stop()
IMyLogger.sayHi()
}
}
26、在对象中混特质
Java:
要通过其他方式实现
Scala:
trait IMyLogger {
def log(msg: String): Unit
}
class MyLogger extends IMyLogger {
override def log(msg: String): Unit = {
System.out.println("The error message:" + msg)
}
}
trait MyGreatLogger extends IMyLogger{
override def log(msg: String): Unit = {
println(s"@_@#${msg}")
}
}
object MyScala {
def main(args: Array[String]): Unit = {
val myLogger = new MyLogger
myLogger.log("There is something wrong")
val myLogger2 = new MyLogger with IMyLogger{ // 给对象混入特质
override def log(msg: String): Unit = {
System.out.println("#####:" + msg)
}
}
myLogger2.log("8888")
val myLogger3 = new MyLogger with MyGreatLogger // 给对象混入特质
myLogger3.log("7890")
}
}
27、对象继承特质
Java:
没有对应的
Scala:
trait IMyLogger {
def log(msg: String): Unit
}
class MyLogger extends IMyLogger {
override def log(msg: String): Unit = {
System.out.println("The error message:" + msg)
}
}
trait MyGreatLogger extends IMyLogger{
override def log(msg: String): Unit = {
println(s"@_@#${msg}")
}
}
object MyLLL extends MyLogger{
}
object MyBBB extends MyGreatLogger{
}
object MyScala {
def main(args: Array[String]): Unit = {
MyLLL.log("Hello world")
MyBBB.log("34567")
}
}
28、apply的使用
Java:
没有
Scala:
通过给类的伴生对象定义apply方法,我们就可以像Object(参数1,参数2,…,参数n) 这样调用啦。当这样调用时,实际就是调用对象中的apply方法。如下例 :
class Account private(var id: Int, balance: Double) {
}
object Account {
def apply(balance1: Double): Account = {
println("hello world")
new Account(7, balance1)
}
}
object HelloScala {
def main(args: Array[String]): Unit = {
var account = Account(88.0)
println(account.id)
}
}
29、AOP实现
AOP(Aspect Oriented Programming)指面向切面编程,将业务逻辑和系统服务(如日志服务)进行分离。AOP的主要功能是日志记录、性能统计、安全控制、事务处理、异常处理等 。在Java的Spring框架的AOP得到了大量应用。
在Scala中,AOP设计思想可以使用特质trait来实现日志事务切面的功能。Scala示例:
trait Action{ // 定义Action特质
def doAction // 定义doAction抽象方法
}
trait TBeforeAfter extends Action{
abstract override def doAction: Unit = {
println("Initialization")
super.doAction
println("Destroyed")
}
}
class Work extends Action{
override def doAction: Unit = {
println("Working....")
}
}
object HelloScala {
def main(args: Array[String]): Unit = {
val work = new Work with TBeforeAfter
work.doAction
}
}
上面的例子,首先定义了Action特质,拥有抽象方法doAction;然后再定义了TBeforeAfter特质,并重写了doAction方法,在方法里调用了super.doAction方法来实现日志事务切面功能;最后定义了class work类,继承Action特质,重写了doAction方法。
30、包对象
Sala中的包定义与Java中的一样,用于管理大型程序的命名空间。但是包对象则是Scala有,而Java没有的。Scala的的包对象中的变量 和方法可以给包中所有的类直接引用。包对象使用package object来定义。
Java:
没有
Scala:
定义包对象:
package object people {
val address = "address on the earth" // 定义于包对象people的属性address
def signature(myName: String): String = {
val signatureName = myName + "@"
signatureName
}
}
package people {
class Student {
val location = address // 引用包对象的变量
def mySignature(name: String): Unit = {// 引用包对象的方法
println(signature(name))
}
}
}
测试:
import people.Student
object HelloScala {
def main(args: Array[String]): Unit = {
var student = new Student
println(student.location)
student.mySignature("Tom")
}
}
31、包的引用
Scala的包的引用比Java的要灵活。
Java:
import java.io.*;
import java.lang.String;
Scala:
import people.Student
import java.awt.{Color,Font} // 只引用java.awt包下的Color和Font对象
import java.util.{HashMap => JavaHashMap} // 为HashMap起个别名JavaHashMap
import scala.{StringBuilder => _ } // 隐藏StringBuilder
import java.lang._ // 引用java.lang包下的所有东西
32、高阶函数
将函数用作参数或返回值的函数称为高阶函数。
Java:
java 8引入了函数式编程。函数式编程重点在函数,函数变成了Java世界里的一等公民,函数和其他值一样,可以到处被定义,可以作为参数传入另一个函数,也可以作为函数的返回值,返回给调用者。
public class Main {
public static void main(String[] args) {
Lock lock = new ReentrantLock();
int temp = new Demo().lock(lock,new Function<Integer, Integer>(){
@Override
public Integer apply(Integer integer) {
return 800;
}
},800);
System.out.println(temp);
}
}
class Demo{
public <T,R> R lock(Lock lock, Function<T,R> body,T t){
lock.lock(); // 锁上
try {
return body.apply(t);
}
finally {
lock.unlock(); // 开锁
}
}
}
再看一个java8的高阶函数的例子:
public class Main {
public static void main(String[] args) {
MyFunction cube = x -> x * x * x;
System.out.println(new Demo().sum(cube,3));
}
}
interface MyFunction {
int action(int a);
}
class Demo{
public int sum(MyFunction func,int x){
return func.action(x);
}
}
@FunctionalInterface是Java 8为函数式接口引入的一个新的注解。表明该接口是函数式接口,它只包含唯一一个抽象方法。任何可以接受一个函数式接口实例的地方,都可以用lambda表达式。
**所以可以使用lambda表达式的前提是接口里只有一个抽象方法,如上例。**所以函数式接口都可以用lamda表达式来代替。加了这个注释,你就不会糊涂写多一个抽象方法。以下这些都是比较常用的函数式接口,JDK8提供的:
java.lang.Runnable,
java.awt.event.ActionListener,
java.util.Comparator,
java.util.concurrent.Callable
java.util.function包下的接口,如Consumer、Predicate、Supplier等
Scala:
包括匿名函数、 偏应用函数、闭包、Curring函数。
匿名函数
不需要 给函数命名的函数就是匿名函数。语法构成:括号、命名参数列表、右箭头、函数体,如
var increase = (x: Int) => x + 1
偏应用函数
又称部分应用函数,是一种表达式,在函数定义中不需要提供所有的参数,只要提供一部分参数或者不提供所需要的参数,称为偏应用函数,偏是相对全而言的。所以要定义偏应用函数首先要把全应用函数定义出来,再来用_占位符来描述偏应用函数要传的参数,其他不用传的参数都 会被赋上默认值,如:
def sum(x: Int, y: Int, z: Int):Int = x + y + z //全应用函数
def fp_a = sum(1,_:Int,3) // 偏应用函数传入1、3两个参数,_占位符代表需要传入的参数
运行实例:
object HelloScala {
def sum(x: Int, y: Int, z: Int):Int = x + y + z
def fp_a = sum(1,_:Int,3) // 偏应用函数传入1、3两个参数,_占位符代表需要传入的参数
def main(args: Array[String]): Unit = {
println(fp_a(8))
println(fp_a.apply(9))
}
}
闭包:
在Scala中,任何带有自由变量的函数字面量,需要先明确自由变量的值(即需要先定义自由变量的值),只有在关闭这个自由变量开放项的前提下,函数才会运行计算出结果,称函数为闭包。闭包由代码和代码用到的任何非局部变量定义构成,如:
var more: Int = 0
var add = (x: Int) => x + more // (x: Int) => x + more 就是闭包函数,在此将赋给add。自由变量more的值变化时,函数值也会发生变化
运行实例:
object HelloScala {
var more: Int = 0
var add = (x: Int) => x + more // (x: Int) => x + more 就是闭包函数,在此将赋给add。自由变量more的值变化时,函数值也会发生变化
def main(args: Array[String]): Unit = {
println(add(10))
more = 999
println(add(10))
println(add.apply(10))
}
}
Curring函数
柯里化(Currying)指的是将原来接受两个参数的函数变成新的接受一个参数的函数的过程。新的函数返回一个以原有第二个参数为参数的函数。
(1)首先我们定义一个函数
def add(x:Int,y:Int): Int = x + y
(2)现在把这个函数变一下形
def add(x:Int)(y:Int) = x + y
这种从(1)变化到(2)的过程就叫柯里化。(2)就是Curring函数。
实现过程
add(1)(2) 实际上是依次调用两个普通函数(非柯里化函数),第一次调用使用一个参数 x,返回一个函数类型的值,第二次使用参数y调用这个函数类型的值。
最先演变成这样一个方法:
def add(x:Int)=(y:Int)=> x + y
接收一个x为参数,返回一个匿名函数,该匿名函数的定义是:接收一个Int型参数y,函数体为x+y。现在我们来对这个方法进行调用。
val result = add(1)
返回一个result,那result的值应该是一个匿名函数:(y:Int)=>1+y。
为了得到结果,我们继续调用result。
val sum = result(2)
33、Scala中常用的高阶函数
1、map函数
定义一个转换,然后将转换应用到列表的每一个元素上。
(1 to 9).map("*"*_).foreach((f: String)=>println(f))
2、filter函数
过滤元素
(1 to 9).filter( _ % 2 == 0).foreach(println)
3、reduceLeft
从左到右应用reduce函数
println((1 to 9).reduceLeft(_ * _))
4、split、sortWith函数
split函数将字符串根据指定的表达式规则进行拆分
sortWith:使用自定义的较函数进行排序
val words: String = "Spark is the most exciting thing happening in big data today"
words.split(" ").sortWith(_.length < _.length).foreach(println)
自定义高阶函数
object HelloScala {
// 自定义高阶函数
def higherOrderFunc(f: (Int) => Int,x: Int): Int = f(x)
def main(args: Array[String]): Unit = {
println(higherOrderFunc((x: Int)=>{
val a = x * 2
a
},80))
}
}
34、Scala模式匹配
Java:
switch语句
int flag = 1;
switch (flag) {
case 1:
System.out.println("登录成功!");
break;
case 2:
System.out.println("登录失败");
break;
default: {
System.out.println("未知错误400");
}
}
Scala:
val flag = 1
flag match {
case 1 =>
println("登录成功!")
case 2 =>
println("登录失败")
case _ =>
println("未知错误400")
}
Scala 提供了强大的模式匹配机制。一个模式匹配包含了一系列备选项,每个都开始于关键字 case。每个备选项都包含了一个模式及一到多个表达式。箭头符号 => 隔开了模式和表达式。
match 对应 Java 里的 switch,但是写在选择器表达式之后。即: 选择器 match {备选项}。
match 表达式通过以代码编写的先后次序尝试每个模式来完成计算,只要发现有一个匹配的case,剩下的case不会继续匹配。
不同数据类型的模式匹配:
def matchTest(x: Any): Any = x match {
case 1 => "one" // 匹配1
case "two" => 2 // 匹配字符串two
case y: Int => "scala.Int" // 用于判断传入的值是否为整型
case _ => "many" // 默认,相当于switch的default
}
// 还可以加上if守卫条件
def matchTest(x: Any): Any = x match {
case 1 => "one" // 匹配1
case "two" => 2 // 匹配字符串two
case y: Int if(y > 10) => "scala.Int" // 用于判断传入的值是否为整型
case _ => "many" // 默认
}
// 常量模式
def patternShow(x: Any): Any = {
x match {
case 5 => "王"
case true => "真"
case "test" => "字符串"
case null => "null 值"
case Nil => "空列表"
case _ => "其他常量"
}
}
// 或
def patternShow(x: Any): Any = x match {
case 5 => "王"
case true => "真"
case "test" => "字符串"
case null => "null 值"
case Nil => "空列表"
case _ => "其他常量"
}
// 变量模式
def patternShow(x: Any): Any = {
x match {
case x if(x == 5) => x
case x if(x == "scala") => x
case _ => "其他常量"
}
}
// 或
def patternShow(x: Any): Any = x match {
case x if(x == 5) => x
case x if(x == "scala") => x
case _ => "其他常量"
}
// 构造器模式
// 样例类
case class Person(name: String, age: Int)
val alice = new Person("Alice", 25)
val bob = new Person("Bob", 32)
val charlie = new Person("Charlie", 32)
for (person <- List(alice, bob, charlie)) {
person match {
case Person("Alice", 25) => println("Hi Alice!")
case Person("Bob", 32) => println("Hi Bob!")
case Person(name, age) =>
println("Age: " + age + " year, name: " + name + "?")
}
}
// 序列(Sequence)模式
val list = List("Spark","Hive","SparkSQL")
var arr = Array("SparkR","Spark Streaming","Spark MLlib")
def sequencePattern(p: Any): Any = p match {
case Array(first,second,_*) => first+","+second // _*表示剩余的内容
case List(_,second,_*) => second
case _ => "Other"
}
// 元组(Tuple)模式
val t = ("spark","hive","SparkSQl")
def tuplePattern(t: Any): Any = t match {
case (one,_,_) => one
case _ => "Other"
}
// 类型模式
def typePattern(t: Any): Any = t match {
case tt:String => "String"
case tt:Int => "Integer"
case tt:Double => "Double"
case _ => "Other Type"
}
// 变量绑定模式
var t = List(List(1,2,3),List(2,3,4))
def variableBindingPattern(t: Any): Any = t match {
case List(_,e@List(_,_,_)) => e // 变量绑定,与@符号,如果后面的模式匹配成功,则将整体匹配结果返回
case _ => Nil
}
// 注意
object HelloScala {
def matchTest(x: Any): Any = x match {
case 1 => "one"
case "two" => 2
case Int => "scala.Int" // 匹配Int类型
case _ => "many"
}
def main(args: Array[String]): Unit = {
println(matchTest(Int))
}
}
使用样例类
使用case关键字定义样例类(case classes),样例类是种特殊的类,经过优化以用于模式匹配。
在声明样例类时,下面的过程自动发生了:
- 构造器的每个参数默认都是val,除非显式被声明为var,但是并不推荐这么做;
- 自动创建伴生对象,同时在伴生对象中实现apply方法,所以在使用时可以不直接使用new关键字就可构建对象;
- 伴生对象中同样可以实现unapply方法,从而可以将样例类(case class)应用于模式匹配;
- 生成toString、equals、hashCode和copy方法,除非显示给出这些方法的定义。
// 抽象类
abstract class Person(name: String)
// 样例类
case class Student(name: String, age: Int, studentNo: Int) extends Person(name)
case class Teacher(name: String, age: Int, teacherNo: Int) extends Person(name)
case class Nobody(name: String) extends Person(name)
object HelloScala {
def main(args: Array[String]): Unit = {
val alice = new Student("Alice", 25,88)
val bob = new Student("Bob", 32,9)
val charlie = new Teacher("Charlie", 32,1)
for (person <- List(alice, bob, charlie)) {
person match {
case Student("Alice", 25,88) => println("Hi Alice!")
case Student(name,age,studentNo) => println(s"${name},Age:${age},NO.${studentNo}")
case Teacher(name, age,teacherNo) =>println(s"${name},Age:${age},NO.${teacherNo}")
case Nobody(name) => println(name)
}
}
}
}
从上例可知,直接使用构造器模式便 可以将对象内容提取出来,这里的构造器模式其实调用的是unapply方法。为验证模式匹配时,后面的实现原理确实是通过unapply方法来实现的。编译器为我们生成apply和unapply这两个重要方法。其中apply方法用于不直接使用new显式创建对象,而unapply方法则用于模式匹配时对对象进行析取。当然这两个方法也可以自己动手写,如:
// 抽象类
abstract class Person(name: String)
// 样例类
case class Student(name: String, age: Int, studentNo: Int) extends Person(name)
case class Teacher(name: String, age: Int, teacherNo: Int) extends Person(name)
case class Nobody(name: String) extends Person(name)
object Student{
// 自己定义的apply方法
def apply(name: String, age: Int, studentNo: Int): Student = new Student(name, age, studentNo)
// 自己定义的unapply方法
def unapply(student: Student):Option[(String,Int,Int)] = {
if(student != null){
Some(student.name,student.age,student.studentNo)
}else{
None
}
}
}
object HelloScala {
def main(args: Array[String]): Unit = {
val alice = new Student("Alice", 25,100)
val bob = new Student("Bob", 32,9)
val charlie = new Teacher("Charlie", 32,1)
for (person <- List(alice, bob, charlie)) {
person match {
case Student("Alice", 25,88) => println("Hi Alice!")
case Student(name,age,studentNo) => println(s"${name},Age:${age},NO.${studentNo}")
case Teacher(name, age,teacherNo) =>println(s"${name},Age:${age},NO.${teacherNo}")
case Nobody(name) => println(name)
}
}
}
}
序列模式匹配原理
它背后实现的原理也是通过样例类来实现的,但与前面构造器模式使用unapply方法不同的是,序列模式使用的是unapplySeq方法。
List伴生对象如下:
object List extends SeqFactory[List]{
override def apply[A](elems: A*): List[A] = elems.toList
override def unapplySeq[A](x: List[A]): Some[List[A]] = Some(x)
// ... 其他方法...
}
35、封闭类sealed class在模式匹配中的应用
在进行模式匹配时,常常希望将所有可能匹配的情况都列举出来,如果有遗漏,编译器应该给出相应的警告,Scala语言通过使用sealed class(封闭类)提供该语法支持。示例如下:
// 抽象类,在前面加关键字sealed
sealed abstract class Person(name: String)
// 样例类
case class Student(name: String, age: Int, studentNo: Int) extends Person(name)
case class Teacher(name: String, age: Int, teacherNo: Int) extends Person(name)
case class Nobody(name: String) extends Person(name)
object HelloScala {
def main(args: Array[String]): Unit = {
val alice = new Student("Alice", 25,100)
val bob = new Student("Bob", 32,9)
val charlie = new Teacher("Charlie", 32,1)
for (person <- List(alice, bob, charlie)) {
person match {
case Student("Alice", 25,88) => println("Hi Alice!")
case Student(name,age,studentNo) => println(s"${name},Age:${age},NO.${studentNo}")
// 注释下面两行,编译器就会发出警告,因为它们都是封闭在Person类中的类,在模式匹配中,必须罗列出来。
case Teacher(name, age,teacherNo) =>println(s"${name},Age:${age},NO.${teacherNo}")
case Nobody(name) => println(name)
}
}
}
}
上面的代码里,只要match没有列举所有可能匹配的情况,编译器就发出警告。
36、for循环控制结构中的模式匹配
// 变量模式匹配
for(x <- List("Spark","Hive","Hadoop")){
println(s"变量:${x}")
}
// 变量绑定模式匹配
for(x@"Spark" <- List("Spark","Hive","Hadoop")){
println(s"变量绑定:${x}")
}
// 匹配特定内容
for((x,2) <- List(("Spark",100),("Hive",2),("Hadoop",2))){
println(s"匹配特定内容:$x")
}
37、正则表达式模式匹配
| 符号 | 功能描述 |
|---|---|
| . | 匹配一个字符 |
| [] | 限定匹配 |
| $ | 匹配行结束符 |
| ^ | 匹配行开始符 |
| * | 匹配0或多个字符 |
| / | 转义符 |
| () | 分组符 |
| + | 匹配1或多次 |
| ? | 匹配0或1次 |
| {n} | 匹配n次 |
| {n,} | 匹配至少n次 |
| {n,m} | 至少匹配n次,最多m次 |
// 进行邮箱匹配,并提取邮箱名
val mailRegex = "([\\w-]+(\\.[\\w-]+)*)@[\\w-]+(\\.[\\w-]+)".r // .r 代表创建正则表达式对象
// 测试字符串
val mailTestStr = "如果有任何疑问,请致电:[email protected]或联系[email protected]"
for(matchString <- mailRegex.findAllIn(mailTestStr)){
println(matchString)
}
38、Scala集合
与Java不同,Scala集合分为可变集合和不可变集合两种。
可变集合就是可以对集合进行增加、删除、修改等扩展性的操作。
如果对不可变集合进行增加、删除、修改等扩展性的操作都会返回一个新的集合,而不会直接修改原有的集合。
import scala.collection.mutable.{ArrayBuffer, Buffer}
object HelloScala {
def f(a: Any): Unit = {
println(a)
}
def ff(a: Any): List[Any] = {
List(a,"@")
}
def sum(a: Int, b: Int, c: Int): Int = {
a + b + c
}
// 偏函数 PartialFunction,是一个数学概念它不是"函数"的一种, 它跟函数是平行的概念。要与偏应用函数区分开哦
val partialFunc = new PartialFunction[Int,Int]{
override def isDefinedAt(x: Int): Boolean = x != 0
override def apply(v1: Int): Int = v1+10
}
def main(args: Array[String]): Unit = {
val xs = Set(5, 4, 3, 6, 7)
val bs = Set("a","b","c","d","e","f")
// 对xs中的每一个元素执行函数f
xs foreach f
// 将两个集合合成一个集合
println(xs ++ bs)
// 将返回值为集合的函数ff应用到xs集合的每个元素上
println(xs flatMap ff)
// 将偏函数应用于每个元素上,然后返回一个新的集合
println(xs collect partialFunc)
// 将集合转成数组
val arr = xs.toArray
arr foreach println
// 将集合转成list
println(xs.toList)
// 将集合转成迭代器
val interable = xs.toIterable
interable foreach println
// 将集合转成序列
println(xs.toSeq)
// 将集合转成索引序列
println(xs.toIndexedSeq)
// 将集合转成一个延迟计算的流
println(xs.toStream)
val list = List(1,2,3)
// 将集合转成Set
println(list.toSet)
val ml = Set((1, "helo"),(2, "Too"),(3, "oohelo"),(3, "pp-pToo"))
// 将集合转成映射表map
println(ml.toMap)
// 把集合中的元素复制到buf缓冲区
val buf:ArrayBuffer[Any] = ArrayBuffer()
xs copyToBuffer buf
println(buf)
// 把集合的元素复制到arr的起始索引为s处,最多复制n个
val myArr: Array[Any] = Array("a","b","c","d","e")
val s = 2
val n = 2
xs copyToArray (myArr,s,n)
myArr foreach print
// 判断集合是否为空
println(xs.isEmpty)
// 判断集合是否不为空
println(xs.nonEmpty)
// 计算集合元素的个数
println(xs.size)
// 如果集合大小是有限的,返回true
println(xs.hasDefiniteSize)
// 返回集合第一个元素
println(xs.head)
// 返回选项值中的第一个元素
println(xs.headOption)
// 返回集合最后一个元素
println(xs.last)
// 返回选项值的最后一个元素
println(xs.lastOption)
// 查找满足条件的元素
println(xs find ((x:Int) => x > 6))
// 获取除xs.head外的其余部分
println(xs.tail)
// 获取除xs.last外的其余部分
println(xs.init)
// 切片操作,从from到to,左闭右开
println(xs slice (2,4))
// 获取集合的前n个元素
println(xs take 3)
// 获取除xs take n以外的元素组成的集合
println(xs drop 3)
// 获取集合xs中满足谓词p最多的元素所组成的集合
println(xs takeWhile ((x: Int)=>x > 3))
// 获取集合xs takeWhile p中满足谓词p以外的元素所组成的集合
println(xs dropWhile ((x: Int)=>x > 3))
// 过滤
println(xs filter ((x: Int) => x < 5))
println(xs withFilter ((x: Int) => x < 5))
println(xs filterNot ((x: Int) => x < 5))
// 从指定位置拆分集合
println(xs splitAt 2)
// 根据谓词p拆分集合
println(xs span ((x: Int)=>x == 5))
// 把集合拆分两个集合,符合谓词p的元素赋予一个集合
println(xs partition ((x: Int)=>x == 5))
// 分组
println(xs groupBy ((x: Int)=>x > 5))
// 判断是否所有元素都符合谓词
println(xs forall ((x: Int)=> x > 1))
// 判断是否存在符合谓词p的元素
println(xs exists ((x: Int)=> x > 1))
// 符合谓词p的元素的个数
println(xs count ((x: Int)=> x > 1))
// 返回集合xs中数值元素的和
println(xs.sum)
// 返回集合xs中数值元素的积
println(xs.product)
// 返回集合xs中最小值
println(xs.min)
// 返回集合xs中最大值
println(xs.max)
// (0/:xs)(op)以z为初值,依次从左到右对集合中的元素进行二元操作op
println((0/:xs)(_+_))
println((2/:xs)(_*_))
println(xs.foldLeft(3)(_*_))
// (xs:\z)(op)以z为初值,依次从右到左对集合中的元素进行二元操作op
println((xs:\2)(_*_))
println(xs.foldRight(3)(_*_))
// 依次从左到右对集合中的元素进行二元操作op
println(xs reduceLeft (_+_))
// 依次从右到左对集合中的元素进行二元操作op
println(xs reduceRight (_+_))
// 从集合xs生成一个视图
println(xs.view)
// 从集合指定索引范围内的元素生成一个视图
println(xs.view(1,3))
// 返回一个字符串,该字符串是集合xs.toString结果的前缀
println(xs.stringPrefix)
// 把一个字符串添加到StringBuilder对象b中,该字符串显示集合中所有的元素,以start开头,以end结尾,同时元素之间以sep作为分隔符。
val b = new StringBuilder()
println(xs addString (b,"{","|","}"))
// 把一个集合转换为一个字符串
println(xs mkString ("{","|","}"))
}
}
39、序列(Seq)
数学上,序列是被排成一列的对象 ,每个元素不是在其他 元素之前,就是在其他 元素之后。在Scala中,使用trait Seq来表示序列。由于序列是有序的,因此可以迭代访问其中的每个元素,索引位置从0开始计数。在Scala中,序列有可变序列和不可变序列之分。
val xs = Seq(11,22,32,44,55,9,22,32,44,55)
// 获取索引为i的元素
println(xs(2))
println(xs apply 2)
// 测试是否包含i
println(xs isDefinedAt 2)
// 序列长度
println(xs.length)
// 如果xs的长度小于10,返回-1,如果xs的长度大于10,返回+1,如果等于10,返回0
println(xs lengthCompare 10)
// 返回xs的索引范围,从0到xs.length - 1
println(xs indices)
println(xs.indices)
// 第一个等于22的元素的索引
println(xs indexOf 22)
// 最后一个等于22的元素的索引
println(xs lastIndexOf 22)
// 第一个包含子序列的索引
val ys = Seq(55,11,22)
println(xs indexOfSlice ys)
// 最后一个包含子序列的索引
println(xs lastIndexOfSlice ys)
// 第一个满足谓词p的索引
println(xs indexWhere ((x: Int) => x > 10))
// 返回序列xs中,从i开始,并满足条件p的元素的最长连续片段的长度
println(xs segmentLength ((x: Int) => x > 10,3))
// 返回序列xs中,满足条件p的先头元素的最大个数
println(xs prefixLength ((x: Int) => x > 10))
val ys = Seq(10,20,30,10)
// 在序列xs前加88得到新的序列
println(88 +: xs)
// 在序列xs后加90得到新的序列
println(xs :+ 90)
// 在序列xs后追加8,直到序列长度等于30得到的新的序列
println(xs padTo(30,8))
// 将xs中第2个元素开始的2个元素替换为ys所得的序列
println(xs patch(2,ys,2))
// 将索引为1的元素替换为999
println(xs updated(1,999))
// 以标准顺序进行排序
println(xs.sorted)
println(xs sorted)
// 按给定的函数进行排序
println(xs.sortWith((x: Int, y: Int)=> x > y))
//
println(xs.sortBy((x : Int) => x > 20))
// 反转xs的序列
println(xs reverse)
println(xs.reverse)
// 获取xs的迭代器,并遍历它
xs.reverseIterator foreach println
// 反序遍历xs
xs.reverseMap(println)
// 序列是否以某个序列开头
println(xs.startsWith(Seq(11,22,32,44)))
// 序列是否以某个序列结束
println(xs.endsWith(Seq(44,55)))
// 序列是否包含某个值
println(xs.contains(55))
// 是否包含指定序列
println(xs.containsSlice(Seq(11,22,32)))
// 按某个判断式,测试两个序列中,对应的元素是否符合判断式
val ys1 = Seq(66,77,88)
val xs1 = Seq(55,66,77)
println((xs1 corresponds ys1)(_ < _))
// 交集
val ys2 = Seq(11,33,22)
println(xs intersect ys2)
// 差集
println(xs diff ys2)
// 并集
println(xs union ys2)
println(xs ++ ys2)
// 去重
println(xs distinct)
println(xs.distinct)
40、列表List
列表是不可变的集合类,即不能修改列表的元素。列表具有递归结构,而数组是连续的。
列表的基础构建块的操作:
- Nil(空列表)
- ::(读cons)中缀操作符,遵循右结合规则
val ls: List[Int] = List(10,22,33,4,55,66,77)
// 等价于上面的创建
val lls: List[Int] = 10::22::33::4::55::66::77::Nil
// 列表第一个元素
println(ls head)
println(ls.head)
// 列表除第一个元素外的所有元素
println(ls tail)
println(ls.tail)
// 列表是否为空
println(ls.isEmpty)
println(ls isEmpty)
// 在列表头加插入999
println(999::ls)
// 在空列表中加入88
println(88::Nil)
println(lls)
41、集合Set
不可重复,且无序。
Java:
Set<String> stringSet = new HashSet<>();
stringSet.add("C");
stringSet.add("D");
stringSet.add("E");
// 修改操作
stringSet.size();// 统计集合中元素的个数
boolean emptyOrNot = stringSet.isEmpty();// 判断集合是否为空
boolean containOrNot = stringSet.contains("2"); // 判断集合中是否存在某个函数
// 批量操作
List<String> tempList = new ArrayList<>();
tempList.add("A");
tempList.add("B");
boolean containsAllOrNot = stringSet.containsAll(tempList); // 判断集合中是否包含某个集合
// 迭代器
Iterator<String> iterator = stringSet.iterator(); // 返回集合中的迭代器
//修改操作
stringSet.add("Hello world"); // 向集合添加元素
stringSet.remove(0); // 移除指定索引的元素
stringSet.remove("Hello world"); //移除指定的元素
Set<String> tmp = new HashSet<>();
tmp.add("Hi");
tmp.add("Bye");
stringSet.addAll(tmp); // 向集合中添加一个集合
stringSet.removeAll(tmp); // 移除集合中一个集合
stringSet.retainAll(tmp); // 判断集合中是否包含某个集合
stringSet.clear(); //清空元素
Scala:
不可变Set的操作
val xs = Set(2,33,44,5,55,77,88)
//
println(xs contains 88)
println(xs.contains(99))
// 是否包含某个元素
println(xs(55))
// xs是否存在某个子集
println(xs subsetOf Set(55,2,44))
// 返回包含两个集合的集合
val ys = Set(10,30,50)
println(xs ++ ys)
// 返回除指定元素外的元素集合
println(xs - 88)
// 返回除指定元素集合外的元素集合
println(xs - (33,44,55))
// 返回元素集合和某个元素的集合
println(xs + 100)
// 返回元素集合和某个元素集合的集合
println(xs + (222,333,444))
// 是否为空
println(xs.isEmpty)
println(xs isEmpty)
// 交集
val yys = Set(33,445,6,7,8,9)
println(xs & yys)
println(xs intersect yys)
// 并集
println(xs union yys)
//差集
println(xs diff yys)
println(xs &~ yys)
可变Set相对不可变Set增加的操作
val xs = mutable.Set(2,33,44,5,55,77,88)
// 在集合xs中添加元素100
println(xs + 100)
// 在集合xs中添加元素集合
println(xs += (70,80,90))
// 在集合xs中添加元素集合
val ys = Set(1,2,3)
println(xs ++ ys)
// 在集合xs中添加元素1000,成功true,失败(已存在)false
println(xs add 1000)
println(xs)
// 在集合xs中删除某个元素
println(xs -= 77)
// 在集合xs中删除某个元素集合
println(xs -= (1,33,44))
// 在集合xs中删除某个元素 成功true,失败(不存在)false
println(xs remove 88)
println(xs)
// 只保留xs中满足条件p的元素
xs retain((p: Int)=> p > 10)
println(xs)
// true表示,如果集合中没有555就添加进去
xs(555) = true
println(xs)
// false表示,如果集合中有55就把它删除掉
xs(55) = false
println(xs)
// 清空列表
println(xs.clear())
42、映射
映射同样有可变映射和不可变映射。
不可变映射
val ms: Map[Int, String] = Map(1 -> "one", 2 -> "two", 3 -> "three")
// 获取某个键关联的值
val d = ms get 1
println(d.get)
// 获取某个键关联的值(Option类型的)
println(ms get 1)
println(ms get 4) // None
// 获取某个键关联的值
println(ms(1))
println(ms apply 1)
// 获取某个键关联的值,不存在则返回默认值
println(ms getOrElse(4, "No Value"))
// 是否包含与某个键关联的映射
println(ms contains 3)
// 是否包含与某个键关联的映射
println(ms isDefinedAt 2)
// 返回当前映射与指定映射的映射集合
println(ms + (4 -> "four"))
// 返回当前映射集合与指定映射集合的映射集合
println(ms + (5 -> "five", 6 -> "six"))
// 返回当前映射集合与指定映射集合的映射集合
val kvs = Map(7 -> "sever", 8 -> "eight")
println(ms ++ kvs)
// 修改某个键关联的值,若不存在, 不添加,事实并不是真的修改原映射中的键值,而是重新生成一个
println(ms updated(1, "ONE"))
println(ms updated(10, "ONE"))
println(ms)
println(ms + (1 -> "OONE"))
// 返回除去指定键外的映射集合
println(ms - 1)
println(ms - (2, 3))
// 返回映射集合的键的集合
println(ms keys)
println(ms.keys)
// 返回映射集合的键的集合
println(ms.keySet)
println(ms keySet)
// 返回映射集合的键的迭代器
ms.keysIterator foreach println
println(ms.values)
// 返回映射集合的值的迭代器
ms.valuesIterator foreach println
// 返回键符合过滤条件的映射集合
println(ms filterKeys((p: Int)=> p > 1))
// 返回值符合过滤条件的映射集合
println(ms mapValues((f: String) => f.length > 3))
可变映射
val ms: mutable.Map[Int, String] = mutable.Map(1 -> "one", 2 -> "two", 3 -> "three")
// 向映射中添加键值,若存在则修改其值
ms(99) = "NinetyNine"
println(ms)
// 向映射中添加键值,若存在则修改其值
ms += (5 -> "Five")
println(ms)
// 向映射中添加键值,若存在则修改其值
ms += (6 -> "Five", 7 -> "Sever")
println(ms)
// 向映射中添加键值,若存在则修改其值
val kvs = Map(9 -> "Nine", 10 -> "Ten")
ms ++= kvs
println(ms)
// 向映射中添加键值,若存在则修改其值
ms put (11,"Eleven")
println(ms)
// 向映射中添加键值,若存在k,则返回k,否则添加此键值,并返回添加键关联的值
println(ms getOrElseUpdate(11,"ELEVEN"))
// 从映射中删除以k为键的映射关系
ms -= 2
println(ms)
// 从映射中删除以集合中的k的映射关系
ms -= (3,4,5)
println(ms)
// 从映射中删除以k为键的映射关系
ms remove 7
println(ms)
// 仅保留映射中满足条件的键的映射关系
println( ms retain ((k:Int,v:String)=> k > 1))
// 复制映射关系
val cloneMs1 = ms.clone
val cloneMs2 = ms clone
val cloneMs3 = ms.clone()
println(cloneMs1)
// 转换映射关系
ms transform ((k: Int, v: String) => s"${v}Hello")
println(ms)
43、泛型
泛型,即 “参数化类型”,将类型参数化,可以用在类,接口,方法上。提高代码的重用性和程序安全性。
泛型类的声明和非泛型类的声明类似,泛型接口只是多了在类名后面添加了类型参数声明部分
Java:
// 泛型接口
interface BoxInterface<T>{
void show(T t);
}
// 声明一个泛型类
class Box<T> implements BoxInterface<T>{
private T t;
public void add(T t) {
this.t = t;
}
// 泛型方法
public T get() {
return t;
}
@Override
public void show(T t) {
System.out.println(t.toString());
}
}
class MyComparator{
// 泛型方法
public <T extends Comparable> boolean comp(T a,T b){
return a.compareTo(b) > 0;
}
}
public class Main {
public static void main(String[] args) {
Box<String> stringBox = new Box<>();
stringBox.add("Hello world");
System.out.println(stringBox.get());
stringBox.show("Hello world");
MyComparator myComparator = new MyComparator();
System.out.println(myComparator.comp("Hello","world"));
}
}
Scala:
Scala也采用了Java的泛型擦除模式,即类型是编译期的,在运行时会被“擦拭”掉,就是运行时看不到类型参数。Scala中,类、特质、函数都可以带类型参数。类型参数使用方括号来定义,
// 类
class Stack[A] protected(protected val elements:List[A])...
// 特质
trait SSeq[A] extends PartialFunction[Int,A]...
// 函数
def newBuuilder[A]():Builder[A,Seq[A]]= immutable.Seq.newBuilder[A]
Scala泛型类的新类型构建与单纯传统的构造器的实例构建相比:
(1)泛型类的新类型构建:为参数化的类型,指定具体的类型
(2)单纯传统的构造器的实例构建:为具体类型的参数,指定具体的值,就是各自具体化在定义时所参数化的对象。
Triple的定义:
object Triple {
def apply[A, B, C](x: A, y: B, z: C) = Tuple3(x, y, z)
def unapply[A, B, C](x: Tuple3[A, B, C]): Option[Tuple3[A, B, C]] = Some(x)
}
我们可以为参数化的类型,指定具体的类型:
val myTriple = Triple[Int, String, String](1,"Tome","jr Tome")
java是通过传给它的参数来指定它的具体类型的。
44、泛型限定
Java:
泛型限定就是对操作的数据类型限定在一个范围之内。限定分为上限和下限。
| 界定类型 | 语法 | 说明 |
|---|---|---|
| 类型上界 | 或 | 类型A是T的子类 |
| 类型下界 | 或 | 类型A是T的父类,直至Object |
| 多重限定 | 类型A同时是T和Y的子类 |
注意: 多重限定中,多个限定用“&”分隔开,且限定中最多只能有一个类,可以有多个接口;如果有类限定,类限定必须放在限定列表的最前面 。
// 声明一个泛型限定 ? super 和 ? extends
class Base{}
class SonClass extends Base{}
class Demo1 {
public static <T> void copy(List<? super T> dest, List<? extends T> src) {
int srcSize = src.size();
if (srcSize > dest.size())
throw new IndexOutOfBoundsException("Source does not fit in dest");
for (int i = 0; i < srcSize; i++) {
dest.add(i,src.get(i));
}
}
}
public class Main {
public static void main(String[] args) {
List<Base> list1 = new ArrayList<>();
list1.add(new Base());
list1.add(new Base());
// 或 因为 Object是Base的父类
// List
// list1.add(new Base());
// list1.add(new Base());
List<SonClass> list2 = new ArrayList<>();
list2.add(new SonClass());
list2.add(new SonClass());
Demo1.copy(list1,list2);
for (Base son: list1) {
if(son instanceof SonClass){
System.out.println("SonClass");
}
}
}
}
Scala:
| 界定类型 | 语法 | 说明 |
|---|---|---|
| 类型上界 | A <: T | 类型A必须是T的子类 |
| 类型下界 | A >: T | 类型A必须是T的父类 |
| 同时指定类型的上下界 | A >: T <: Y | 类型可以是A。或者是T的父类,或者是Y的子类 |
| 多重上界限定 | A <: T with Y | 类型可以是A。或者同时是T和Y的子类 |
| 多重下界限定 | A >: T with Y | 类型可以是A。或者同时是T和Y的父类 |
举些例子来说明一下:
类型上界
// 类型T必须是Comparable[T]的子类
class Pair[T <: Comparable[T]](val first: T, val second: T){
def bigger: T = if(first.compareTo(second) > 0) first else second
}
// 测试
object HelloScala {
def main(args: Array[String]): Unit = {
val myPair = new Pair[Integer](1,3)
println(myPair.bigger)
// 如下式所示,如果没有指明泛型类型,编译器会自己去推断,但是推断的结果是Int,Int不是Comparable的子类,所以会报错
//val myPair1 = new Pair(4,6)
//println(myPair1.bigger)
// 如下式所示,就不会报错,虽然没有指明参数化类型,但是编译器推断出它们的类型String是Comparable的子类,所以不会报错
val stringPair = new Pair("Hello","Spark")
println(stringPair.bigger)
}
}
类型下界
class PairLowerBound[T](val first: T, val second: T){
// 类型A必须是T的父类
def replaceFirst[ A >: T](newFirst: A): PairLowerBound[A] = new PairLowerBound[A](newFirst,second)
}
// 测试
class Person( val name: String, val age: Int)
class Student( name: String, age: Int, val stdNum: Int) extends Person(name,age)
object HelloScala {
def main(args: Array[String]): Unit = {
val pairLowerBound = new PairLowerBound[Student](new Student("Tome",12,1222),new Student("Jhon",12,1333))
// 如下例注释部分,泛型必须是Student的父类,否则会报错
//val people = pairLowerBound.replaceFirst[String]("asfd")
val people = pairLowerBound.replaceFirst[Person](new Person("Lily",12))
println(people.first.name)
// 如下例,如果没有指明泛型类型,编译器会根据所给的具体参数进行推断
val people1 = pairLowerBound.replaceFirst(new Person("Lily",12))
println(people1.first.name)
}
}
Scala除了有与Java相对应的上下界定之外还有视图界定、上下文界定
| 界定类型 | 语法 | 说明 |
|---|---|---|
| 视图界定 | A <% T | 类型A可以被隐式转换成类型T |
| 上下文界定 | A : T | 类型A存在一个T[A]的隐式值 |
| 多视图界定 | A <% T1[A] <% T2[A] | 类型A可以隐式转换为T1[A]和T2[A]类型 |
| 多上下文界定 | A : T : ClassTag | 类型A同时T[A]和ClassTag[A]的隐式值 |
下面我们来举一些例子来说明 :
视图界定
object HelloScala {
def main(args: Array[String]): Unit = {
// PairNotPerfect类的参数化类型是T <% Comparable[T],下面的代码推断出T为String,而String是Comparable[T]的子类,可以直接调用compareTo方法
// PairNotPerfect1类的参数化类型是T <: Comparable[T]时,如
// val pair = new PairNotPerfect1(3,5);
// println(pair.bigger)
// 上面就会报错,为什么?上面推断出参数化类型为Int,因为T必须是Comparable[T]子类型,而Int不满足,所以无法调用compareTo方法
val pair = new PairNotPerfect("Spark","Hadoop")
println(pair.bigger)
// airNotPerfect类的参数化类型是T <% Comparable[T],下面推断出类型为Int,但代码中在Int上调用了compareTo操作,
// 因此需要做一个隐式转换,Int最终会隐式转换为RichInt,因为RichInt继承了Comparable的compareTo方法,所以现在就可以做compareTo操作了。
val pair1 = new PairNotPerfect(3,5)
println(pair1.bigger)
// PairBetter的参数化类型为T <% Ordered[T],下面代码,推断类型为Int,但代码中在Int上调用了compareTo操作,
// 因此需要做一个隐式转换,之后就可以了。
val pairBetter = new PairBetter(5,6)
println(pairBetter.bigger)
}
}
// 上界界定,要求T必须是 Comparable[T]的子类型
class PairNotPerfect1[ T <: Comparable[T]](val first: T, val second: T){
def bigger = if(first.compareTo(second) >0)first else second
}
// 视图界定:声明参数化的类型T存在一个到类型Comparable[T]的隐式转换
class PairNotPerfect[T <% Comparable[T]](val first: T, val second: T){
def bigger = if(first.compareTo(second) >0)first else second
}
// 视图界定:声明参数化的类型T存在一个到类型Ordered[T]的隐式转换
class PairBetter[T <% Ordered[T]](val first: T, val second: T){
def bigger = if(first > second)first else second
}
上下文界定:
object HelloScala {
def main(args: Array[String]): Unit = {
val pair = new PairOrdering[Int](5,6)
println(pair.bigger)
val pair1 = new PairOrdering("Spark","hello")
println(pair1.bigger)
}
}
// 参数化类型T: Ordering指明了存在一个类型为Ordering[T]隐式值
// 参数化类型的定义已经保证了存在这么一个隐式值
// 因此在未明确指定bigger函数的参数的情况下,bigger函数将会使用该隐式值作为参数
// 由于bigger函数的参数的隐式值为Ordering[T]类型,因此可以调用 Ordering[T]提供的接口compare
// Ordering中已经定义了放多常见类型T的Ordering[T]隐式值
class PairOrdering[T: Ordering](val first: T, val second: T) {
def bigger(implicit ordered: Ordering[T]) = {
if(ordered.compare(first,second) > 0)first else second
}
}
多上下文界定:
object HelloScala {
// 多重上下文界定,要求存在T到M_A和M_B的隐式值
def foo[T: M_A : M_B](i: T) = println("OK")
def main(args: Array[String]): Unit = {
implicit val a = new M_A[Int]
implicit val b = new M_B[Int]
// 此时T类型为Int,存在Int到M_A的隐式值a,到M_B的隐式值b
foo(8)
}
}
class M_A[T]
class M_B[T]
45、implicit使用
查找范围
当需要查找隐式对象、隐式方法、隐式类时,查找的范围是:
1.当前代码作用域下查找。
2.如果当前作用域下查找失败,会在隐式参数类型的作用域里查找。
类型的作用域是指与该类型相关联的全部伴生模块,一个隐式实体的类型T它的查找范围如下:
(1)如果T被定义为T with A with B with C,那么A,B,C都是T的部分,在T的隐式解析过程中,它们的伴生对象都会被搜索
(2)如果T是参数化类型,那么类型参数和与类型参数相关联的部分都算作T的部分,比如List[String]的隐式搜索会搜索List的伴生对象和String的伴生对象
(3) 如果T是一个单例类型p.T,即T是属于某个p对象内,那么这个p对象也会被搜索
(4) 如果T是个类型注入S#T,那么S和T都会被搜索
一次性规则
编译器在需要使用 implicit 定义时,只会试图转换一次。
无歧义
对于隐式参数,如果查找范围内有两个该类型的变量,则编译报错。
对于隐式转换,如果查找范围内有两个从A类型到B类型的隐式转换,则编译报错。
隐式参数
在声明方法时,在参数的前面添加implict修饰符,当调用方法时,如果没有传递该参数,那么编译器会去上述的查找范围去查找隐式参数,如果存在,就使用查到的隐式参数作为参数值。
隐式转换
在两种情况下会使用隐式转换:
①调用方法时,传递的参数类型与方法声明的参数类型不同时,编译器会在查找范围下查找隐式转换,把传递的参数转变为方法声明需要的类型。
②调用方法时,如果对象没有该方法,那么编译器会在查找范围内查找隐式转换,把调用方法的对象转变成有该方法的类型的对象。
46、类型约束
类型约束是Scala类库提供的特性。
| 界定类型 | 语法 | 说明 |
|---|---|---|
| 类型等同约束 | T =:= U | 测试T类型是否等同于U类型 |
| 子类型约束 | T <:< U | 测试T类型是否为U类型的子类 |
| 视图(隐式)转换约束 (在Scala2.10中被废弃了) | T <%< U | 测试T类型能否被视图(隐式)转换为U类型 |
object HelloScala {
def main(args: Array[String]): Unit = {
// A <:< B 表示A类型是B类型的子类型
def rocky[T](i:T)(implicit ev: T <:< java.io.Serializable): Unit ={
println("Spark ho ho ho")
}
// Error:(12, 10) Cannot prove that Int <:< java.io.Serializable.
// rocky(1)
// String是java.io.Serializable的子类型
rocky("Spark")
// A =:= B 表示A类型等同于B类型
def fish[T](f:T)(implicit ev:T =:= java.lang.String)={
println("Hello world")
}
fish("Baidu")
// fish(2)
}
}
47、型变
Scala型变注释,也称变化型注释,是定义类型抽象的时候就指定的。泛型类、特质的继承关系与对应的参数化类型的继承关系直接的变化关系,有三种:
假设当前存在类D和B,其中D类为B类的子类,对应存在 一个泛型类A[T],那么对应的3种关系如下:
| 型变类型 | 语法 | 说明| |
|---|---|---|
| 协变 | A[+T] | A[D]是A[B]的子类,即A[T]继承层次中的父子关系与参数化类型T的父子关系一致,或者说泛型与它的类型参数保持协变(或有弹性的)的子类型化 |
| 逆变 | A[-T] | A[B]是A[D]的子类,即A[T]继承层次中的父子关系与参数化类型T的父子关系相反,或者说泛型与它的类型参数是逆变的子类型化 |
| 不变 | A[T] | A[B]和A[D]之间没有父子继承关系(注:当且仅当 B =:= D时,A[B]是A[D]子类) |
类型参数前面的+号和-号被称为型变注意。
在开发过程中,编译器会帮忙检查型变的使用是否正确,检查的规则如下:
- +T注释:声明类型T只能用于协变的位置
- -T注释:声明类型T只能用于逆变的位置
举例子说明一下:
协变
协变示意图
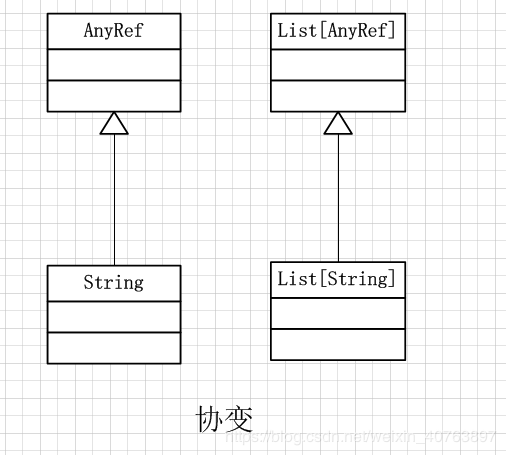
Java中不存在协变:
java.util.List<String> s1=new LinkedList<String>();
java.util.List<Object> s2=new LinkedList<Object>();
//下面这条语句会报错
//Type mismatch: cannot convert from
// List to List
s2=s1;
虽然在类层次结构上看,String是Object类的子类,但List
// 定义自己的List类
class List[T](val head: T, val tail: List[T])
object NonVariance {
def main(args: Array[String]): Unit = {
// 编译报错
// type mismatch; found :
// cn.scala.xtwy.covariance.List[String] required:
// cn.scala.xtwy.covariance.List[Any]
// Note: String <: Any, but class List
// is invariant in type T.
// You may wish to define T as +T instead. (SLS 4.5)
val list:List[Any]= new List[String]("Hello world",null)
}
}
可以看到,当不指定类为协变的时候,只是一个普通的scala类,此时它跟java一样是具有类型安全的,称这种类是非变的(Nonvariance)。scala的灵活性在于它提供了协变与逆变语言特点供你选择。上述的代码要使其合法,可以定义List类是协变的,泛型参数前面用+符号表示,此时List就是协变的,即如果T是S的子类型,那List[T]也是List[S]的子类型。代码如下:
//用+标识泛型T,表示List类具有协变性
class List[+T](val head: T, val tail: List[T])
object NonVariance {
def main(args: Array[String]): Unit = {
val list:List[Any]= new List[String]("Hello world",null)
}
}
上述代码将List[+T]满足协变要求,但往List类中添加方法时会遇到问题,代码如下:
class List[+T](val head: T, val tail: List[T]) {
//下面的方法编译会出错
//covariant type T occurs in contravariant position in type T of value newHead
//编译器提示协变类型T出现在逆变的位置
//即泛型T定义为协变之后,泛型便不能直接
//应用于成员方法当中
def prepend(newHead:T):List[T]=new List(newHead,this)
}
object Covariance {
def main(args: Array[String]): Unit = {
val list:List[Any]= new List[String]("Hello world",null)
}
}
必须将成员方法也定义为泛型,代码如下:
class List[+T](val head: T, val tail: List[T]) {
//将函数也用泛型表示
//因为是协变的,输入的类型必须是T的超类
def prepend[U>:T](newHead:U):List[U]=new List(newHead,this)
override def toString()=""+head
}
object Covariance {
def main(args: Array[String]): Unit = {
val list:List[Any]= new List[String]("Hello world",null)
println(list)
}
}
逆变
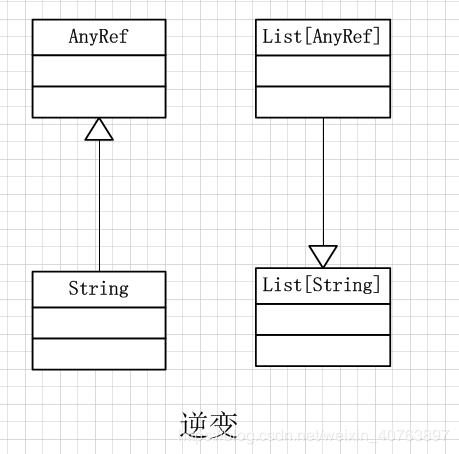
逆变定义形式如:trait List[-T] {}
当类型S是类型A的子类型,则Queue[A]反过来可以认为是Queue[S}的子类型。也就是被参数化类型的泛化方向与参数类型的方向是相反的,所以称为逆变(contravariance)。 下面的代码给出了逆变与协变在定义成员函数时的区别:
//声明逆变
class Person2[-A]{ def test(x:A){} }
//声明协变,但会报错
//covariant type A occurs in contravariant position in type A of value x
class Person3[+A]{ def test(x:A){} }
协变点(covariant position) 和 逆变点(contravariant position)。
协变点

逆变点

我们先假设class Person3[+A]{ def test(x:A){} } 能够编译通过,则对于Person3[Any] 和 Person3[String] 这两个父子类型来说,它们的test方法分别具有下列形式:
//Person3[Any]
def test(x:Any){}
//Person3[String]
def test(x:String){}
由于AnyRef是String类型的父类,由于Person3中的类型参数A是协变的,也即Person3[Any]是Person3[String]的父类,因此如果定义了val pAny=new Person3[AnyRef]、val pString=new Person3[String],调用pAny.test(123)是合法的,但如果将pAny=pString进行重新赋值(这是合法的,因为父类可以指向子类,也称里氏替换原则),此时再调用pAny.test(123)时候,这是非法的,因为子类型不接受非String类型的参数。也就是父类能做的事情,子类不一定能做,子类只是部分满足。
为满足里氏替换原则,子类中函数参数的必须是父类中函数参数的超类,这样的话父类能做的子类也能做。因此需要将类中的泛型参数声明为逆变或不变的。class Person2[-A]{ def test(x:A){} },我们可以对Person2进行分析,同样声明两个变量:val pAnyRef=new Person2[AnyRef]、val pString=new Person2[String],由于是逆变的,所以Person2[String]是Person2[AnyRef]的超类,pAnyRef可以赋值给pString,从而pString可以调用范围更广泛的函数参数(比如未赋值之前,pString.test(“123”)函数参数只能为String类型,则pAnyRef赋值给pString之后,它可以调用test(x:AnyRef)函数,使函数接受更广泛的参数类型。方法参数的位置称为做逆变点(contravariant position),这是class Person3[+A]{ def test(x:A){} }会报错的原因。为使class Person3[+A]{ def test(x:A){} }合法,可以利用下界进行泛型限定,如:
class Person3[+A]{ def test[R>:A](x:R){} }
将参数范围扩大,从而能够接受更广泛的参数类型。
通过前述的描述,我们弄明白了什么是逆变点,现在我们来看一下什么是协变点,先看下面的代码:
//下面这行代码能够正确运行
class Person4[+A]{
def test:A=null.asInstanceOf[A]
}
//下面这行代码会编译出错
//contravariant type A occurs
//in covariant position in type ⇒ A of method test
class Person5[-A]{
def test:A=null.asInstanceOf[A]
}
这里我们同样可以通过里氏替换原则来进行说明
scala> class Person[+A]{def f():A=null.asInstanceOf[A]}
defined class Person
scala> val p1=new Person[AnyRef]()
p1: Person[AnyRef] = Person@8dbd21
scala> val p2=new Person[String]()
p2: Person[String] = Person@1bb8cae
scala> p1.f
res0: AnyRef = null
scala> p2.f
res1: String = null
可以看到,定义为协变时父类的处理范围更广泛,而子类的处理范围相对较小
48、结构类型
结构类型通过利用反映机制为静态语言添加动态特性,从而使得参数类型不受限于某个已命名的类型。结构体类型通过花括号{}进行定义,花括号中给出方法标签,即抽象方法,在使用时才给出具体实现。
object HelloScala {
def releaseMemory(res:{
def close():Unit // 结构体中的方法不能实现它哦
}): Unit ={
res.close()
}
def main(args: Array[String]): Unit = {
// 结构体使用方式
releaseMemory(new { def close():Unit = println("Hello world 888")})
}
}
49、存在类型
java泛型中有通配符类型,如ArrayList< ? extends Serializable>,Scala语言也提供了类似的语法,在Scala语言中被称之为存在类型。其语法格式为:C[T] forSome { type T},C表示泛型类,如Array[T] forSome { type T}(化简表示为:Array[ _ ])表示Array的泛型参数可以是任何类型。java中的ArrayList< ? extends Serializable>在Scala可以这样表示:ArrayList[ _ <: Serializable]
// 没有化简之前
def print2(x: Array[T] forSome {type T})= println(x)
// 化简之后
def print(x: Array[_])= println(x)
50、函数类型
Scala语言中函数也是有类型的,函数类型的语法格式为(T1,T2,…,Tn) => R,其中n的最大值为22,即定义的函数输入参数最多为22 个,R是函数的返回值类型。
object HelloScala {
val max=(x: Int, y: Int)=> if(x > y) x else y
def main(args: Array[String]): Unit = {
println(max(5,6))
}
}
51、抽象类型
抽象类型是指在类或特质中得用type关键字定义一个没有确定类型的标识,该标识的具体类型在子类中被确定,称这种类型为抽象为抽象类型。
object HelloScala {
def main(args: Array[String]): Unit = {
val student = new Student
println(student.getIndentityNo())
}
}
abstract class Person{
type IndentityType // 用type关键字定义了一个抽象类型IndentityType
def getIndentityNo(): IndentityType
}
class Student extends Person{
override type IndentityType = String // 在子类中具体化抽象类型
override def getIndentityNo(): IndentityType = "I am a good student"
}
52、Scala隐式转换
在Scala语言当中,隐式转换是一项强大的程序语言功能,使用程序具有很强的灵活性。**在Scala语言中的视图界定、上下文界定背后都是通过隐式转换来完成的。**隐式转换背后实现的深层机制便是隐式转换函数,隐式转换函数的作用是在无须显式调用的情况下,自动地将一个类型转换成另一个类型。
直接将一个Double类型赋值给Int类型是非法的,但如果给定一个隐式转换函数,就会变得合法啦。
object HelloScala {
def main(args: Array[String]): Unit = {
// 下面的代码会报错,不能直接将一个Double类型的值赋给一个Int类型的变量
// val a: Int = 1.44
implicit def double2Int(x:Double) = x.toInt
val a: Int = 1.44 // 因为提供了上面的隐式转换函数,所以就可以直接将一个Double类型的值赋给一个Int类型的变量
}
}
53、隐式转换函数
隐式转换函数可以快速地扩展类的功能:
object HelloScala {
def main(args: Array[String]): Unit = {
// 定义如下这样一个隐式转换,就将Peron转换成SuperMan
implicit def person2SuperMan(p: Person) = new SuperMan
val p = new Person
p.fly
}
}
class Person // Person类没有任何变量和成员方法
class SuperMan{
def fly = println("I can fly")
}
54、隐式类
在Scala语言中,隐式转换的普遍性也体现在Scala语言提供的隐式类。隐式类的定义同普通类相似,只不过是需要在class关键字前面加implicit关键字。
object HelloScala {
def main(args: Array[String]): Unit = {
// 定义一个隐式类,该类的主构造器参数为待转换的类,隐式类类名为转换后的类
implicit class SuperMan(p:Person){
def fly = println("I can fly 888")
}
val p = new Person
p.fly
}
}
class Person // Person类没有任何变量和成员方法
55、隐式参数与隐式值
Scala语言中还存在隐式参数和隐式值,隐式参数在定义函数时,通过implicit关键字指定,隐式值的定义与一般变量的定义类似,只不过是需要在最前面加implicit关键字。
object HelloScala {
// 隐式值
implicit val a: Int = 10
// implicit作用于整个函数参数,即参数x,y都为隐式参数
// 因为sum函数有隐式参数,因此在使用时可以不指定具体的参数,编译器会自动在相应的作用域中查找对应的隐式值, 如上面定义了一个隐式值,到时sum没有指定参数的话,就会使用这个隐式值
def sum(implicit x: Int, y: Int):Int = x + y
def main(args: Array[String]): Unit = {
println(sum(88,22))
println(sum)
}
}
56、视图界定的隐式转换
视图界定、上下文界定的实现都是通过隐式转换。视图界定在泛型的基础上,对泛型的范围进行进一步限定。
object HelloScala {
def main(args: Array[String]): Unit = {
// 第二个参数"190"是String类型,是Comparable类继承层次结构中实现了Comparable接口的类
val stu1 = new Student("Tom","190")
println(stu1)
// 第二个参数190是Int类型,不是Comparable类继承层次结构中实现了Comparable接口的类,但是Scala提供了隐式转换,可以转换成RichInt,这个类实现了Comparable接口
val stu2 = new Student("Tom",190)
println(stu2)
}
}
// 利用<%符号对泛型S进行限定,它的意思是S可以是Comparable类继承层次结构中实现了Comparable接口的类,也可以是能够经过隐式转换得到的类,该类也实现了Comparable接口。
case class Student[T,S <% Comparable[S]](var name: T, var height: S)
57、上下文界定中的隐式转换
视图界定、上下文界定的实现都是通过隐式转换。只不过上下文采用隐式值来实现。上下文界定的类型参数形式为T:M[T],其中M是一个泛型,这种形式要求存在一个M[T]类型的隐式值。
object HelloScala {
// 定义一个Person类
case class Person(val name: String){
println(s"正在构造对象:${name}")
}
// PersonOrdering混入了Ordering,它与实现了Comparator接口的类的功能一致
class PersonOrdering extends Ordering[Person]{
override def compare(x: Person, y: Person): Int = if(x.name > y.name) 1 else -1
}
// 定义一个上下文界定
// 因此必须在对应的作用域中,必须存在一个类型为Ordering[Person]的隐式值,该隐式值可以作用于PairComparator内部的方法,如smaller方法中的参数
class PairComparator[T:Ordering](val first: T,val second: T){
// 不明确指定的话,编译器就会在对应的作用域中找一个隐式值,并把它转递进来
def smaller(implicit ord:Ordering[T]) = if (ord.compare(first,second) < 0) first else second
}
def main(args: Array[String]): Unit = {
// 在该作用域内定义一个可以作用于PairComparator内部的方法smaller的隐式值
implicit val p1 = new PersonOrdering
val pair = new PairComparator(Person("Tome"),Person("Jhon"))
println(pair.smaller)
}
}
58、隐式转换规则
- 隐式转换函数必须在有效的作用域范围内才能生效
- 当方法中参数的类型与实际类型不一致时,编译器会偿试进行隐式转换
59、不会发生隐式转换的条件
- 如果转换存在二义性,则不会发生隐式转换
- 隐式转换不会嵌套进行
60、自身类型
任何混入该特质的具体类必须确保它的类型符合特质的自身类型:
object HelloScala {
def main(args: Array[String]): Unit = {
// A类在实例化时
val a = new A with X {
override def foo(): Unit = println("We are A and X")
}
a.foo()
val b = new B
b.foo()
}
}
// 定义一个特质
trait X {
def foo()
}
class A {
// self:X =>要求A类在实例化时或定义A类的子类时,必须混入指定的X类型,这个X类型也可以指定为当前类型
self: X =>
}
// 子类
class B extends A with X{
override def foo(): Unit = println("This is plan B")
}
61、中置类型
Scala语言中存在很多中置操作符,如+、等等,在执行12、1+2等操作时,其后面的结果是通过方法调用来实现的,即通过1.*(2)、1.+(2)实现。类似地,当某个类的构造器参数有且仅有两个时,就可以用中置类型表示,语法定义:类型1 实际类 类型2
object HelloScala {
def main(args: Array[String]): Unit = {
// 以下这个声明是错的,因为第二个要求是Int
//val p:String Person Int = new Person("Tom","ddd")
val p:String Person Int = new Person("Tom",11)
println(p.name)
// 还可以像下面这样写
val p1:Person[String,Int] = new Person("Tomy",12)
println(p1.name)
p match {
case "Tom" Person 11 => println("Hello Tom")
case name Person age => println(s"hello everyone,I am ${name},I am ${age}")
}
}
}
case class Person[S,T](val name: S,val age: T)
62、类型投影
Scala中存在的内部类,内部类与外部类的成员变量、成员方法并没有太大的区别,唯一的区别在于它是一个类,在使用内部类时要注意的问题:两个不同外部类实例对应的内部类是不同的类。类型投影就是要解决这一问题。
由内部类引发的问题:
object HelloScala {
def main(args: Array[String]): Unit = {
val outter1 = new Outter
outter1.x = 8878
val inner1 = new outter1.Inner
val outter2 = new Outter
outter2.x = 5555
val inner2 = new outter2.Inner
println(outter1.print(inner1).text())// 8878
// 以下调用直接报错
// 因为outter1.Inner与outter2.Inner是不一样的类,而且Outter类里的成员方法def print(i:Inner) = i,相当于def print(i:this.Inner) = i或def print(i:Outter.this.Inner) = i
//println(outter1.print(inner2).text())
}
}
class Outter{
var x: Int = 0
// 相当于def print(i:this.Inner) = i或def print(i:Outter.this.Inner) = i
// print函数依赖于外部类,由此构成了一条路径,因此也称为路径依赖类型
def print(i:Inner) = i
// 内部类 Inner
class Inner{
def text() = x
}
}
以上问题可以用类型投影来解决,类型投影的目的就是将外部类Outter中定义的方法def print(i:Inner) = i变成可以接受任意外部类对象中的Inner类。修正过后代码如下:
object HelloScala {
def main(args: Array[String]): Unit = {
val outter1 = new Outter
outter1.x = 8878
val inner1 = new outter1.Inner
val outter2 = new Outter
outter2.x = 5555
val inner2 = new outter2.Inner
println(outter1.print(inner1).text())// 8878
println(outter1.print(inner2).text())// 5555
}
}
class Outter{
var x: Int = 0
// Outter#Inner类型投影,这样就可以接受作何Outter对象中的Inner类型对象了
def print(i:Outter#Inner) = i
// 内部类 Inner
class Inner{
def text() = x
}
}
63、柯里化
object HelloScala {
def helle(from: String)(to: String) = println(s"${from} says:Hello ${to}")
def main(args: Array[String]): Unit = {
helle("Tom")("Lily")
}
}
谢谢阅读!