上一篇文章--[GAN学习系列3]采用深度学习和 TensorFlow 实现图片修复(上)中,我们先介绍了对于图像修复的背景,需要利用什么信息来对缺失的区域进行修复,以及将图像当做概率分布采样的样本来看待,通过这个思路来开始进行图像的修复。
这篇文章将继续介绍原文的第二部分,利用对抗生成网络来快速生成假图片。目录如下:
- 第二步:快速生成假的图片
- 从未知的概率分布中学习生成新的样本
- [ML-Heavy] 建立 GAN 模型
- 采用 G(z) 生成假的图片
- [ML-Heavy] 训练 DCGAN
- 目前的 GAN 和 DCGAN 实现
- [ML-Heavy] TensorFlow 实现 DCGAN
- 在你的数据集上运行 DCGAN 模型
同样的,标题带有 [ML-Heavy] 的会介绍比较多的细节,可以选择跳过。
第二步:快速生成假的图片
从未知的概率分布中学习生成新的样本
与其考虑如何计算概率密度函数,现在在统计学中更好的方法是采用一个生成模型来学习如何生成新的、随机的样本。过去生成模型一直是很难训练或者非常难以实现,但最近在这个领域已经有了一些让人惊讶的进展。Yann LeCun在这篇 Quora 上的问题“最近在深度学习有什么潜在的突破的领域”中给出了一种训练生成模型(对抗训练)方法的介绍,并将其描述为过去十年内机器学习最有趣的想法:
![[GAN学习系列3]采用深度学习和 TensorFlow 实现图片修复(中)_第1张图片](http://img.e-com-net.com/image/info10/81ccd32bb99845619ab440e357ca362e.jpg)
Yann LeCun 在回答中简单介绍了 GAN 的基本原理,也就是两个网络相互博弈的过程。
实际上,深度学习还有其他方法来训练生成模型,比如 Variational Autoencoders(VAEs)。但在本文,主要介绍对抗生成网络(GANs)
[ML-Heavy] 建立 GAN 模型
GANs 这个想法是 Ian Goodfellow 在其带有里程碑意义的论文“Generative Adversarial Nets” (GANs)发表在 2014 年的 Neural Information Processing Systems (NIPS) 会议上后开始火遍整个深度学习领域的。这个想法就是我们首先定义一个简单并众所周知的概率分布,并表示为,在本文后面,我们用 表示在[-1,1)(包含-1,但不包含1)范围的均匀分布。用表示从这个分布中采样,如果是一个五维的,我们可以利用下面一行的 Python 代码来进行采样得到,这里用到 numpy这个库:
z = np.random.uniform(-1, 1, 5)
array([ 0.77356483, 0.95258473, -0.18345086, 0.69224724, -0.34718733])
现在我们有一个简单的分布来进行采样,接下来可以定义一个函数G(z)来从原始的概率分布中生成样本,代码例子如下所示:
def G(z):
...
return imageSample
z = np.random.uniform(-1, 1, 5)
imageSample = G(z)
那么问题来了,怎么定义这个G(Z)函数,让它实现输入一个向量然后返回一张图片呢?答案就是采用一个深度神经网络。对于深度神经网络基础,网络上有很多的介绍,本文就不再重复介绍了。这里推荐的一些参考有斯坦福大学的 CS231n 课程、Ian Goodfellow 等人编著的《深度学习》书籍、形象解释图像的核心以及论文"A guide to convolution arithmetic for deep learning"。
通过深度学习可以有多种方法来实现G(z)函数。在原始的 GAN 论文中提出一种训练方法并给出初步的实验结果,这个方法得到了极大的发展和改进。其中一种想法就是在论文“Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks”中提出的,这篇论文的作者是 Alec Radford, Luke Metz, and Soumith Chintala,发表在 2016 年的 International Conference on Learning Representations (ICLR)会议上,这个方法因为提出采用深度卷积神经网络,被称为 DCGANs,它主要采用小步长卷积( fractionally-strided convolution)方法来上采样图像。
那么什么是小步长卷积以及如何实现对图片的上采样呢? Vincent Dumoulin and Francesco Visin’s 在论文"A guide to convolution arithmetic for deep learning"以及 Github 项目都给出了这种卷积算术的详细介绍,Github 地址如下:
https://github.com/vdumoulin/conv_arithmetic
上述 Github 项目给出了非常直观的可视化,如下图所示,这让我们可以很直观了解小步长卷积是如何工作的。
首先,你要知道一个正常的卷积操作是一个卷积核划过输入区域(下图中蓝色区域)后生成一个输出区域(下图的绿色区域)。这里,输出区域的尺寸是小于输入区域的。(当然,如果你还不知道,可以先看下斯坦福大学的CS231n 课程或者论文"A guide to convolution arithmetic for deep learning"。)
![[GAN学习系列3]采用深度学习和 TensorFlow 实现图片修复(中)_第2张图片](http://img.e-com-net.com/image/info10/99468e90f24741939b33bb286ba16dfb.gif)
接下来,假设输入是 3x3。我们的目标是通过上采样让输出尺寸变大。你可以认为小步长卷积就是在像素之间填充 0 值来拓展输入区域的方法,然后再对输入区域进行卷积操作,正如下图所示,得到一个 5x5 的输出。
![[GAN学习系列3]采用深度学习和 TensorFlow 实现图片修复(中)_第3张图片](http://img.e-com-net.com/image/info10/cb45f627ac0e47bbbafd4b22ccb233f8.gif)
注意,对于作为上采样的卷积层有很多不同的名字,比如全卷积(full convolution), 网络内上采样(in-network upsampling), 小步长卷积(fractionally-strided convolution), 反向卷积(backwards convolution), 反卷积(deconvolution), 上卷积(upconvolution), 转置卷积(transposed convolution)。这里并不鼓励使用反卷积(deconvolution)这个词语,因为在数学运算或者计算机视觉的其他应用中,这个词语有着其他完全不同的意思,这是一个非常频繁使用的词语。
现在利用小步长卷积作为基础,我们可以实现G(z)函数,让它接收一个的向量输入,然后输出一张尺寸是 64x64x3 的彩色图片,其网络结构如下图所示:
![[GAN学习系列3]采用深度学习和 TensorFlow 实现图片修复(中)_第4张图片](http://img.e-com-net.com/image/info10/ee8c75146836409fa6a99ca82676635f.jpg)
在 DCGAN 这篇论文中还提出了其他的一些技巧和改进来训练 DCGANs,比如采用批归一化(batch normalization)或者是 leaky ReLUs 激活函数。
采用 G(z) 生成假的图片
现在先让我们暂停并欣赏下这种G(z)网络结构的强大,在 DCGAN 论文中给出了如何采用一个卧室图片数据集训练 一个 DCGAN 模型,然后采用G(z)生成如下的图片,它们都是生成器网络 G 认为的卧室图片,注意,下面这些图片都是原始训练数据集没有的!
![[GAN学习系列3]采用深度学习和 TensorFlow 实现图片修复(中)_第5张图片](http://img.e-com-net.com/image/info10/836edfdd506f430195af5db64b9ad366.jpg)
此外,你还可以对 z 输入实现一个向量算术操作,下图就是一个例子:
![[GAN学习系列3]采用深度学习和 TensorFlow 实现图片修复(中)_第6张图片](http://img.e-com-net.com/image/info10/e86d0add0ae948de90117cf5345ef636.jpg)
[ML-Heavy] 训练 DCGAN
现在我们定义好了G(z),也知道它的能力有多强大,问题来了,怎么训练呢?我们需要确定很多隐变量(或者说参数),这也是采用对抗网络的原因了。
首先,我们先定义几个符号。表示训练数据,但概率分布未知,表示从已知的概率分布采样的样本,一般从高斯分布或者均匀分布采样,z也被称为随机噪声,最后一个,就是 G 网络生成的数据,也可以说是生成概率分布。
接着介绍下判别器(discriminator,D)网络,它是输入一批图片x,然后返回该图片来自训练数据的概率。如果来自训练数据,D 应该返回一个接近 1 的数值,否则应该是一个接近 0 的值来表示图片是假的,来自 G 网络生成的。在 DCGANs 中,D 网络是一个传统的卷积神经网络,如下图所示,一个包含4层卷积层和1层全连接层的卷积神经网络结构。
![[GAN学习系列3]采用深度学习和 TensorFlow 实现图片修复(中)_第7张图片](http://img.e-com-net.com/image/info10/9507aee780d548a3953f38eaa4f1f007.jpg)
因此,训练 D 网络的目标有以下两个:
- 如果
x来自训练数据集,最大化D(x); - 如果
x是来自 G 生成的数据,最小化D(x)。
对应的 G 网络的目标就是要欺骗 D 网络,生成以假乱真的图片。它生成的图片也是 D 的输入,所以 G 的目标就是最大化D(G(z)),也等价于最小化1-D(G(z)),因为 D 其实是一个概率估计,且输出范围是在 0 到 1 之间。
正如论文提到的,训练对抗网络就如同在实现一个最小化最大化游戏(minimax game)。如下面的公式所示,第一项是对真实数据分布的期望,第二项是对生成数据的期望值。
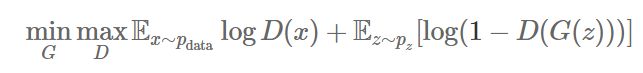
训练的步骤如下图所示,具体可以看下我之前写的文章[GAN学习系列2] GAN的起源有简单介绍了这个训练过程,或者是看下 GAN 论文[5]的介绍
![[GAN学习系列3]采用深度学习和 TensorFlow 实现图片修复(中)_第8张图片](http://img.e-com-net.com/image/info10/1836e18019f24aeb9814a76e2861951a.jpg)
目前的 GAN 和 DCGAN 实现
目前在 Github 上有许多 GAN 和 DCGAN 的实现(原文是写于2016年八月份,现在的话代码就更多了):
- https://github.com/goodfeli/adversarial
- https://github.com/tqchen/mxnet-gan
- https://github.com/Newmu/dcgan_code
- https://github.com/soumith/dcgan.torch
- https://github.com/carpedm20/DCGAN-tensorflow
- https://github.com/openai/improved-gan
- https://github.com/mattya/chainer-DCGAN
- https://github.com/jacobgil/keras-dcgan
本文实现的代码是基于 https://github.com/carpedm20/DCGAN-tensorflow
[ML-Heavy] TensorFlow 实现 DCGAN
这部分的实现的源代码可以在如下 Github 地址:
https://github.com/bamos/dcgan-completion.tensorflow
当然,主要实现部分代码是来自 https://github.com/carpedm20/DCGAN-tensorflow 。但采用这个项目主要是方便实现下一部分的图像修复工作。
主要实现代码是在model.py中的类DCGAN。采用类来实现模型是有助于训练后保存中间层的状态以及后续的加载使用。
首先,我们需要定义生成器和判别器网络结构。在ops.py会定义网络结构用到的函数,如linear,conv2d_transpose, conv2d以及 lrelu。代码如下所示
def generator(self, z):
self.z_, self.h0_w, self.h0_b = linear(z, self.gf_dim*8*4*4,
'g_h0_lin', with_w=True)
self.h0 = tf.reshape(self.z_, [-1, 4, 4, self.gf_dim * 8])
h0 = tf.nn.relu(self.g_bn0(self.h0))
self.h1, self.h1_w, self.h1_b = conv2d_transpose(h0,
[self.batch_size, 8, 8, self.gf_dim*4], name='g_h1', with_w=True)
h1 = tf.nn.relu(self.g_bn1(self.h1))
h2, self.h2_w, self.h2_b = conv2d_transpose(h1,
[self.batch_size, 16, 16, self.gf_dim*2], name='g_h2', with_w=True)
h2 = tf.nn.relu(self.g_bn2(h2))
h3, self.h3_w, self.h3_b = conv2d_transpose(h2,
[self.batch_size, 32, 32, self.gf_dim*1], name='g_h3', with_w=True)
h3 = tf.nn.relu(self.g_bn3(h3))
h4, self.h4_w, self.h4_b = conv2d_transpose(h3,
[self.batch_size, 64, 64, 3], name='g_h4', with_w=True)
return tf.nn.tanh(h4)
def discriminator(self, image, reuse=False):
if reuse:
tf.get_variable_scope().reuse_variables()
h0 = lrelu(conv2d(image, self.df_dim, name='d_h0_conv'))
h1 = lrelu(self.d_bn1(conv2d(h0, self.df_dim*2, name='d_h1_conv')))
h2 = lrelu(self.d_bn2(conv2d(h1, self.df_dim*4, name='d_h2_conv')))
h3 = lrelu(self.d_bn3(conv2d(h2, self.df_dim*8, name='d_h3_conv')))
h4 = linear(tf.reshape(h3, [-1, 8192]), 1, 'd_h3_lin')
return tf.nn.sigmoid(h4), h4
当初始化这个类的时候,就相当于用上述函数来构建了这个模型。我们需要创建两个 D 网络来共享参数,一个的输入是真实数据,另一个是来自 G 网络的生成数据。
self.G = self.generator(self.z)
self.D, self.D_logits = self.discriminator(self.images)
self.D_, self.D_logits_ = self.discriminator(self.G, reuse=True)
接下来是定义损失函数。这里采用的是 D 的输出之间的交叉熵函数,并且它的效果也不错。D 是期望对真实数据的预测都是 1,对生成的假数据预测都是 0,相反,生成器 G 希望 D 的预测都是 1。代码的实现如下:
self.d_loss_real = tf.reduce_mean(
tf.nn.sigmoid_cross_entropy_with_logits(self.D_logits,
tf.ones_like(self.D)))
self.d_loss_fake = tf.reduce_mean(
tf.nn.sigmoid_cross_entropy_with_logits(self.D_logits_,
tf.zeros_like(self.D_)))
self.d_loss = self.d_loss_real + self.d_loss_fake
self.g_loss = tf.reduce_mean(
tf.nn.sigmoid_cross_entropy_with_logits(self.D_logits_,
tf.ones_like(self.D_)))
接着是分别对 G 和 D 的参数聚集到一起,方便后续的梯度计算:
t_vars = tf.trainable_variables()
self.d_vars = [var for var in t_vars if 'd_' in var.name]
self.g_vars = [var for var in t_vars if 'g_' in var.name]
现在才有 ADAM 作为优化器来计算梯度,ADAM 是一个深度学习中常用的自适应非凸优化方法,它相比于随机梯度下降方法,不需要手动调整学习率、动量(momentum)以及其他的超参数。
d_optim = tf.train.AdamOptimizer(config.learning_rate, beta1=config.beta1) \
.minimize(self.d_loss, var_list=self.d_vars)
g_optim = tf.train.AdamOptimizer(config.learning_rate, beta1=config.beta1) \
.minimize(self.g_loss, var_list=self.g_vars)
定义好模型和训练策略后,接下来就是开始输入数据进行训练了。在每个 epoch 中,先采样一个 mini-batch 的图片,然后运行优化器来更新网络。有趣的是如果 G 只更新一次,D 的 loss 是不会变为0的。此外,在后面额外调用d_loss_fake和d_loss_real会增加不必要的计算量,并且也是多余的,因为它们的数值在d_optim和g_optim计算的时候已经计算到了。这里你可以尝试优化这部分代码,然后发送一个 PR 到原始的 Github 项目中。
for epoch in xrange(config.epoch):
...
for idx in xrange(0, batch_idxs):
batch_images = ...
batch_z = np.random.uniform(-1, 1, [config.batch_size, self.z_dim]) \
.astype(np.float32)
# Update D network
_, summary_str = self.sess.run([d_optim, self.d_sum],
feed_dict={ self.images: batch_images, self.z: batch_z })
# Update G network
_, summary_str = self.sess.run([g_optim, self.g_sum],
feed_dict={ self.z: batch_z })
# Run g_optim twice to make sure that d_loss does not go to zero
# (different from paper)
_, summary_str = self.sess.run([g_optim, self.g_sum],
feed_dict={ self.z: batch_z })
errD_fake = self.d_loss_fake.eval({self.z: batch_z})
errD_real = self.d_loss_real.eval({self.images: batch_images})
errG = self.g_loss.eval({self.z: batch_z})
完整的代码可以在 https://github.com/bamos/dcgan-completion.tensorflow/blob/master/model.py 中查看
在你的数据集上运行 DCGAN 模型
如果你跳过上一小节,但希望运行一些代码:这部分的实现的源代码可以在如下 Github 地址:
https://github.com/bamos/dcgan-completion.tensorflow
当然,主要实现部分代码是来自 https://github.com/carpedm20/DCGAN-tensorflow 。但采用这个项目主要是方便实现下一部分的图像修复工作。但必须注意的是,如果你没有一个可以使用 CUDA 的 GPU 显卡,那么训练网络将会非常慢。
首先需要克隆两份项目代码,地址分别如下:
https://github.com/bamos/dcgan-completion.tensorflow
http://cmusatyalab.github.io/openface
第一份就是作者的项目代码,第二份是采用 OpenFace 的预处理图片的 Python 代码,并不需要安装它的 Torch 依赖包。先创建一个新的工作文件夹,然后开始克隆,如下所示:
git clone https://github.com/cmusatyalab/openface.git
git clone https://github.com/bamos/dcgan-completion.tensorflow.git
接着是安装 Python2 版本的 OpenCV和 dlib(采用 Python2 版本是因为 OpenFace 采用这个版本,当然你也可以尝试修改为适应 Python3 版本)。对于 OpenFace 的 Python 库安装,可以查看其安装指导教程,链接如下:
http://cmusatyalab.github.io/openface/setup/
此外,如果你没有采用一个虚拟环境,那么需要加入sudo命令来运行setup.py实现全局的安装 OpenFace,当然如果安装这部分有问题,也可以采用 OpenFace 的 docker 镜像安装。安装的命令如下所示
cd openface
pip2 install -r requirements.txt
python2 setup.py install
models/get-models.sh
cd ..
接着就是下载一些人脸图片数据集了,这里并不要求它们是否带有标签,因为不需要。目前开源可选的数据集包括
- MS-Celeb-1M--https://www.microsoft.com/en-us/research/project/msr-image-recognition-challenge-irc/
- CelebA--http://mmlab.ie.cuhk.edu.hk/projects/CelebA.html
- CASIA-WebFace--http://www.cbsr.ia.ac.cn/english/CASIA-WebFace-Database.html
- FaceScrub--http://vintage.winklerbros.net/facescrub.html
- LFW--http://vis-www.cs.umass.edu/lfw/
- MegaFace--http://megaface.cs.washington.edu/
然后将数据集放到目录dcgan-completion.tensorflow/data/your-dataset/raw下表示其是原始的图片。
接着采用 OpenFace 的对齐工具来预处理图片并调整成64x64的尺寸:
./openface/util/align-dlib.py data/dcgan-completion.tensorflow/data/your-dataset/raw align innerEyesAndBottomLip data/dcgan-completion.tensorflow/data/your-dataset/aligned --size 64
最后是整理下保存对齐图片的目录,保证只包含图片而没有其他的子文件夹:
cd dcgan-completion.tensorflow/data/your-dataset/aligned
find . -name '*.png' -exec mv {} . \;
find . -type d -empty -delete
cd ../../..
然后确保已经安装了 TensorFlow,那么可以开始训练 DCGAN了:
./train-dcgan.py --dataset ./data/your-dataset/aligned --epoch 20
在samples文件夹中可以查看保存的由 G 生成的图片。这里作者是采用手上有的两个数据集 CASIA-WebFace 和 FaceScrub 进行训练,并在训练 14 个 epochs 后,生成的结果如下图所示:
还可以通过 TensorBoard 来查看 loss 的变化:
tensorboard --logdir ./logs
![[GAN学习系列3]采用深度学习和 TensorFlow 实现图片修复(中)_第9张图片](http://img.e-com-net.com/image/info10/bdaf39823dd1482cb182b9e3d6912adb.jpg)
小结
这就是本文的第二部分内容,主要是介绍了 DCGAN 的基本原理以及代码实现,还有就是训练前的准备和开始训练,训练的实验结果。
在下一篇将介绍最后一步内容,如何利用 DCGAN 来实现图像修复的工作!
欢迎关注我的微信公众号--机器学习与计算机视觉,或者扫描下方的二维码,在后台留言,和我分享你的建议和看法,指正文章中可能存在的错误,大家一起交流,学习和进步!
![[GAN学习系列3]采用深度学习和 TensorFlow 实现图片修复(中)_第10张图片](http://img.e-com-net.com/image/info10/4a744e8503834a659a99c0003620cd47.jpg)
我的个人博客:http://ccc013.github.io/
CSDN 博客:https://blog.csdn.net/lc013/article/details/84845439
推荐阅读
1.机器学习入门系列(1)--机器学习概览(上)
2.机器学习入门系列(2)--机器学习概览(下)
3.[GAN学习系列] 初识GAN
4.[GAN学习系列2] GAN的起源
5.[GAN学习系列3]采用深度学习和 TensorFlow 实现图片修复(上)