Python的学习心得和知识总结(十一)|Python模块(module)
注:前面我们在学习I/O和文件处理的时候,之后学了一下相关的模块如:os os.path等。我们今天就详细全面而又系统的学习一下 模块
注:Python安装之后的DOC文档是全英文的,当然这就苦了不太会英语的小伙伴们了。下面是中文文档的链接(官方文档,是最好最准确的学习资料)
中文文档在线查看
Python 模块
- 模块化程序设计的理念
- 模块化组织进程
- 标准库模块使用
- 模块化编程优势
- 模块化开发流程
- 模块创建和测试
- 模块的导入
- import 方式导入
- from import方式
- `__import__()`导入
- 包(package)的使用
- 包的导入
- sys.path模块以及模块搜索路径
- 模块的发布和安装
- 模块的本地发布
- 模块的本地安装
- 上传module到PyPI上
模块化程序设计的理念
模块化组织进程
随着程序的复杂程度越来越高,各种新型管理组织方式应用而生:
1、实现同一个功能的代码段被封装成一个 函数来进行统一管理和调用
2、而函数和变量也越发的多的时候 就被抽象成类的方法和属性,于是面向对象:类和对象就诞生了
3、而类和函数也变多的时候 就将类似功能的函数和类统一放到一个模块之中,于是模块也诞生了
4、模块也会变的复杂且繁多,这个时候功能相近的模块被组织到一个 包里面
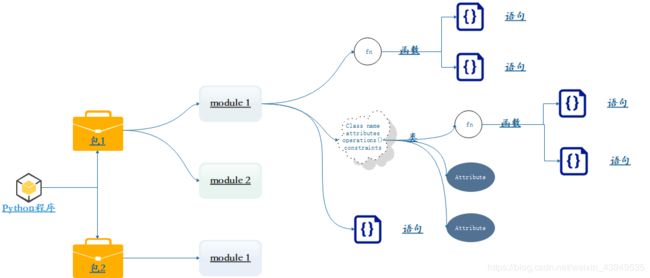
如上图所示:
1、Python程序是由模块组成。一个模块module对应一个Python源文件
2、module是由语句组成,运行一个Python程序的时候 会按照module里面的语句顺序依次执行
3、Python程序的构造单元为语句:包括创建对象、变量赋值、函数调用和控制语句等
标准库模块使用
除了可以调用标准库里面的函数之外,我们还可以自定义函数进行调用。和函数一样,模块的使用也是划分:自定义模块和标准库模块的。
在Python里面,标准库模块提供了:OS功能、网络通信、文件文本处理和数学运算等基础功能。 这样的模块有:random (随机数)、math(数学运算)、time(时间操作)、file(文件处理)、os(OS交互)和sys(和解释器交互)等
但是这仅仅只有这些是远不够的,Python还有大量的第三方模块的支持。(在使用上和标准库模块类似)而这些第三方库模块就涉及到了所有的领域:web开发、大数据、AI、GUI和科学计算等。
模块化编程优势
上面也说了一个module对应上一个Python源文件,在这个module里面定义了:变量、function、类和一些语句等内容。这样做的好处:我们可以将一个Python程序进行分解为多个module(进行独立开发),还便利于开发后期的代码复用。
这种类似于搭积木的模块化编程方式有利于任务的分解(便于团队协作开发)、module的重复独立利用和强大的可靠易维护性。
模块化开发流程
OK,那我们在实际的模块化协作开发的时候,整个开发流程是:
- 设计API接口,详细描述相关模块功能(分析有什么类 函数 和语句等)
- 进行编码,实现API
- 在module里面编制测试代码,并消除 全局代码
- 注意外部访问权限,在module里面使用私有方法 防止被外部调用并修改
- 最后在其他module里面导入本模块进行使用
help(modulename)可以来查看module的API(前提是 import modulename)
OK,我们下面就看一个简单的Python标准模块(就是一个.py文件):
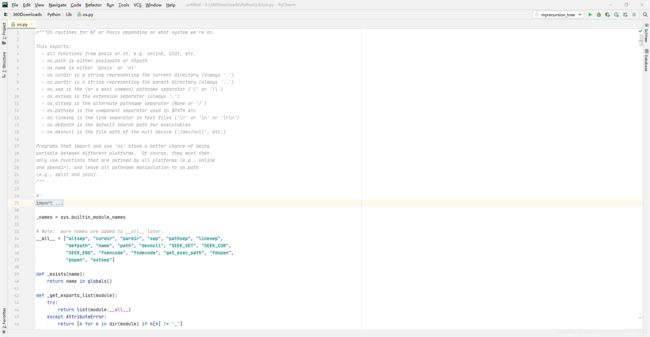
里面定义的函数就可以被我们直接使用,我们除了可以直接翻看Python源码 还可以查看DOC文档:
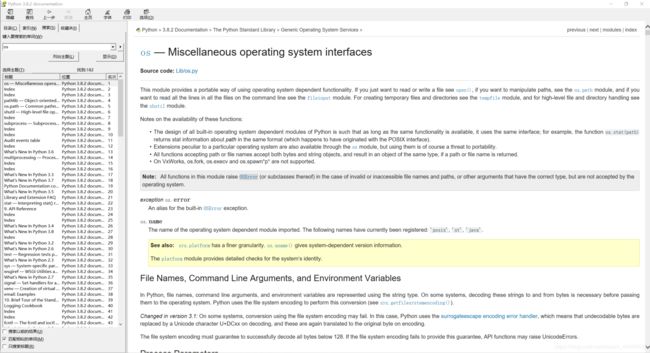
注:这个文档是全英文的,当然这就苦了不太会英语的小伙伴们了。
中文文档在线查看
当然我们也可以通过__doc__来获得一个模块或者内部一个函数的文档字符串内容:(在模块的第一行增加的文档字符串 描述模块的相关功能信息)
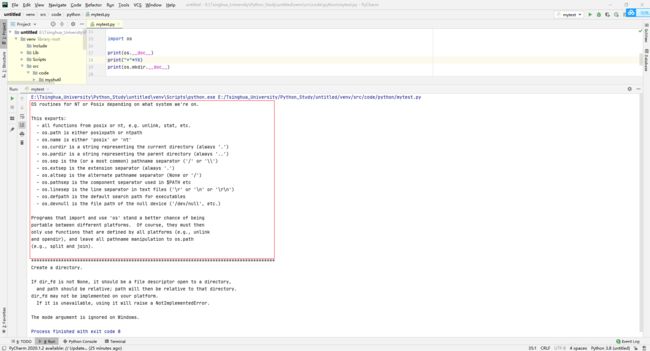
模块创建和测试
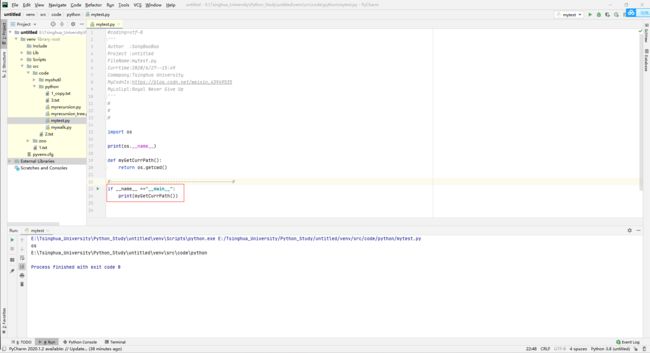
一般来说,每个模块都有一个名称,可以通过特殊变量__name__来获取模块的名称。(但是一般情形下 模块名对应源文件名字)
注:但是当一个模块被作为程序入口时(主程序、交互式提示符下),此时的变量__name__是"__main__"。于是我们就可以根据这个特点来将module源码文件里面的测试代码进行独立的处理了。示例如下:
模块的导入
上面也说了:模块化设计的优点之一在于“代码复用程度高”,而模块的导入就是在我们当前模块(文件)里面使用已经写好的其他module。不过下面有两种静态方式都可以进行模块导入:
1、import 导入的是模块module,是“文件”
2、from…import 导入的是模块中的一个函数/一个类,是文件下的“内容”
3、import 导入的,我们要使用时,必须前面加 module.function()
from…import 导入的 我们直接使用这些“内容”即可 function()
import 方式导入
其语法格式如下:
import module1 #导入一个模块
import module1,module2,…… #导入多个模块
import module1 as mymodule #导入一个模块,并使用其他新名字
我们上面导入的module可以是下面几种类型:
- 使用Python编制的.py文件
- 内含一组module的包
- 已经被编译为动态库的C/C++扩展
- 使用C语言编写并链接到Python解释器的内置模块
注:而import语句的功能实现是使用了内置函数__import__()的功能,即:使用import导入一个模块 Python解释器会执行 然后生成一个对象,被加载的module就是由该对象所指向。
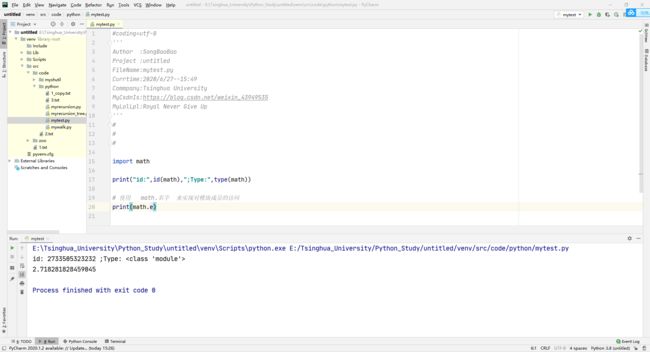
如上图所示:
math模块被加载之后,实际上生成了一个module类的对象。这个对象是被math变量所指向(引用),之后就可以使用math变量来访问模块中的内容。而import在导入多个module之后,本质上也是生成了多个module类的对象而已。
但 是 一 个 m o d u l e 无 论 被 i m p o r t 多 少 次 ( 在 同 一 个 文 件 中 ) , 它 对 应 的 都 只 是 一 个 对 象 。 但是一个module无论被import多少次(在同一个文件中),它对应的都只是一个对象。 但是一个module无论被import多少次(在同一个文件中),它对应的都只是一个对象。
但是我们在上面给模块起个别名,本质上这个别名仅仅是新创建一个变量来引用加载的模块对象而已。
from import方式
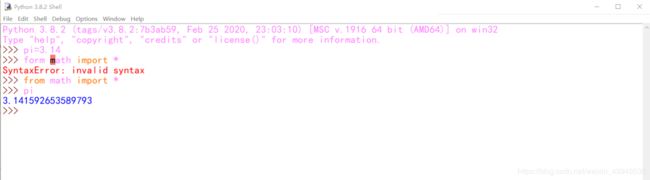
在Python里面,from module import 成员1,成员2,……来导入模块中的成员。若是导入所有的成员,那么如下:
from module import *
但是这个方式(全导入)尽量不要使用:* 表示导入模块中所有的不是用 下划线_开头的名字都导入到当前位置。但你不知道你导入了什么名字,很有可能会覆盖掉你之前已经定义的名字。
__import__()导入
和上面两种导入方式不太一样的是:import 语句本质上就是调用内置函数__import__()来静态导入,而我们可以直接通过它实现动态导入,即:给__import__()动态传递不同的的参数值,就能导入不同的模块。
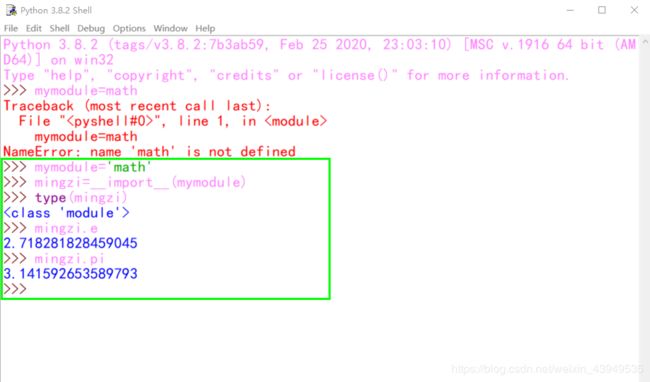
注:但是一般不建议我们自行使用__import__()导入(这是系统导入库的行为),因为该方法的行为在 python2 和 python3 中有差异,会导致意外错误。如果需要动态导入可以使用 importlib 模块。示例如下:

OK,下面把模块导入进行汇总:
- 当导入一个模块时, 模块中的代码都会被执行 (第一次加载 相当于一个
Ctrl+Shift+F10)。不过,如果再次(指的是第二次import)导入这个模块,则不会再次执行 - 因为上面导入模块更多的时候需要的是:定义在模块中的变量、函数、对象等。这些并不需要反复定义和执行。于是“只导入一次import-only-once”就成了一种优化
- 一个模块无论导入多少次,这个模块在整个解释器进程内有且仅有一个实例对象
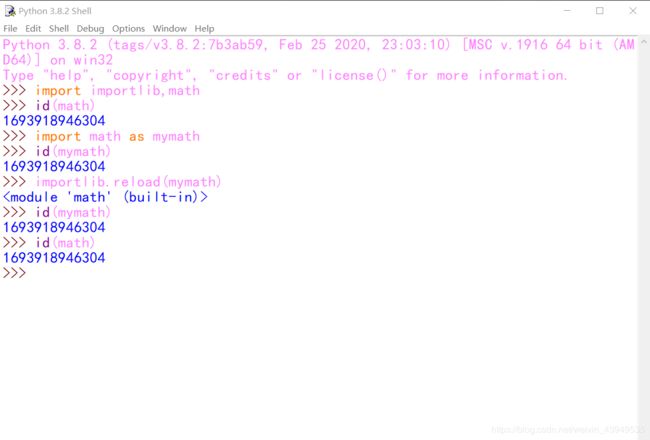
- 但是可以使用importlib模块下面的
importlib.reload(math)重新加载一个module
包(package)的使用
上面也说了:package类似于目录;而module则是目录里面的文件。
功能实现类似的module被放在一起就形成了一个package,而package里面则必须要有一个__init__.py的文件。在学习package的时候 类比于目录 文件的方式会更加容易理解一些。相较于目录里面也可以有子目录,package里面也可以包含子package(而子包必须也要有一个__init__.py的文件)
包的导入
包的导入在实质上就是导入了包里面的__init__.py文件。意思就是:在导入一个包的时候,就是执行了包下面的__init__.py文件。于是我们就可以在__init__.py文件里面批量导入我们所需要的module,而非一个个的导入。(但是尽可能要保证__init__.py文件简单,不要在里面乱加东西)
假如我们需要导入module1.py,那么导入方式为:
1.import packagename.module1.py
# 此时的话,需要使用其中的函数就得:packagename.module1.function()
2.from packagename import module1
# 此时的话,需要使用其中的函数就得:module1.function()
3.from packagename.module1 import function
# 此时的话,需要使用其中的函数就得:function()
4.import *
# 这个语句在理论上是希望文件系统能够找出package中所有的子module,然后进行导入(可能很耗时)
5.from item1.item2 import *
# 在`__init__.py`文件里面定义`__all__`变量明确索引,然后该from一行就可以从对应的包中导入all变量里面的子module
注:在上面第2种方式下from packagename import item 这个item可以是package、module或者function、class和variable等。
但是在import item1.item2 这个item只可以是package和module。
说实话,我感觉__init__.py文件批量导入module,其实就跟我们定义一个头文件c.h一样 在里面我们可以包含stdio.h string.h time.h等等 然后我们在源文件里面#include "c.h" 就可以使用字符串和时间等标准库函数了。
OK,我们下面就来对这个__init__.py文件进行一个小结:
1、作为一个package的标志
2、可以实现批量的module导入
3、导入包的实质就是执行__init__.py文件,于是就可以在__init__.py文件里面做一些该package的初始化和其他一些公共的执行代码
4、module的模糊导入(import *的使用)
sys.path模块以及模块搜索路径
当我们在import一个module的时候,解释器是怎么找到这个.py文件的呢?(解释器咋知道该module路径的呢?)
在Python里面,已经做了如下规定顺序进行搜索module文件:
- 内置模块
- 当前目录(当前运行的程序所在目录)
- 程序的主目录(一般是指项目目录)
- pythonpath (若无设置环境变量则无)
- 标准链接库目录
- 第三方库目录(或者 site-packages目录)
- .pth文件的内容(若无设置则无)
- sys.path.append()新临时添加的目录(当前程序有效 临时有效)
注:如果上面都找了,没有发现则报错;而一旦找到则直接停止寻找(不找了),之后就是module的读取、装载和执行了。
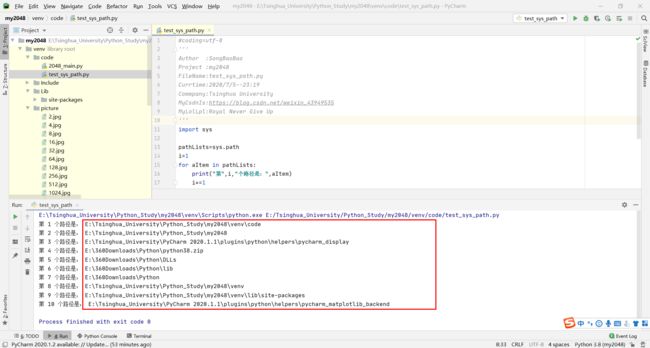
OK,我们来看一下这个打印的路径信息:
1、在Python程序启动的时候,就会将上面(除内置模块以外)的路径进行收集,然后放到sys模块的path属性里面
2、首先打印的就是当前目录、程序主目录
3、那个E:\360Downloads\Python\python38.zip DLLs lib 是标准库目录
4、这个E:\Tsinghua_University\Python_Study\my2048\venv\lib\site-packages就是安装的第三方的目录
模块的发布和安装
模块的本地发布
当我们完成一个module的开发之后,如果希望给别人分享使用的话 就可以进行一个module的发布。之后其他的开发人员就可以以第三方扩展库的方式来使用它。
模块的本地发布主要有下面几个步骤:
第一步:为我们的module创建目录结构dir(dir里面包含我们的package)(注:一般而言 目录名==modulename)
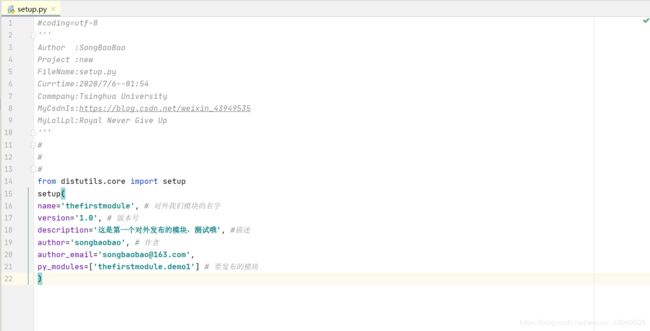
第二步:在与package同级(就是dir下面创建setup.py 内容如下:)
from setuptools import setup, find_packages
from distutils.core import setup
setup(
name = "modulename",# 对外的模块名字
version = "1.0",# 版本号
keywords = ("test", "xxx"),
description = "这是宋宝宝发布的一个module!",# 信息描述
long_description = "这是宋宝宝发布的一个module! 纯属开心",# 详细描述
license = "MIT Licence", # 许可证
url = "http://songbaobao.com", # 一个URL(假的)
author = "songbaobao",# 作者
author_email = "[email protected]",# 这是宋宝宝的邮箱啊(不是真的)
packages = find_packages(),
include_package_data = True,
platforms = "any",
install_requires = [],
scripts = [],
entry_points = {
'console_scripts': [
'test = test.help:main'
]
}
py_modules=["songbaobao.demo1","songbaobao.demo2"] # 要发布的模块
)
第三步:构建一个发布文件(在上面的dir目录下)执行:
python setup.py sdist
注:然后生成的.gz.tar 包就是最后给别人使用的包了。
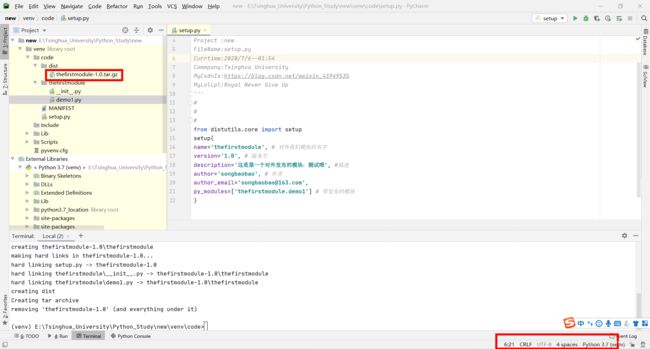
模块的本地安装
第一步:将发布安装到本地之后 cmd下执行命令:
python setup.py install
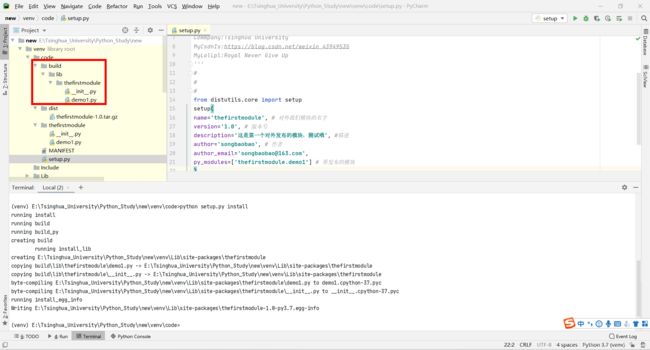
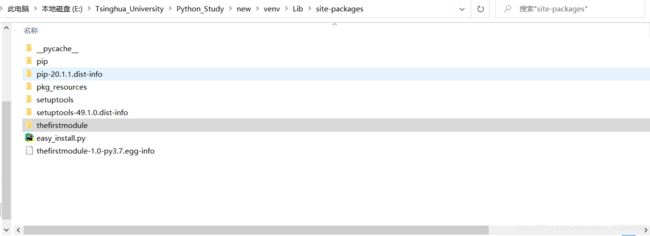
第二步:在安装完成之后,进入E:\Tsinghua_University\Python_Study\new\venv\Lib\site-packages\目录(我们上面也说了这是第三方module安装目录)查看
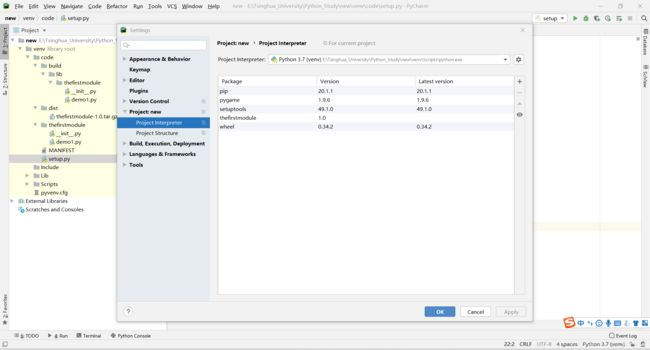
第三步:在setting-->Project Interpreter里面进行安装(这个和我们上次安装的pygame类似)
第四步:进行使用
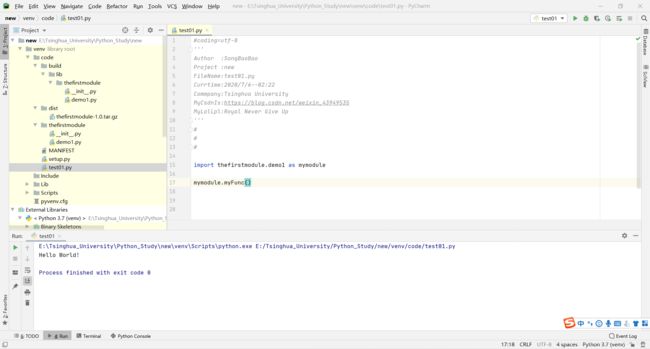
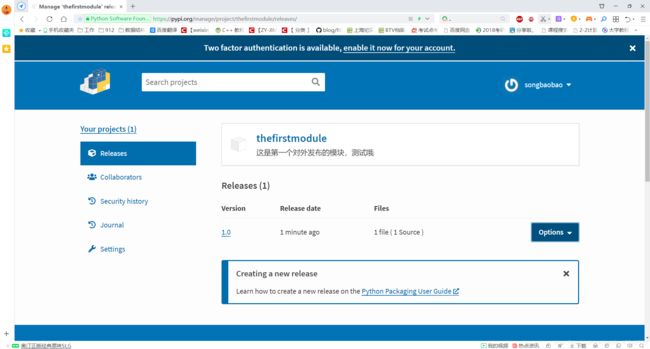
上传module到PyPI上
详细的使用相关教程请见博客:Python模块资源仓库PyPI的使用教程
当我们完成一个module的开发之后,如果希望真正以第三方扩展库的方式来分享给其他的开发人员使用它。(就得把它上传到PyPI网站上 PyPI官网链接)