白话内存屏障(Memory Barrier)与volatile关键字
MESI所带来的问题
上一节我们说到了MESI缓存一致性协议是如何实现的,实际上就是在进行写的时候只有一个能写,告诉别的核中的缓存都是过期的需要从最新的里面读;在读的时候大家可以一起读。虽然有了这个协议但是仔细分析一下会有这样一种情况的发生:
首先有一个变量在多个核中的缓存存在,那么这个缓存的状态是S(shared)共享的,现在核A想要修改这个变量,首先核A会向所有拥有相同缓存的其他核发送一个请求,告诉其他核中的缓存是I(Invalid)无效的,其他核收到这个信息将自己核中的缓存状态设置为无效之后,返回一个设置完成的消息,这个核A收到这个无效状态修改的消息后,再把自己的状态改为E(Exclusive)独享的,然后修改为M(Modified)进行缓存修改。
乍看之下没什么问题,但是在核A等待其他核返回无效状态修改的消息返回的时候是一直在阻塞没事情干的,这对于高性能的CPU是不能容忍的,所以这个时候设计者引入了写缓存(Store Buffer)的无效化队列(Invalidate Queue)。
写缓存(Store Buffer)
写缓存是一个容量极小的高速存储部件,每个核都有自己的写缓存,而且一个核不能够读取到其他核的写缓存(Store Buffer)的内容。
如上面的场景,核A修改共享的缓存,先将这个修改操作放入到写缓存(Store Buffer)中,再告诉其他核中的缓存失效了,然后核A继续执行其他指令操作,当接受到了其他核返回无效状态修改的消息之后,才将写缓存(Store Buffer)中的操作写入到核A中的缓存中,这时写操作才算完成。
这样就解决了等待阻塞所带来的性能问题,减少了延时,提高了执行效率。上图理解一下:

无效化队列(Invalidate Queue)
同样的,回应方为了能够快速进行回应所以,先将无效的操作放到队列里面去,并立刻返回无效状态修改的消息,等当前的操作执行完再回来真正的把缓存里面的值标识为I状态,这个存放无效操作的队列就叫做无效化队列。同时可能也是考虑到了写缓存(Store Buffer)是比较小的高速缓存,如果不能够及时返回会造成写缓存满了,还是需要等待无效状态修改的消息的返回才能继续进行后续的指令,所以就出现了无效化队列和写缓存配合使用。
这样就解决了写缓存(Store Buffer)带来的性能问题。上图理解一下:

写缓冲和无效化队列带来的问题
写缓冲器和无效化队列的引入带来了性能的提高,但同时又带来新的问题
首先一种最简单的,在单核情况下:
x的初始值为0,在多个核中共享
x = 2;
b = x + 1:
判断b == 3
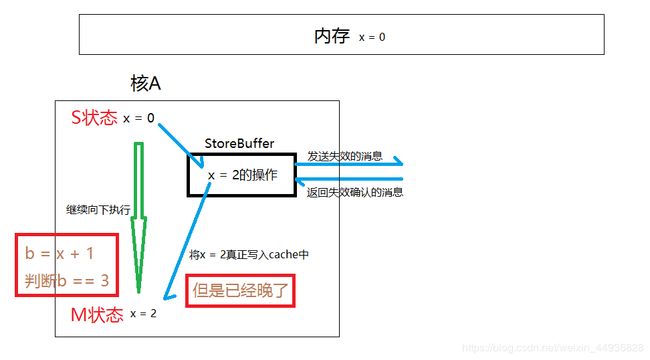
b=x+1,因为x已经在缓存中读到的为0,b为1,所以判断是false,,虽然后来Store Buffer后来将x的值刷新到了缓存中,但是已经晚了,所以为了避免这个问题,Store Buffer设计了一种策略叫做Store Forwarding。就是说核A在读取数据的时候会先看Store Buffer中的数据,如果Store Buffer中有数据,直接使用Store Buffer中的,从而避免使用错误数据。
在多核情况下:
核B在进行判断的时候发现在自己的缓存存在x=0,就直接+1进行了赋值判断,但此时核A刚刚将x=2的操作放到Store Buffer中,所以由于Store Buffer的存在导致多核下不能获取到最新值,所以产生了错误的结果。以下是图例分析:
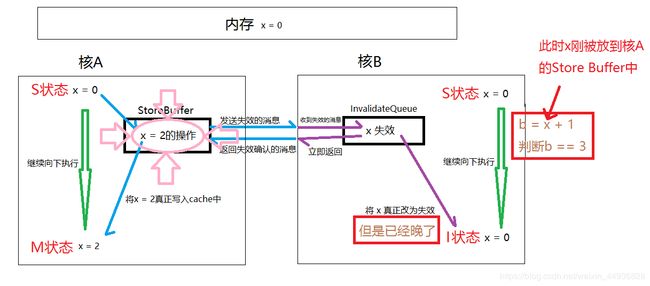
所以为了解决上面的问题出现了写屏障,写屏障的出现保证屏障两边写的执行是分开的,也就是说需要先将之前Store Buffer中的所有写指令都刷新到缓存之后,才执行后面的写指令。
具体实现方法是,先将屏障之前的Store Buffer中所有操作都刷新到缓存中,将屏障后的所有指令操作也同样放到Store Buffer中,不管后续的操作是什么都往里面放,这样可以提高CPU的执行效率,都通过Store Buffer刷新到了缓存中。
核B在进行判断的时候发现在自己的缓存存在x=0,就直接+1进行了赋值判断,但此时核B刚刚将x=2的操作放到Invalidate Queue中,所以由于Invalidate Queue的存在导致多核下不能获取到最新值,所以产生了错误的结果。以下是图例分析:
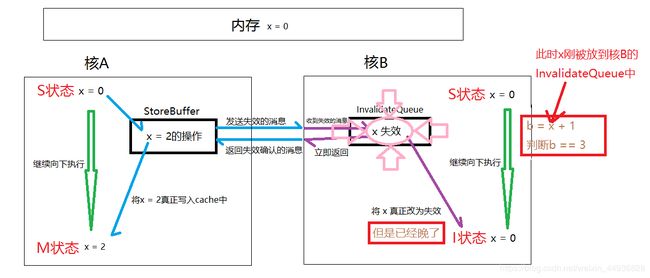
所以为了解决上面的问题出现了读屏障,读屏障的出现保证屏障两边读的执行是分开的,也就是说需要先将之前Invalidate Queue中的所有指令都失效之后,才执行后面的指令,保证下一次读取共享变量的时候读到的是最新的变量。
通过以上两个操作的结合使用可以保证在多核的情况下对共享变量的修改和读取都是一致的。
内存屏障(Memory Barrier)
通过上面对错误情况的分析可以知道,内存屏障的出现就是为了解决因为Store Buffer和Invalidate Queue所带来的数据可见性问题,也就是读和写不能实时更新到其他核的问题。内存屏障同时还具备强制将Store Buffer的内容刷到缓存中,强制将Invalidate Queue中的内容设置完毕的作用。
具体又分为写屏障和读屏障
写屏障(Store Memory Barrier):强制将Store Buffer中的内容写入到缓存中或者将该指令之后的写操作写入store buffer直到之前的内容被刷入到缓存中,也被称之为smp_wmb
读屏障(Load Memory Barrier):强制将Invalidate Queue中的内容处理完毕,也被称之为smp_rmb
读写屏障:兼备以上两个屏障的功能,也被称之为smp_mb
有序性
同时保证了在写屏障之前所有的写操作都已经完成,在读屏障之前所有的无效都已经设置完成,也就是说保证了程序执行的有序性,为什么这么说呢,因为本来在CPU执行指令的时候为了提高效率会将写的操作放入到Store Buffer中去,然后去执行其他操作,这时给我们的感觉就是CPU在执行其他操作,当Store Buffer中的操作异步收到其他核返回的信息后,才执行Store Buffer中的操作,这时执行顺序和本应该执行的顺序是相反的,这种现象就是指令乱序执行。而加上内存屏障之后保证异步中的操作执行完毕后才进行其他指令的执行,在现象上保证了指令执行的有序性。
与java的联系
上面讲了这么多底层的东西都是为了更好的去理解java中对于这种现象是如何进行封装的。
java为了封装CPU执行的复杂性,对内存屏障的操作进行了抽象来保证程序的正确性,但是并不代表实际CPU的执行,而是同样的效果。
LoadLoad Barriers
该屏障保证了在屏障前的读取操作效果先于屏障后的读取操作效果发生。在各个不同平台上会插入的编译指令不相同,可能的一种做法是插入也被称之为smp_rmb指令,强制处理完成当前的invalidate queue中的内容
StoreStore Barriers
该屏障保证了在屏障前的写操作效果先于屏障后的写操作效果发生。可能的做法是使用smp_wmb指令,而且是使用该指令中,将后续写入数据先写入到store buffer的那种处理方式。因为这种方式消耗比较小
LoadStore Barriers
该屏障保证了屏障前的读操作效果先于屏障后的写操作效果发生。
StoreLoad Barriers
该屏障保证了屏障前的写操作效果先于屏障后的读操作效果发生。该屏障兼具上面三者的功能,是开销最大的一种屏障。可能的做法就是插入一个smp_mb指令来完成。
与volatile的联系
java中对于内存屏障的使用最多的就是volatile关键字,那么到底是如何操作的呢:
在每个volatile写操作的前面插入一个StoreStore屏障,保证volatile写操作前面的Store Buffer队列中的操作都已经刷新到缓存中,防止前面的写操作与volatile写操作发生指令重排。
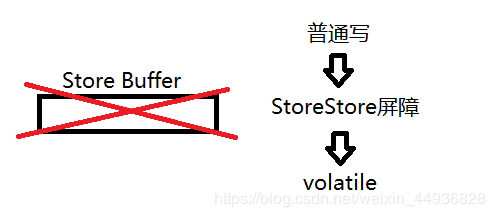
在每个volatile写操作的后面插入一个StoreLoad屏障,保证后面的其他写/读操作前面的Store Buffer队列中的操作都已经刷新到缓存中(也就是volatile写操作),防止后面的其他写/读操作与volatile写操作发生指令重排。
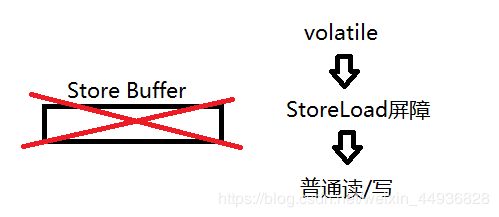
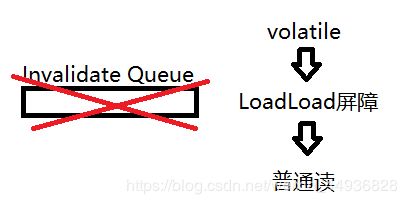
在每个volatile读操作的后面插入一个LoadLoad屏障,保证后面的其他读操作的无效化队列已经将volatile无效刷新到缓存中,防止后面的读操作与volatile读操作发生指令重排。
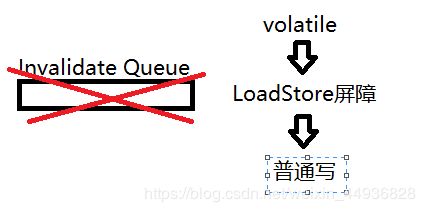
在每个volatile读操作的后面插入一个LoadStore屏障,保证后面的其他写操作的无效化队列已经将volatile无效刷新到缓存中,防止后面的写操作与volatile读操作发生指令重排。
通过对内存语义的封装实现了对volatile关键字读写时的顺序和可见。保证了我们所谓的多线程下的可见性。
最后
再说一下为什么volatile关键字不能保证多线程下修改数据的同步,因为同步除了有序和可见还需要满足原子性,也就是本次修改操作全部成功,举个例子,有两个人存钱同时往一个账号里面存钱(两个线程同时对一个变量进行增加操作),存钱分为几个步骤,先查询原来有多少钱,再在原来的基础上增加钱,最后将增加后的钱写回银行(就是CPU的核先将变量读入到自己的缓存中,再将自己缓存中的数据增加,最后将增加后的数据写回到主存中),假如第一个人先查到原来有50元(核A读到数据为50),就要在增加钱之前,第一个人有别的事情停下了(核A挂起保存挂起前的数据50,让出CPU执行权),这个时候第二个人查询原来有多少钱(核B读到数据为50),因为第一个人在增加之前去做别的事情了,所以查询还是50元,然后第二个人将查询出来的钱增加50元,变成了100元(核B增加数据为100),最后第二个人将100元写回银行(核B将内存最终值修改为100),第二个人的操作完成,这时第一个人别的事情忙完了开始执行原来的操作,因为之前在挂起的时候就是50元(核A读取到挂起前的缓存为50),所以会将当时读到的50元增加50元(将挂起前的数据增加50),后将这100元写回到银行(核A将内存最终值修改为100)。可以发现本来应该是150元的现在是100元,所以就丢了50元,这就是线程不安全。
因为即使是修改后可以让所有人可见,但是不能保证你读取到的就一定是最新的数据,就是读取和写入不是在一起的,所以volatile关键字不能保证线程安全。上图理解一下: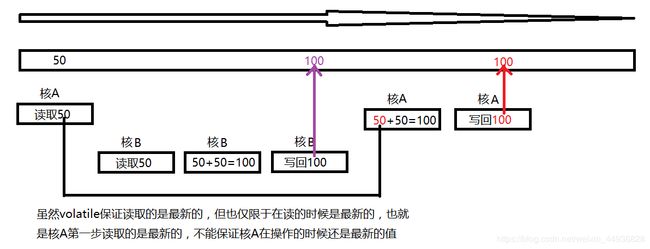
总结
通过对于硬件层的内存屏障理解,我们了解了内存屏障底层的实现原理,通过java中对volatile关键字的抽象操作,进一步理解了java对于内存的操作(屏蔽了各个平台的差异,一次编译到处运行的思想),使我们对volatile的可见性有了深刻的理解。