机器学习 线性回归----Sklearn & fit方法(多种梯度下降方法)
文章目录
- 机器学习 线性回归
- 一、一元线性回归算法
- 1.回归的理解
- 2.回归应用
- 3.线性回归
- (1)利用Sklearn做线性回归的预测
- (2)例:预测一组数据中当输入为12 对应输出的值。
- 4.线性回归拟合原理(fit方法)
- (1)损失函数
- (2)梯度下降法
- (3)梯度下降的分类
- 1>“Batch” Gradient Descent 批梯度下降
- 2>“Stochastic” Gradient Descent 随机梯度下降
- 3>“Mini-Batch” Gradient Descent “Mini-Batch”梯度下降
- 二、多元线性回归算法
- 1.多元梯度下降法
- 2.多元批梯度下降例
- 3.三种梯度下降总结
- (1)随机梯度下降
- (2)Mini-batch梯度算法优化
- (3)多项式回归
- 1>不同维度绘制的图形:
- 2>对于已知数据进行多项式拟合:心电波形的绘制
- 3>保险保费的多元线性回归模型案例
- 三、线性回归总结
机器学习 线性回归
一、一元线性回归算法
1.回归的理解
大自然让我们回归到一定的区间范围之内;反过来说就是,有一个平均的水平,可以让突出的事物能向他靠拢。
回归是由达尔文(Charles Darwin)的表兄弟Francis Galton发明的。 Galton于1877年完成了第一次回归预测,目的是根据上一代豌豆种子(双亲)的尺寸来预测下一代豌豆种子(孩子)的尺寸。Galton在大量对象上应用了回归分析,甚至包括人的身高。他注意到,如果双亲的高度比平均高度高,他们的子女也倾向于比平均高度高,但尚不及双亲。孩子的高度向着平均高度回退(回归)。Galton在多项研究上都注意到这个现象,所以尽管这个英文单词跟数值预测没有任何关系,但这种研究方法仍被称作回归 。
那些高个子的后代的身高,有种回归到大众身高的趋势。 eg: 姚明身高2米26,叶莉身高1米90, 但是他们后代的身高是会逐渐回归到正常的身高水平。
2.回归应用
销售量预测
制造缺陷预测。
预测名人的离婚率。
预测所在地区的房价。
3.线性回归
线性:利用算法生成的模型是一条直线。
回归:让数据聚集到一个特定的模型中。
线性回归:如果模型是一条直线,就是让数据靠近这条直线。
(1)利用Sklearn做线性回归的预测
预测步骤如下:
- 导包:
from sklearn.linear_model import LinearRegression - 导数据:导入文件或者随机生成
- 建模:利用 sklearn中 LinearRegression的
fit方法:
1> 实例化一个线性回归类:lin_reg= LinearRegression()
2> 训练模型,确定参数:lin_reg.fit(X,Y)
3> 参数存入对象lin_reg中,可以通过lin_reg.intercept_(截距)、lin_reg.coef_(系数)查看参数。 - 预测:利用 sklearn中 LinearRegression的predict()方法:
1> 准入预测数据X_predict
2> lin_reg.predict(X_predict)
(2)例:预测一组数据中当输入为12 对应输出的值。
import numpy as np
from sklearn.linear_model import LinearRegression #在线性模型中导入线性回归
X=np.array([1,2,3,4,5,6,7,8,9,10,11]).reshape(-1,1)#x从一维转为二维
Y=np.array([3,4,5,7,9,11,13,15,17,19,21])#Y:一维
#实例化对象
lin_reg= LinearRegression()
#调用fit方法 训练模型找规律
lin_reg.fit(X,Y)
#找到规律 截距与斜率
print(lin_reg.intercept_,lin_reg.coef_)
#预测x=12对应的Y
X_new=np.array([[12]]) #创建数组
print(lin_reg.predict(X_new))
执行结果:
0.03636363636363171 [1.87272727]
[22.50909091]
4.线性回归拟合原理(fit方法)
- 拟合就是把平面上一系列的点,用一条光滑的曲线连接起来。因为这条曲线有无数种可能,从而有各种拟合方法。拟合的曲线一般可以用函数表示。
- 对于一元线性回归(单变量线性回归)来说,学习算法为 y = ax + b 换一种写法: hθ(x) = θ0 + θ1x1
- 线性回归实际上要做的事情就是: 选择合适的参数(θ0, θ1),使得hθ(x)方程,很好的拟合训练集。实现如何把最有可能的直线与我们的数据相拟合。
- 我们选择的参数决定了我们得到的直线相对于我们的训练集的准确程度,模型所预测的值与训练集中实际值之间的差距就是建模误差(modeling
error)。 - 我们的目标便是选择出可以使得建模误差的平方和能够最小的模型参数。 即使得损失函数最小。
- 模型=规律=函数=函数所表示的图像
(1)损失函数
判断模型最优拟合方式:损失函数- 损失函数含义:所有的点与模型距离平均和的公式。距离为0表示所有点都在直线上,参数为最优参数,拟合最准确。距离不为0时,要尽量找到损失函数的最小值时所对应的参数。

(2)梯度下降法
使得损失函数最小的方法:梯度下降法
- 思想:
1:随机初始化参数确定模型θ0 、θ1,得到一个损失函数值
2:使用特殊的更新方法更新参数θ0 、θ1,使得每一次所对应的损失函数的值越来越小。
3:直到更新参数损失函数的值变化波动不大,表示斜率到达最平稳处参数不变化进而损失函数不变化,找到损失函数最小值,此时对应的参数为最优解。

即:

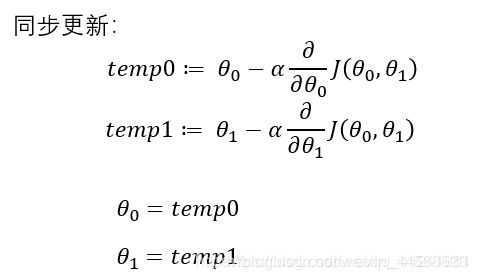
- 损失函数是一个凸函数,斜率变化是逐渐平缓的
如果α太小的话,梯度下降会很慢
如果α太大的话,梯度下降越过最小值,不仅不会收敛,而且有可能发散 - 即使学习率α是固定不变的,梯度下降也会熟练到一个最低点
因为随着梯度下降迭代次数的递增,斜率会趋于平缓,也就是说,导数部分/(_1 ) (_0,_1 )会慢慢变小
做法: 根据上图公式
1> 求出损失函数对参数的偏导数
2> 损失函数对参数的偏导数乘学习率(梯度下降的幅度),得到梯度下降的距离。
3> 用梯度下降的距离更新参数
(3)梯度下降的分类
1>“Batch” Gradient Descent 批梯度下降
批梯度下降:指的是每下降一步,使用所有的训练集来计算梯度值
在梯度下降中,在计算微分求导项时,我们需要进行求和运算,所以,在每一个单独的梯度下降中,我们最终都要计算这样一个东西,这个项需要对所有个训练样本求和。因此,批量梯度下降法这个名字说明了我们需要考虑所有这一"批"训练样本。
线性回归实现一元批梯度下降:
import numpy as np
X = 2*np.random.rand(100,1) #生成100行1列的向量范围为0-2
Y=4+3*X+np.random.randn(100,1) #截距为4,斜率为3
#c_把两个维度相同的矩阵结合成以个矩阵 3x1 3x2 ->3x3
X_b=np.c_[np.ones((100,1)),X] #将 100行1列全为1的向量与X向量结合。实现矩阵的相乘截距处乘1,因此将x结合100行1列全为1的向量。为样本
learning_rate=0.1 #实现梯度下降函数的步长为0.1(1、0.1、0.2.。)
n_iterations=1000 #梯度函数执行1000次,自行判断是否收敛
m=100#样本数为100
theta=np.random.randn(2,1) #初始化,theta为一次函数的斜率和截距 2行1列
count=0
for iteration in range(n_iterations):
count+=1
#按照梯度函数公式求梯度
gradients=1.0/m*X_b.T.dot(X_b.dot(theta)-Y) #矩阵相乘实现了加法。X_b中全为1的一列实现截距,另一列实现X的系数
theta=theta-learning_rate*gradients #更新theta值,根据梯度下降公式theta值不变表示找到损失函数最小值。
print(count) #判断theta更新1000次的时候是否逼近真实值
print(theta)
执行结果:
1000
[[4.28222204]
[2.90247165]]
2>“Stochastic” Gradient Descent 随机梯度下降
随机梯度下降:指的是每下降一步,使用一条训练集来计算梯度值
假设有100个样本,批梯度下降一次使用100个样本更新theta 一次就是epoch
随机梯度下降一次使用1个样本 样本数为m个,m次为一个epoch,如果设置n_epochs=n,theta更新了mn次
3>“Mini-Batch” Gradient Descent “Mini-Batch”梯度下降
“Mini-Batch”梯度下降:指的是每下降一步,使用一部分的训练集来计算梯度值
二、多元线性回归算法
- 我们探讨了单变量/特征的回归模型,现在我们对房价模型增加更多的特征,例如房间数楼层等,构成一个含有多个变量的模型。
1.多元梯度下降法
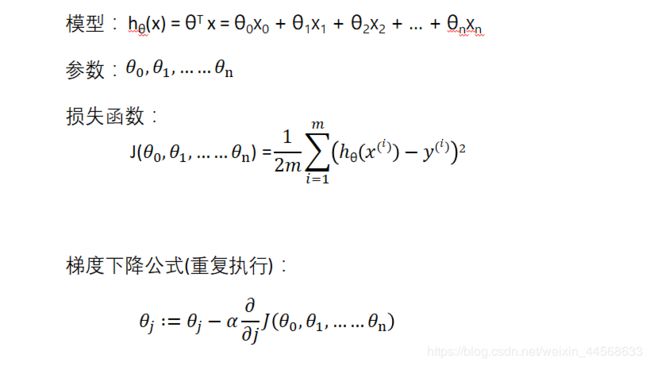

2.多元批梯度下降例
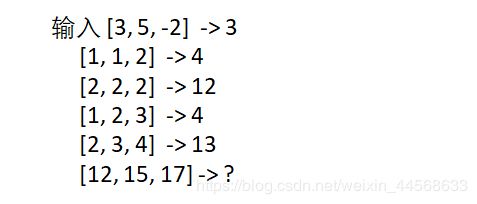
代码如下:
分析:每一行对应一个输出,每一列为一个特征。每三个特征值确定一个标签,将三类特征作为输入,对应的标签值作为输出。
import numpy as np
from sklearn.linear_model import LinearRegression #在线性模型中导入线性回归
X2 = np.array([3,1,2,1,2]).reshape(-1,1)#x从一维转为二维
X1 = np.array([5,1,2,2,3]).reshape(-1,1)#x从一维转为二维
X3 = np.array([-1*2,2,2,3,4]).reshape(-1,1)#x从一维转为二维
X=np.c_[X2,X1,X3]
Y= np.array([3,4,12,4,13])
#实例化对象
lin_reg= LinearRegression()
#调用fit方法 训练模型找规律
lin_reg.fit(X,Y)
#找到规律 截距与斜率
print(lin_reg.intercept_,lin_reg.coef_)
#预测x=12对应的Y
X_new=np.array([[12,15,17]]) #创建数组
print(lin_reg.predict(X_new))
执行结果:
-7.609756097560967 [10.38617886 -3.14634146 2.38617886]
[110.39430894]
注意:尝试在如下的数值中选择α : 0.001, 0.003, 0.01, 0.03, 0.1, 0.3, 1,…
3.三种梯度下降总结
训练集比较小: 使用批梯度下降(小于2000个)
训练集比较大:使用Mini-bitch梯度下降 一般的Mini-batch size 是64,128,256, 512,1024, Mini-batch size要适用CPU/GPU的内存

(1)随机梯度下降
随机梯度下降思想:随机使用一个数据。把m个样本分成m份,每次用1份做梯度下降;也就是说,当有m个样本时,批梯度下降只能做一次梯度下降,但是随机梯度下降可以做m次。
假设有100个样本,批梯度下降一次使用100个样本更新theta 一次就是epoch,随机梯度下降一次使用1个样本 样本数为m个,m次为一个epoch,如果设置n_epochs=n,theta更新了mn次。
"""
使用衰减学习率的随机梯度下降
"""
import numpy as np
import random
X = 2*np.random.rand(100,1)
Y=4+3*X+np.random.randn(100,1)
X_b=np.c_[np.ones((100,1)),X]
n_epochs=500
a0=0.1
decay_rate=1
m=100
num=[i for i in range(m)]
def learning_schedule(epoch_num): #衰减学习率的公式
return (1.0/(decay_rate*epoch_num +1))*a0
theta=np.random.randn(2,1)
for epoch in range(n_epochs):#用m个样本做n_epochs个轮代
rand=random.sample(num,100) #生成100行、100列,每一行都是100个不重复的随机数
#print(rand)
for i in range(m):
random_index=rand[i] #索引
xi=X_b[random_index:random_index+1]#随机从X_b与Y中找一个数据
yi=Y[random_index:random_index+1]
gradients=xi.T.dot(xi.dot(theta)-yi) #只用了一个数据不需要求平均值
learning_rate=learning_schedule(epoch+i)#每更新一次theta学习率也更新,收敛更准确
theta= theta - learning_rate * gradients
print(theta)
执行结果:
[[4.16191884]
[2.84624263]]
(2)Mini-batch梯度算法优化
随机梯度下降会丧失向量带来的加速,所以我们不会太用随机梯度下降。
如果 mini-batch 大小 = m : 那他就是批梯度下降
如果 mini-batch 大小 = 1 : 那他就是随机梯度下降
如果 mini-batch 1 < 大小 < m :那他就是‘Mini-batch’随机梯度下降
优化: 学习率衰减
在做Mini-batch的时候,因为噪声的原因,可能训练结果不是收敛的,而是在最低点周围晃动,如果我们要解决这个问题,那我们就需要减少学习率,让他在尽量小的范围内晃动
1 epoch = 1 次遍历所有的数据
学习率衰减公式:
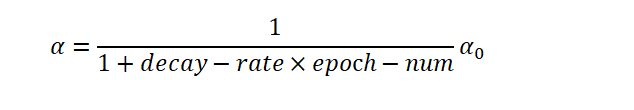
Mini-batch梯度下降:将100个数据分成5份 每份20个,一次执行20个数据
import numpy as np
import random
X = 2 * np.random.rand(100, 1)
y = 4 + 3 * X + np.random.randn(100, 1)
X_b = np.c_[np.ones((100, 1)), X]
# print(X_b)
n_epochs = 500
t0, t1 = 5, 50
m = 100
num = [i for i in range(100)]
def learning_schedule(t):
return float(t0) / (t + t1)
theta = np.random.randn(2, 1)
batch_num = 5
batch_size = m // 5
# epoch 是轮次的意思,意思是用m个样本做一轮迭代
for epoch in range(n_epochs):
# 生成100个不重复的随机数
for i in range(batch_num):
start = i*batch_size
end = (i+1)*batch_size
xi = X_b[start:end]
yi = y[start:end]
gradients = 1/batch_size * xi.T.dot(xi.dot(theta)-yi)
learning_rate = learning_schedule(epoch*m + i)
theta = theta - learning_rate * gradients
print(theta)
执行结果:
[[4.07699116]
[2.9148502 ]]
(3)多项式回归
1>不同维度绘制的图形:
"""
多项式拟合:一阶x组成二阶生维数据 改变原始数据特征 再当作一阶的数据做线性回归求参
"""
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import PolynomialFeatures #导入预处理包中的多项式特征提取
from sklearn.linear_model import LinearRegression
m=100
X=6*np.random.rand(m,1)-3
Y=0.5*X**2+X+2+np.random.randn(m,1)
d={1:'g-',2:'r+',10:'y*'}
for i in d:
poly_features=PolynomialFeatures(degree=i,include_bias=False)#include_bias=False表示不要偏差,截距为0
X_poly=poly_features.fit_transform(X) #对原数据生维产生新的数据特征
print(X_poly)
#当作一阶的数据做线性回归
lin_reg=LinearRegression()
lin_reg.fit(X_poly,Y) #求参
y_predict=lin_reg.predict(X_poly) #对生维的数据预测曲线结果
plt.plot(X_poly[:, 0],y_predict,d[i]) #X_poly[:,0]取第一列的值
plt.show()

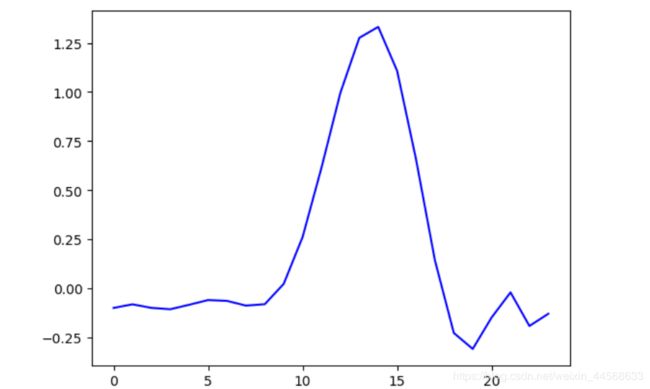
2>对于已知数据进行多项式拟合:心电波形的绘制
X扩充如下才可以对应每一个Y:
[11111111111111111111] #XYshape相同,X与Y的每一个位置都要一一对应
[222222222222222222]
[333333333333333333]
…
[23 23 23 23 23 … 23]
"""
拟合心电信号,每一个输出要对应一个输入。每一列是一个数据,共8965列,共8965个数据
Y,X要扩充
数据大小为23x8965 要让输入输出shape相同 输入输出均为n行一列
由于数据格式的特殊性:即每一列为一个输出。每一类特征值的数量要与输出值(样本数)的数量相同。Y有23行8965列,表示有8965个样本数,因此每一类特征值的数量也应该为8965个,
本案例X只有一个特征:时间。为1-23秒 Y为23行8965列的所有值,所有行轮回一次为一个输出波形
"""
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import PolynomialFeatures #导入预处理包中的多项式特征提取
from sklearn.linear_model import LinearRegression
import pandas as pd
data = pd.read_excel('C:/Users/scq/Desktop/pycharmprodect/机器学习code/dataSet/rb.xlsx')
Y=np.array(data) #转成2维数组
#count=Y.shape[0] #打印多少行多少列(23,8965)
X=[]
for item in range(np.array(data).shape[0]):
x=[item for j in range(np.array(data).shape[1])] #每一个Y对应一个X
X.extend(x)
X=np.array(X).reshape(-1,1) #8965行1列
Y=Y.reshape(-1,1) #8965行1列
lin_reg=LinearRegression()
poly_features=PolynomialFeatures(degree=10,include_bias=False)#include_bias=False表示不要偏差,截距为0
X_poly=poly_features.fit_transform(X) #对原数据生维求值得出新的数据特征
#当作一阶的数据做线性回归
lin_reg.fit(X_poly,Y) #求参
X_predict=np.array([i for i in range(23)]).reshape(-1,1) #随意输入一组时间,的出一组预测值连成一条线
X_poly1=poly_features.fit_transform(X_predict) #把X_predict生成10维
y_predict=lin_reg.predict(X_poly1) #对生维的预测数据预测曲线结果
plt.plot(X_predict,y_predict,'b-')
plt.show()
3>保险保费的多元线性回归模型案例
关于保险

数据信息如下图:

我们已经获取到保险公司部分数据,文件名为insurance.csv,文件内容如下。
我们可以看出数据中共有六个维度:age(年龄),sex(性别),bmi(肥胖指数),children(孩子数量),smoker(是否吸烟),region(居住地)。charges则是当前数据人上年度在保险的额度。
所以我们可以构建一个六维高维空间来求解这个模型。
相对于年龄来说, 年龄越大, 购买保险的金额应该越大;
相对于性别来说,整体女性的寿命大于男性寿命大约10年, 因此男性的保险额度应该更大。
相对于肥胖指数来说, 肥胖指数越小, 身体状况越不好, 购买保险的金额应该越大;
相对于孩子的数量来说, 孩子的数量越多, 压力越大, 越劳累, 购买保险的金额应该越大;
相对于是否吸烟来说, 吸烟的人寿命远少于不吸烟的寿命, 因此 购买保险的金额应该越大;
相对于地区来说, 地区环境越差, 有雾霾, 则越容易生病, 那么购买保险的金额应该越大;
实战:
如何从训练数据中估计统计量。
如何从数据估计线性回归系数。
如何使用线性回归预测新数据
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import PolynomialFeatures #导入预处理包中的多项式特征提取
from sklearn.linear_model import LinearRegression
import pandas as pd
data = pd.read_csv('C:/Users/scq/Desktop/pycharmprodect/机器学习code/dataSet/insurance.csv')
reg=LinearRegression()
x=data[['age','sex','bmi','children','smoker','region']]
x=x.apply(pd.to_numeric,errors='coerce') #将文字转为0
y=data['charges']
y=y.apply(pd.to_numeric,errors='coerce')
x.fillna(0,inplace=True)
y.fillna(0,inplace=True)
poly_features=PolynomialFeatures(degree=10,include_bias=False)#include_bias=False表示不要偏差,截距为0
X_poly=poly_features.fit_transform(x)
reg.fit(X_poly,y)
y_predict=reg.predict(X_poly)
plt.plot(X_poly[:,0],y_predict,'r.') #看年龄与金钱的关系
plt.plot(x['age'],y,'b.')
plt.show()

- 代码分析
import pandas as pd #pandas包数据处理比较快
import matplotlib.pyplot as plt
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression
data = pd.read_csv('insurance.csv')
print(type(data))# 数据类型是DataFrame,相当于pandas读取数据之后,这个对象有很多方法,我们可以调用
print(data.head()) #输出前5条数据
print(data.tail())
# describe做简单的统计摘要
print(data.describe())
结果如下:
#对保险金额又影响的特征:年龄,性别,bmi,有没有孩子,是否抽烟,区域,charges
age sex bmi children smoker region charges
0 19 1 27.900 0 0 1 sss
1 18 0 33.770 1 1 0 1725.5523
2 28 0 33.000 3 1 0 4449.462
3 33 0 22.705 0 1 2 21984.47061
4 32 0 28.880 0 1 2 3866.8552
age sex bmi children smoker region charges
1333 50 0 30.97 3 1 2 10600.5483
1334 18 1 31.92 0 1 3 2205.9808
1335 18 1 36.85 0 1 0 1629.8335
1336 21 1 25.80 0 1 1 2007.945
1337 61 1 29.07 0 0 2 29141.3603
#对特征进行一个简单的统计,count:特征的数量;mean:平均数;std:方差;min:最小值;25%:指min和50%中间的数;后面同
age sex ... smoker region
count 1338.000000 1338.000000 ... 1338.000000 1338.000000
mean 39.207025 0.494768 ... 0.795217 1.455157
std 14.049960 0.500160 ... 0.403694 1.130197
min 18.000000 0.000000 ... 0.000000 0.000000
25% 27.000000 0.000000 ... 1.000000 0.000000
50% 39.000000 0.000000 ... 1.000000 1.000000
75% 51.000000 1.000000 ... 1.000000 2.000000
max 64.000000 1.000000 ... 1.000000 3.000000
[8 rows x 6 columns]
三、线性回归总结


