【Hadoop集群搭建】Hadoop运行环境配置——虚拟机准备(CentOS 8)
主要步骤:
1.修改静态IP
2.修改主机名称
3.关闭防火墙
4.创建具有root权限的普通用户
5.安装jdk和hadoop
6.关机快照克隆并配置克隆虚拟机事先准备
VMware Workstation Pro 15(可变)
CentOS 8 64位(可变,但使用别的linux版本后续操作会有几处不同)
Xshell 6(终端模拟软件,比起直接操作虚拟机终端方便很多,具体安装和连接方法可上网学习)
1.改一下静态IP
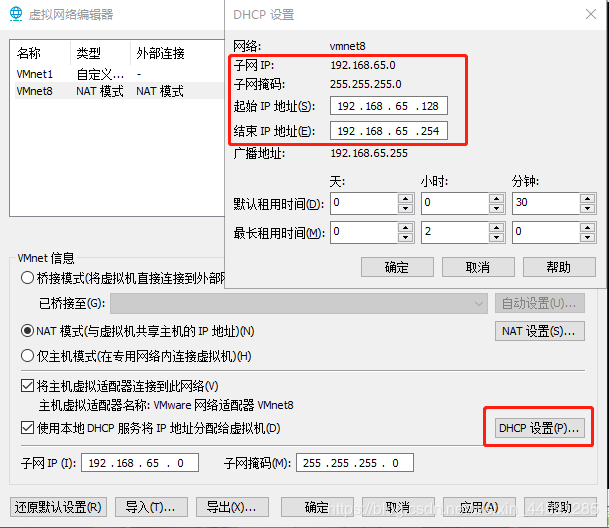
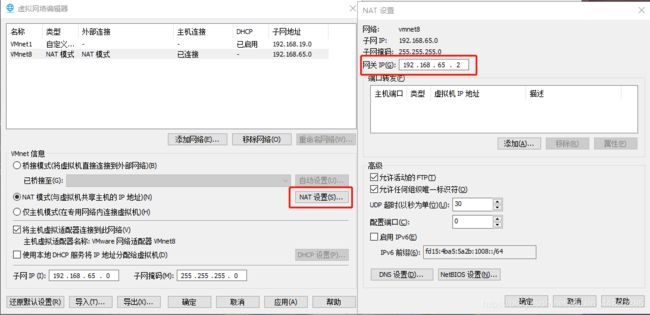
首先在VM工具栏打开“编辑—虚拟网络编辑器”,选择VMnet8,分别打开DHCP设置/NAT设置,记住IP地址范围 / 子网IP / 子网掩码 / 网关IP。
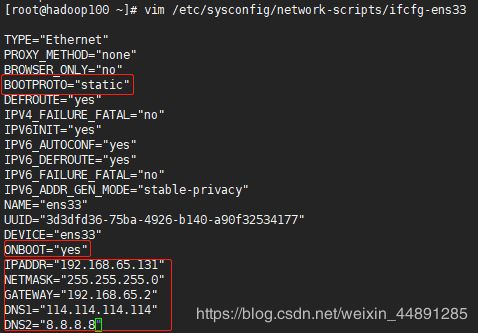
建议root用户登陆,编辑网络配置文件(不同版本CentOS这里的网络配置文件名称有所不同)
vim /etc/sysconfig/network-scripts/ifcfg-ens33
将BOOTPROTO从“dhcp”(动态ip)改为“static”(静态ip)
ONBOOT设置为“yes”(在系统启动时激活网卡)
然后依次添加的是IP地址/子网掩码/网关IP/DNS1和DNS2,其中IP地址网段必须与上面的一致,并处于范围内,这里设为192.168.65.131,子网掩码/网关IP与上面一致,主备用DNS可自行决定。
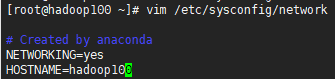
2.再改一下主机名
vim /etc/sysconfig/network
这里设置HOSTNAME为hadoop100
vim /etc/hosts
这里是集群机器主机名和IP地址的映射,规划好所有集群机器的IP地址,这里我就规划四台机器,按顺序规划主机名和对应IP地址。
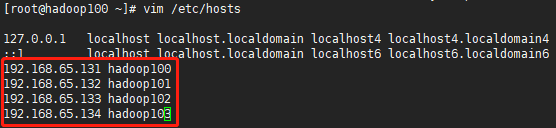
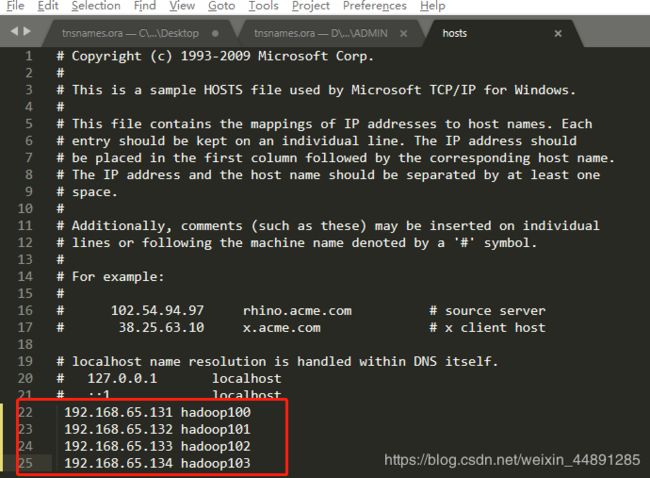
同时也要修改Windows下的hosts文件(C:\Windows\System32\drivers\etc下),添加相同主机名-IP映射。
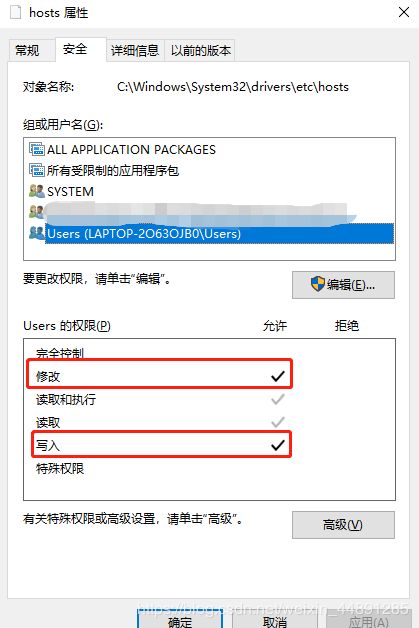
ps:如果没有保存修改权限可以修改文件属性-安全,为Users添加相应权限(如下)。
全部完成后我们重启网络服务以使配置生效。
(CentOS 7的重启网络服务命令是systemctl start network.service或者service network restart)
nmcli c reload
当然,个人经验是好像没啥用,不如reboot一下来的简单粗暴>_<。
那么我们重启机器后查看主机名:
hostname
发现是hadoop100,很好,如果还有问题使用命令hostnamectl set-hostname hadoop100并再次重启。
![]()
至此我们的网络就配置好了。(不难吧,就是烦了点,已经好了一半了,奥里给!)
3.关一下防火墙
此步骤一定要在root用户进行。
首先查看防火墙状态
systemctl status firewalld
我这里已经关闭过了,如果是active就意味着防火墙打开。

以下命令关闭防火墙
systemctl stop firewalld #停止firewall
systemctl disable firewalld.service #禁止firewall开机启动
也可以执行 vim /etc/selinux/config修改参数SELINUX=disabled来禁止开机启动。
ping一下
我们在hadoop100上ping3次外网,ping3次主机,如下说明网络配置好了
ps:如果不加次数会一直ping下去,可使ctrl+c停止命令。
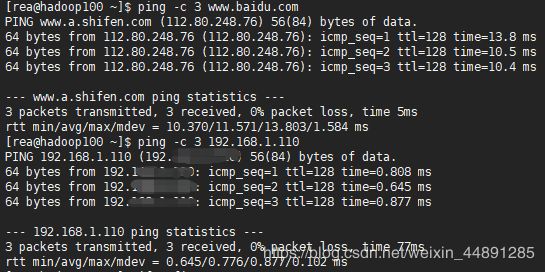
再在主机上ping一下hadoop100,无丢包现象。
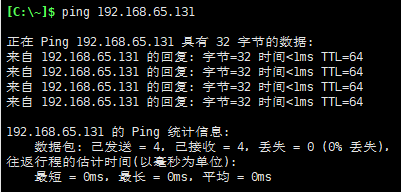
这样我们的网络配置就没问题啦。
4.建一个普通用户并使其具有root权限
由于日常使用中往往使用普通用户而非root用户(当然个人觉得root用户往往比较方便权限比较大,但是一般情况下都不推荐使用root,最好单独建立一个普通的用户。因为root用户有等同于操作系统的权限,假设你不小心误操作或黑客黑进来rm -rf一下你的系统就完喽)那有root权限的普通用户和root用户有区别吗?懂的小伙伴答一下~~
创建并进入一个普通用户,添加用户到root权限组
vim /etc/sudoers
添加这么一行命令,最前面是你的用户名

5.装个JDK和Hadoop
首先rpm -qa | grep java查看是否有已安装的jdk,如果发现jdk版本低于1.7或是系统自带的openjdk需要sudo rpm -e 软件包卸载。
我下载的jdk1.8和Hadoop2.7.2,Hadoop我不知道,jdk1.8我是真的觉得这个版本比较稳定,在其他项目中我使用过最新版本的jdk13会遇到问题,1.8就没问题,推荐!(当然我们也要了解最新版本的新特性)Hadoop已经出到了3点几,这里也是使用比较稳定的版本。
我在根目录下的opt目录创建一个module文件夹,用于存放解压后Hadoop,jdk则存放在了之前的项目创建的/usr/java下,大家可以自行选择路径,只要便于管理就行。(下载解压过程就不多说了)
下面来配置二者的环境变量。
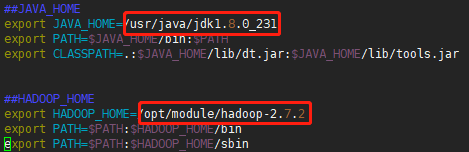
vim /etc/profile打开配置文件,在文件末尾添加如下语句,红框处改为你本机的jdk和hadoop的安装路径。
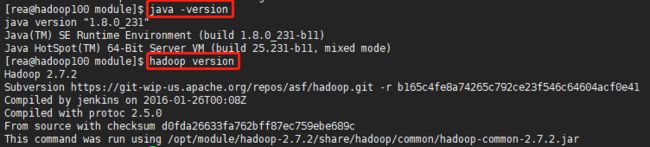
终端输入命令java -version和hadoop version出现以下内容则说明配置成功。
6. 关机-快照-克隆-配置
如题,快照是用于保存虚拟机现在的状态,崩溃后便于恢复,也可略过。按照上面的规划,我克隆了3台,分别命名为hadoop101 / hadoop102 / hadoop103,每台克隆虚拟机需要
- 按照之前的主机名-IP映射规划修改**/etc/sysconfig/network-scripts/ifcfg-ens33**(不同版本系统文件名可能不同)中的IP地址;
- 更改相应的主机名;
- 检查防火墙是否关闭,并重启网络服务或重启虚拟机使其生效。
你也可以每台虚拟机都互ping一下,保证集群间的通信。
**
至此我们的Hadoop运行环境配置之虚拟机准备篇就完成啦!
希望能帮到大家>_<
下一篇我们会进入下一大板块:Hadoop运行模式学习,并先了解三大模式之本地模式,传送门:【Hadoop集群搭建】Hadoop运行模式——本地模式(附Hadoop目录结构了解)
**