Hadoop 2.7.6集群部署
Hadoop 2.7.6集群部署 ——详细流程图解及命令实现
相关环境:
- CentOS 6.4 64
- jdk1.7.0_79
- VMware Tools
- Hadoop 2.7.6
部署文件网盘提取链接,提取码码在文章尾部
https://pan.baidu.com/s/1y-Q9JpHsZ_Rbq-Ig_z4yTw
一、安装VMware Tools
1.下载VMware Tools及解压安装

虚拟机–>安装VMware Tools
2.双击打开系统下载好的VMware Tools,将其里面的VMwareTools-10.3.10-13959562.tar.gz文件放出至桌面

3. 打开终端进入root用户将压缩包解压
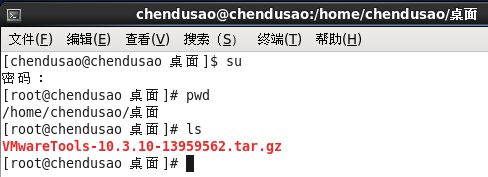
tar -zxvf VMwareTools-10.3.10-13959562.tar.gz
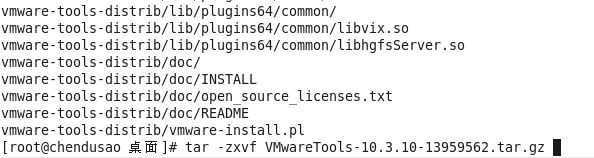
4. 得到vmware-tools-distrib文件夹,进入该文件夹,执行vmware-install.pl文件(文件名前加“./”)
![]()

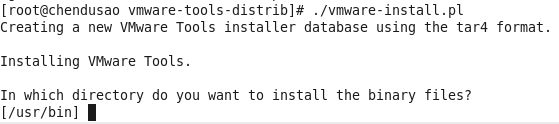
一路回车到底
5.成功安装VMware Tools(响应过慢无法共享文件重启客户机即可)
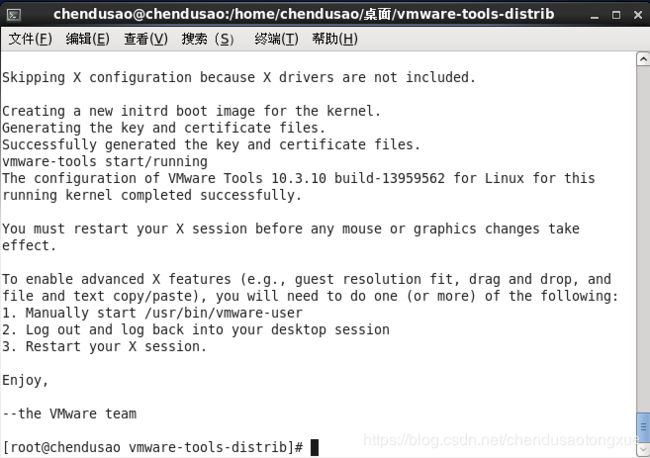
——————————————————————————————————————2020.6.17
二、网络配置
(一)、创建网卡
1.新建VPN
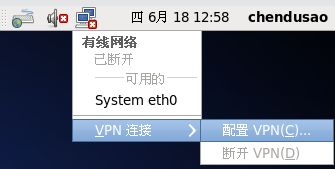
小电脑—>VPN连接—>配置VPN
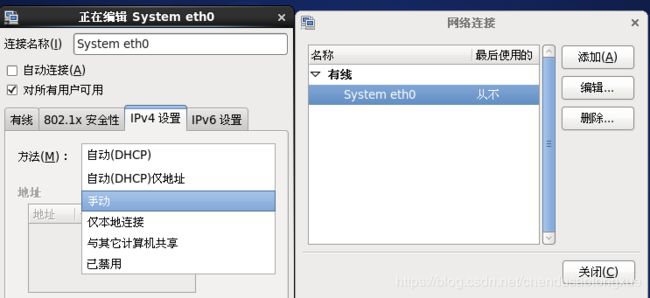 编辑—>IPV4设置—>手动
编辑—>IPV4设置—>手动
2.添加→地址、子网掩码、网关、DNS服务器(用自己的物理机网段、连接名我这设置为eth0)→应用

3. 将虚拟机网络连接设置为桥接模式

4. 解决mac地址冲突
vim /etc/udev/rules.d/70-persistent-net.rules
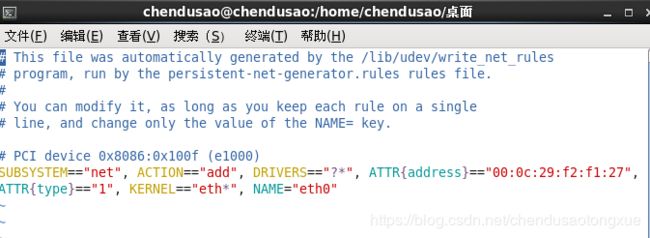
把网卡的名字改成“eth0”,并记录下mac地址
vim /etc/sysconfig/network-scripts/ifcfg-eth0
5.进入配置将HWADDR更改为刚记录的mac地址
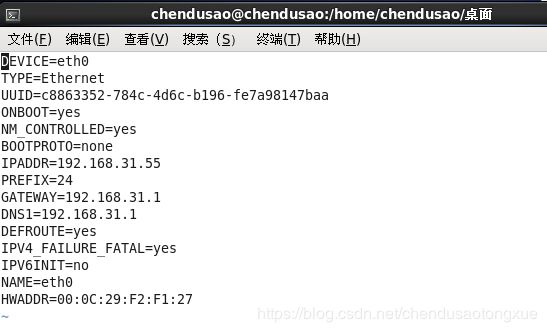
service network restart
6.重启网络服务

7. 关闭防火墙
service iptables stop
service iptables status

8. 验证是否可以进入网络和相同网段的地址
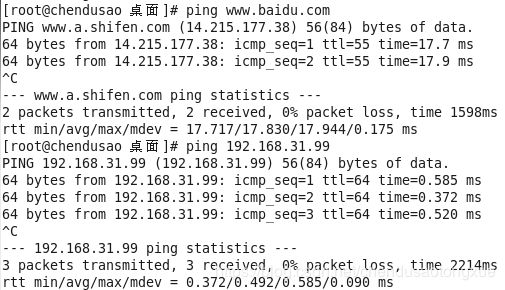
(二)、配置主机名及域名映射
1.进入network文件,将HOSTNAME修改为自己的主机名
vim /etc/sysconfig/network

2.修改域名映射,添加主节点的和子节点的映射(主与子都需配置相同)
vim /etc/hosts

三、安装JDK及配置环境变量
(一)、安装JDK
1.将jdk1.7.0_79文件放到桌面。

rpm -qa|grep java
rpm -e --nodeps java-1.6.0-openjdk-1.6.0.0-1.50.1.11.5.el6_3.x86_64
rpm -e --nodeps java-1.7.0-openjdk-1.7.0.9-2.3.4.1.el6_3.x86_64
2.查看系统自带的jkd,将其删掉。

3. 安装jdk。
rpm -ivh jdk-7.79-linux-x64.rpm

4.完成Jdk安装,默认路径在usr/java路径中。
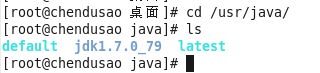
(二)、配置环境变量
1.编辑profile文件,保存并生效文件。
vim /etc/profile
export JAVA_HOME=/usr/java/jdk1.7.0_79
export PATH=$PATH:$JAVA_HOME/bin
source /etc/profile

2.查看到当前的jdk

四、安装Hadoop及配置环境变量。
(一)、安装Haddop
1.将hadoop-2.7.6.tar.gz放至桌面。

2. 将压缩包解压至你喜欢的目录
tar -zxvf hadoop-2.7.6.tar.gz -C /home/chendusao/

3. 复制当前Hadoop路径备用
![]()
4. 编辑profile文件添加Hadoop信息,保存退出并生效。
vim /etc/profile
export HADOOP_HOME=/home/chendusao/hadoop-2.7.6
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
source /etc/profile
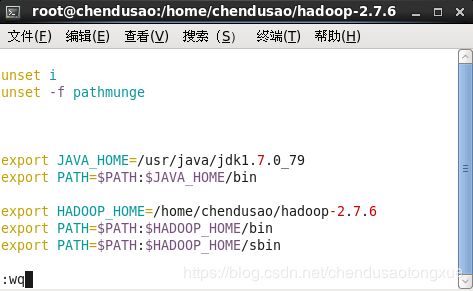
5. 生效激活检查

(二)、配置Hadoop目录下的相关文件
进到hadoop目录下配置几个主要文件
cd /home/chendusao/hadoop-2.7.6/etc/hadoop
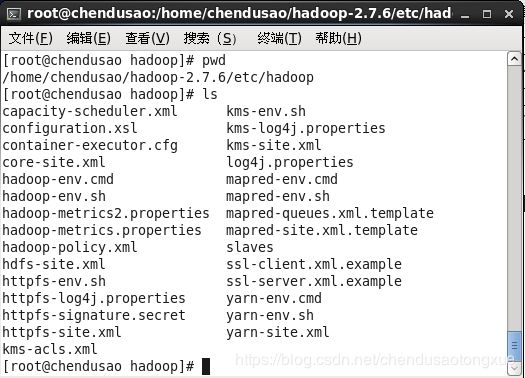
1.hadoop-env.sh
export JAVA_HOME=/usr/java/jdk1.7.0_79
将JAVA_HOME设置为刚安装JDK的路径。

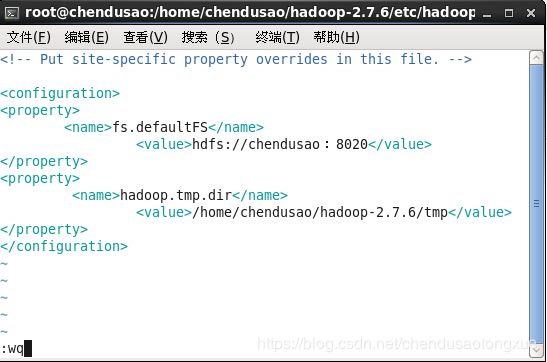
2. Core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://chendusao:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/chendusao/hadoop-2.7.6/tmp</value>
</property>
将内容追加到标签内,chendusao为主节点主机名。
3. yarn-site.xml
<property>
<name>yarn.resourcemanager.hostname</name>
<value>chendusao</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
进入yarn-site.xml,将内容追加到标签内,chendusao为自己主机名。

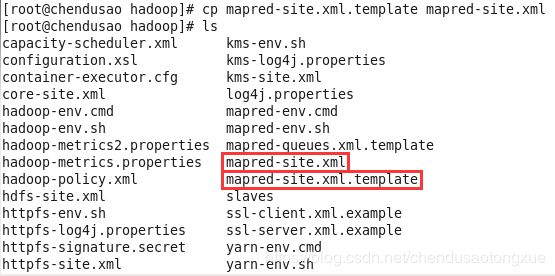
4. Mapred-site.xml
cp mapred-site.xml.template mapred-site.xml
复制mapred-queues.xml.template文件将其后缀template去除,生成一份mapred-queues.xml文件
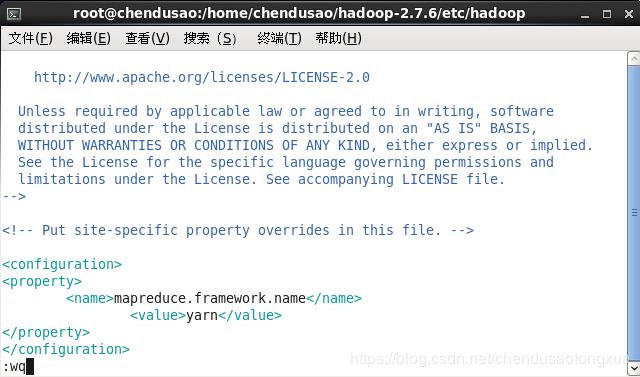
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
进入mapred-queues.xml,将内容追加到标签内。
五、启动主服务
(一)、启动Hadoop
1.进入hadoop下的bin目录
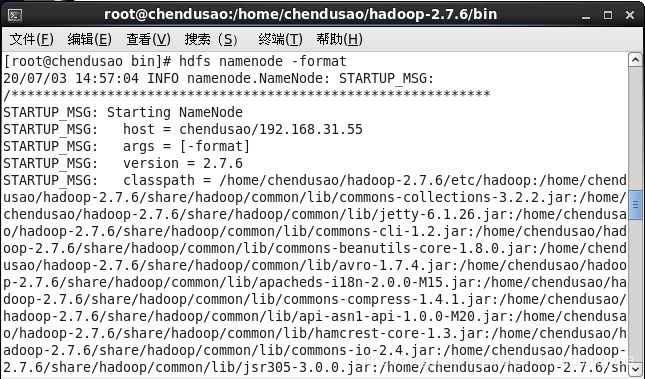
cd /home/chendusao/hadoop-2.7.6/bin

2. 格式化主节点命名空间
hdfs namenode -format
3. 进入hadoop下sbin目录,启动存储主服务
cd /home/chendusao/hadoop-2.7.6/sbin
hadoop-daemon.sh start namenode

4. 启动资源管理主服务。
yarn-daemon.sh start resourcemanager

5. 启动存储从服务,并查看进程。
hadoop-daemon.sh start datanode

(二)、查看服务
(1)查看存储服务
1.打开默认浏览器Firefox
2. 在地址栏中输入“主节点地址:50070”,在Web的界面可以看到HDFS相关信息。

3. 进入Datendoes可以看到主节点相关存储服务。


(2)查看资源管理服务
1.在地址栏中输入“主节点地址:8088”,在Web的界面可以看到Yarn相关信息。
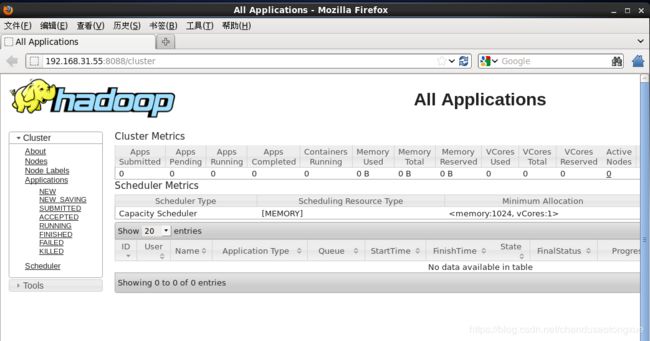
六、启动从服务
新建虚拟机与上述配置步骤相同,参考到四(一)。主节点和子节点域名映射要添加相同的地址和主机名,前面几个需要追加的文件主机名均改为主节点的主机名。以下用相同配置主机名为“chendusao2”的子节点。
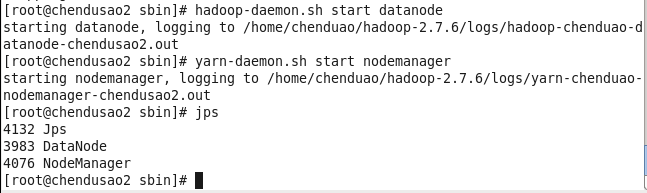
1.进入hadoop的sbin目录,启动存储从服务和资源管理从服务,连接到主节点。并查看进程。
cd /home/chendusao2/hadoop-2.7.6/sbin
hadoop-daemon.sh start datanode
yarn-daemon.sh start nodemanager
2. 打开默认浏览器Firefox
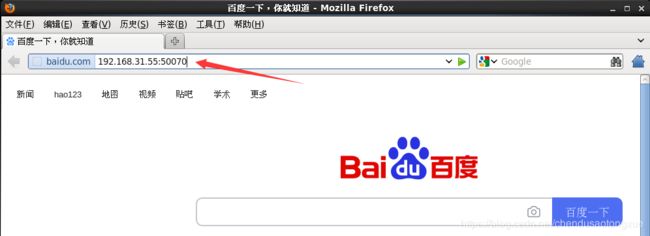
3. 在地址栏中输入“主节点地址:50070”,在Web的界面可以看到HDFS相关信息。
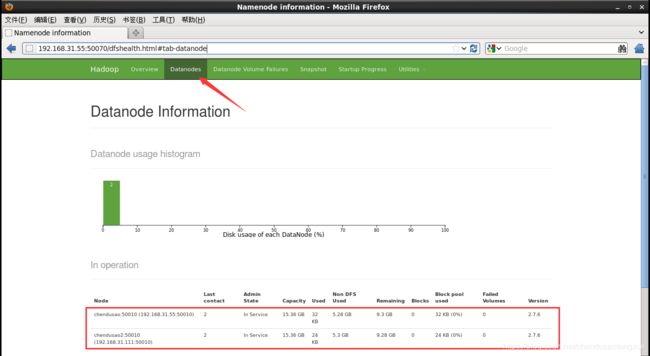
4. 进入Datendoes可以看到主节点和子节点的相关存储服务
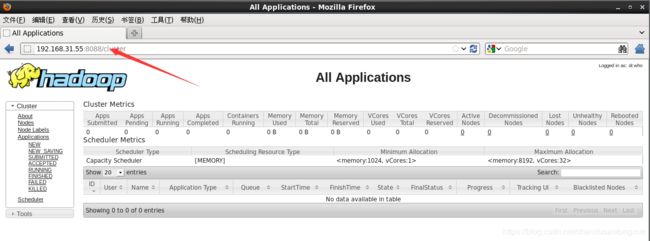
 5. 在地址栏中输入“主节点地址:8088”,在Web的界面可以看到Yarn相关信息。
5. 在地址栏中输入“主节点地址:8088”,在Web的界面可以看到Yarn相关信息。
相关部署文件提取码: cfx9