Python语言特性及注意(一)
目录
1、函数参数传递
2、普通方法,类方法和实例方法
3、类变量和实例变量
4、Python中单下划线和双下划线
5、迭代器、生成器和装饰器
6、python里的list底层机制探讨:
7、python里其他数据结构的底层实现:
8、python里的深拷贝和浅拷贝
9、Python中的垃圾回收机制:
10、GIL线程全局锁(重点)
11、函数参数(*args and **kwargs)
12、新式类和旧式类(super)
13、Python中的is和==
14、__new__和__init__的区别
15、python实现单例模式
1、函数参数传递
#变量是内存中类型的引用,类型是属于对象的,不属于变量,可变对象有list,dict,set
#不可变对象有string,tuble,numbers
#当引用传递给函数的时候,函数会自动复制引用,example.1中引用指向不可变对象,所以a的地址和数值没有改变
#example.2中引入可变对象后,指向地址和数值都会改变,所以print(2)
a=1
def fun(a):
print ("func_in",id(a))
a=2
print ("func_out",id(a),id(2))
print("func_id",id(a),id(1))
fun(a)
print(a)
'''
输出:
func_id 1405551088 1405551088
func_in 1405551088
func_out 1405551120 1405551120
1
'''a=[]
def fun(a):
print ("func_in",id(a))
a.append(1)
print ("func_out",id(a))
print ("func_id",id(a))
fun(a)
print(a)
'''
输出:
func_id 1954939330760
func_in 1954939330760
func_out 1954939330760
[1]
'''因此在函数传递过程中传递的其实是指向对象的引用,变量值是否改变取决于指向的对象是否是可变对象,懂否?可能否、
2、普通方法,类方法和实例方法
在类中的方法定义时,其中self和cls表示对类或实例的绑定 因此在普通方法调用时需要用a.foo(x)和A.foo(a,x)指定其中的实例,相当于在A中传递实例a,类方法中可以不绑定实例直接调用A.class_foo(x),表示传递的是类实例、
静态方法和普通方法一样,不过可以忽略self,直接调用
def foo(x):
print ("executing foo(%s)"%x)
class A(object):
def foo(self,x):
print ("executing foo(%s,%s)"%(self,x))
@classmethod
def class_foo(cls,x):
print ("executing class_foo(%s,%s)"%(cls,x))
@staticmethod
def static_foo(x):
print ("executing static_foo(%s)"%x)
a=A()
x=1
A.foo(a,x)
a.foo(x)
#foo(a,1)
A.class_foo(x)
A.static_foo(x)
'''
输出:
executing foo(<__main__.A object at 0x000001C72B76D710>,1)
executing foo(<__main__.A object at 0x000001C72B76D710>,1)
executing class_foo(,1)
executing static_foo(1)
''' | \ | 实例方法 | 类方法 | 静态方法 |
|---|---|---|---|
| a = A() | a.foo(x) | a.class_foo(x) | a.static_foo(x) |
| A | 不可用 | A.class_foo(x) | A.static_foo(x) |
实例方法的调用是基于实例被创建出来的,因此在普通方法调用时A.foo(a,x)或者a.foo(x)的形式,必须指定实例a,这也是为什么普通方法需要传递self指向实例的参数
而类方法在调用时传入参数是cls参数,因此可以通过实例或者类的方法调用
静态方法和一般方法类似,不过可以通过实例或者类方法调用a.static_foo(x)或者A.static_foo(x)
3、类变量和实例变量
类变量: 是可在类的所有实例之间共享的值(也就是说,它们不是单独分配给每个实例的)。例如下例中,num_of_instance 就是类变量,用于跟踪存在着多少个Test 的实例。
实例变量: 实例化之后,每个实例单独拥有的变量。
class Test(object):
num_of_instance = 0
def __init__(self, name):
self.name = name
Test.num_of_instance += 1
if __name__ == '__main__':
print Test.num_of_instance # 0
t1 = Test('jack')
print Test.num_of_instance # 1
t2 = Test('lucy')
print t1.name , t1.num_of_instance # jack 2
print t2.name , t2.num_of_instance # lucy 2上例中Test.num_of_instance属于类变量,在创造实例中不同变量之间共享类变量的数值
class Person:
name=[]
p1=Person()
p2=Person()
p1.name.append(1)
print p1.name # [1]
print p2.name # [1]
print Person.name # [1]上例中Person内部定义name[]属于类变量,在类内部定义,被不同实例引用共享
4、Python中单下划线和双下划线
class MyClass():
def __init__(self):
self.__superprivate = "Hello"
self._semiprivate = ", world!"
mc = MyClass()
print(mc._semiprivate)
print(mc._MyClass__superprivate)
print(mc.__dict__)
'''
输出:
, world!
Hello
{'_MyClass__superprivate': 'Hello', '_semiprivate': ', world!'}
'''其中python中有三种下划线,前面单、前面双、前双后双
- __init__在类定义内部相当于python内部的定义,用来指定方法,例如
__init__(),__del__(),__call__()这些特殊方法 if __name__ == '__main__':同样在主程序中也是双下划线进行main函数调用 - _foo()表示是私有变量,为类内部所调用,属于私有变量
- __foo()在解析器中用_classname__foo的形式调用,只能通过对象名._类名__xxx这样的方式可以访问.详情可见上例
5、迭代器、生成器和装饰器
L=[x * x for x in range(10)]
L
Out[15]: [0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
g=(x * x for x in range(10))
g
Out[17]: at 0x0000024E24432048> 在列表生成式中[]改成()后,数据结构由列表变成生成器,直接输出生成器的地址位置
生成器:边循环、边计算的机制---generator()
在函数中使用yield关键字,函数就变成了generator生成器,利用yield关键字可以不停的调用next()函数实现惰性计算
2)可迭代对象(Iterable)和迭代器(Iterator)
可以直接用于for循环语句的都是可迭代对象(Iterable),包括集合类型(list,tuple,set,dict,str)等和生成器
可以使用isinstance()判断一个对象是否是Iterable对象
from collections import Iterable
isinstance([], Iterable)
True迭代器表示一个庞大的数据流,通过不停的调用next()函数实现对数据流的顺序访问和数据提取
生成器属于迭代器,但list,set等类型属于迭代对象,并不是迭代器,其中for循环的本质就是不停调用next()函数实现数据提取的
yield函数变成一个生成器对象,返回多个值并停在程序调用的位置
因此yield生成器实质上是迭代器的简化生成,实际上是调用next()函数一步步执行的,利用raise stopitreation来终止迭代
3)面向切面编程AOP和装饰器
编程范式在java中用到的较多,在python中实现就是装饰器。
装饰器相当于函数嵌套,内部封装,返回一个函数的高阶模式。
装饰器的本质是调用一个函数f,返回一个函数wrapper(),从而实现了函数封装和编程外部操作。
import functools
#防止函数名更改
def log(text):
def decorator(func):
@functools.wraps(func)
def wrapper(*args, **kw):
print('%s %s():' % (text, func.__name__))
return func(*args, **kw)
return wrapper
return decorator
@log('execute')
def now():
print('2015-3-25')
now()
now.__name__
'''
输出:
execute now():
2015-3-25
'now'
'''https://zhuanlan.zhihu.com/p/22229197
闭包的概念,可以看做是实现装饰器的基础,相当于函数内部再定义一个函数,内部返回的是函数本身
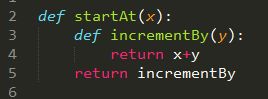
闭包概念:在一个内部函数中,对外部作用域的变量进行引用,(并且一般外部函数的返回值为内部函数),那么内部函数就被认为是闭包
闭包无法修改外部函数的局部变量、python循环中不包含域的概念,作用:闭包可以保存当前的运行环境
6、python里的list底层机制探讨:
原文链接:http://www.laurentluce.com/posts/python-list-implementation/
list是用下边的C语言的结构来表示的。ob_item是用来保存元素的指针数组,allocated是ob_item预先分配的内存总容量
typedef struct {
PyObject_VAR_HEAD
PyObject **ob_item;
Py_ssize_t allocated;
} PyListObject;list初始化过程中会有ob_size和allocated两个变量记录列表的实际长度和预分配的空间大小,本质也是会动态扩容的
和C++语言中vector的机制类似,底层有3个指针数组管理,resize()--元素数量,reserverse()--改变最大容量
append:list_resize(),list_resize()会申请多余的空间以避免调用多次list_resize()函数,list增长的模型是:0, 4, 8, 16, 25, 35, 46, 58, 72, 88,
下图一次是append(1),append(2),append(3),append(4)的数组指针机制

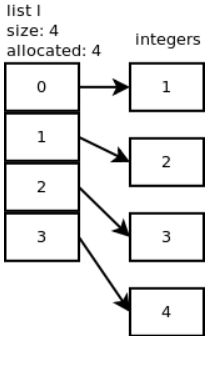
Insert():申请了8个内存空间但是list实际用来存储元素只使用了其中5个内存空间,insert的时间复杂度是O(n),动态扩容

pop():用listpop(),list_resize在函数listpop()内部被调用,如果这时ob_size(译者注:弹出元素后)小于allocated的一半。这时申请的内存空间将会缩小。


如上例,如果pop两次以后,实际内存空间<4,因此allocated维护的空间会变为6,但是在内容空间3和4指向的内容并没有被完全删除,只是实际使用空间缩减
Remove()的时间复杂度:O(n)
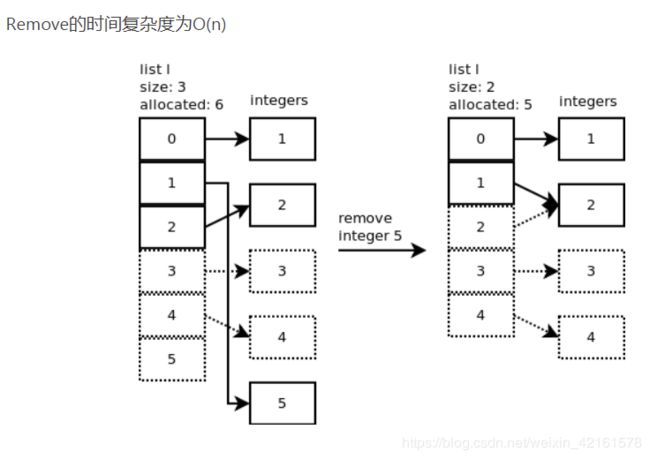
我们能看到 Python 设计者的苦心。在需要的时候扩容,但又不允许过度的浪费,适当的内存回收是非常必要的。
这个确定调整后的空间大小算法很有意思。
调整后大小 (new_allocated) = 新元素数量 (newsize) + 预留空间 (new_allocated)
调整后的空间肯定能存储 newsize 个元素。要关注的是预留空间的增长状况。
将预留算法改成 Python 版就更清楚了:(newsize // 8) + (newsize < 9 and 3 or 6)。
当 newsize >= allocated,自然按照这个新的长度 "扩容" 内存。
而如果 newsize < allocated,且利用率低于一半呢?
allocated newsize new_size + new_allocated
10 4 4 + 3
20 9 9 + 7
很显然,这个新长度小于原来的已分配空间长度,自然会导致 realloc 收缩内存。(不容易啊)
引自《深入Python编程》7、python里其他数据结构的底层实现:
前言:
1、可以同时考虑C++中STL容器的底层机制实现,其中最基础的是vector和list基本数据类型,vector底层是数组,在内存区域由3个指针进行管理,list底层是双向链表,deque相当于指针数组,指针指向另一个数组,在堆中保存。
以上三种为基本类型实现stack,queue和prioty-queue优先队列(vector+max_heap),相当于deque+list
2、map和set的底层实现是红黑树,红黑树作为AVL树的改进,不仅有序,在插入操作中也优于AVL树,内部自动排序,其中map以键值对的方式存储,set只包含一个关键字,都不允许键重复。时间复杂度O(logn)
3、unordered_map和unordered_set底层实现是哈希表,内部无序存储,类似于字典的形式存放,时间复杂度是O(n),注意联系他们底层的数据结构实现
其中红黑树的统计性能是高于AVL的。STL map,set的实现只是折衷了两者在search、insert以及delete下的效率。
dict又称为关联数组,是通过哈希散列表实现的,python2中采用开放寻址法,3.0以后采用伪随机探测法。其中dict中的数据是无序存放的同样set也是默认以键值对的方式存储,但是默认键和值是相同的,因此set内部也是无序的,利用集合set可以去重
1、操作的时间复杂度,插入、查找和删除都可以在O(1)的时间复杂度
2、键的限制,只有可哈希的对象才能作为字典的键和set的值。可hash的对象即python中的不可变对象和自定义的对象。可变对象(列表、字典、集合)是不能作为字典的键和st的值的。
3、与list相比:list的查找和删除的时间复杂度是O(n),添加的时间复杂度是O(1)。但是dict使用hashtable内存的开销更大。为了保证较少的冲突,hashtable的装载因子,一般要小于0.75,在python中当装载因子达到2/3的时候就会自动进行扩容
8、python里的深拷贝和浅拷贝
https://www.cnblogs.com/wilber2013/p/4645353.html
这篇博客讲的不错,从内存地址说明了三者的区别
import copy
a=[1,2,3,4,['a','b']]
b=a
c = copy.copy(a)
d = copy.deepcopy(a)
a.append(5)
a[4].append('c')
print('a=',a)
print('b=',b)
print('c=',c)
print('d=',d)
'''
Output:
a= [1, 2, 3, 4, ['a', 'b', 'c'], 5]
b= [1, 2, 3, 4, ['a', 'b', 'c'], 5]
c= [1, 2, 3, 4, ['a', 'b', 'c']]
d= [1, 2, 3, 4, ['a', 'b']]
'''python中直接赋值语句传递的是对象的引用(内存地址),因此并没有新开内存空间,因此对源对象a的修改会直接体现在b对象中去。
浅拷贝可以利用copy函数中的copy进行拷贝,它复制了对象,但是依然使用原始的引用,因此指向对象发生内部修改时也会体现出来,如同字符串中c的输出
深拷贝不仅会创建新对象,对于对象中的每一个元素也会重新生成一份,因此对源对象的修改并不会体现在d的变更上来。
前方高能:
在C++中也有浅拷贝和深拷贝,对应默认构造函数和复制构造函数。
浅拷贝是系统默认的复制构造函数,拷贝后指针指向同一块内存空间,复制后析构两次会导致崩溃,因此可以在析构时用智能指针实现
深拷贝是自动定义的复制构造函数,对指向的内容进行拷贝
9、Python中的垃圾回收机制:
Python中 GC主要使用引用计数来跟踪和回收来记录垃圾,通过“标记-清除”的方式来解决容器对象产生的循环应用问题。通过分代技术以空间换时间来提高垃圾回收效率。
引用计数,Pyobject是每一个对象必有的内容,其中利用ob_refcnt作为引用计数会增加减少,直到为0生命周期结束。
标记-清除机制一开始按需分配,没有空闲内存的时候会遍历以对象为节点,以引用为边构成的图,所有可以访问到的对象会被打上标记,然后所有没有被标记的对象会被释放。
分代技术根据存活时间分为不同的代,python中分为3代,垃圾收集频率会随着代的存活时间增大而减小,默认三代对象集合,索引数越大,对象存活时间越长。
C++中的循环引用的解决:
Shared_ptr 智能指针内部可以有count变量,当共享资源时,指针内部count++,而后当生命周期结束释放资源时,count--,通过引用计数最终确保资源共享和防止内存的非法访问
当内部存在循环引用无法释放资源时引入weak_ptr指针,弱引用指针作为引用只在对象存在时不修改内部的引用计数,类似于普通指针,但它能够检测到访问资源是否释放,从而避免非法访问
10、GIL线程全局锁(重点)
python中的多线程其实是假的,因为在python内存在全局锁,即一个核同一时间只能运行1个线程,因此对于IO密集型任务,Python的多线程可以起到作用,在IO进行状态等待时进行切换。但对于CPU密集型任务,python的多线程基本不起作用,反而会因为争夺资源而变慢。
其中线程是通过Thread和Threading类实现的,其中主进程和t1,t2是同时跑运行的。
主进程只有会在所有非守护进程结束后,它才会结束
join():在子进程完成之前,父进程一直处于堵塞状态
setDaemon(true):设定为守护进程后,则就不管他,主进程结束后会被强制退出
因此python的多进程是通过多道技术并发实现的,并不是CPU并行,只有在执行完100条字节码后,全局锁才会释放,切换进程。
2、创建进程:一种是传递给对象可执行方法,另一种通过继承定义子类并重写run()方法
3、其中保证线程同步的方法有锁机制和同步队列,锁机制可以在run方法中引入互斥锁,同步队列可以加入到线程列表中join()循环遍历列表。
4.在python中实现多线程的其他方法:进程是在系统中调度资源,线程是CPU调度,协程用于用户控制,计算密集型问题
第一种有初期的yield/send函数,yield属于生成器实例,每次调用next继续执行;利用send每次有返回值,实现协程机制
第二种是并发编程,利用asyncio实现消息循环,在continue通过yield from完成,并且多个continue可以封装成一组task并发执行
第三种同上,可以利用关键字async/await()实现消息循环
import threading
import time
class myThread(threading.Thread): # 继承父类threading.Thread
def __init__(self, threadID, name, counter):
threading.Thread.__init__(self)
self.threadID = threadID
self.name = name
self.counter = counter
def run(self): # 把要执行的代码写到run函数里面 线程在创建后会直接运行run函数
print("Starting " + self.name)
print_time(self.name, self.counter, 5)
print("Exiting " + self.name)
def print_time(threadName, delay, counter):
while counter:
time.sleep(delay)
print("%s process at: %s" % (threadName, time.ctime(time.time())))
counter -= 1
# 创建新线程
thread1 = myThread(1, "Thread-1", 1)
thread2 = myThread(2, "Thread-2", 2)
# 开启线程
thread1.start()
thread2.start()
# 等待线程结束
thread1.join()
thread2.join()
print("Exiting Main Thread")
'''
Starting Thread-1
Starting Thread-2
Thread-1 process at: Sun May 24 17:03:10 2020
Thread-1 process at: Sun May 24 17:03:11 2020Thread-2 process at: Sun May 24 17:03:11 2020
Thread-1 process at: Sun May 24 17:03:12 2020
Thread-2 process at: Sun May 24 17:03:13 2020
Thread-1 process at: Sun May 24 17:03:13 2020
Thread-1 process at: Sun May 24 17:03:14 2020
Exiting Thread-1
Thread-2 process at: Sun May 24 17:03:15 2020
Thread-2 process at: Sun May 24 17:03:17 2020
Thread-2 process at: Sun May 24 17:03:19 2020
Exiting Thread-2
Exiting Main Thread
'''import threading
import time
class myThread(threading.Thread):
def __init__(self, threadID, name, counter):
threading.Thread.__init__(self)
self.threadID = threadID
self.name = name
self.counter = counter
def run(self):
print("Starting " + self.name)
# 获得锁,成功获得锁定后返回True
# 可选的timeout参数不填时将一直阻塞直到获得锁定
# 否则超时后将返回False
threadLock.acquire()
print_time(self.name, self.counter, 5)
# 释放锁
threadLock.release()
def print_time(threadName, delay, counter):
while counter:
time.sleep(delay)
print("%s: %s" % (threadName, time.ctime(time.time())))
counter -= 1
threadLock = threading.Lock()
threads = []
# 创建新线程
thread1 = myThread(1, "Thread-1", 1)
thread2 = myThread(2, "Thread-2", 2)
# 开启新线程
thread1.start()
thread2.start()
# 添加线程到线程列表
threads.append(thread1)
threads.append(thread2)
# 等待所有线程完成
for t in threads:
t.join()
print("Exiting Main Thread")
output:
'''
Starting Thread-1
Starting Thread-2
Thread-1: Sun May 24 17:04:09 2020
Thread-1: Sun May 24 17:04:10 2020
Thread-1: Sun May 24 17:04:11 2020
Thread-1: Sun May 24 17:04:12 2020
Thread-1: Sun May 24 17:04:13 2020
Thread-2: Sun May 24 17:04:15 2020
Thread-2: Sun May 24 17:04:17 2020
Thread-2: Sun May 24 17:04:19 2020
Thread-2: Sun May 24 17:04:21 2020
Thread-2: Sun May 24 17:04:23 2020
Exiting Main Thread
'''import threading
import asyncio
@asyncio.coroutine
def hello():
print('Hello world! (%s)' % threading.currentThread())
yield from asyncio.sleep(1)
print('Hello again! (%s)' % threading.currentThread())
loop = asyncio.get_event_loop()
tasks = [hello(), hello()]
loop.run_until_complete(asyncio.wait(tasks))
loop.close()11、函数参数(*args and **kwargs)
二者可以混搭,但是*args必须在**kwargs之前,相当于一个星是元祖参数,两个星是字典参数,会将传入的自动组合成元祖或字典的形式
其中在python中传入的参数包括位置参数,默认参数,关键字参数,可变位置参数等
在Python中不需要函数重载,可变参数类型和可变参数个数都可以在python中解决
def print_everything(*args):
for count, thing in enumerate(args):
print('{0}.{1}'.format(count,thing))
print_everything('apple', 'banana', 'cabbage')
'''
0.apple
1.banana
2.cabbage
'''def f(a,*b,c=10,**d):
print('a:{0},b:{1},c:{2},d:{3}'.format(a,b,c,d))
f(1,2,5,width=10,hight=5)
'''
a:1,b:(2, 5),c:10,d:{'width': 10, 'hight': 5}
'''12、新式类和旧式类(super)
py3.0之后是新式类,在经典类中继承是深度优先DFS,新式类中是广度优先BFS
class A():
def foo1(self):
print("A")
class B(A):
def foo2(self):
pass
class C(A):
def foo1(self):
print("C")
class D(B, C):
pass
d = D()
d.foo1()
'''
新式类输出是C
旧式类输出是A
'''按照经典类的查找顺序从左到右深度优先的规则,在访问d.foo1()的时候,D这个类是没有的..那么往上查找,先找到B,里面没有,深度优先,访问A,找到了foo1(),所以这时候调用的是A的foo1(),从而导致C重写的foo1()被绕过
Super函数一般在子类继承中调用父类方法,保证在多重继承时每个基类的构造函数被调用1次,其中的实现机制是利用其中内部的MRO列表依次调用,目前的常见继承方式是广度优先。
- 事实上,super 和父类没有实质性的关联。
- super(cls, inst) 获得的是 cls 在 inst 的 MRO 列表中的下一个类。
13、Python中的is和==
is是判断对象的id是否相同,==是比较值是否相等
当变量是数字、字符串、元组,列表,字典时,is和==都不相同, 不能互换使用!当比较值时,要使用==,比较是否是同一个内存地址时应该使用is。当然,开发中比较值的情况比较多。其中数字在Python中优化,[-5,256]的数字会保存在small_ints数组中去
14、__new__和__init__的区别
一般比较多的使用__init__进行类中变量的初始化,但是new是一个静态方法,init是一个实例方法
利用new来返回创建的实例,init什么都不返回,因此new只有在返回一个cls的实例后init才会被调用
在一般的类中我们并不重写new方法,一般继承自基类/元类的new函数
15、python实现单例模式
通过单例模式可以保证系统中一个类只有一个实例而且该实例易于外界访问,从而方便对实例个数的控制并节约系统资源。如果希望在系统中某个类的对象只能存在一个,单例模式是最好的解决方案。
基本思路是如果实例不存在,会创建一个实例;如果已存在就会返回这个实例
1.利用python中的import模块实现单例模式,
2、利用__new__方法创建单例模式
class Single(object):
_instance = None
def __new__(cls,*args,**kw):
if cls._instance is None:
cls._instance = object.__new__(cls,*args,**kw)
return cls._instance
def __init__(self):
pass
single1 = Single()
single2 = Single()
print(id(single1) == id(single2))3、利用函数装饰器实现单例模式
def singleton(cls):
_instance={}
def inner():
if cls not in _instance:
_instance[cls] = cls()
return _instance[cls]
return inner
@singleton
class Cls(object):
def __init__(self):
pass
cls1 = Cls()
cls2 = Cls()
print(id(cls1) == id(cls2))