SOLOv2 学习笔记
博客原文:https://blog.csdn.net/weixin_44270815/article/details/105283301
模型下载教程:https://blog.csdn.net/weixin_44270815/article/details/105283697
论文地址:https://arxiv.org/pdf/2003.10152.pdf
开源地址:https://github.com/aim-uofa/AdelaiDet/
SOLOv2: Dynamic, Faster and Stronger
作者:xinlong wang
**0介绍:**在这项工作中,我们旨在建立一个性能强大的简单,直接和快速的实例细分框架。我们遵循Wang等人的SOLO方法的原理。“ SOLO:按位置分割对象”。重要的是,我们通过动态学习对象分割器的蒙版头,使蒙版头以位置为条件,进一步迈出了一步。具体来说,将遮罩分支解耦为遮罩内核分支和遮罩特征分支,分别负责学习卷积内核和卷积特征。此外,我们提出矩阵NMS(非最大抑制)以显着减少由于掩码的NMS造成的推理时间开销。我们的Matrix NMS可以一次完成具有并行矩阵运算的NMS,并产生更好的结果。我们演示了一个简单的直接实例分割系统,该系统在速度和准确性上均优于一些最新方法。轻量级版本的SOLOv2以31.3 FPS的速度执行,并产生37.1的遮罩副产品),全景分割显示了除实例分割之外,还可以作为许多实例级识别任务的新基准的潜力。
1 引言 通用对象检测需要定位单个对象并识别其类别的功能。为了表示对象的位置,边框以其简单性而突出。已经广泛探索了使用边界框对对象进行本地化的方法,包括问题表述,网络体系结构,后处理以及所有专注于优化和处理边界框的问题。量身定制的解决方案极大地提高了性能和效率,从而使最近的下游应用成为可能。但是,边界框是粗糙且不自然的。人类的视觉可以毫不费力地通过其边界来定位对象。实例分割i。Ë使用遮罩定位对象,将对象定位推到像素级别的极限,并为更多实例级别的感知和应用打开了机会。迄今为止,大多数现有方法都在边界框(即)的视图中处理实例分割。例如,在(锚定)边界框中分割对象。如何开发包括支持工具e的纯实例分割。与边界框检测和在其之上构建的实例分割方法相比,后处理(例如后处理)在很大程度上尚未开发。
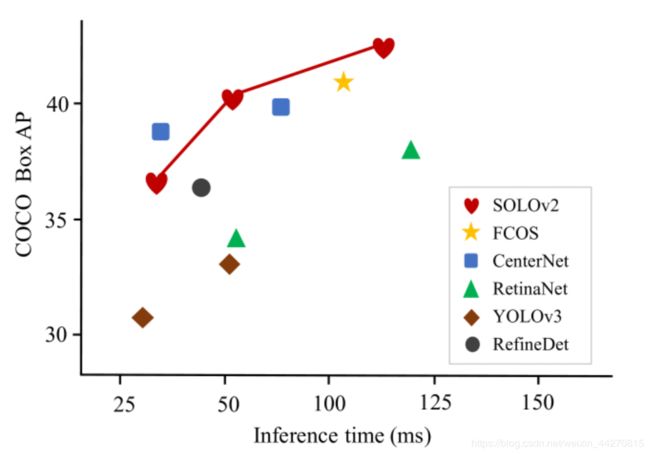
 图1: COCO 测试中的速度精度折衷 - 开发人员提供了一些最新的实例分割方法。拟议的SOLOv2优于一系列最新算法。所有方法的推理时间都在Tesla V100-GPU机器上进行了测试。
图1: COCO 测试中的速度精度折衷 - 开发人员提供了一些最新的实例分割方法。拟议的SOLOv2优于一系列最新算法。所有方法的推理时间都在Tesla V100-GPU机器上进行了测试。
最后主要结果:
在表 1的 MS COCO test - dev实例分割中,我们将SOLOv2与最新方法进行了比较。带有ResNet-101的SOLOv2实现了39.7%的蒙版AP,这比SOLOv1和其他最新实例分割方法要好得多。我们的方法显示出其优越性espically对大对象(ē。摹。+5.0 APL比Mask R-CNN)。
我们还提供了COCO的速度准确性权衡,以与一些主要实例分割器进行比较(图 1)。我们将使用ResNet-50,ResNet-101,ResNet-DCN-101以及第5.1.3节中介绍的两个轻量级版本展示我们的模型 。所提出的SOLOv2在准确性和速度上均胜过一系列最新算法。运行时间在我们的本地计算机上通过单个V100 GPU,Pytorch 1.2和CUDA 10.0进行了测试。我们下载代码和预先训练的模型,以测试同一台机器上每种模型的推理时
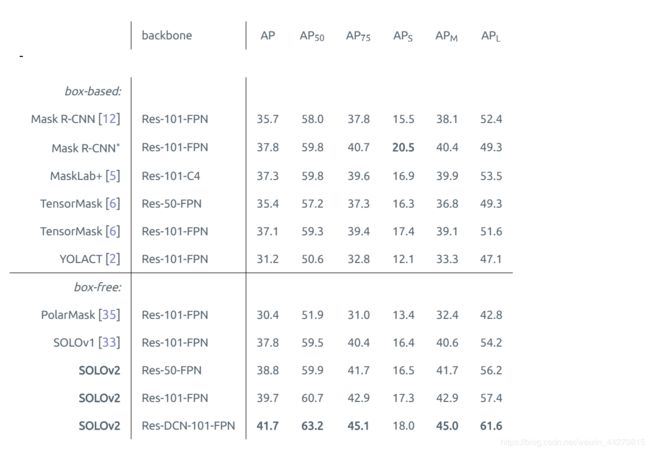
表1:实例分割上COCO掩模AP(%)试验 - dev的。所有条目均为单模型结果。面具R-CNN∗是我们的改进版本,具有扩展比例和更长的培训时间(6×)。“ DCN”是指使用的可变形卷积。
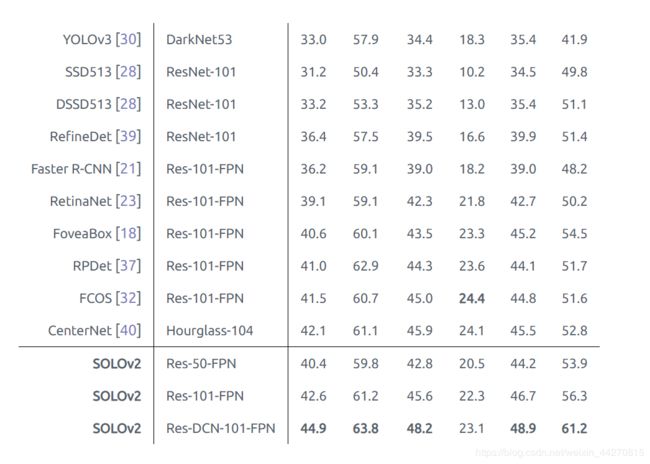
表2:对象检测框AP(%)在COCO 测试 - dev的。尽管我们的边界框是直接从预测的蒙版生成的,但其精度却优于大多数最新方法。典型方法的速度精度折衷如图7所示 。
SOLOv2可视化
我们将SOLOv2从两个方面形象化地学习:蒙版特征行为和动态学习的卷积内核进行卷积后的最终输出。
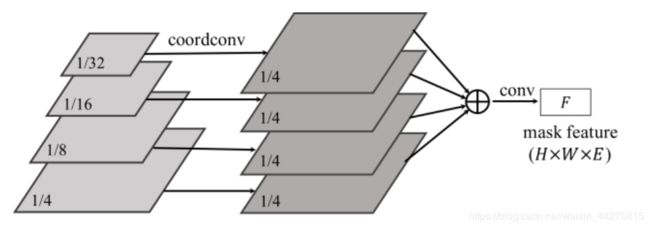
我们可视化蒙版特征分支的输出。我们使用具有64个输出通道的模型(我。ê,Ë = 64为最后一个特征之前映射到掩蔽预测),便于可视化。在这里,我们绘制了64个通道中的每个通道(调用通道空间分辨率为H × W),如图5所示 。
有两种主要模式。首先,掩模特征是位置感知的。它显示了水平和垂直扫描图像中对象的明显行为。有趣的是,它确实符合去耦头SOLO中的目标:按对象的独立水平和垂直位置类别对其进行分段。另一个明显的模式是某些特征图负责激活所有前景对象,例如。g。,白盒中的那个。
最终输出如图8所示 。不同的对象具有不同的颜色。我们的方法在各种场景中显示出令人鼓舞的结果。值得指出的是,边界处的细节分割得很好,尤其是对于大型物体。在图6中,我们将Mask R-CNN与对象详细信息进行了比较 。我们的方法显示出很大的优势。

图5: SOLOv2 遮罩功能行为。 每个绘制的子图对应于掩模预测之前的最后一个特征图的64个通道之一。遮罩功能似乎对位置敏感(橙色框),而一些遮罩功能与位置无关,并且在所有实例上均已激活(白框)。最好在屏幕上观看。
给出了Matrix NMS的Python代码:
def matrix nms(scores, masks, method=’gauss’, sigma=0.5):
# scores: mask scores in descending order (N)
# masks: binary masks (NxHxW)
# method: ’linear’ or ’gauss’
# sigma: std in gaussian method
# reshape for computation: Nx(HW)
masks = masks.reshape(N, HxW)
# pre−compute the IoU matrix: NxN
intersection = mm(masks, masks.T)
areas = masks.sum(dim=1).expand(N, N)
union = areas + areas.T − intersection
ious = (intersection / union).triu(diagonal=1)
# max IoU for each: NxN
ious cmax = ious.max(0)
ious cmax = ious cmax.expand(N, N).T
# Matrix NMS, Eqn.(4): NxN
if method == ’gauss’: # gaussian
decay = exp(−(iousˆ2 − ious cmaxˆ2) / sigma)
else: # linear
decay = (1 − ious) / (1 − ious cmax)
# decay factor: N
decay = decay.min(dim=0)
return scores ∗ decay
其他图片: