Java编程思想第四版学习总结
Java编程思想第四版学习总结
文章目录
- Java编程思想第四版学习总结
- 第 1 章 对象入门
- 1.1 抽象的进步
- 1.2 对象的接口
- 1.3 实现方案的隐藏
- 1.4 方案的重复使用
- 1.5 继承:重新使用接口
- 1.5.1 改善基础类
- 1.5.2 等价于类似关系
- 1.6 多形对象的互换使用
- 1.6.1 动态绑定
- 1.6.2 抽象的基础类和接口
- 1.7 对象的创建和存在时间
- 1.7.1 集合与继承器
- 1.7.2 单根结构
- 1.7.3 集合库与方便使用集合
- 1.7.4 清除时的困境:由谁负责清除?
- 1.8 违例控制:解决错误
- 1.9 多线程
- 1.10 永久性
- 1.11 Java 和因特网
- 1.12 分析和设计
- 1.12.1 不要迷失
- 1.12.2 阶段 0:拟出一个计划
- 1.12.3 阶段 1:要制作什么
- 1.12.4 阶段 2:如何构建
- 1.12.5 阶段 3:开始创建
- 1.12.6 阶段 4:校订
- 1.12.7 计划的回报
- 1.13 Java 还是 C++ ?
- 第 2 章 一切都是对象
- 2.1 用句柄操作对象
- 2.2 所有对象都必须创建
- 2.2.1 保存到什么地方
- 2.2.2 特殊情况:主要类型
- 2.2.3 Java 的数组
- 2.3 绝对不要清除对象
- 2.3.1 作用域
- 2.3.2 对象的作用域
- 2.4 新建数据类型:类
- 2.4.1 字段和方法
- 2.5 方法、自变量和返回值
- 2.5.1 自变量列表
- 2.6 构建 Java 程序
- 2.6.1 名字的可见性
- 2.6.2 使用其他组件
- 2.6.3 static 关键字
- 2.7 我们的第一个Java程序
- 2.8 注释和嵌入文档
- 2.8.1 注释文档
- 2.8.2 具体语法
- 2.8.3 嵌入HTML
- 2.8.4 @see:引用其他类
- 2.8.5 类文档标记
- 2.8.6 变量文档标记
- 2.8.7 文档方法标记
- 2.8.8 文档示例
- 2.9 编码样式
- 第 3 章 控制程序流程
- 3.1 使用 Java 运算符
- 3.1.1 优先级
- 3.1.2 赋值
- 3.1.3 算数运算符
- 3.1.4 自动递增和递减
- 3.1.5 关系运算符
- 3.1.6 逻辑运算符
- 3.1.7 按位运算符
- 3.1.8 移位运算符
- 3.1.9 三元if-else运算符
- 3.1.10 逗号运算符
- 3.1.11 字串运算符
- 3.1.12 运算符常规操作规则
- 3.1.13 造型运算符
- 3.2 执行控制
- 3.2.1 真和假
- 3.2.2 if-else
- 3.2.3 反复
- 3.2.4 do-while
- 3.2.5 for
- 3.2.6 中断和继续
- 3.2.7 开关
- 第 4 章 初始化和清除
- 4.1 用构建器自动初始化
- 4.2 方法过载(Overlode)
- 4.2.1 区分过载方法
- 4.2.2 主类型的过载
- 4.2.3 返回值过载
- 4.2.4 默认构建器
- 4.2.5 this 关键字
- 1.在构建器里调用构建器
- 2.static的含义
- 4.3 清除:收尾和垃圾收集
- 4.3.1 finalize() 用途何在
- 4.3.2 必须执行清除
- 4.4 成员初始化
- 4.4.1 规定初始化
- 4.4.2 构建器初始化
- 1.初始化顺序
- 2.静态数据的初始化
- 4.5 数组初始化
- 第 5 章 隐藏实施过程
- 5.1 包:库单元
- 5.1.1 创建独一无二的包名
- 5.1.2 自定义工具库
- 5.1.3 利用导入改变行为
- 5.1.4 包的停用
- 5.2 Java 访问指示符
- 5.2.1 “友好的”
- 5.2.2 public:接口访问
- 5.2.3 private:不能接触
- 5.2.4 protected:“友好的一种”
- 5.3 接口与实现
- 5.4 类访问
- 第 6 章 类再生
- 6.1 合成的语法
- 6.2 继承的语法
- 6.2.1 初始化基类
- 6.3 合成与继承的结合
- 6.3.1 确保正确的清除
- 6.3.2 名字的隐藏
- 6.4 到底选择合成还是继承
- 6.5 protected
- 6.6 积累开发
- 6.7 上溯造型
- 6.7.1 何谓“上溯造型”?
- 6.8 final 关键字
- 6.8.1 final 数据
- 6.8.2 final 方法
- 6.8.3 final 类
- 6.8.4 final 的注意事项
- 6.9 初始化和类装载
- 6.9.1 继承初始化
- 第 7 章 多形性
- 7.1 上溯造型
- 7.1.1 为什么要上溯造型
- 7.2 深入理解
- 7.2.1 方法调用的绑定
- 7.2.2 产生正确的行为
- 7.2.3 扩展性
- 7.3 覆盖与过载
- 7.4 抽象类和方法
- 7.5 接口
- 7.5.1 Java 的"多重继承"
- 7.5.2 通过继承扩展接口
- 7.5.3 常数分组
- 7.5.4 初始化接口中的字段
- 7.6内部类
- 7.6.1 内部类和上溯造型
- 7.6.2 方法和作用域中的内部类
- 7.6.3链接到外部类
- 7.6.4 static 内部类
- 7.6.5 引用外部类对象
- 7.6.6 从内部类继承
- 7.6.7 内部类可以被覆盖吗?
- 7.6.8 内部类标识符
- 7.6.9 为什么要用内部类:控制框架
- 7.7 构建器和多形性
- 7.7.1 构建器的调用顺序
- 7.7.2 继承和 finalize()
- 7.7.3 构建器内部的多形性方法的行为
- 7.8 通过继承进行设计
- 7.8.1 纯继承与扩展
- 7.8.2 下溯造型与运行期类型标识
- 第 8 章 对象的容纳
- 8.1 数组
- 8.1.1 数组和第一类对象
- 8.1.2 数组的返回
- 8.2 集合
- 8.2.1 缺点:类型未知
- 8.3 枚举器(反复器)
- 8.4 集合的类型
- 8.4.1 Vector
- 8.4.2 BitSet
- 8.4.3 Stack
- 8.4.4 Hashtable
- 8.4.5 再论枚举器
- 8.5 排序
- 8.6 通用集合库
- 8.7 新集合
- 8.7.1 使用Collection
- Collection和Collections的区别:
- 8.7.2 使用 Lists
- List 常用方法
- ArrayList 基本操作
- LinkedList 基本操作
- 8.7.3 使用Sets
- 常见的方法:
- HashSet
- TreeSet
- LinkedHashSet
- 8.7.4 使用Maps
- Map基本操作:
- HashMap
- TreeMap
- HashTable
- LinkedHashMap
- 8.7.5 决定实施方案
- 8.7.6 未支持的操作
- 8.7.7 排序和搜索
- 8.7.8 实用工具
- 第 9 章 违例差错控制
- 9.1 基本违例
- 9.1.1 违例自变量
- 9.2 违例的捕获
- 9.2.1 try 块
- 9.2.2 违例控制器
- 9.2.3 违例规范
- 9.2.4 捕获所有违例
- 9.2.5 重新“掷”出违例
- 9.3 标准 Java 违例
- 9.3.1 RuntimeException 的特殊情况
- 9.4 创建自己的违例
- 9.5 违例的限制
- 9.6 用 finally 清除
- 9.6.1 用 finally 做什么
- 9.6.2 缺点:丢失的违例
- 9.7 构建器
- 9.8 违例匹配
- 9.8.1 违例准则
- 9.9 总结
- 第 10 章 Java IO 系统
- 10.1 文件和目录路径
- 10.2 选取路径部分片段
- 10.3 路径分析
- 10.4 Paths的增减修改
- 10.5 目录
- 10.6 文件系统
- 10.7 路径监听
- 10.8 文件查找
- 10.9 文件读写
- 10.10 本章小结
- 第 11 章 运行期类型鉴定
- 11.1 对 RTTI 的需要
- 11.1.1 Class 对象
- 11.1.2 造型前的检查
- 11.2 RTTI 语法
- 11.3 反射:运行期类信息
- 11.3.1 一个类方法提取器
- 第 12 章 传递和返回对象
- 12.1 传递句柄
- 12.1.1 别名问题
- 12.2 制作本地副本
- 12.2.1 按值传递
- 12.2.2 克隆对象
- 12.2.3 使类具有克隆能力
- 12.2.4 成功的克隆
- 12.2.5 Object.clone() 的效果
- 12.2.6 克隆合成对象
- 12.2.7 用 Vector 进行深层复制
- 12.2.8 通过序列化进行深层复制
- 12.2.9 使克隆具有更大的深度
- 12.2.10 为什么有这个奇怪的设计
- 12.3 克隆的控制
- 12.3.1 副本构建器
- 12.4 只读类
- 12.4.1 创建只读类
- 12.4.2 “一成不变”的弊端
- 12.4.3 不变字串
- 12.4.4 String、StringBuffer 和 StringBuilder 类
- StringBuffer 方法:
第 1 章 对象入门
面向对象与面向过程优缺点:
面向过程
- 优点:性能比面向对象高,因为类调用时需要实例化,开销比较大,比较消耗资源。比如单片机、嵌入式开发、Linux/Unix等一般采用面向过程开发,性能是最重要的因素。
- 缺点:没有面向对象易维护、易复用、易扩展
面向对象
- 优点:易维护、易复用、易扩展,由于面向对象有封装、继承、多态性的特性,可以设计出低耦合的系统,使系统更加灵活、更加易于维护
- 缺点:性能比面向过程低
面向对象程序设计的一些显著的特性包括:
程序设计的重点在于数据而不是过程;
程序被划分为所谓的对象;
数据结构为表现对象的特性而设计;
函数作为对某个对象数据的操作,与数据结构紧密的结合在一起;
数据被隐藏起来,不能为外部函数访问;
对象之间可以通过函数沟通;
新的数据和函数可以在需要的时候轻而易举的添加进来;
在程序设计过程中遵循由下至上(bottom-up)的设计方法。
1.1 抽象的进步
所有编程语言的最终目的都是提供一种“抽象”方法。
当父类知道子类应该包含什么样的方法,但无法确定子类如何实现这些方法;在分析事物时,会发现事物的共性,将共性抽取出,实现的时候,就会有这样的情况:方法功能声明相同,但方法功能主体不同,这时,将方法声明抽取出,那么,此方法就是一个抽象方法。
Alan Kay 总结了Smalltalk 的五大基本特征。这是第一种成功的面向对象程序设计语言,也是Java 的基础语言。通过这些特征,我们可理解“纯粹”的面向对象程序设计方法是什么样的:
(1) 所有东西都是对象。可将对象想象成一种新型变量;它保存着数据,但可要求它对自身进行操作。理论上讲,可从要解决的问题身上提出所有概念性的组件,然后在程序中将其表达为一个对象。
(2) 程序是一大堆对象的组合;通过消息传递,各对象知道自己该做些什么。为了向对象发出请求,需向那个对象“发送一条消息”。更具体地讲,可将消息想象为一个调用请求,它调用的是从属于目标对象的一个子例程或函数。
(3) 每个对象都有自己的存储空间,可容纳其他对象。或者说,通过封装现有对象,可制作出新型对象。所以,尽管对象的概念非常简单,但在程序中却可达到任意高的复杂程度。
(4) 每个对象都有一种类型。根据语法,每个对象都是某个“类”的一个“实例”。其中,“类”(Class)是“类型”(Type)的同义词。一个类最重要的特征就是“能将什么消息发给它?”。
(5) 同一类所有对象都能接收相同的消息。这实际是别有含义的一种说法,大家不久便能理解。由于类型为
“圆”(Circle)的一个对象也属于类型为“形状”(Shape)的一个对象,所以一个圆完全能接收形状消息。这意味着可让程序代码统一指挥“形状”,令其自动控制所有符合“形状”描述的对象,其中自然包括“圆”。这一特性称为对象的“可替换性”,是OOP 最重要的概念之一。
1.2 对象的接口
接口
是Java语言中一种引用类型,是方法的集合,如果说类的内部封装了成员变量、构造方法和成员方法,那么接口的内部主要就是封装了方法,包含抽象方法(JDK 7及以前),默认方法和静态方法(JDK 8),私有方法(JDK 9)。
接口的定义:
它与定义类方式相似,但是使用 interface 关键字。它也会被编译成.class文件,但一定要明确它并不是类,而是另外一种引用数据类型。
接口的特点:
- 接口就是一种引用数据类型
- 接口中只能定义常量和方法(抽象方法,静态方法,默认方法,私有方法)
- 接口不能定义成员变量和构造方法
- 接口不能创建对象,只能通过其实现类来使用
如何利用对象完成真正有用的工作呢?必须有一种办法能向对象发出请求,令其做一些实际的事情,比如完成一次交易、在屏幕上画一些东西或者打开一个开关等等。每个对象仅能接受特定的请求。我们向对象发出的请求是通过它的“接口”(Interface)定义的,对象的“类型”或“类”则规定了它的接口形式。“类型”与“接口”的等价或对应关系是面向对象程序设计的基础。
1.3 实现方案的隐藏
封装的定义:
隐藏对象内部的复杂性,只对外提供简单的接口。便于外界的调用,从而提高系统的可扩展性,可维护性。
封装的特点:
-
属性都用private修饰,外界不能通过对象名.属性调用;
-
对外提供对属性的get/set方法,可以对属性进行调用和修改;
-
在set方法中可以增加逻辑判断,规范属性传入的标准化;
-
提高了数据的安全性。
若任何人都能使用一个类的所有成员,那么客户程序员可对那个类做任何事情,没有办法强制他们遵守任何约束。即便非常不愿客户程序员直接操作类内包含的一些成员,但倘若未进行访问控制,就没有办法阻止这
一情况的发生——所有东西都会暴露无遗。有两方面的原因促使我们控制对成员的访问。第一个原因是防止程序员接触他们不该接触的东西——通常是内部数据类型的设计思想。若只是为了解决特定的问题,用户只需操作接口即可,毋需明白这些信息。我们向用户提供的实际是一种服务,因为他们很容易就可看出哪些对自己非常重要,以及哪些可忽略不计。
Java 采用三个显式(明确)关键字以及一个隐式(暗示)关键字来设置类边界:public,private,protected 以及暗示性的friendly(default)。
类的访问范围:
- public修饰类,表示该类在所有包中可见
- (default)修饰类,表示该类仅在同一个包中可见
- 不能用protected和private修饰类
成员变量及成员方法的访问范围
- public 包内、包外,所有类中可见
- protected 包内所有类可见,包外有继承关系的子类可见(子类对象可调用)
- (default)表示默认,不仅本类访问,而且是同包可见。
- private 仅在同一类中可见
1.4 方案的重复使用
为重复使用一个类,最简单的办法是仅直接使用那个类的对象。但同时也能将那个类的一个对象置入一个新类。我们把这叫作“创建一个成员对象”。新类可由任意数量和类型的其他对象构成。无论如何,只要新类达到了设计要求即可。这个概念叫作“组织”——在现有类的基础上组织一个新类。有时,我们也将组织称作“包含”关系。新类的“成员对象”通常设为“私有”(Private),使用这个类的客户程序员不能访问它们。这样一来,我们可在不干扰客户代码的前提下,从容地修改那些成员。也可以在“运行期”更改成员,这进一步增大了灵活性。
1.5 继承:重新使用接口
继承的格式:
- 通过extends关键字可以实现类与类的继承
- class 子类类名 extends 父类类名 {}
- 被继承的这个类称为父类,基类或者超类
- 继承的这个类称为子类或者派生类。
类与类之间有两种格式
一种是(is a)属于继承;
另一种是(has a)属于组合。
继承的特点:
- 通过extends关键字,实现了继承之后,让类与类之间产生了关系。
- 继承的本质就是抽取共性代码,多个重复代码的向上抽取,简化代码。
- 类是对一批对象的抽象,继承是对一批类的抽象。
- 父类又被称为超类,或者基类,子类又被称为派生类。
- Java是面向对象语言,万事万物皆是对象,为了满足这个设计原则,所有的类都直接或者间接继承自Object类。
继承的优缺点
优点:
- 简化了代码
- 提高了扩展性
- 提高了可维护性
缺点:
造成了耦合性过高,牵一发动全身
编写Java程序时一般要满足开闭原则。即:对扩展开放,对修改关闭;
高内聚,低耦合: 类与类之间,功能与功能之间,模块与模块之间,功能尽量内聚,不同模块之间,尽量独立。
*继承的注意点
- 单一继承性。(在Java中是不支持多继承的,通俗的说子类只能有一个父类,而父类可以有很多子类。)
- 支持多层继承。(继承可以一直传下去,子类有父类,父类又有父类…)
- 如果父类成员使用private修饰,那么子类不能被继承。(private只是对本类有效)
- 如果一个子类继承了父类的属性和方法还可以有自己特有的属性和方法。(不光有父类的属性(可继承的)和方法(可继承的),也有自己独有的属性和方法。)
- 当子类和父类的成员变量重名的时候,子类优先。(就近原则)
若能利用现成的数据类型,对其进行“克隆”,再根据情况进行添加和修改,令其实现大致相同的功能,情况就显得理想多了。“继承”正是针对这个目标而设计的。但继承并不完全等价于克隆。在继承过程中,若原始类(正式名称叫作基础类、超类或父类)发生了变化,修改过的“克隆”类(正式名称叫作继承类或者子类)也会反映出这种变化。在Java 语言中,继承是通过extends 关键字实现的。
使用继承时,相当于创建了一个新类。这个新类不仅包含了现有类型的所有成员(尽管private 成员被隐藏起来,且不能访问),但更重要的是,它复制了基础类的接口。也就是说,可向基础类的对象发送的所有消息亦可原样发给衍生类的对象。根据可以发送的消息,我们能知道类的类型。这意味着衍生类具有与基础类相同的类型!为真正理解面向对象程序设计的含义,首先必须认识到这种类型的等价关系。
由于基础类和衍生类具有相同的接口,所以那个接口必须进行特殊的设计。也就是说,对象接收到一条特定的消息后,必须有一个“方法”能够执行。若只是简单地继承一个类,并不做其他任何事情,来自基础类接口的方法就会直接照搬到衍生类。这意味着衍生类的对象不仅有相同的类型,也有同样的行为,这一后果通常是我们不愿见到的。
1.5.1 改善基础类
尽管extends 关键字暗示着我们要为接口“扩展”新功能,但实情并非肯定如此。为区分我们的新类,第二个办法是改变基础类一个现有函数的行为。我们将其称作“改善”那个函数。
为改善一个函数,只需为衍生类的函数建立一个新定义即可。我们的目标是:“尽管使用的函数接口未变,但它的新版本具有不同的表现”。
1.5.2 等价于类似关系
我们完全能够将衍生类的一个对象换成基础类的一个对象!可将其想象成一种“纯替换”。在某种意义上,这是进行继承的一种理想方式。此时,我们通常认为基础类和衍生类之间存在一种“等价”关系。
许多时候,我们必须为衍生类型加入新的接口元素。所以不仅扩展了接口,也创建了一种新类型。这种新类型仍可替换成基础类型,但这种替换并不是完美的,因为不可在基础类里访问新函数。我们将其称作“类似”关系;新类型拥有旧类型的接口,但也包含了其他函数,所以不能说它们是完全等价的。
1.6 多形对象的互换使用
多态的定义:
多态的定义是指允许不同类的对象对同一消息做出响应。即同一消息可以根据发送对象的不同而采用多种不同的行为方式。
多态的优点:
提高了代码的维护性(继承保证),提高了代码的扩展性(由多态保证)。
多态必要条件
- 被动方必须有继承关系;
- 子类一般都要重写父类方法;
- 父类引用指向子类对象。
多态的定义格式:(存在三种情况的多态:普通类的多态,抽象类的多态,接口的多态)
/*多态的基本定义格式:
* 父类类型 变量名 = new 子类类型();
* 变量名.方法名();
*/
// 情况一:普通类多态定义的格式
// 父类 变量名 = new 子类();
public class Parent { public void fun(){...}}
// 子类重写父类方法
public class Child extends Parent { public void fun(){ xxx } }
//类的多态使用
Parent p = new Child();
// 情况二:抽象类多态定义的格式
// 抽象类 变量名 = new 抽象类子类();
public class abstract class Parent {
public abstract void method();
}
public class Child extends Parent {
public void method(){
System.out.println(“重写父类抽象方法”);
}
}
//类的多态使用
Parent parent= new Child();
// 情况三:接口多态定义的格式
// 接口 变量名 = new 接口实现类();
public class interface Parent {
public abstract void method();
}
public class Child implements Parent {
public void method(){
System.out.println(“重写接口抽象方法”);
}
}
//接口的多态使用
Parent parent = new Child();
多态中的两种转型:
多态的转型分为向上转型与向下转型两种:
向上转型:当有子类对象赋值给一个父类引用时,便是向上转型,多态本身就是向上转型的过程。(自动的)
向上转型的弊端:只能使用父类共性的内容,而无法使用子类特有功能,功能有限制。
使用格式:
父类类型 变量名 = new 子类类型();
如:Person p = new Student();
向下转型:一个已经向上转型的子类对象可以使用强制类型转换的格式,将父类引用转为子类引用,这个过程是向下转型。如果是直接创建父类对象,是无法向下转型的!
向下转型的用处:可以使用子类特有功能。
使用格式:
子类类型 变量名 = (子类类型) 父类类型的变量;
如:Student stu = (Student) p; //变量p 实际上指向Student对象
此时 stu可以调用子类中特有的方法(就是父类中没有定义,只有子类定义了的方法)。
1.6.1 动态绑定
将一条消息发给对象时,如果并不知道对方的具体类型是什么,但采取的行动同样是正确的,这种情况就叫作“多形性”(Polymorphism)。对面向对象的程序设计语言来说,它们用以实现多形性的方法叫作“动态绑定”。编译器和运行期系统会负责对所有细节的控制;我们只需知道会发生什么事情,而且更重要的是,如何利用它帮助自己设计程序。
在Java 中,我们则完全不必记住添加一个关键字,因为函数的动态绑定是自动进行的。所以在将一条消息发给对象时,我们完全可以肯定对象会采取正确的行动,即使其中涉及上溯造型之类的处理。
1.6.2 抽象的基础类和接口
设计程序时,我们经常都希望基础类只为自己的衍生类提供一个接口。也就是说,我们不想其他任何人实际创建基础类的一个对象,只对上溯造型成它,以便使用它们的接口。为达到这个目的,需要把那个类变成“抽象”的——使用abstract 关键字。若有人试图创建抽象类的一个对象,编译器就会阻止他们。这种工具可有效强制实行一种特殊的设计。
亦可用abstract 关键字描述一个尚未实现的方法——作为一个“根”使用,指出:“这是适用于从这个类继承的所有类型的一个接口函数,但目前尚没有对它进行任何形式的实现。”抽象方法也许只能在一个抽象类
里创建。继承了一个类后,那个方法就必须实现,否则继承的类也会变成“抽象”类。通过创建一个抽象方法,我们可以将一个方法置入接口中,不必再为那个方法提供可能毫无意义的主体代码。
interface(接口)关键字将抽象类的概念更延伸了一步,它完全禁止了所有的函数定义。“接口”是一种相当有效和常用的工具。另外如果自己愿意,亦可将多个接口都合并到一起(不能从多个普通class 或abstract class 中继承)。
1.7 对象的创建和存在时间
C++允许我们决定是在写程序时创建对象,还是在运行期间创建,这种控制方法更加灵活。大家或许认为既然它如此灵活,那么无论如何都应在内存堆里创建对象,而不是在堆栈中创建。但还要考虑另外一个问题,亦即对的“存在时间”或者“生存时间”(Lifetime)。若在堆栈或者静态存储空间里创建一个对象,编译器会判断对象的持续时间有多长,到时会自动“破坏”或者“清除”它。程序员可用两种方法来破坏一个对象:用程序化的方式决定何时破坏对象,或者利用由运行环境提供的一种“垃圾收集器”特性,自动寻找那些不再使用的对象,并将其清除当然,垃圾收集器显得方便得多,但要求所有应用程序都必须容忍垃圾收集器的存在,并能默许随垃圾收集带来的额外开销但这并不符合C++语言的设计宗旨,所以未能包括到C++里。但Java 确实提供了一个垃圾收集 。
1.7.1 集合与继承器
所有集合都提供了相应的读写功能。将某样东西置入集合时,采用的方式是十分明显的。有一个叫作“推”(Push)、“添加”(Add)或其他类似名字的函数用于做这件事情。但将数据从集合中取出的时候,方式却并不总是那么明显。如果是一个数组形式的实体,比如一个矢量(Vector),那么也许能用索引运算符或函数。但在许多情况下,这样做往往会无功而返。此外,单选定函数的功能是非常有限的。如果想对集合中的一系列元素进行操纵或比较,而不是仅仅面向一个,这时又该怎么办呢?办法就是使用一个“继续器”(Iterator),它属于一种对象,负责选择集合内的元素,并把它们提供给继承器的用户。作为一个类,它也提供了一级抽象。利用这一级抽象,可将集合细节与用于访问那个集合的代码隔离开。通过继承器的作用,集合被抽象成一个简单的序列。继承器允许我们遍历那个序列,同时毋需关心基础结构是什么——换言之,不管它是一个矢量、一个链接列表、一个堆栈,还是其他什么东西。这样一来,我们就可以灵活地改变基础数据,不会对程序里的代码造成干扰。Java 最开始(在1.0 和1.1 版中)提供的是一个标准继承器,名为Enumeration(枚举),为它的所有集合类提供服务。
1.7.2 单根结构
在Java 中(与其他几乎所有OOP 语言一样),所有类最终是否都应从单独一个基础类继承,而且这个终级基础类的名字很简单,就是一个“Object”。这种“单根结构”具有许多方面的优点。
单根结构中的所有对象都有一个通用接口,所以它们最终都属于相同的类型。
单根结构中的所有对象(比如所有Java 对象)都可以保证拥有一些特定的功能。在自己的系统中,我们知道对每个对象都能进行一些基本操作。一个单根结构,加上所有对象都在内存堆中创建,可以极大简化参数的传递(这在C++里是一个复杂的概念)。利用单根结构,我们可以更方便地实现一个垃圾收集器。与此有关的必要支持可安装于基础类中,而垃圾收集器可将适当的消息发给系统内的任何对象。如果没有这种单根结构,而且系统通过一个句柄来操纵对象,那么实现垃圾收集器的途径会有很大的不同,而且会面临许多障碍。由于运行期的类型信息肯定存在于所有对象中,所以永远不会遇到判断不出一个对象的类型的情况。这对系统级的操作来说显得特别重要,比如违例控制;而且也能在程序设计时获得更大的灵活性。
1.7.3 集合库与方便使用集合
由于集合是我们经常都要用到的一种工具,所以一个集合库是十分必要的,它应该可以方便地重复使用。这样一来,我们就可以方便地取用各种集合,将其插入自己的程序。Java 提供了这样的一个库。
1.7.4 清除时的困境:由谁负责清除?
每个对象都要求资源才能“生存”,其中最令人注目的资源是内存。如果不再需要使用一个对象,就必须将其清除,以便释放这些资源,以便其他对象使用。如果要解决的是非常简单的问题,如何清除对象这个问题并不显得很突出:我们创建对象,在需要的时候调用它,然后将其清除或者“破坏”。但在另一方面,我们平时遇到的问题往往要比这复杂得多。
在Java 中,垃圾收集器在设计时已考虑到了内存的释放问题(尽管这并不包括清除一个对象涉及到的其他方面)。垃圾收集器“知道”一个对象在什么时候不再使用,然后会自动释放那个对象占据的内存空间。采用这种方式,另外加上所有对象都从单个根类Object 继承的事实,而且由于我们只能在内存堆中以一种方式创建对象,所以Java 的编程要比C++的编程简单得多。我们只需要作出少量的抉择,即可克服原先存在的大量障碍。
1.8 违例控制:解决错误
异常机制,是指程序不正常时的处理方式。具体来说,异常机制提供了程序退出的安全通道。当出现错误后,程序执行的流程发生改变,程序的控制权转移到异常处理器。
异常的一般性语法为:
try {
// 有可能抛出异常的代码
} catch (Exception e) {
// 异常处理
} finally {
// 无论是否捕获到异常都会执行的程序
}
“违例控制”将错误控制方案内置到程序设计语言中,有时甚至内建到操作系统内。这里的“违例”(Exception)属于一个特殊的对象,它会从产生错误的地方“扔”或“掷”出来。随后,这个违例会被设计用于控制特定类型错误的“违例控制器”捕获。
Java 的违例控制机制与大多数程序设计语言都有所不同。因为在Java 中,违例控制模块是从一开始就封装好的,所以必须使用它
1.9 多线程
多线程的实现:
1.继承Thread类,重写run方法(其实Thread类本身也实现了Runnable接口)
2.实现Runnable接口,重写run方法
3.实现Callable接口,重写call方法(有返回值)
4.使用线程池(有返回值)
一个基本的概念就是同时对多个任务加以控制。许多程序设计问题都要求程序能够停下手头的工作,改为处理其他一些问题,再返回主进程。可以通过多种途径达到这个目的。最开始的时候,那些拥有机器低级知识的程序员编写一些“中断服务例程”,主进程的暂停是通过硬件级的中断实现的。尽管这是一种有用的方法,但编出的程序很难移植,由此造成了另一类的代价高昂问题。有些时候,中断对那些实时性很强的任务来说是很有必要的。但还存在其他许多问题,它们只要求将问题划分进入独立运行的程序片断中,使整个程序能更迅速地响应用户的请求。在一个程序中,这些独立运行的片断叫作“线程”(Thread),利用它编程的概念就叫作“多线程处理”。多线程处理一个常见的例子就是用户界面。利用线程,用户可按下一个按钮,然后程序会立即作出响应,而不是让用户等待程序完成了当前任务以后才开始响应。
1.10 永久性
(永久代???)
创建一个对象后,只要我们需要,它就会一直存在下去。但在程序结束运行时,对象的“生存期”也会宣告结束。尽管这一现象表面上非常合理,但深入追究就会发现,假如在程序停止运行以后,对象也能继续存在,并能保留它的全部信息,那么在某些情况下将是一件非常有价值的事情。下次启动程序时,对象仍然在那里,里面保留的信息仍然是程序上一次运行时的那些信息。当然,可以将信息写入一个文件或者数据库,从而达到相同的效果。但尽管可将所有东西都看作一个对象,如果能将对象声明成“永久性”,并令其为我们照看其他所有细节,无疑也是一件相当方便的事情。
1.11 Java 和因特网
Java 除了可解决传统的程序设计问题以外,还能解决World Wide Web(万维网)上的编程问题。
1.12 分析和设计
1.12.1 不要迷失
假如你正在考察一种特殊的方法,其中包含了大量细节,并推荐了许多步骤和文档,那么仍然很难正确判断自己该在何时停止。时刻提醒自己注意以下几个问题:
(1) 对象是什么?(怎样将自己的项目分割成一系列单独的组件?)
(2) 它们的接口是什么?(需要将什么消息发给每一个对象?)
在确定了对象和它们的接口后,便可着手编写一个程序。出于对多方面原因的考虑,可能还需要比这更多的说明及文档,但要求掌握的资料绝对不能比这还少。
1.12.2 阶段 0:拟出一个计划
第一步是决定在后面的过程中采取哪些步骤。在这个阶段,可能要决定一些必要的附加处理结构。但非常不幸,有些程序员写程序时喜欢随心所欲,他们
认为“该完成的时候自然会完成”。这样做刚开始可能不会有什么问题,但我觉得假如能在整个过程中设置几个标志,或者“路标”,将更有益于你集中注意力。这恐怕比单纯地为了“完成工作”而工作好得多。至,在达到了一个又一个的目标,经过了一个接一个的路标以后,可对自己的进度有清晰的把握,干劲也会相应地提高,不会产生“路遥漫漫无期”的感觉/
1.12.3 阶段 1:要制作什么
应尽可能总结出自己系统的一套完整的“使用条件”或者“应用场合”。一旦完成这个工作,就相当于摸清了想让系统完成的核心任务。由于将重点放在“使用条件”上,一个很好的效果就是它们总能让你放精力放在最关键的东西上,并防止自己分心于对完成任务关系不大的其他事情上面。也就是说,只要掌握了一套完整的“使用条件”,就可以对自己的系统作出清晰的描述,并转移到下一个阶段。在这一阶段,也有可能无法完全掌握系统日后的各种应用场合,但这也没有关系。只要肯花时间,所有问题都会自然而然暴露出来。不要过份在意系统规格的“完美”,否则也容易产生挫败感和焦燥情绪。
1.12.4 阶段 2:如何构建
在这一阶段,必须拿出一套设计方案,并解释其中包含的各类对象在外观上是什么样子,以及相互间是如何沟通的。此时可考虑采用一种特殊的图表工具:“统一建模语言”(UML)。请到http://www.rational.com去下载一份UML 规格书。作为第1 阶段中的描述工具,UML 也是很有帮助的。此外,还可用它在第2 阶段中处理一些图表(如流程图)。当然并非一定要使用UML,但它对你会很有帮助,特别是在希望描绘一张详尽的图表,让许多人在一起研究的时候。除UML 外,还可选择对对象以及它们的接口进行文字化描述(就象我在《Thinking in C++》里说的那样,但这种方法非常原始,发挥的作用亦较有限。
1.12.5 阶段 3:开始创建
构建好系统,并令其运行起来后,必须进行实际检验,以前做的那些需求分析和系统规格便可派上用场了。全面地考察自己的程序,确定提出的所有要求均已满足。
1.12.6 阶段 4:校订
构建一套系统时,“校订”几乎是不可避免的。我们需要不断地对比自己的需求,了解系统是否自己实际所需要的。有时只有实际看到系统,才能意识到自己需要解决一个不同的问题。若认为这种形式的校订必然会发生,那么最好尽快拿出自己的第一个版本,检查它是否自己希望的,使自己的思想不断趋向成熟。
1.12.7 计划的回报
软件开发则完全不同,它的“设计图”(计划)必须详尽而完备。在很长的一段时间里,人们在他们的开发过程中并没有太多的结构,但那些大型项目很容易就会遭致失败。通过不断的摸索,人们掌握了数量众多的结构和详细资料。但它们的使用却使人提心吊胆在意——似乎需要把自己的大多数时间花在编写文档上,而没有多少时间来编程(经常如此)。我希望这里为大家讲述的一切能提供一条折衷的道路。需要采取一种最适合自己需要(以及习惯)的方法。不管制订出的计划有多么小,但与完全没有计划相比,一些形式的计划会极大改善你的项目。
1.13 Java 还是 C++ ?
1)Java 为解释型语言。
其运行过程为:程序源代码经过 Java 编译器编译成字节码,然后 由 JVM 解释执行。
而 C/C++ 为编译型语言,源代码经过编译和链接后生成可执行的二进制代码。因此,Java 的执行速度比 C/C+ + 慢,但是 Java 能够跨平台执行,而 C/C++ 不能。
2)Java 为纯面向对象语言。
所有代码(包括函数、变量等)必须在类中实现,除基本数 据类型 (包括 int、float 等)外,所有类型都是类。此外,Java语言中不存在全局变量或全局函数,而C++兼具面向过程和面向过程编程的特点,可以定义全局变量和全局函数。
3)Java语言中没有指针的概念。(Java 有引用)
这有效防止了 C/C++ 语言中操作 指针可能引起的系统问题,从而使程序变得更加安全。
4)Java语言不支持多重继承。
但是Java语言引入了接口的概念,可以同时实现多个接口。由于接口也具有多态特性,因此在Java语言中可以通过实现多个接口 来实现与C++语言中多重继承类似的目的。
5)Java语言提供了垃圾回收器来实现垃圾的自动回收。
在C++语言中,需要开发人员去管理对内存的分配(包括申请与释放),而Java语言 提供了垃圾回收器来实现垃圾的自动回收,不:要程序显式地管理内存的分配。在C++语言 中,通常都会把释放资源的代码放到析构函数中,Java语言中虽然没有析构函数,但却引入了 一个finalize()方法,当垃圾回收器将要释放无用对象的内存时,会首先调用该对象的finalize ()方法,因此,开发人员不需要关心也不需要知道对象所占的内存空间何时会被释放。
6)其它。
1.C++语言支持运算符重载,而Java语言不支持运算符重载。
2.C++语言支持预处理,而 Java语言没有预处理器,虽然不支持预处理功能(包括头文件、宏定义等),但它提供的import 机制与 C++中的预处理器功能类似。
3.C++支持默认函数参数,而 Java 不支持默认函数参数,C/C++支持goto句,而Java不提供goto语句(但Java中goto是保留关键字)。
4.C/C+ + 支持自动强制类型转换,这会导致程序的不安全;而Java不支持自动强制类型转换,必须由 开发人员进行显式地强制类型转换。
5.C/C++中,结构和联合的所有成员均为公有,这往往会导致安全性问题的发生,而Java根本就不包含结构和联合,所有内容都封装在类里而。
6.Java具有平台无关性,即对每种数据类型都分配固定长度,例如,int类型总是占据32 位,而C/C++却不然,同一个数据类型在不同的平台上会分配不同的字节数。
7.Java提供对注释文档的内建支持,所以源码文件也可以包含它们自己的文档。通过一个单独的程序,这些文档信息可以提取出来,并重新格式化成HTML。
8.Java包含了一些标准库,用于完成特定的任务,同时这些库简单易用,能够大大缩短开发周期,例如,Java提供了用于访问数据库的JDBC库,用于实现分布式对象的RMI等标准库。 C++则依靠一些非标准的、由其他厂商提供的库。
第 2 章 一切都是对象
尽管以 C++ 为基础,但 Java 是一种更纯粹的面向对象程序设计语言
2.1 用句柄操作对象
尽管将一切都“看作”对象,但操纵的标识符实际是指向一个对象的“句柄”
(Handle)。
句柄:在java中我们在实例化完对象后,在对其进行操作时,用来去操作对象的就叫做句柄。他代表了当前对象的唯一一个标识,并不能代表当前对象的内存地址。
例如:
Tree t1 = new Tree();
上边例子中,t1就属于当前新建对象的句柄,它指向新建对象的实例,我们通过他去操作对象。
2.2 所有对象都必须创建
创建句柄时,我们希望它同一个新对象连接。通常用new 关键字达到这一目的。
2.2.1 保存到什么地方
程序运行时,我们最好对数据保存到什么地方做到心中有数。特别要注意的是内存的分配。有六个地方都可
以保存数据:
(1) 寄存器。这是最快的保存区域,因为它位于和其他所有保存方式不同的地方:处理器内部。然而,寄存器的数量十分有限,所以寄存器是根据需要由编译器分配。我们对此没有直接的控制权,也不可能在自己的程序里找到寄存器存在的任何踪迹。
(2) 堆栈。驻留于常规RAM(随机访问存储器)区域,但可通过它的“堆栈指针”获得处理的直接支持。堆栈指针若向下移,会创建新的内存;若向上移,则会释放那些内存。这是一种特别快、特别有效的数据保存方式,仅次于寄存器。创建程序时,Java 编译器必须准确地知道堆栈内保存的所有数据的“长度”以及“存在时间”。这是由于它必须生成相应的代码,以便向上和向下移动指针。这一限制无疑影响了程序的灵活性,所以尽管有些Java 数据要保存在堆栈里——特别是对象句柄,但Java 对象并不放到其中。
(3) 堆。一种常规用途的内存池(也在RAM 区域),其中保存了Java 对象。和堆栈不同,“内存堆”或“堆”(Heap)最吸引人的地方在于编译器不必知道要从堆里分配多少存储空间,也不必知道存储的数据要在堆里停留多长的时间。因此,用堆保存数据时会得到更大的灵活性。要求创建一个对象时,只需用new 命令编制相关的代码即可。执行这些代码时,会在堆里自动进行数据的保存。当然,为达到这种灵活性,必然会付出一定的代价:在堆里分配存储空间时会花掉更长的时间!
(4) 静态存储。这儿的“静态”(Static)是指“位于固定位置”(尽管也在RAM 里)。程序运行期间,静态存储的数据将随时等候调用。可用static 关键字指出一个对象的特定元素是静态的。但Java 对象本身永远都不会置入静态存储空间。
(5) 常数存储。常数值通常直接置于程序代码内部。这样做是安全的,因为它们永远都不会改变。有的常数需要严格地保护,所以可考虑将它们置入只读存储器(ROM)。
(6) 非RAM 存储。若数据完全独立于一个程序之外,则程序不运行时仍可存在,并在程序的控制范围之外。其中两个最主要的例子便是“流式对象”和“固定对象”。对于流式对象,对象会变成字节流,通常会发给另一台机器。而对于固定对象,对象保存在磁盘中。即使程序中止运行,它们仍可保持自己的状态不变。对于这些类型的数据存储,一个特别有用的技巧就是它们能存在于其他媒体中。一旦需要,甚至能将它们恢复成普通的、基于RAM 的对象。
2.2.2 特殊情况:主要类型
byte:8位,最大存储数据量是255,存放的数据范围是-128127之间。short:16位,最大数据存储量是65536,数据范围是-3276832767之间。int:32位,最大数据存储容量是2的32次方减1,数据范围是负的2的31次方到正的2的31次方减1。
long:64位,最大数据存储容量是2的64次方减1,数据范围为负的2的63次方到正的2的63次方减1。
float:32位,数据范围在3.4e-45~1.4e38,直接赋值时必须在数字后加上f或F。
double:64位,数据范围在4.9e-324~1.8e308,赋值时可以加d或D也可以不加。
boolean:只有true和false两个取值。
char:16位,存储Unicode码,用单引号赋值。
高精度整数和高精度小数 BigInteger和BigDecimal :
import java.math.BigDecimal;
import java.math.BigInteger;
public class BigIntegerTest {
public static void main(String[] args) {
float f1 = 123.01f + 2.01f;
// 预期输出:125.02,实际输出:125.020004
System.out.println(f1);
// 预期输出:125.02,实际输出:125.02000000000001
System.out.println(123.01 + 2.01);
System.out.println("===============================");
// 高精度整数测试
BigInteger bint1 = new BigInteger("125");
BigInteger bint2 = new BigInteger("999");
BigInteger tmp;
// 相加
tmp = bint1.add(bint2);
System.out.println("bint1 + bint2 = " + tmp);
// 相减
tmp = bint2.subtract(bint1);
System.out.println("bint2 - bint1 = " + tmp);
// 相乘
tmp = bint1.multiply(bint2);
System.out.println("bint1 * bint2 = " + tmp);
// 相除
tmp = bint2.divide(bint1);
System.out.println("bint2 / bint1 = " + tmp);
// 求余数
tmp = bint2.remainder(bint1);
System.out.println("bint2 % bint1 = " + tmp);
// 求次方
tmp = bint2.pow(2);
System.out.println("bint2的二次方 = " + tmp);
System.out.println("======================================");
// 高精度小数测试
BigDecimal bd1 = new BigDecimal(123.01);
BigDecimal bd2 = new BigDecimal(2.01);
BigDecimal bd;
// 相加
bd = bd1.add(bd2);
System.out.println("bd1 + bd2 = " + bd);
// 相减
bd = bd1.subtract(bd2);
System.out.println("bd2 - bd1 = " + bd);
// 相乘
bd = bd1.multiply(bd2);
System.out.println("bd1 * bd2 = " + bd);
// 相除
// bd = bd1.divide(bd2);
bd = bd1.divide(new BigDecimal(2.0));
System.out.println("bd1 / 2.0 = " + bd);
// 求余数
bd = bd1.remainder(bd2);
System.out.println("bd2 % bd1 = " + bd);
// 求次方
bd = bd1.pow(3);
System.out.println("bd2的三次方 = " + bd);
System.out.println("======================================");
// 四舍五入保留小数位数
BigDecimal bd3 = new BigDecimal(123.01).setScale(5,5);
System.out.println("bd3 = " + bd3);
}
}
2.2.3 Java 的数组
Java 可以保证被初始化,而且不可在它的范围之外访问。由于系统自动进行范围检查,所以必然要付出一些代价:针对每个数组,以及在运行期间对索引的校验,都会造成少量的内存开销。但由此换回的是更高的安全性,以及更高的工作效率。为此付出少许代价是值得的。
创建对象数组时,实际创建的是一个句柄数组。而且每个句柄都会自动初始化成一个特殊值,并带有自己的关键字:null(空)。一旦Java 看到null,就知道该句柄并未指向一个对象。正式使用前,必须为每个句柄都分配一个对象。若试图使用依然为null 的一个句柄,就会在运行期报告问题。因此,典型的数组错误在Java 里就得到了避免。
2.3 绝对不要清除对象
2.3.1 作用域
大多数程序设计语言都提供了“作用域”(Scope)的概念。对于在作用域里定义的名字,作用域同时决定了它的“可见性”以及“存在时间”。
由于Java 是一种形式自由的语言,所以额外的空格、制表位以及回车都不会对结果程序造成影响。
2.3.2 对象的作用域
Java 对象不具备与主类型一样的存在时间。用new 关键字创建一个Java 对象的时候,它会超出作用域的范围之外。
Java 有一个特别的“垃圾收集器”,它会查找用new 创建的所有对象,并辨别其中哪些不再被引用。随后,它会自动释放由那些闲置对象占据的内存,以便能由新对象使用。这意味着我们根本不必操心内存的回收问题。只需简单地创建对象,一旦不再需要它们,它们就会自动离去。这样做可防止在C++里很常见的一个编程问题:由于程序员忘记释放内存造成的“内存溢出”。
2.4 新建数据类型:类
在这个关键字的后面,应该跟随新数据类型的名称。例如:
class ATypeName {/*类主体置于这里}
这样就引入了一种新类型,接下来便可用new 创建这种类型的一个新对象:
ATypeName a = new ATypeName();
在ATypeName 里,类主体只由一条注释构成(星号和斜杠以及其中的内容,本章后面还会详细讲述),所以并不能对它做太多的事情。事实上,除非为其定义了某些方法,否则根本不能指示它做任何事情。
2.4.1 字段和方法
定义一个类时,可在自己的类里设置两种类型的元素:数据成员(有时也叫“字段”)以及成员函数(通常叫“方法”)。其中,数据成员是一种对象(通过它的句柄与其通信),可以为任何类型。它也可以是主类型(并不是句柄)之一。如果是指向对象的一个句柄,则必须初始化那个句柄,用一种名为“构建器”(第4 章会对此详述)的特殊函数将其与一个实际对象连接起来(就象早先看到的那样,使用new 关键字)。但若是一种主类型,则可在类定义位置直接初始化(正如后面会看到的那样,句柄亦可在定义位置初始化)。
假若在一个函数定义中写入下述代码:
int x;
那么x 会得到一些随机值(这与C 和C++是一样的),不会自动初始化成零。我们责任是在正式使用x 前分配一个适当的值。如果忘记,就会得到一条编译期错误,告诉我们变量可能尚未初始化。
2.5 方法、自变量和返回值
Java 的“方法”决定了一个对象能够接收的消息。
方法的基本组成部分包括名字、自变量、返回类型以及主体。下面便是它最基本的形式:
返回类型 方法名( /* 自变量列表*/ ) {/* 方法主体 */}
返回类型是指调用方法之后返回的数值类型。显然,方法名的作用是对具体的方法进行标识和引用。自变量列表列出了想传递给方法的信息类型和名称。
Java 的方法只能作为类的一部分创建。只能针对某个对象调用一个方法(“静态”方法可针对类调用,毋需一个对象。),而且那个对象必须能够执行那个方法调用。若试图为一个对象调用错误的方法,就会在编译期得到一条出错消息。为一个对象调用方法时,需要先列出对象的名字,在后面跟上一个句点,再跟上方法名以及它的参数列表。亦即“对象名.方法名(自变量1,自变量2,自变量3…)。
2.5.1 自变量列表
自变量列表规定了我们传送给方法的是什么信息。我们必须在自变量列表里指定要传递的对象类型,以及每个对象的名字。
2.6 构建 Java 程序
2.6.1 名字的可见性
Java 的设计者鼓励程序员反转使用自己的Internet 域名,因为它们肯定是独一
无二的。
2.6.2 使用其他组件
要用import 关键字准确告诉Java 编译器我们希望的类是什么。import 的作用是指示编译器导入一个“包”——或者说一个“类库”(在其他语言里,可将“库”想象成一系列函数、数据以及类的集合。但请记住,Java 的所有代码都必须写入一个类中)。
我们有时希望使用其中的几个,同时不想全部明确地声明它们。为达到这个目的,可使用“*”通配符。
2.6.3 static 关键字
static 表示“全局”或者“静态”的意思,用来修饰成员变量和成员方法,也可以形成静态static代码块。
static 修饰的变量习惯称为静态变量,static修饰的方法称为静态方法,static修饰的代码块叫做静态代码块。
static 的意义在于方便在没有创建对象的情况下来进行调用(方法/变量)
静态变量和实例变量的区别 :
**实例变量:**每次创建对象,都会为每个对象分配成员变量内存空间,实例变量是属于实例对象的,在内存中,创建几次对象,就有几份成员变量。
**静态变量:**静态变量由于不属于任何实例对象,是属于类的,所以在内存中只会有一份,在类的加载过程中,JVM为静态变量分配一次内存空间。
2.7 我们的第一个Java程序
// Property.java
import java.util.*;
public class Property {
public static void main(String[] args) {
System.out.println(new Date());
Properties p = System.getProperties();
p.list(System.out);
System.out.println("--- Memory Usage:");
Runtime rt = Runtime.getRuntime();
System.out.println("Total Memory = "
+ rt.totalMemory()
+ " Free Memory = "
+ rt.freeMemory());
}
}
在某些编程环境里,程序会在屏幕上一切而过,甚至没机会看到结果。可将下面这段代码置于main()的末尾,用它暂停输出:
try {
Thread.currentThread().sleep(5 * 1000);
} catch(InterruptedException e) {}
}
第二行调用了System.getProperties()。若用Web 浏览器查看联机用户文档,就可知道getProperties()是System 类的一个static 方法。
2.8 注释和嵌入文档
/* 这是
*一段注释,
*它跨越了多个行
*/
/*其实这一段
和上面一段没有不同*/
//这是一条单行注释
2.8.1 注释文档
用于提取注释的工具叫作javadoc。它采用了部分来自Java 编译器的技术,查找我们置入程序的特殊注释标记。它不仅提取由这些标记指示的信息,也将毗邻注释的类名或方法名提取出来。这样一来,我们就可用最轻的工作量,生成十分专业的程序文档。
javadoc 输出的是一个HTML 文件,可用自己的Web 浏览器查看。该工具允许我们创建和管理单个源文件,并生动生成有用的文档。由于有了javadoc,所以我们能够用标准的方法创建文档。而且由于它非常方便,所以我们能轻松获得所有Java 库的文档。
2.8.2 具体语法
有三种类型的注释文档,它们对应于位于注释后面的元素:类、变量或者方法。也就是说,一个类注释正好位于一个类定义之前;变量注释正好位于变量定义之前;而一个方法定义正好位于一个方法定义的前面。如下面这个简单的例子所示:
/** 一个类注释 */
public class docTest {
/** 一个变量注释 */
public int i;
/** 一个方法注释 */
public void f() {}
}
注意javadoc 只能为public(公共)和protected(受保护)成员处理注释文档。“private”(私有)和“友好”(详见5 章)成员的注释会被忽略,我们看不到任何输出(也可以用-private 标记包括private 成员)。这样做是有道理的,因为只有public 和protected 成员才可在文件之外使用,这是客户程序员的希望。然而,所有类注释都会包含到输出结果里。
上述代码的输出是一个HTML 文件,它与其他Java 文档具有相同的标准格式。
2.8.3 嵌入HTML
javadoc 将HTML 命令传递给最终生成的HTML 文档。这便使我们能够充分利用HTML 的巨大威力。
下面列出一个例子:
/**
*
* System.out.println(new Date());
*
*/
亦可象在其他Web 文档里那样运用HTML,对普通文本进行格式化,使其更具条理、更加美观:
/**
* 您甚至可以插入一个列表:
*
* - 项目一
*
- 项目二
*
- 项目三
*
*/
注意在文档注释中,位于一行最开头的星号会被javadoc 丢弃。同时丢弃的还有前导空格。javadoc 会对所
有内容进行格式化,使其与标准的文档外观相符。不要将
或
这样的标题当作嵌入HTML 使用,因为
javadoc 会插入自己的标题,我们给出的标题会与之冲撞。
所有类型的注释文档——类、变量和方法——都支持嵌入HTML。
2.8.4 @see:引用其他类
所有三种类型的注释文档都可包含@see 标记,它允许我们引用其他类里的文档。对于这个标记,javadoc 会生成相应的HTML,将其直接链接到其他文档。格式如下:
@see 类名
@see 完整类名
@see 完整类名#方法名
每一格式都会在生成的文档里自动加入一个超链接的“See Also”(参见)条目。注意javadoc 不会检查我们指定的超链接,不会验证它们是否有效。
2.8.5 类文档标记
随同嵌入HTML 和@see 引用,类文档还可以包括用于版本信息以及作者姓名的标记。类文档亦可用于“接口”目的、。
-
@version
-
@author
2.8.6 变量文档标记
变量文档只能包括嵌入的HTML 以及@see 引用。
2.8.7 文档方法标记
除嵌入HTML 和@see 引用之外,方法还允许使用针对参数、返回值以及违例的文档标记。
-
@param
格式如下:
@param 参数名 说明
其中,“参数名”是指参数列表内的标识符,而“说明”代表一些可延续到后续行内的说明文字。一旦遇到一个新文档标记,就认为前一个说明结束。可使用任意数量的说明,每个参数一个。 -
@return
格式如下:
@return 说明
其中,“说明”是指返回值的含义。它可延续到后面的行内。 -
@exception
有关“违例”(Exception)的详细情况,我们会在第9 章讲述。简言之,它们是一些特殊的对象,若某个方
法失败,就可将它们“扔出”对象。调用一个方法时,尽管只有一个违例对象出现,但一些特殊的方法也许
能产生任意数量的、不同类型的违例。所有这些违例都需要说明。所以,违例标记的格式如下:
@exception 完整类名 说明
其中,“完整类名”明确指定了一个违例类的名字,它是在其他某个地方定义好的。而“说明”(同样可以
延续到下面的行)告诉我们为什么这种特殊类型的违例会在方法调用中出现。 -
@deprecated
这是Java 1.1 的新特性。该标记用于指出一些旧功能已由改进过的新功能取代。该标记的作用是建议用户不
必再使用一种特定的功能,因为未来改版时可能摒弃这一功能。若将一个方法标记为@deprecated,则使用该
方法时会收到编译器的警告。
2.8.8 文档示例
//: Property.java
import java.util.*;
/** The first Thinking in Java example program.
* Lists system information on current machine.
* @author Bruce Eckel
* @author http://www.BruceEckel.com
* @version 1.0
*/
public class Property {
/** Sole entry point to class & application
* @param args array of string arguments
* @return No return value
* @exception exceptions No exceptions thrown
*/
public static void main(String[] args) {
System.out.println(new Date());
Properties p = System.getProperties();
p.list(System.out);
System.out.println("--- Memory Usage:");
Runtime rt = Runtime.getRuntime();
System.out.println("Total Memory = "
+ rt.totalMemory()
+ " Free Memory = "
+ rt.freeMemory());
}
} ///:~
2.9 编码样式
一个非正式的Java 编程标准是大写一个类名的首字母。若类名由几个单词构成,那么把它们紧靠到一起(也就是说,不要用下划线来分隔名字)。此外,每个嵌入单词的首字母都采用大写形式。
第 3 章 控制程序流程
3.1 使用 Java 运算符
几乎所有运算符都只能操作“主类型”(Primitives)。唯一的例外是“=”、“==”和“!=”,它们能操作所有对象(也是对象易令人混淆的一个地方)。除此以外,String 类支持“+”和“+=”。
3.1.1 优先级
运算符的优先级决定了存在多个运算符时一个表达式各部分的计算顺序。Java 对计算顺序作出了特别的规定。其中,最简单的规则就是乘法和除法在加法和减法之前完成。程序员经常都会忘记其他优先级规则,所以应该用括号明确规定计算顺序。
3.1.2 赋值
赋值是用等号运算符(=)进行的。
3.1.3 算数运算符
+= -= *= /=
3.1.4 自动递增和递减
++ –
3.1.5 关系运算符
关系运算符生成的是一个“布尔”(Boolean)结果。它们评价的是运算对象值之间的关系。若关系是真实的,关系表达式会生成true(真);若关系不真实,则生成false(假)。
3.1.6 逻辑运算符
逻辑运算符AND(&&)、OR(||)以及NOT(!)能生成一个布尔值(true 或false)——以自变量的逻辑关系为基础。下面这个例子向大家展示了如何使用关系和逻辑运算符。
3.1.7 按位运算符
若两个输入位都是1,则按位AND 运算符(&)在输出位里生成一个1;否则生成0。若两个输入位里至少有一个是1,则按位OR 运算符(|)在输出位里生成一个1;只有在两个输入位都是0 的情况下,它才会生成一个0。若两个输入位的某一个是1,但不全都是1,那么按位XOR(^,异或)在输出位里生成一个1。按位NOT(~,也叫作“非”运算符)属于一元运算符;它只对一个自变量进行操作(其他所有运算符都是二元运算符)。按位NOT 生成与输入位的相反的值——若输入0,则输出1;输入1,则输出0。
3.1.8 移位运算符
移位运算符面向的运算对象也是二进制的“位”。可单独用它们处理整数类型(主类型的一种)。左移位运算符(<<)能将运算符左边的运算对象向左移动运算符右侧指定的位数(在低位补0)。“有符号”右移位运算符(>>)则将运算符左边的运算对象向右移动运算符右侧指定的位数。“有符号”右移位运算符使用了“符号扩展”:若值为正,则在高位插入0;若值为负,则在高位插入1。Java 也添加了一种“无符号”右移位运算符(>>>),它使用了“零扩展”:无论正负,都在高位插入0。
3.1.9 三元if-else运算符
布尔表达式 ? 值0:值1
3.1.10 逗号运算符
在Java 里需要用到逗号的唯一场所就是for 循环。
3.1.11 字串运算符
我们注意到运用“String +”时一些有趣的现象。若表达式以一个String 起头,那么后续所有运算对象都必须是字串。
3.1.12 运算符常规操作规则
3.1.13 造型运算符
“造型”(Cast)的作用是“与一个模型匹配”。在适当的时候,Java 会将一种数据类型自动转换成另一种。例如,假设我们为浮点变量分配一个整数值,计算机会将int 自动转换成float。通过造型,我们可明确设置这种类型的转换,或者在一般没有可能进行的时候强迫它进行。
若对主数据类型执行任何算术或按位运算,只要它们“比int 小”(即char,byte 或者short),那么在正式执行运算之前,那些值会自动转换成int。这样一来,最终生成的值就是int 类型。所以只要把一个值赋回较小的类型,就必须使用“造型”。
3.1.14Java没有“sizeof”
Java 不需要sizeof() 运算符来满足这方面的需要,因为所有数据类型在所有机器的大小都是相同的。我们不必考虑移植问题——Java 本身就是一种“与平台无关”的语言。
3.2 执行控制
在Java 里,涉及的关键字包括if-else、while、do-while、for 以及一个名为switch 的选择语句。然而,Java 并不支持非常有害的goto。
3.2.1 真和假
所有条件语句都利用条件表达式的真或假来决定执行流程。条件表达式的一个例子是AB。它用条件运算符“”来判断A 值是否等于B 值。该表达式返回true 或false。
3.2.2 if-else
if-else 语句或许是控制程序流程最基本的形式。其中的else 是可选的,所以可按下述两种形式来使用if:
if(布尔表达式)
语句
或者
if(布尔表达式)
语句
else
语句
3.2.3 反复
while,do-while 和for 控制着循环,有时将其划分为“反复语句”。除非用于控制反复的布尔表达式得到“假”的结果,否则语句会重复执行下去。while 循环的格式如下:
while(布尔表达式)
语句
在循环刚开始时,会计算一次“布尔表达式”的值。而对于后来每一次额外的循环,都会在开始前重新计算一次。
3.2.4 do-while
do-while 的格式如下:
do
语句
while(布尔表达式)
while 和do-while 唯一的区别就是do-while 肯定会至少执行一次;也就是说,至少会将其中的语句“过一遍”——即便表达式第一次便计算为false。
3.2.5 for
for 循环在第一次反复之前要进行初始化。随后,它会进行条件测试,而且在每一次反复的时候,进行某种形式的“步进”(Stepping)。for 循环的形式如下:
for(初始表达式; 布尔表达式; 步进)
语句
3.2.6 中断和继续
在任何循环语句的主体部分,亦可用break 和continue 控制循环的流程。其中,break 用于强行退出循环,不执行循环中剩余的语句。而continue 则停止执行当前的反复,然后退回循环起始和,开始新的反复。
3.2.7 开关
“开关”(Switch)有时也被划分为一种“选择语句”。根据一个整数表达式的值,switch 语句可从一系列代码选出一段执行。它的格式如下:
switch(整数选择因子) {
case 整数值1 : 语句; break;
case 整数值2 : 语句; break;
case 整数值3 : 语句; break;
case 整数值4 : 语句; break;
case 整数值5 : 语句; break;
//…
default:语句;
}
每个case 均以一个break 结尾。这样可使执行流程跳转至switch 主体的末
尾。这是构建switch 语句的一种传统方式,但break 是可选的。若省略break,会继续执行后面的case 语句的代码,直到遇到一个break 为止。
switch 不支持 long,是因为 switch 的设计初衷是对那些只有少数的几个值进行等值判断,如果值过于复杂,那么还是用 if 比较合适。
第 4 章 初始化和清除
C++为我们引入了“构建器”的概念。这是一种特殊的方法,在一个对象创建之后自动调用。Java 也沿用了这个概念,但新增了自己的“垃圾收集器”,能在资源不再需要的时候自动释放它们。
4.1 用构建器自动初始化
在Java 中,由于提供了名为“构建器”的一种特殊方法,所以类的设计者可担保每个对象都会得到正确的初始化。若某个类有一个构建器,那么在创建对象时,Java 会自动调用那个构建器——甚至在用户毫不知觉的情况下。
和其他任何方法一样,构建器也能使用自变量,以便我们指定对象的具体创建方式。可非常方便地改动上述例子,以便构建器使用自己的自变量。如下所示:
class Rock {
Rock(int i) {
System.out.println(
"Creating Rock number " + i);
}
}
public class SimpleConstructor {
public static void main(String[] args) {
for(int i = 0; i < 10; i++)
new Rock(i);
}
}
4.2 方法过载(Overlode)
为了让相同的方法名伴随不同的自变量类型使用,“方法过载”是非常关键的一项措施。同时,尽管方法过载是构建器必需的,但它亦可应用于其他任何方法,且用法非常方便。
class Tree {
height;
Tree() {
prt("Planting a seedling");
height = 0;
}
Tree(int i) {
prt("Creating new Tree that is "
+ i + " feet tall");
height = i;
}
void info() {
prt("Tree is " + height
+ " feet tall");
}
void info(String s) {
prt(s + ": Tree is "
+ height + " feet tall");
}
static void prt(String s) {
System.out.println(s);
}
}
public class Overloading {
public static void main(String[] args) {
for(int i = 0; i < 5; i++) {
Tree t = new Tree(i);
t.info();
t.info("overloaded method");
}
// Overloaded constructor:
new Tree();
}
}
4.2.1 区分过载方法
每个过载的方法都必须采取独一无二的自变量类型列表。自变量的顺序也足够我们区分两个方法(尽管我们通常不愿意采用这种方法,因为它会产生难以维护的代码)
4.2.2 主类型的过载
若我们的数据类型“小于”方法中使用的自变量,就会对那种数据类型进行“转型”处理。char 获得的效果稍有些不同,这是由于假期它没有发现一个准确的char 匹配,就会转型为int。若我们的自变量范围比它宽,就必须用括号中的类型名将其转为适当的类型。如果不这样做,编译器会报告出错。
4.2.3 返回值过载
不能根据返回值类型来区分过载的方法。
4.2.4 默认构建器
若创建一个没有构建器的类,则编译程序会帮我们自动创建一个默认构建器。
4.2.5 this 关键字
this 关键字只能用于那些特殊的类——需明确使用当前对象的句柄。例如,假若您希望将句柄返回给当前对象,那么它经常在return 语句中使用。
public class Leaf {
private int i = 0;
Leaf increment() {
i++;
return this;
}
void print() {
System.out.println("i = " + i);
}
public static void main(String[] args) {
Leaf x = new Leaf();
x.increment().increment().increment().print();
}
}
1.在构建器里调用构建器
若为一个类写了多个构建器,那么经常都需要在一个构建器里调用另一个构建器,以避免写重复的代码。可用this 关键字做到这一点。
public class Flower {
private int petalCount = 0;
private String s = new String("null");
Flower(int petals) {
petalCount = petals;
System.out.println(
"Constructor w/ int arg only, petalCount= "
+ petalCount);
}
Flower(String ss) {
System.out.println(
"Constructor w/ String arg only, s=" + ss);
s = ss;
}
Flower(String s, int petals) {
this(petals);
//! this(s); // Can't call two!
this.s = s; // Another use of "this"
System.out.println("String & int args");
}
Flower() {
this("hi", 47);
System.out.println(
"default constructor (no args)");
}
void print() {
//! this(11); // Not inside non-constructor!
System.out.println(
"petalCount = " + petalCount + " s = "+ s);
}
public static void main(String[] args) {
Flower x = new Flower();
x.print();
}
}
尽管可用this 调用一个构建器,但不可调用两个。除此以外,构建器调用必须是我们做的第一件事情,否则会收到编译程序的报错信息。
2.static的含义
它意味着一个特定的方法没有this。我们不可从一个static 方法内部发出对非static 方法的调用,尽管反过来说是可以的。
4.3 清除:收尾和垃圾收集
finalize:
该关键字是一个方法finalize(),其是垃圾回收器(gc)要回收对象的时候,首先要调用这个类的finalize()
一旦垃圾收集器准备好释放对象占用的存储空间,它首先调用finalize(),而且只有在下一次垃圾收集过程中,才会真正回收对象的内存.所以如果使用finalize(),就可以在垃圾收集期间进行一些重要的清除或清扫工作.
finalize()在什么时候被调用:
(1)所有对象被Garbage Collection(GC)时自动调用,比如运行System.gc()的时候.
(2)程序退出时为每个对象调用一次finalize方法。
(3)显式的调用finalize方法
- 当某个对象被系统收集为无用信息的时候,finalize()将被自动调用,但是jvm不保证finalize()一定被调用,
Java 可用垃圾收集器回收由不再使用的对象占据的内存。现在考虑一种非常特殊且不多见的情况。假定我们的对象分配了一个“特殊”内存区域,没有使用new。垃圾收集器只知道释放那些由new 分配的内存,所以不知道如何释放对象的“特殊”内存。为解决这个问题,Java 提供了一个名为finalize()的方法,可为我们的类定义它。在理想情况下,它的工作原理应该是这样的:一旦垃圾收集器准备好释放对象占用的存储空间,它首先调用finalize(),而且只有在下一次垃圾收集过程中,才会真正回收对象的内存。所以如果使用finalize(),就可以在垃圾收集期间进行一些重要的清除或清扫工作。
4.3.1 finalize() 用途何在
垃圾收集只跟内存有关
垃圾收集器存在的唯一原因是为了回收程序不再使用的内存。所以对于与垃圾收集有关的任何动来说,其中最值得注意的是finalize()方法,它们也必须同内存以及它的回收有关。
4.3.2 必须执行清除
finalize()最有用处的地方之一是观察垃圾收集的过程。
4.4 成员初始化
Java 尽自己的全力保证所有变量都能在使用前得到正确的初始化。若被定义成相对于一个方法的“局部”变量,这一保证就通过编译期的出错提示表现出来。
在一个类的内部定义一个对象句柄时,如果不将其初始化成新对象,那个句柄就会获得一个空值。
基本类型的默认初始化值:
boolean false
char \u0000(null)
byte (byte)0
short (short)0
int 0
long 0L
float 0.0f
double 0.0d
4.4.1 规定初始化
如果想自己为变量赋予一个初始值,又会发生什么情况呢?为达到这个目的,一个最直接的做法是在类内部定义变量的同时也为其赋值。
这正是编译器对“向前引用”与初始化的顺序有关,而不是与程序的编译方
式有关。
4.4.2 构建器初始化
可考虑用构建器执行初始化进程。这样便可在编程时获得更大的灵活程度,因为我们可以在运行期调用方法和采取行动,从而“现场”决定初始化值。但要注意这样一件事情:不可妨碍自动初始化的进行,它在构建器进入之前就会发生。
1.初始化顺序
在一个类里,初始化的顺序是由变量在类内的定义顺序决定的。即使变量定义大量遍布于方法定义的中间,
那些变量仍会在调用任何方法之前得到初始化——甚至在构建器调用之前。
2.静态数据的初始化
若数据是静态的(static),那么同样的事情就会发生;如果它属于一个基本类型(主类型),而且未对其初始化,就会自动获得自己的标准基本类型初始值;如果它是指向一个对象的句柄,那么除非新建一个对象,并将句柄同它连接起来,否则就会得到一个空值(NULL)。
如果想在定义的同时进行初始化,采取的方法与非静态值表面看起来是相同的。但由于static 值只有一个存储区域,所以无论创建多少个对象,都必然会遇到何时对那个存储区域进行初始化的问题。
4.5 数组初始化
/**
* 创建数组的几种方式
**/
//1. 固定大小的空数组, 动态创建
String[] strArr1 = new String[3];
//2. 创建数组并直接赋值, 动态创建
String[] strArr2 = new String[]{"data", "struct", "static"};
//3. 直接赋值数组, 静态创建
String[] strArr3 = {"public", "private", "protected"};
数组代表一系列对象或者基本数据类型,所有相同的类型都封装到一起——采用一个统一的标识符名称。数组的定义和使用是通过方括号索引运算符进行的([])。为定义一个数组,只需在类型名后简单地跟随一对空方括号即可:
int[] al;
也可以将方括号置于标识符后面,获得完全一致的结果:
int al[];
由于数组的大小是随机决定的(使用早先定义的pRand()方法),所以非常明显,数组的创建实际是在运行期间进行的。除此以外,从这个程序的输出中,大家可看到基本数据类型的数组元素会自动初始化成“空”值(对于数值,空值就是零;对于char,它是null ;而对于boolean,它却是false)。
当然,数组可能已在相同的语句中定义和初始化了,如下所示:
int[] a = new int[20];
第 5 章 隐藏实施过程
“进行面向对象的设计时,一项基本的考虑是:如何将发生变化的东西与保持不变的东西分隔开。”
为解决这个问题,Java 推出了“访问指示符”的概念,允许库创建者声明哪些东西是客户程序员可以使用的,哪些是不可使用的。这种访问控制的级别在“最大访问”和“最小访问”的范围之间,分别包括:public,“友好的”(无关键字),protected 以及private。根据前一段的描述,大家或许已总结出作为一名库设计者,应将所有东西都尽可能保持为“private”(私有),并只展示出那些想让客户程序员使用的方法。
5.1 包:库单元
我们用import 关键字导入一个完整的库时,就会获得“包”(Package)。
之所以要进行这样的导入,是为了提供一种特殊的机制,以便管理“命名空间”(Name Space)。我们所有类成员的名字相互间都会隔离起来。位于类A 内的一个方法f()不会与位于类B 内的、拥有相同“签名”(自变量列表)的f()发生冲突。
编译一个.java 文件时,我们会获得一个名字完全相同的输出文件;但对于.java 文件中的每个类,它们都有一个.class 扩展名。因此,我们最终从少量的.java 文件里有可能获得数量众多的.class 文件。
package 语句必须作为文件的第一个非注释语句出现。该语句的作用是指出这个编译单元属于名为mypackage 的一个库的一部分。
5.1.1 创建独一无二的包名
-
自动编译
为导入的类首次创建一个对象时(或者访问一个类的static 成员时),编译器会在适当的目录里寻找同名的.class 文件(所以如果创建类X 的一个对象,就应该是X.class)。若只发现X.class,它就是必须使用的那一个类。然而,如果它在相同的目录中还发现了一个X.java,编译器就会比较两个文件的日期标记。如果X.java 比X.class 新,就会自动编译X.java,生成一个最新的X.class。
对于一个特定的类,或在与它同名的.java 文件中没有找到它,就会对那个类采取上述的处理。 -
冲突
若通过*导入了两个库,而且它们包括相同的名字,则需通过包名 类的方式进行声明
例:java.util.Vector v = new java.util.Vector();
5.1.2 自定义工具库
5.1.3 利用导入改变行为
如果想使用这个类,可在自己的程序中加入下面这一行:
import com.bruceeckel.tools.debug.*;
通过改变导入的package,我们可将自己的代码从调试版本变成最终的发行版本。这种技术可应用于任何种类的条件代码。
5.1.4 包的停用
每次创建一个包后,都在为包取名时间接地指定了一个目录结构。这个包必须存在(驻留)于由它的名字规定的目录内。而且这个目录必须能从CLASSPATH 开始搜索并发现。最开始的时候,package 关键字的运用可能会令人迷惑,因为除非坚持遵守根据目录路径指定包名的规则,否则就会在运行期获得大量莫名其妙的消息,指出找不到一个特定的类
5.2 Java 访问指示符
针对类内每个成员的每个定义,Java 访问指示符public,protected 以及private 都置于它们的最前面——无论它们是一个数据成员,还是一个方法。每个访问指示符都只控制着对那个特定定义的访问。
5.2.1 “友好的”
java8中加入default关键字,无需再使用“Friendly”概念
不加访问修饰符,表示包级可见
5.2.2 public:接口访问
使用public 关键字时,它意味着紧随在public 后面的成员声明适用于所有人,特别是适用于使用库的客户程序员。
5.2.3 private:不能接触
private可以修饰数据成员,构造方法,方法成员,不能修饰类(此处指外部类,不考虑内部类)。
private 关键字意味着除非那个特定的类,而且从那个类的方法里,否则没有人能访问那个成员。同一个包内的其他成员不能访问private 成员。所以private 允许我们自由地改变那个成员,同时毋需关心它是否会影响同一个包内的另一个类。
5.2.4 protected:“友好的一种”
protected可以修饰数据成员,构造方法,方法成员,不能修饰类(此处指外部类,不考虑内部类)。被protected修饰的成员,能在定义它们的类中,同包 的类中被调用。如果有不同包的类想调用它们,那么这个类必须是定义它们的类 的子类。
5.3 接口与实现
我们通常认为访问控制是“隐藏实施细节”的一种方式。将数据和方法封装到类内后,可生成一种数据类型,它具有自己的特征与行为。但由于两方面重要的原因,访问为那个数据类型加上了自己的边界。第一个原因是规定客户程序员哪些能够使用,哪些不能。我们可在结构里构建自己的内部机制,不用担心客户程序员将其当作接口的一部分,从而自由地使用或者“滥用”。
5.4 类访问
在Java 中,亦可用访问指示符判断出一个库内的哪些类可由那个库的用户使用。若想一个类能由客户程序员调用,可在类主体的起始花括号前面某处放置一个public 关键字。它控制着客户程序员是否能够创建属于这个类的一个对象。
为控制一个类的访问,指示符必须在关键字class 之前出现。所以我们能够使用:
一个class文件中,只能有一个public类。
第 6 章 类再生
存在继承的情况下,初始化顺序为:
- 父类(静态变量、静态语句块)
- 子类(静态变量、静态语句块)
- 父类(实例变量、普通语句块)
- 父类(构造函数)
- 子类(实例变量、普通语句块)
- 子类(构造函数)
在新类里简单地创建原有类的对象。我们把这种方法叫作“合成”,因为新类由现有类的对象合并而成。我们只是简单地重复利用代码的功能,而不是采用它的形式。
第二种方法则显得稍微有些技巧。它创建一个新类,将其作为现有类的一个“类型”。我们可以原样采取现有类的形式,并在其中加入新代码,同时不会对现有的类产生影响。这种魔术般的行为叫作“继承”(Inheritance),涉及的大多数工作都是由编译器完成的。对于面向对象的程序设计,“继承”是最重要的基础概念之一。
6.1 合成的语法
为进行合成,我们只需在新类里简单地置入对象句柄即可。
编译器并不只是为每个句柄创建一个默认对象,因为那样会在许多情况下招致不必要的开销。如希望句柄得到初始化,可在下面这些地方进行:
(1) 在对象定义的时候。这意味着它们在构建器调用之前肯定能得到初始化。
(2) 在那个类的构建器中。
(3) 紧靠在要求实际使用那个对象之前。这样做可减少不必要的开销——假如对象并不需要创建的话。
如果不在定义时进行初始化,仍然不能保证能在将一条消息发给一个对象句柄之前会执行任何初始化——除非出现不可避免的运行期违例。
6.2 继承的语法
需要继承的时候,我们会说:“这个新类和那个旧类差不多。”为了在代码里表面这一观念,需要给出类名。但在类主体的起始花括号之前,需要放置一个关键字extends,在后面跟随“基础类”的名字。若采取这种做法,就可自动获得基础类的所有数据成员以及方法。
通常建议大家象这样进行编写代码,使自己的测试代码能够封装到类内。即便在程序中含有数量众多的类,但对于在命令行请求的public 类,只有main()才会得到调用。所以在这种情况下,当我们使用“java Detergent”的时候,调用的是Degergent.main()——即使Cleanser 并非一个public 类。采用这种将main()置入每个类的做法,可方便地为每个类都进行单元测试。而且在完成测试以后,毋需将main()删去;可把它保留下来,用于以后的测试。
6.2.1 初始化基类
由于这儿涉及到两个类——基础类及衍生类,而不再是以前的一个。
从外部看,似乎新类拥有与基础类相同的接口,而且可包含一些额外的方法和字段。但继承并非仅仅简单地复制基础类的接口了事。创建衍生类的一个对象时,它在其中包含了基础类的一个“子对象”。这个子对象就象我们根据基础类本身创建了它的一个对象。从外部看,基础类的子对象已封装到衍生类的对象里了。
通过调用基础类构建器,有足够的能力和权限来执行对基础类的初始化。在衍生类的构建器中,Java 会自动插入对基础类构建器的调用。
可以看出,构建是在基础类的“外部”进行的,所以基础类会在衍生类访问它之前得到正确的初始化。
即使没有为Cartoon()创建一个构建器,编译器也会为我们自动合成一个默认构建器,并发出对基础类构建器的调用。
6.3 合成与继承的结合
尽管编译器会强迫我们对基础类进行初始化,并要求我们在构建器最开头做这一工作,但它并不会监视我们是否正确初始化了成员对象。所以对此必须特别加以留意。
6.3.1 确保正确的清除
垃圾收集器大多数时候都能很好地工作,但在某些情况下,我们的类可能在自己的存在时期采取一些行动,而这些行动要求必须进行明确的清除工作。正如第4 章已经指出的那样,我们并不知道垃圾收集器什么时候才会显身,或者说不知它何时会调用。所以一旦希望为一个类清除什么东西,必须写一个特别的方法,明确、专门地来做这件事情。同时,还要让客户程序员知道他们必须调用这个方法。而在所有这一切的后面,就如第9 章(违例控制)要详细解释的那样,必须将这样的清除代码置于一个finally 从句中,从而防范任何可能出现的违例事件。
1.垃圾收集的顺序
不能指望自己能确切知道何时会开始垃圾收集。垃圾收集器可能永远不会得到调用。即使得到调用,它也可能以自己愿意的任何顺序回收对象。除内存的回收以外,其他任何东西都最好不要依赖垃圾收集器进行回收。若想明确地清除什么,请制作自己的清除方法,而且不要依赖finalize()。
6.3.2 名字的隐藏
如果Java 基础类有一个方法名被“过载”使用多次,在衍生类里对那个方法名的重新定义就不会隐藏任何基础类的版本。所以无论方法在这一级还是在一个基础类中定义,过载都会生效。
很少会用与基础类里完全一致的签名和返回类型来覆盖同名的方法,否则会使人
感到迷惑
6.4 到底选择合成还是继承
如果想利用新类内部一个现有类的特性,而不想使用它的接口,通常应选择合成。也就是说,我们可嵌入一个对象,使自己能用它实现新类的特性。但新类的用户会看到我们已定义的接口,而不是来自嵌入对象的接口。考虑到这种效果,我们需在新类里嵌入现有类的private 对象。
有些时候,我们想让类用户直接访问新类的合成。也就是说,需要将成员对象的属性变为 public。成员对象会将自身隐藏起来,所以这是一种安全的做法。
“属于”关系是用继承来表达的,而“包含”关系是用合成来表达的。
6.5 protected
我们采取的最好的做法是保持成员的 private 状态——无论如何都应保留对基础的实施细节进行修改的权利。在这一前提下,可通过 protected 方法允许类的继承者进行受到控制的访问。
6.6 积累开发
继承的一个好处是它支持“累积开发”,允许我们引入新的代码,同时不会为现有代码造成错误。这样可将新错误隔离到新代码里。通过从一个现成的、功能性的类继承,同时增添成员新的数据成员及方法(并重新定义现有方法),我们可保持现有代码原封不动(另外有人也许仍在使用它),不会为其引入自己的编程错误。
尽管继承是一种非常有用的技术,但在某些情况下,特别是在项目稳定下来以后,仍然需要从新的角度考察自己的类结构,将其收缩成一个更灵活的结构。
6.7 上溯造型
继承最值得注意的地方就是它没有为新类提供方法。继承是对新类和基础类之间的关系的一种表达。
6.7.1 何谓“上溯造型”?
类继承图的画法是根位于最顶部,再逐渐向下扩展(当然,可根据自己的习惯用任何方法描绘这种图)。由于造型的方向是从衍生类到基础类,箭头朝上,所以通常把它叫作“上溯造型”,即 Upcasting。上溯造型肯定是安全的,因为我们是从一个更特殊的类型到一个更常规的类型。
进行上溯造型的时候,类接口可能出现的唯一一个问题是它可能丢失方法,而不是赢得这些方法。
6.8 final 关键字
1. 数据
声明数据为常量,可以是编译时常量,也可以是在运行时被初始化后不能被改变的常量。
- 对于基本类型,final 使数值不变;
- 对于引用类型,final 使引用不变,也就不能引用其它对象,但是被引用的对象本身是可以修改的。
final int x = 1;
// x = 2; // cannot assign value to final variable 'x'
final A y = new A();
y.a = 1;
2. 方法
声明方法不能被子类重写。
private 方法隐式地被指定为 final,如果在子类中定义的方法和基类中的一个 private 方法签名相同,此时子类的方法不是重写基类方法,而是在子类中定义了一个新的方法。
3. 类
声明类不允许被继承。
它最一般的意思就是声明“这个东西不能改变”。之所以要禁止改变,可能是考虑到两方面的因素:设计或效率。
6.8.1 final 数据
在 Java 中,这些形式的常数必须属于基本数据类型(Primitives),而且要用final 关键字进行表达。在对这样的一个常数进行定义的时候,必须给出一个值。
对于基本数据类型,final 会将值变成一个常数;但对于对象句柄,final 会将句柄变成一个常数。进行声明时,必须将句柄初始化到一个具体的对象。而且永远不能将句柄变成指向另一个对象。然而,对象本身是可以修改的。
Java 允许我们创建“空白 final”,它们属于一些特殊的字段。尽管被声明成 final,但却未得到一个初始值。无论在哪种情况下,空白 final 都必须在实际使用前得到正确的初始化。而且编译器会主动保证这一规定得以贯彻。
Java 允许我们将自变量设成 final 属性,方法是在自变量列表中对它们进行适当的声明。这意味着在一个方法的内部,我们不能改变自变量句柄指向的东西。
6.8.2 final 方法
之所以要使用 final 方法,可能是出于对两方面理由的考虑。第一个是为方法“上锁”,防止任何继承类改变它的本来含义。设计程序时,若希望一个方法的行为在继承期间保持不变,而且不可被覆盖或改写,就可以采取这种做法。
采用final 方法的第二个理由是程序执行的效率。将一个方法设成 final 后,编译器就可以把对那个方法的所有调用都置入“嵌入”调用里。只要编译器发现一个 final 方法调用,就会(根据它自己的判断)忽略为执行方法调用机制而采取的常规代码插入方法。通常,只有在方法的代码量非常少,或者想明确禁止方法被覆盖的时候,才应考虑将一个方法设为 final。
类内所有private 方法都自动成为final。
6.8.3 final 类
如果说整个类都是final(在它的定义前冠以final 关键字),就表明自己不希望从这个类继承,或者不允许其他任何人采取这种操作。将类定义成final 后,结果只是禁止进行继承——没有更多的限制。
6.8.4 final 的注意事项
若将一个方法定义成final,就可能杜绝了在其他程序员的项目中对自己的类进行继承的途径,因为我们根本没有想到它会象那样使用。
6.9 初始化和类装载
首次使用的地方也是 static 初始化发生的地方。装载的时候,所有 static 对象和 static 代码块都会按照本来的顺序初始化(亦即它们在类定义代码里写入的顺序)。当然,static 数据只会初始化一次。
6.9.1 继承初始化
存在继承的情况下,初始化顺序为:
- 父类(静态变量、静态语句块)
- 子类(静态变量、静态语句块)
- 父类(实例变量、普通语句块)
- 父类(构造函数)
- 子类(实例变量、普通语句块)
- 子类(构造函数)
运行Java 时,发生的第一件事情是装载程序到外面找到那个类。在装载过程中,装载程序注意它有一个基础类(即extends 关键字要表达的意思),所以随之将其载入。无论是否准备生成那个基础类的一个对象,这个过程都会发生。
若基础类含有另一个基础类,则另一个基础类随即也会载入,以此类推。接下来,会在根基础类(此时是Insect)执行static 初始化,再在下一个衍生类执行,以此类推。保证这个顺序是非常关键的,因为衍生类的初始化可能要依赖于对基础类成员的正确初始化。
第 7 章 多形性
“对于面向对象的程序设计语言,多型性(多态)是第三种最基本的特征(前两种是数据抽象和继承)。”
利用具有多形性的方法调用,一种类型可将自己与另一种相似的类型区分开,只要它们都是从相同的基础类型中衍生出来的。这种区分是通过各种方法在行为上的差异实现的,可通过基础类实现对那些方法的调用。
7.1 上溯造型
上溯造型 父类指向子类
父类=====>子类-----(上溯造型)
class Father {
public int i = 1;
public void say(){
System.out.println("我是爸爸");
}
}
class Son extends Father{
public void say(){
System.out.println("我是儿子");
}
}
public class Test {
public static void main(String[] args) {
Father f = new Son();
System.out.println(f.i);
f.say();
}
}
结果:
1
我是儿子
下溯造型 父类转子类
public class Test {
public static void main(String[] args) {
Father f = new Son();
Son son = (Son)f;
son.say();
}
}
结果:
我是儿子
7.1.1 为什么要上溯造型
假如只写一个方法,将基础类作为自变量或参数使用,而不是使用那些特定的衍生类,岂不是会简单得多?也就是说,如果我们能不顾衍生类,只让自己的代码与基础类打交道,那么省下的工作量将是难以估计的。
7.2 深入理解
7.2.1 方法调用的绑定
将一个方法调用同一个方法主体连接到一起就称为“绑定”(Binding)。
若一种语言实现了后期绑定,同时必须提供一些机制,可在运行期间判断对象
的类型,并分别调用适当的方法。也就是说,编译器此时依然不知道对象的类型,但方法调用机制能自己去调查,找到正确的方法主体。
Java 中绑定的所有方法都采用后期绑定技术,除非一个方法已被声明成final。这意味着我们通常不必决定是否应进行后期绑定——它是自动发生的。
把一个方法声明成 final 能防止其他人覆盖那个方法。但也许更重要的一点是,它可有效地“关闭”动态绑定,或者告诉编译器不需要进行动态绑定。这样一来,编译器就可为final 方法调用生成效率更高的代码。
7.2.2 产生正确的行为
为了在编译的时候发出正确的调用,编译器毋需获得任何特殊的情报。
对draw()的所有调用都是通过动态绑定进行的。
7.2.3 扩展性
在一个设计良好的OOP 程序中,我们的大多数或者所有方法都会遵从tune()的模型,而且只与基础类接口通信。我们说这样的程序具有“扩展性”,因为可以从通用的基础类继承新的数据类型,从而新添一些功能。如果是为了适应新类的要求,那么对基础类接口进行操纵的方法根本不需要改变。
7.3 覆盖与过载
编译器允许我们对方法进行过载处理,使其不报告出错。但这种行为可能并不是我们所希望的。
“过载”是指同一样东西在不同的地方具有多种含义;而“覆盖”是指它随时随地都只有一种含义,只是原先的含义完全被后来的含义取代了。
7.4 抽象类和方法
抽象类和普通类最大的区别是,抽象类不能被实例化,需要继承抽象类才能实例化其子类。
若想通过该通用接口处理一系列类,就需要创建一个抽象类。对所有与基础类声明的签名相符的衍生类方法,都可以通过动态绑定机制进行调用。
Java 专门提供了一种机制,名为“抽象方法”。它属于一种不完整的方法,只含有一个声明,没有方法主体。下面是抽象方法声明时采用的语法:
abstract void X();
包含了抽象方法的一个类叫作“抽象类”。如果一个类里包含了一个或多个抽象方法,类就必须指定成abstract(抽象)。否则,编译器会向我们报告一条出错消息。
若一个抽象类是不完整的,那么一旦有人试图生成那个类的一个对象,编译器又会采取什么行动呢?由于不能安全地为一个抽象类创建属于它的对象,所以会从编译器那里获得一条出错提示。通过这种方法,编译器可保证抽象类的“纯洁性”,我们不必担心会误用它。
如果从一个抽象类继承,而且想生成新类型的一个对象,就必须为基础类中的所有抽象方法提供方法定义。如果不这样做(完全可以选择不做),则衍生类也会是抽象的,而且编译器会强迫我们用 abstract 关键字标志那个类的“抽象”本质。
即使不包括任何abstract 方法,亦可将一个类声明成“抽象类”。如果一个类没必要拥有任何抽象方法,而且我们想禁止那个类的所有实例,这种能力就会显得非常有用。
7.5 接口
接口是抽象类的延伸,在 Java 8 之前,它可以看成是一个完全抽象的类,也就是说它不能有任何的方法实现。
从 Java 8 开始,接口也可以拥有默认的方法实现,这是因为不支持默认方法的接口的维护成本太高了。在 Java 8 之前,如果一个接口想要添加新的方法,那么要修改所有实现了该接口的类。
接口的成员(字段 + 方法)默认都是 public 的,并且不允许定义为 private 或者 protected。
接口的字段默认都是 static 和 final 的。
比较
- 从设计层面上看,抽象类提供了一种 IS-A 关系,那么就必须满足里式替换原则,即子类对象必须能够替换掉所有父类对象。而接口更像是一种 LIKE-A 关系,它只是提供一种方法实现契约,并不要求接口和实现接口的类具有 IS-A 关系。
- 从使用上来看,一个类可以实现多个接口,但是不能继承多个抽象类。
- 接口的字段只能是 static 和 final 类型的,而抽象类的字段没有这种限制。
- 接口的成员只能是 public 的,而抽象类的成员可以有多种访问权限。
“interface”(接口)关键字使抽象的概念更深入了一层。我们可将其想象为一个“纯”抽象类。它允许创建者规定一个类的基本形式:方法名、自变量列表以及返回类型,但不规定方法主体。接口也包含了基本数据类型的数据成员,但它们都默认为static 和final。接口只提供一种形式,并不提供实施的细节。
为创建一个接口,请使用interface 关键字,而不要用class。与类相似,我们可在interface 关键字的前面增加一个public 关键字(但只有接口定义于同名的一个文件内);或者将其省略,营造一种“友好的”状态。
7.5.1 Java 的"多重继承"
Java 类只能单继承,但可以通过接口实现多重继承。
我们将所有接口名置于implements关键字的后面,并用逗号分隔它们。可根据需要使用多个接口,而且每个接口都会成为一个独立的类型,可对其进行上溯造型。
事实上,如果事先知道某种东西会成为基础类,那么第一个选择就是把它变成一个接口。只有在必须使用方法定义或者成员变量的时候,才应考虑采用抽象类。
7.5.2 通过继承扩展接口
利用继承技术,可方便地为一个接口添加新的方法声明,也可以将几个接口合并成一个新接口。在这两种情况下,最终得到的都是一个新接口。
通常,我们只能对单独一个类应用extends(扩展)关键字。但由于接口可能由多个其他接口构成,所以在构建一个新接口时,extends 可能引用多个基础接口。正如大家看到的那样,接口的名字只是简单地使用逗号分隔。
package com.lib.ThinkInJava.mutilExtends;
public interface Lethal {
void kill();
}
package com.lib.ThinkInJava.mutilExtends;
public interface Monster {
void destroy();
}
package com.lib.ThinkInJava.mutilExtends;
public interface Vampire extends Monster, Lethal {
void drinkBlood();
}
7.5.3 常数分组
由于置入一个接口的所有字段都自动具有 static 和 final 属性,所以接口是对常数值进行分组的一个好工具。
注意根据Java 命名规则,拥有固定标识符的static final 基本数据类型(亦即编译期常数)都全部采用大写字母(用下划线分隔单个标识符里的多个单词)。
接口中的字段会自动具备public 属性,所以没必要专门指定。
7.5.4 初始化接口中的字段
接口中定义的字段会自动具有 static 和 final 属性。它们不能是“空白 final ”,但可初始化成非常数表达式。
例如:
//: RandVals.java
// Initializing interface fields with
// non-constant initializers
import java.util.*;
public interface RandVals {
int rint = (int)(Math.random() * 10);
long rlong = (long)(Math.random() * 10);
float rfloat = (float)(Math.random() * 10);
double rdouble = Math.random() * 10;
}
由于字段是static 的,所以它们会在首次装载类之后、以及首次访问任何字段之前获得初始化。
7.6内部类
在 Java 中,可将一个类定义置入另一个类定义中,这就叫作“内部类”。
1.成员内部类
public class Main{
//成员变量
private String data = "数据";
//定义成员内部类
class Inner{
public void go(){
//可以访问外部类的private或静态成员变量
System.out.println(data);
}
}
}
需要注意的是, 当成员内部类拥有和外部类同名的成员变量或这方法时, 默认情况下访问的是内部类的成员, 如要访问外部类的同名成员, 需要使用以下形式:
外部类.this.成员变量外部类.this.成员方法
内部类是依附外部类而存在的, 也就是说要创建成员内部类的对象,前提是创建一个外部类的对象,创建成员内部类的方式如下:
new Main().new Inner();
成员内部类可以拥有private访问权限、protected访问权限、public访问权限、默认访问权限。如用private修饰,则只能在外部类的内部访问。
2.局部内部类
局部内部类是定义在一个方法或作用域中的类,它的访问权限仅限于方法内或作用域内。
public class Main{
public void go(){
//局部内部类
class Tt{
System.out.println("test");
}
//创建并调用方法
new Tt().print();
}
}
局部内部类也可以返回,像这样:
public class Main{
public Runnable go(){
class Tt implements Runnable{
@override
public void run(){
//TODO 自动生成的方法存根
System.out.println("run");
}
}
//创建并调用方法
return new Tt();
}
}
3.匿名内部类
匿名内部类应该是我们平常使用最多的了,如下面创建线程:
public class Main{
public void go(){
new Thread(new Runnable(){
/*
* 当前类为匿名内部类
*/
@override
public void run(){
//TODO 自动生成的方法存根
}
}).start();
}
}
匿名内部类在编译的时候有系统自动起名:Main$1
匿名内部类是没有构造器的类,大部分用于继承其他类或实现接口,并不需要增加额外的方法,只是对继承方法的实现或是重写
4.静态内部类
静态内部类也是定义在另一个类里面的类,只不过在类前加上了static。静态内部类是不需要依赖于外部类的,与静态成员变量类似。
public class Main{
//静态内部类
static class Inner{
public void go(){
System.out.println("test");
}
}
}
外部创建该静态类时可以如下创建:
Main.Inner mi = new Main Inner();
内部类其实拥有外部类的一个引用,在构造函数中将外部类的引用传递进来。
匿名内部类为什么只能访问局部的final变量?
其实可以这样想,当方法执行完毕后,局部变量的生命周期就结束了,而局部内部类对象的生命周期可能还没有结束,那么在局部内部类中访问局部变量就不可能了,所以将局部变量改为final,改变其生命周期。
7.6.1 内部类和上溯造型
当我们准备上溯造型到一个基础类(特别是到一个接口)的时候,内部类就开始发挥其关键作用(从用于实现的对象生成一个接口句柄具有与上溯造型至一个基础类相同的效果)。这是由于内部类随后可完全进入不可见或不可用状态——对任何人都将如此。所以我们可以非常方便地隐藏实施细节。我们得到的全部回报就是一个基础类或者接口的句柄,而且甚至有可能不知道准确的类型。
7.6.2 方法和作用域中的内部类
若试图定义一个匿名内部类,并想使用在匿名内部类外部定义的一个对象,则编译器要求外部对象为 final 属性。
7.6.3链接到外部类
创建自己的内部类时,那个类的对象同时拥有指向封装对象(这些对象封装或生成了内部类)的一个链接。所以它们能访问那个封装对象的成员——毋需取得任何资格。除此以外,内部类拥有对封装类所有元素的访问权限。
7.6.4 static 内部类
static 内部类意味着:
(1) 为创建一个 static 内部类的对象,我们不需要一个外部类对象。
(2) 不能从 static 内部类的一个对象中访问一个外部类对象。
但在存在一些限制:由于 static 成员只能位于一个类的外部级别,所以内部类不可拥有 static 数据或 static 内部类。
倘若为了创建内部类的对象而不需要创建外部类的一个对象,那么可将所有东西都设为 static。为了能正常工作,同时也必须将内部类设为 static。
7.6.5 引用外部类对象
若想生成外部类对象的句柄,就要用一个点号以及一个this 来命名外部类。
7.6.6 从内部类继承
//: InheritInner.java
// Inheriting an inner class
class WithInner {
class Inner {}
}
public class InheritInner
extends WithInner.Inner {
//! InheritInner() {} // Won't compile
InheritInner(WithInner wi) {
wi.super();
}
public static void main(String[] args) {
WithInner wi = new WithInner();
InheritInner ii = new InheritInner(wi);
}
}
从中可以看到,InheritInner 只对内部类进行了扩展,没有扩展外部类。但在需要创建一个构建器的时候,默认对象已经没有意义,我们不能只是传递封装对象的一个句柄。此外,必须在构建器中采用下述语法:
enclosingClassHandle.super();
它提供了必要的句柄,以便程序正确编译。
7.6.7 内部类可以被覆盖吗?
如果创建了一个内部类,然后继承其外围类并重新定义内部类时,"覆盖"内部类就好像是其外围类的一个方法,并不起作用,
这两个内部类是完全独立的两个实体,各自在自己的命名空间内
//: innerclasses/BigEgg.java
// An inner class cannot be overriden like a method.
import static net.mindview.util.Print.*;
class Egg {
private Yolk y;
protected class Yolk {
public Yolk() { print("Egg.Yolk()"); }
}
public Egg() {
print("New Egg()");
y = new Yolk();
}
}
public class BigEgg extends Egg {
public class Yolk {
public Yolk() { print("BigEgg.Yolk()"); } //这里并没有输出
}
public static void main(String[] args) {
new BigEgg();
}
} /* Output:
New Egg()
Egg.Yolk()
*///:~
当然,明确的继承某个内部类也是可以的
//: innerclasses/BigEgg2.java
// Proper inheritance of an inner class.
import static net.util.Print.*;
class Egg2 {
protected class Yolk {
public Yolk() { print("Egg2.Yolk()"); }
public void f() { print("Egg2.Yolk.f()");}
}
private Yolk y = new Yolk();
public Egg2() { print("New Egg2()"); }
public void insertYolk(Yolk yy) { y = yy; }
public void g() { y.f(); }
}
public class BigEgg2 extends Egg2 {
public class Yolk extends Egg2.Yolk { //通过继承明确的继承了Egg2.Yolk类,并覆盖了其中的方法
public Yolk() { print("BigEgg2.Yolk()"); }
public void f() { print("BigEgg2.Yolk.f()"); }
}
public BigEgg2() { insertYolk(new Yolk()); }//向上转型成Egg2.Yolk类
public static void main(String[] args) {
Egg2 e2 = new BigEgg2();
e2.g();
}
} /* Output:
Egg2.Yolk()
New Egg2()
Egg2.Yolk()
BigEgg2.Yolk()
BigEgg2.Yolk.f()
*///:~
7.6.8 内部类标识符
由于每个类都会生成一个.class 文件,用于容纳与如何创建这个类型的对象有关的所有信息(这种信息产生了一个名为Class 对象的元类),所以大家或许会猜到内部类也必须生成相应的.class 文件,用来容纳与它们的Class 对象有关的信息。这些文件或类的名字遵守一种严格的形式:先是封装类的名字,再跟随一个 , 再 跟 随 内 部 类 的 名 字 。 例 如 , 由 I n h e r i t I n n e r . j a v a 创 建 的 . c l a s s 文 件 包 括 : I n h e r i t I n n e r . c l a s s W i t h I n n e r ,再跟随内部类的名字。例如,由InheritInner.java 创建的.class 文件包括: InheritInner.class WithInner ,再跟随内部类的名字。例如,由InheritInner.java创建的.class文件包括:InheritInner.classWithInnerInner.class
WithInner.class
如果内部类是匿名的,那么编译器会简单地生成数字,把它们作为内部类标识符使用。若内部类嵌套于其他内部类中,则它们的名字简单地追加在一个$以及外部类标识符的后面。
7.6.9 为什么要用内部类:控制框架
一个“应用程序框架”是指一个或一系列类,它们专门设计用来解决特定类型的问题。为应用应用程序框架,我们可从一个或多个类继承,并覆盖其中的部分方法。我们在覆盖方法中编写的代码用于定制由那些应用程序框架提供的常规方案,以便解决自己的实际问题。“控制框架”属于应用程序框架的一种特殊类型,受到对事件响应的需要的支配;主要用来响应事件的一个系统叫作“由事件驱动的系统”。
7.7 构建器和多形性
同往常一样,构建器与其他种类的方法是有区别的。在涉及到多形性的问题后,这种方法依然成立。
7.7.1 构建器的调用顺序
用于基础类的构建器肯定在一个衍生类的构建器中调用,而且逐渐向上链接,使每个基础类使用的构建器都能得到调用。之所以要这样做,是由于构建器负有一项特殊任务:检查对象是否得到了正确的构建。一个衍生类只能访问它自己的成员,不能访问基础类的成员(这些成员通常都具有private 属性)。只有基础类的构建器在初始化自己的元素时才知道正确的方法以及拥有适当的权限。所以,必须令所有构建器都得到调用,否则整个对象的构建就可能不正确。
在衍生类的构建器主体中,若我们没有明确指定对一个基础类构建器的调用,它就会“默默”地调用默认构建器。如果不存在默认构建器,编译器就会报告一个错误.
是首先调用基础类构建器。然后在进入衍生类构建器以后,我们在基础类能够访问的所有成员都已得到初始化。
7.7.2 继承和 finalize()
在进行初始化的时候,必须覆盖衍生类中的finalize()方法——如果已经设计了某个特殊的清除进程,要求它必须作为垃圾收集的一部分进行。覆盖衍生类的finalize()时,务必记住调用finalize()的基础类版本。否则,基础类的初始化根本不会发生。
7.7.3 构建器内部的多形性方法的行为
从概念上讲,构建器的职责是让对象实际进入存在状态。在任何构建器内部,整个对象可能只是得到部分组织——我们只知道基础类对象已得到初始化,但却不知道哪些类已经继承。然而,一个动态绑定的方法调用却会在分级结构里“向前”或者“向外”前进。它调用位于衍生类里的一个方法。如果在构建器内部做这件事情,那么对于调用的方法,它要操纵的成员可能尚未得到正确的初始化——这显然不是我们所希望的。
7.8 通过继承进行设计
事实上,当我们以一个现成类为基础建立一个新类时,如首先选择继承,会使情况变得异常复杂。
一个更好的思路是首先选择“合成”——如果不能十分确定自己应使用哪一个。合成不会强迫我们的程序设计进入继承的分级结构中。同时,合成显得更加灵活,因为可以动态选择一种类型(以及行为),而继承要求在编译期间准确地知道一种类型。
7.8.1 纯继承与扩展
学习继承时,为了创建继承分级结构,看来最明显的方法是采取一种“纯粹”的手段。也就是说,只有在基础类或“接口”中已建立的方法才可在衍生类中被覆盖。
经过细致的研究,我们发现扩展接口对于一些特定问题来说是特别有效的方案。可将其称为“类似于”关系,因为扩展后的衍生类“类似于”基础类——它们有相同的基础接口——但它增加了一些特性,要求用额外的方法加以实现。
7.8.2 下溯造型与运行期类型标识
由于我们在上溯造型(在继承结构中向上移动)期间丢失了具体的类型信息,所以为了获取具体的类型信息——亦即在分级结构中向下移动——我们必须使用 “下溯造型”技术。
在Java 中,所有造型都会自动得到检查和核实!所以即使我们只是进行一次普通的括弧造型,进入运行期以后,仍然会毫无留情地对这个造型进行检查,保证它的确是我们希望的那种类型。如果不是,就会得到一个ClassCastException(类造型违例)。在运行期间对类型进行检查的行为叫作“运行期类型标识”(RTTI)。
第 8 章 对象的容纳
Java 提供了容纳对象(或者对象的句柄)的多种方式。其中内建的类型是数组,我们之前已讨论过它,本章准备加深大家对它的认识。此外,Java 的工具(实用程序)库提供了一些“集合类”(亦称作“容器类”,但该术语已由AWT 使用,所以这里仍采用“集合”这一称呼)。利用这些集合类,我们可以容纳乃至操纵自己的对象。
8.1 数组
有两方面的问题将数组与其他集合类型区分开来:效率和类型。对于Java 来说,为保存和访问一系列对象(实际是对象的句柄)数组,最有效的方法莫过于数组。数组实际代表一个简单的线性序列,它使得元素的访问速度非常快,但我们却要为这种速度付出代价:创建一个数组对象时,它的大小是固定的,而且不可在那个数组对象的“存在时间”内发生改变。可创建特定大小的一个数组,然后假如用光了存储空间,就再创建一个新数组,将所有句柄从旧数组移到新数组。这属于“矢量”(Vector)类的行为.
8.1.1 数组和第一类对象
无论使用的数组属于什么类型,数组标识符实际都是指向真实对象的一个句柄。那些对象本身是在内存“堆”里创建的。堆对象既可“隐式”创建(即默认产生),亦可“显式”创建(即明确指定,用一个new表达式)。
- 基本数据类型集合
集合类只能容纳对象句柄。但对一个数组,却既可令其直接容纳基本类型的数据,亦可容纳指向对象的句柄。利用象Integer、Double 之类的“封装器”类,可将基本数据类型的值置入一个集合里。
8.1.2 数组的返回
Java 采用的是类似的方法,但我们能“返回一个数组”。当然,此时返回的实际仍是指向数组的指针。但在Java 里,我们永远不必担心那个数组的是否可用——只要需要,它就会自动存在。而且垃圾收集器会在我们完成后自动将其清除。
8.2 集合
当我们编写程序时,通常并不能确切地知道最终需要多少个对象。有些时候甚至想用更复杂的方式来保存对象。为解决这个问题,Java 提供了四种类型的“集合类”:Vector(矢量)、BitSet(位集)、Stack(堆栈)以及 Hashtable(散列表)。
8.2.1 缺点:类型未知
使用Java 集合的“缺点”是在将对象置入一个集合时丢失了类型信息。之所以会发生这种情况,是由于当初编写集合时,那个集合的程序员根本不知道用户到底想把什么类型置入集合。
8.3 枚举器(反复器)
在任何集合类中,必须通过某种方法在其中置入对象,再用另一种方法从中取得对象。毕竟,容纳各种各样的对象正是集合的首要任务。
假若最开始决定使用Vector,后来在程序中又决定(考虑执行效率的原因)改变成一个List,可利用“反复器”(Iterator)的概念达到这个目的。它可以是一个对象,作用是遍历一系列对象,并选择那个序列中的每个对象,同时不让客户程序员知道或关注那个序列的基础结构。
Java中的Iterator功能比较简单,并且只能单向移动:
(1) 使用方法iterator()要求容器返回一个Iterator。第一次调用Iterator的next()方法时,它返回序列的第一个元素。注意:iterator()方法是java.lang.Iterable接口,被Collection继承。
(2) 使用next()获得序列中的下一个元素。
(3) 使用hasNext()检查序列中是否还有元素。
(4) 使用remove()将迭代器新返回的元素删除。
Iterator是Java迭代器最简单的实现,为List设计的ListIterator具有更多的功能,它可以从两个方向遍历List,也可以从List中插入和删除元素。
8.4 集合的类型
8.4.1 Vector
Vector 可实现自动增长的对象数组。
java.util.vector提供了向量类(Vector)以实现类似动态数组的功能。
创建了一个向量类的对象后,可以往其中随意插入不同类的对象,即不需顾及类型也不需预先选定向量的容量,并可以方便地进行查找。
对于预先不知或者不愿预先定义数组大小,并且需要频繁地进行查找,插入,删除工作的情况,可以考虑使用向量类。
Vector 类支持 4 种构造方法。
第一种构造方法创建一个默认的向量,默认大小为 10:
Vector()
第二种构造方法创建指定大小的向量。
Vector(int size)
第三种构造方法创建指定大小的向量,并且增量用 incr 指定。增量表示向量每次增加的元素数目。
Vector(int size,int incr)
第四种构造方法创建一个包含集合 c 元素的向量:
Vector(Collection c)
除了从父类继承的方法外 Vector 还定义了以下方法:
| 序号 | 方法描述 |
|---|---|
| 1 | void add(int index, Object element) 在此向量的指定位置插入指定的元素。 |
| 2 | boolean add(Object o) 将指定元素添加到此向量的末尾。 |
| 3 | boolean addAll(Collection c) 将指定 Collection 中的所有元素添加到此向量的末尾,按照指定 collection 的迭代器所返回的顺序添加这些元素。 |
| 4 | boolean addAll(int index, Collection c) 在指定位置将指定 Collection 中的所有元素插入到此向量中。 |
| 5 | void addElement(Object obj) 将指定的组件添加到此向量的末尾,将其大小增加 1。 |
| 6 | int capacity() 返回此向量的当前容量。 |
| 7 | void clear() 从此向量中移除所有元素。 |
| 8 | Object clone() 返回向量的一个副本。 |
| 9 | boolean contains(Object elem) 如果此向量包含指定的元素,则返回 true。 |
| 10 | boolean containsAll(Collection c) 如果此向量包含指定 Collection 中的所有元素,则返回 true。 |
| 11 | void copyInto(Object[] anArray) 将此向量的组件复制到指定的数组中。 |
| 12 | Object elementAt(int index) 返回指定索引处的组件。 |
| 13 | Enumeration elements() 返回此向量的组件的枚举。 |
| 14 | void ensureCapacity(int minCapacity) 增加此向量的容量(如有必要),以确保其至少能够保存最小容量参数指定的组件数。 |
| 15 | boolean equals(Object o) 比较指定对象与此向量的相等性。 |
| 16 | Object firstElement() 返回此向量的第一个组件(位于索引 0) 处的项)。 |
| 17 | Object get(int index) 返回向量中指定位置的元素。 |
| 18 | int hashCode() 返回此向量的哈希码值。 |
| 19 | int indexOf(Object elem) 返回此向量中第一次出现的指定元素的索引,如果此向量不包含该元素,则返回 -1。 |
| 20 | int indexOf(Object elem, int index) 返回此向量中第一次出现的指定元素的索引,从 index 处正向搜索,如果未找到该元素,则返回 -1。 |
| 21 | void insertElementAt(Object obj, int index) 将指定对象作为此向量中的组件插入到指定的 index 处。 |
| 22 | boolean isEmpty() 测试此向量是否不包含组件。 |
| 23 | Object lastElement() 返回此向量的最后一个组件。 |
| 24 | int lastIndexOf(Object elem) 返回此向量中最后一次出现的指定元素的索引;如果此向量不包含该元素,则返回 -1。 |
| 25 | int lastIndexOf(Object elem, int index) 返回此向量中最后一次出现的指定元素的索引,从 index 处逆向搜索,如果未找到该元素,则返回 -1。 |
| 26 | Object remove(int index) 移除此向量中指定位置的元素。 |
| 27 | boolean remove(Object o) 移除此向量中指定元素的第一个匹配项,如果向量不包含该元素,则元素保持不变。 |
| 28 | boolean removeAll(Collection c) 从此向量中移除包含在指定 Collection 中的所有元素。 |
| 29 | void removeAllElements() 从此向量中移除全部组件,并将其大小设置为零。 |
| 30 | boolean removeElement(Object obj) 从此向量中移除变量的第一个(索引最小的)匹配项。 |
| 31 | void removeElementAt(int index) 删除指定索引处的组件。 |
| 32 | protected void removeRange(int fromIndex, int toIndex) 从此 List 中移除其索引位于 fromIndex(包括)与 toIndex(不包括)之间的所有元素。 |
| 33 | boolean retainAll(Collection c) 在此向量中仅保留包含在指定 Collection 中的元素。 |
| 34 | Object set(int index, Object element) 用指定的元素替换此向量中指定位置处的元素。 |
| 35 | void setElementAt(Object obj, int index) 将此向量指定 index 处的组件设置为指定的对象。 |
| 36 | void setSize(int newSize) 设置此向量的大小。 |
| 37 | int size() 返回此向量中的组件数。 |
| 38 | List subList(int fromIndex, int toIndex) 返回此 List 的部分视图,元素范围为从 fromIndex(包括)到 toIndex(不包括)。 |
| 39 | Object[] toArray() 返回一个数组,包含此向量中以恰当顺序存放的所有元素。 |
| 40 | Object[] toArray(Object[] a) 返回一个数组,包含此向量中以恰当顺序存放的所有元素;返回数组的运行时类型为指定数组的类型。 |
| 41 | String toString() 返回此向量的字符串表示形式,其中包含每个元素的 String 表示形式。 |
| 42 | void trimToSize() 对此向量的容量进行微调,使其等于向量的当前大小。 |
在Enumeration中封装了有关枚举数据集合的方法。
方法 hasMoreElement()来判断集合中是否还有其他元素。
方法 nextElement()来获取下一个元素
以下代码就是用hasMoreElement()和 nextElement()遍历Vector:
import java.util.Enumeration;
import java.util.Iterator;
import java.util.List;
import java.util.Vector;
public class TestVector {
public void test01() {
Vector<String> hs = new Vector<String>();
hs.add("aa");
hs.add("bb");
hs.add("cc");
hs.add("dd");
printSet2(hs);
}
public void printSet(List hs) {
Iterator iterator = hs.iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next());
}
}
public void printSet2(Vector<String> hs) {
Enumeration<String> elements = hs.elements();
while (elements.hasMoreElements()) {
System.out.println(elements.nextElement());
}
}
public static void main(String[] args) {
new TestVector().test01();
}
}
/*
* 输出结果:
* aa
* bb
* cc
* dd
*/
8.4.2 BitSet
BitSet 实际是由“二进制位”构成的一个Vector。如果希望高效率地保存大量“开-关”信息,就应使用BitSet。它只有从尺寸的角度看才有意义;如果希望的高效率的访问,那么它的速度会比使用一些固有类型的数组慢一些。
BitSet的应用场景
海量数据去重、排序、压缩存储
BitSet的基本操作
and(与)、or(或)、xor(异或)
BitSet的优缺点
优点:
-
按位存储,内存占用空间小
-
丰富的api操作
缺点:
-
线程不安全
-
BitSet内部动态扩展long型数组,若数据稀疏会占用较大的内存
BitSet定义了两个构造方法。
第一个构造方法创建一个默认的对象:
BitSet()
第二个方法允许用户指定初始大小。所有位初始化为0。
BitSet(int size)
BitSet中实现了Cloneable接口中定义的方法如下表所列:
| 序号 | 方法描述 |
|---|---|
| 1 | void and(BitSet set) 对此目标位 set 和参数位 set 执行逻辑与操作。 |
| 2 | void andNot(BitSet set) 清除此 BitSet 中所有的位,其相应的位在指定的 BitSet 中已设置。 |
| 3 | int cardinality( ) 返回此 BitSet 中设置为 true 的位数。 |
| 4 | void clear( ) 将此 BitSet 中的所有位设置为 false。 |
| 5 | void clear(int index) 将索引指定处的位设置为 false。 |
| 6 | void clear(int startIndex, int endIndex) 将指定的 startIndex(包括)到指定的 toIndex(不包括)范围内的位设置为 false。 |
| 7 | Object clone( ) 复制此 BitSet,生成一个与之相等的新 BitSet。 |
| 8 | boolean equals(Object bitSet) 将此对象与指定的对象进行比较。 |
| 9 | void flip(int index) 将指定索引处的位设置为其当前值的补码。 |
| 10 | void flip(int startIndex, int endIndex) 将指定的 fromIndex(包括)到指定的 toIndex(不包括)范围内的每个位设置为其当前值的补码。 |
| 11 | boolean get(int index) 返回指定索引处的位值。 |
| 12 | BitSet get(int startIndex, int endIndex) 返回一个新的 BitSet,它由此 BitSet 中从 fromIndex(包括)到 toIndex(不包括)范围内的位组成。 |
| 13 | int hashCode( ) 返回此位 set 的哈希码值。 |
| 14 | boolean intersects(BitSet bitSet) 如果指定的 BitSet 中有设置为 true 的位,并且在此 BitSet 中也将其设置为 true,则返回 true。 |
| 15 | boolean isEmpty( ) 如果此 BitSet 中没有包含任何设置为 true 的位,则返回 true。 |
| 16 | int length( ) 返回此 BitSet 的"逻辑大小":BitSet 中最高设置位的索引加 1。 |
| 17 | int nextClearBit(int startIndex) 返回第一个设置为 false 的位的索引,这发生在指定的起始索引或之后的索引上。 |
| 18 | int nextSetBit(int startIndex) 返回第一个设置为 true 的位的索引,这发生在指定的起始索引或之后的索引上。 |
| 19 | void or(BitSet bitSet) 对此位 set 和位 set 参数执行逻辑或操作。 |
| 20 | void set(int index) 将指定索引处的位设置为 true。 |
| 21 | void set(int index, boolean v) 将指定索引处的位设置为指定的值。 |
| 22 | void set(int startIndex, int endIndex) 将指定的 fromIndex(包括)到指定的 toIndex(不包括)范围内的位设置为 true。 |
| 23 | void set(int startIndex, int endIndex, boolean v) 将指定的 fromIndex(包括)到指定的 toIndex(不包括)范围内的位设置为指定的值。 |
| 24 | int size( ) 返回此 BitSet 表示位值时实际使用空间的位数。 |
| 25 | String toString( ) 返回此位 set 的字符串表示形式。 |
| 26 | void xor(BitSet bitSet) 对此位 set 和位 set 参数执行逻辑异或操作。 |
8.4.3 Stack
Stack 有时也可以称为“后入先出”(LIFO)集合。换言之,我们在堆栈里最后“压入”的东西将是以后第一个“弹出”的。和其他所有Java 集合一样,我们压入和弹出的都是“对象”,所以必须对自己弹出的东西进行“造型”。
栈是Vector的一个子类,它实现了一个标准的后进先出的栈。
堆栈只定义了默认构造函数,用来创建一个空栈。 堆栈除了包括由Vector定义的所有方法,也定义了自己的一些方法。
Stack()
除了由Vector定义的所有方法,自己也定义了一些方法:
| 序号 | 方法描述 |
|---|---|
| 1 | boolean empty() 测试堆栈是否为空。 |
| 2 | Object peek( ) 查看堆栈顶部的对象,但不从堆栈中移除它。 |
| 3 | Object pop( ) 移除堆栈顶部的对象,并作为此函数的值返回该对象。 |
| 4 | Object push(Object element) 把项压入堆栈顶部。 |
| 5 | int search(Object element) 返回对象在堆栈中的位置,以 1 为基数。 |
8.4.4 Hashtable
Hashtable是原始的java.util的一部分, 是一个Dictionary具体的实现 。
然而,Java 2 重构的Hashtable实现了Map接口,因此,Hashtable现在集成到了集合框架中。它和HashMap类很相似,但是它支持同步。
像HashMap一样,Hashtable在哈希表中存储键/值对。当使用一个哈希表,要指定用作键的对象,以及要链接到该键的值。
然后,该键经过哈希处理,所得到的散列码被用作存储在该表中值的索引。
Hashtable定义了四个构造方法。第一个是默认构造方法:
Hashtable()
第二个构造函数创建指定大小的哈希表:
Hashtable(int size)
第三个构造方法创建了一个指定大小的哈希表,并且通过fillRatio指定填充比例。
填充比例必须介于0.0和1.0之间,它决定了哈希表在重新调整大小之前的充满程度:
Hashtable(int size,float fillRatio)
第四个构造方法创建了一个以M中元素为初始化元素的哈希表。
哈希表的容量被设置为M的两倍。
Hashtable(Map m)
Hashtable中除了从Map接口中定义的方法外,还定义了以下方法:
| 序号 | 方法描述 |
|---|---|
| 1 | void clear( ) 将此哈希表清空,使其不包含任何键。 |
| 2 | Object clone( ) 创建此哈希表的浅表副本。 |
| 3 | boolean contains(Object value) 测试此映射表中是否存在与指定值关联的键。 |
| 4 | boolean containsKey(Object key) 测试指定对象是否为此哈希表中的键。 |
| 5 | boolean containsValue(Object value) 如果此 Hashtable 将一个或多个键映射到此值,则返回 true。 |
| 6 | Enumeration elements( ) 返回此哈希表中的值的枚举。 |
| 7 | Object get(Object key) 返回指定键所映射到的值,如果此映射不包含此键的映射,则返回 null. 更确切地讲,如果此映射包含满足 (key.equals(k)) 的从键 k 到值 v 的映射,则此方法返回 v;否则,返回 null。 |
| 8 | boolean isEmpty( ) 测试此哈希表是否没有键映射到值。 |
| 9 | Enumeration keys( ) 返回此哈希表中的键的枚举。 |
| 10 | Object put(Object key, Object value) 将指定 key 映射到此哈希表中的指定 value。 |
| 11 | void rehash( ) 增加此哈希表的容量并在内部对其进行重组,以便更有效地容纳和访问其元素。 |
| 12 | Object remove(Object key) 从哈希表中移除该键及其相应的值。 |
| 13 | int size( ) 返回此哈希表中的键的数量。 |
| 14 | String toString( ) 返回此 Hashtable 对象的字符串表示形式,其形式为 ASCII 字符 ", " (逗号加空格)分隔开的、括在括号中的一组条目。 |
8.4.5 再论枚举器
我们现在可以开始演示Enumeration(枚举)的真正威力:将穿越一个序列的操作与那个序列的基础结构分隔开。
//: Enumerators2.java
// Revisiting Enumerations
import java.util.*;
class PrintData {
static void print(Enumeration e) {
while(e.hasMoreElements())
System.out.println(
e.nextElement().toString());
}
}
class Enumerators2 {
public static void main(String[] args) {
Vector v = new Vector();
for(int i = 0; i < 5; i++)
v.addElement(new Mouse(i));
Hashtable h = new Hashtable();
for(int i = 0; i < 5; i++)
h.put(new Integer(i), new Hamster(i));
System.out.println("Vector");
PrintData.print(v.elements());
System.out.println("Hashtable");
PrintData.print(h.elements());
}
} ///:~
8.5 排序
Java 1.0 和1.1 库都缺少的一样东西是算术运算,甚至没有最简单的排序运算方法。因此,我们最好创建一个Vector,利用经典的Quicksort(快速排序)方法对其自身进行排序。
java集合的工具类Collections中提供了两种排序的方法,分别是:
- Collections.sort(List list)
- Collections.sort(List list,Comparator c)
第一种称为自然排序,参与排序的对象需实现comparable接口,重写其compareTo()方法,方法体中实现对象的比较大小规则,示例如下:
实体类:(基本属性,getter/setter方法,有参无参构造方法,toString方法)
package test;
public class Emp implements Comparable {
private String name;
private int age;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public Emp() {
super();
}
public Emp(String name, int age) {
super();
this.name = name;
this.age = age;
}
@Override
public String toString() {
return "Emp [name=" + name + ", age=" + age + "]";
}
@Override
public int compareTo(Object o) {
if(o instanceof Emp){
Emp emp = (Emp) o;
// return this.age-emp.getAge();//按照年龄升序排序
return this.name.compareTo(emp.getName());//换姓名升序排序
}
throw new ClassCastException("不能转换为Emp类型的对象...");
}
}
第二种叫定制排序,或自定义排序,需编写匿名内部类,先new一个Comparator接口的比较器对象c,同时实现compare()其方法; 然后将比较器对象c传给Collections.sort()方法的参数列表中,实现排序功能;
说明:第一种方法不够灵活,实体类实现了comparable接口后,会增加耦合,如果在项目中不同的位置需要根据不同的属性调用排序方法时,需要反复修改比较规则(按name还是按age),二者只能选择其一,会起冲突.第二种就很好地解决了这个问题.在需要的地方,创建个内部类的实例,重写其比较方法即可.
package test;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Comparator;
import java.util.List;
import org.junit.BeforeClass;
import org.junit.Test;
public class TestSort {
static List list = new ArrayList();
//@BeforeClass注解标注的方法会在其它测试方法执行之前先执行,
//且只执行一次.@Before注解标注的方法会在每个测试方法之前执行;
//此处初始化集合只需要一次,因此使用@BeforeClass.
@BeforeClass
public static void init(){
list.add(new Emp("tom",18));
list.add(new Emp("jack",20));
list.add(new Emp("rose",15));
list.add(new Emp("jerry",17));
System.out.println("排序前:");
for(Object o : list){
System.out.println(o);
}
}
/**按age升序排序*/
// @Test
// public void testSortAge(){
// Collections.sort(list);
// System.out.println("自然排序按age排序后:");
// for(Object o : list){
// System.out.println(o);
// }
// }
//
/**按name升序排序*/
@Test
public void testSortName(){
Collections.sort(list);
System.out.println("自然排序按name升序排序后:");
for(Object o : list){
System.out.println(o);
}
}
/**使用Comparator比较器按age升序排序*/
@Test
public void testComparatorSortAge(){
Collections.sort(list,new Comparator () {
@Override
public int compare(Object o1, Object o2) {
if(o1 instanceof Emp && o2 instanceof Emp){
Emp e1 = (Emp) o1;
Emp e2 = (Emp) o2;
return e1.getAge() - e2.getAge();
}
throw new ClassCastException("不能转换为Emp类型");
}
});
System.out.println("使用Comparator比较器按age升序排序后:");
for(Object o : list){
System.out.println(o);
}
}
/**使用Comparator比较器按name升序排序*/
@Test
public void testComparatorSortName(){
Collections.sort(list,new Comparator () {
@Override
public int compare(Object o1, Object o2) {
if(o1 instanceof Emp && o2 instanceof Emp){
Emp e1 = (Emp) o1;
Emp e2 = (Emp) o2;
return e1.getName().compareTo(e2.getName());
}
throw new ClassCastException("不能转换为Emp类型");
}
});
System.out.println("使用Comparator比较器按name升序排序后:");
for(Object o : list){
System.out.println(o);
}
}
}
运行结果如下:
排序前:
Emp [name=tom, age=18]
Emp [name=jack, age=20]
Emp [name=rose, age=15]
Emp [name=jerry, age=17]
自然排序按name升序排序后:
Emp [name=jack, age=20]
Emp [name=jerry, age=17]
Emp [name=rose, age=15]
Emp [name=tom, age=18]
使用Comparator比较器按age升序排序后:
Emp [name=rose, age=15]
Emp [name=jerry, age=17]
Emp [name=tom, age=18]
Emp [name=jack, age=20]
使用Comparator比较器按name升序排序后:
Emp [name=jack, age=20]
Emp [name=jerry, age=17]
Emp [name=rose, age=15]
Emp [name=tom, age=18]
8.6 通用集合库
ObjectSpace 公司设计了Java 版本的“通用集合库”(从前叫作“Java通用库”,即JGL;但JGL 这个缩写形式侵犯了Sun 公司的版权——尽管本书仍然沿用这个简称)。这个库尽可能遵照STL 的设计(照顾到两种语言间的差异)。JGL 实现了许多功能,可满足对一个集合库的大多数常规需求,它与C++的模板机制非常相似。JGL 包括相互链接起来的列表、设置、队列、映射、堆栈、序列以及反复器,它们的功能比Enumeration(枚举)强多了。同时提供了一套完整的算法,如检索和排序等。在某些方面,ObjectSpace 的设计也显得比Sun 的库设计方案“智能”一些。举个例子来说,JGL 集合中的方法不会进入final 状态,所以很容易继承和改写那些方法。
8.7 新集合
新的集合库考虑到了“容纳自己对象”的问题,并将其分割成两个明确的概念:
(1) 集合(Collection):一组单独的元素,通常应用了某种规则。在这里,一个List(列表)必须按特定的顺序容纳元素,而一个Set(集)不可包含任何重复的元素。相反,“包”(Bag)的概念未在新的集合库中实现,因为“列表”已提供了类似的功能。
(2) 映射(Map):一系列“键-值”对(这已在散列表身上得到了充分的体现)。从表面看,这似乎应该成为一个“键-值”对的“集合”,但假若试图按那种方式实现它,就会发现实现过程相当笨拙。这进一步证明了应该分离成单独的概念。另一方面,可以方便地查看Map 的某个部分。只需创建一个集合,然后用它表示那一部分即可。这样一来,Map 就可以返回自己键的一个Set、一个包含自己值的List 或者包含自己“键-值”对的一个List。和数组相似,Map 可方便扩充到多个“维”,毋需涉及任何新概念。只需简单地在一个Map 里包含其他Map(后者又可以包含更多的Map,以此类推)。
8.7.1 使用Collection
Collection和Collections的区别:
-
java.util.Collection 是一个集合接口。它提供了对集合对象进行基本操作的通用接口方法。Collection接口在Java 类库中有很多具体的实现。Collection接口的意义是为各种具体的集合提供了最大化的统一操作方式。
-
java.util.Collections 是一个包装类。它包含有各种有关集合操作的静态多态方法。此类不能实例化,就像一个工具类,服务于Java的Collection框架。
Collections提供以下方法对List进行排序操作
void reverse(List list):反转
void shuffle(List list),随机排序
void sort(List list),按自然排序的升序排序
void sort(List list, Comparator c);定制排序,由Comparator控制排序逻辑
void swap(List list, int i , int j),交换两个索引位置的元素
void rotate(List list, int distance),旋转。当distance为正数时,将list后distance个元素整体移到前面。当distance为负数时,将 list的前distance个元素整体移到后面。
8.7.2 使用 Lists
在Collection中,List 集合是有序的,Developer可对其中每个元素的插入位置进行精确地控制,可以通过索引来访问元素,遍历元素。
在List集合中,我们常用到 ArrayList 和 LinkedList 这两个类。
其中,ArrayList 底层通过数组实现,随着元素的增加而动态扩容。而 LinkedList 底层通过链表来实现,随着元素的增加不断向链表的后端增加节点。
ArrayList 是Java集合框架中使用最多的一个类,是一个数组队列,线程不安全集合。
它继承于 AbstractList,实现了 List, RandomAccess , Cloneable , Serializable 接口。
- ArrayList 实现 List,得到了 List 集合框架基础功能;
- ArrayList 实现 RandomAccess,获得了快速随机访问存储元素的功能,RandomAccess是一个标记接口,没有任何方法;
- ArrayList 实现 Cloneable,得到了 clone() 方法,可以实现克隆功能;
- ArrayList 实现 Serializable,表示可以被序列化,通过序列化去传输,典型的应用就是hessian 协议。
它具有如下特点:
- 容量不固定,随着容量的增加而动态扩容(阈值基本不会达到)
- 有序集合(插入的顺序==输出的顺序)
- 插入的元素可以为 null
- 增删改查效率更高(相对于 LinkedList 来说)
- 线程不安全
LinkedList 是一个双向链表,每一个节点都拥有指向前后节点的引用。相比于 ArrayList 来说,LinkedList 的随机访问效率更低。
它继承 AbstractSequentialList ,实现了 List , Deque , Cloneable , Serializable接口。
- LinkedList 实现 List,得到了 List 集合框架基础功能;
- LinkedList 实现 Deque,Deque 是一个双向队列,也就是既可以先入先出,又可以先入后出,说简单些就是既可以在头部添加元素,也可以在尾部添加元素;
- LinkedList 实现 Cloneable,得到了 clone() 方法,可以实现克隆功能;
- LinkedList 实现 Serializable,表示可以被序列化,通过序列化去传输,典型的应用就是hessian 协议。
对于随机访问 get 和 set,ArrayList 优于 LinkedList,因为 LinkedList 要移动指针。
对于新增和删除操作 add 和 remove,LinedList 比较占优势,因为 ArrayList 要移动数据。
List 常用方法
A:添加功能
boolean add(E e):向集合中添加一个元素
void add(int index, E element):在指定位置添加元素
boolean addAll(Collection c):向集合中添加一个集合的元素。
B:删除功能
void clear():删除集合中的所有元素
E remove(int index):根据指定索引删除元素,并把删除的元素返回
boolean remove(Object o):从集合中删除指定的元素
boolean removeAll(Collection c):从集合中删除一个指定的集合元素。
C:修改功能
E set(int index, E element):把指定索引位置的元素修改为指定的值,返回修改前的值。
D:获取功能
E get(int index):获取指定位置的元素
Iterator iterator():就是用来获取集合中每一个元素。
E:判断功能
boolean isEmpty():判断集合是否为空。
boolean contains(Object o):判断集合中是否存在指定的元素。
boolean containsAll(Collection c):判断集合中是否存在指定的一个集合中的元素。
F:长度功能
int size():获取集合中的元素个数
G:把集合转换成数组
Object[] toArray():把集合变成数组。
ArrayList 基本操作
public class ArrayListTest {
public static void main(String[] agrs){
//创建ArrayList集合:
List<String> list = new ArrayList<String>();
System.out.println("ArrayList集合初始化容量:"+list.size());
//添加功能:
list.add("Hello");
list.add("world");
list.add(2,"!");
System.out.println("ArrayList当前容量:"+list.size());
//修改功能:
list.set(0,"my");
list.set(1,"name");
System.out.println("ArrayList当前内容:"+list.toString());
//获取功能:
String element = list.get(0);
System.out.println(element);
//迭代器遍历集合:(ArrayList实际的跌倒器是Itr对象)
Iterator<String> iterator = list.iterator();
while(iterator.hasNext()){
String next = iterator.next();
System.out.println(next);
}
//for循环迭代集合:
for(String str:list){
System.out.println(str);
}
//判断功能:
boolean isEmpty = list.isEmpty();
boolean isContain = list.contains("my");
//长度功能:
int size = list.size();
//把集合转换成数组:
String[] strArray = list.toArray(new String[]{});
//删除功能:
list.remove(0);
list.remove("world");
list.clear();
System.out.println("ArrayList当前容量:"+list.size());
}
}
LinkedList 基本操作
public class LinkedListTest {
public static void main(String[] agrs){
List<String> linkedList = new LinkedList<String>();
System.out.println("LinkedList初始容量:"+linkedList.size());
//添加功能:
linkedList.add("my");
linkedList.add("name");
linkedList.add("is");
linkedList.add("jiaboyan");
System.out.println("LinkedList当前容量:"+ linkedList.size());
//修改功能:
linkedList.set(0,"hello");
linkedList.set(1,"world");
System.out.println("LinkedList当前内容:"+ linkedList.toString());
//获取功能:
String element = linkedList.get(0);
System.out.println(element);
//遍历集合:(LinkedList实际的跌倒器是ListItr对象)
Iterator<String> iterator = linkedList.iterator();
while(iterator.hasNext()){
String next = iterator.next();
System.out.println(next);
}
//for循环迭代集合:
for(String str:linkedList){
System.out.println(str);
}
//判断功能:
boolean isEmpty = linkedList.isEmpty();
boolean isContains = linkedList.contains("jiaboyan");
//长度功能:
int size = linkedList.size();
//删除功能:
linkedList.remove(0);
linkedList.remove("jiaboyan");
linkedList.clear();
System.out.println("LinkedList当前容量:" + linkedList.size());
}
}
8.7.3 使用Sets
Java中的Set集合是继承 Collection 的接口,是一个不包含重复元素的集合。
Set(接口) 添加到Set 的每个元素都必须是独一无二的;否则Set 就不会添加重复的元素。添加到Set 里的对象必须定义equals(),从而建立对象的唯一性。Set 拥有与Collection 完全相同的接口。一个Set 不能保证自己可按任何特定的顺序维持自己的元素。
常见的方法:
| 序号 | Method & Description |
|---|---|
| 1 | add( ) 向集合中添加元素 |
| 2 | clear( ) 去掉集合中所有的元素 |
| 3 | contains( ) 判断集合中是否包含某一个元素 |
| 4 | isEmpty( ) 判断集合是否为空 |
| 5 | iterator( ) 主要用于递归集合,返回一个Iterator()对象 |
| 6 | remove( ) 从集合中去掉特定的对象 |
| 7 | size( ) 返回集合的大小 |
HashSet
特点:没有重复数据,数据不按存入的顺序输出。
HashSet 由 Hash 表结构支持。不支持set的迭代顺序,不保证顺序。但是Hash表结构查询速度很快。
HashSet 的底层就是 HashMap 来构建的并可以添加初始容量和加载因子,来调节反应时间或是空间容量。
元素的哈希值是通过元素的hashcode方法 来获取的, HashSet首先判断两个元素的哈希值,如果哈希值一样,接着会比较equals方法 如果 equls结果为true ,HashSet就视为同一个元素。如果equals 为false就不是同一个元素。
TreeSet
基于红黑树实现,支持有序性操作,例如根据一个范围查找元素的操作。但是查找效率不如 HashSet,HashSet 查找的时间复杂度为 O(1),TreeSet 则为 O(logN)。
TreeSet支持两种排序方式,自然排序和定制排序。默认为自然排序,和HashSet的输出顺序不一样。
自然排序(默认情况):
调用TreeSet的无参的构造器,并实现Comparable接口,实现里的 compareTo(Object obj)方法,来比较集合元素的大小,然后按照compareTo里的排序。
定制排序
自己写个比较器的类,传入TreeSet的有参数的构造器,这样往集合里add元素就能按照定制的顺序排序了。
与HashSet相比,TreeSet还额外提供了以下的方法:
| 序号 | 方法 |
|---|---|
| 1 | SortedSet subSet(Object fromElement, Object toElement) :返回这个Set的子集合,范围从 fromElement(包含)到 toElement(不包含) |
| 2 | SortedSet headSet(Object toElement):返回这个Set的子集合,范围小于到toElement的子集合 |
| 3 | SortedSet tailSet(Object fromElement):返回这个 Set 的子集合,范围大于或等于到fromElement 的子集合 |
| 4 | Object first():返回这个Set第一个元素 |
| 5 | Object last():返回这个Set最后一个元素 |
| 6 | Object lower(Object e):返回小于指定元素的集合里最大的那个元素 |
| 7 | Object higher(Object e):返回大于指定元素的集合里最小的那个元素 |
LinkedHashSet
具有 HashSet 的查找效率,且内部使用双向链表维护元素的插入顺序。
Set的性能
HashSet综合效率最高,LinkedHashSet因为有链表,遍历时会更快一些。TreeSet因为要维护红黑树,效率较低。
8.7.4 使用Maps
Map基本操作:
Map 初始化
Map
插入元素
map.put(“key1”, “value1”);
获取元素
map.get(“key1”)
移除元素
map.remove(“key1”);
清空map
map.clear();
HashMap
hashMap是由数组和链表这两个结构来存储数据。
数组:存储区间是连续的,占用内存严重,故空间复杂的很大。但数组的二分查找时间复杂度小,为O(1);寻址容易,插入和删除困难;
链表:存储区间离散,占用内存比较宽松,故空间复杂度很小,但时间复杂度很大,达O(N);寻址困难,插入和删除容易。
hashMap则结合了两者的优点,既满足了寻址,又满足了操作,为什么呢?关键在于它的存储结构。
它底层是一个数组,数组元素就是一个链表形式,见下图:
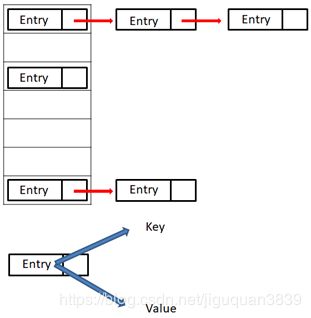
Entry: 存储键值对。
Map类在设计时提供了一个静态修饰接口Entry。Entry将键值对的对应关系封装成了键值对对象,这样我们在遍历Map集合时,就可以从每一个键值对对象中获取相应的键与值。之所以被修饰成静态是为了可以用类名直接调用。
每次初始化HashMap都会构造一个table数组,而table数组的元素为Entry节点,它里面包含了键key,值value,下一个节点next,以及hash值。
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next;
int hash;
}
TreeMap
TreeMap 是一个有序的key-value集合,继承于AbstractMap,它是通过红黑树实现的。TreeMap 实现了NavigableMap接口,实现了Cloneable接口,实现了java.io.Serializable接口。
TreeMap基于红黑树(Red-Black tree)实现。该映射根据其键的自然顺序进行排序,或者根据创建映射时提供的 Comparator 进行排序,具体取决于使用的构造方法。TreeMap的基本操作 containsKey、get、put 和 remove 的时间复杂度是 log(n) 。另外,TreeMap是非同步的。 它的iterator 方法返回的迭代器是fail-fastl的。
HashTable
与 HashMap类似,不同的是:key和value的值均不允许为null;它支持线程的同步,即任一时刻只有一个线程能写Hashtable,因此也导致了Hashtale在写入时会比较慢。
LinkedHashMap
它虽然增加了时间和空间上的开销,但是通过维护一个运行于所有条目的双向链表,LinkedHashMap保证了元素迭代的顺序,该迭代顺序可以是插入顺序或者是访问顺序。那么是如何维护的呢,首先参考HashMap的存储结构,将其中的Entry元素增加一个pre指针和一个next指针,这样,根据插入元素的顺序将各个元素依次连接起来,这样LinkedHashMap就保证了元素的顺序。
map的遍历有4种:
第一种,这是最常见的用法,这种用法可以同时拿到key和value值。 缺点:如果map是空,将会出现空指针异常,那么每次在对map遍历以前,就要先进行判空
public static void forEachMap(Map<String,String> map) {
for ( Map.Entry<String,String> entry : map.entrySet()) {
System.out.println(entry.getKey()+entry.getValue());
}
}
第二种遍历方法,这种方法是只遍历key或者value。这种方法比第一种方法的效率略微有提升,而且代码也能简洁一点。同样,这种方法也需要判断map是否为空。
public static void forEachMap2(Map<String,String> map){
for (String str :map.keySet()){
System.out.println(str);
}
for (String str :map.values()){
System.out.println(str);
}
}
第三种方法是使用迭代器的方式
// 使用迭代器
public static void forEachMap3(Map<String, String> map) {
Iterator<Map.Entry<String, String>> iterator = map.entrySet().iterator();
while (iterator.hasNext()) {
Map.Entry<String, String> entry = iterator.next();
System.out.println(entry.getKey() + entry.getValue());
}
}
//使用迭代器但是不适用泛型
public static void forEachMap4(Map<String, String> map) {
Iterator iterator = map.entrySet().iterator();
while (iterator.hasNext()){
Map.Entry entry= (Map.Entry) iterator.next();
//这里的类型转换的原因是,如果不加String,那么背默认为两个object,不能相加
System.out.println((String)entry.getKey() + entry.getValue());
}
}
这两种方式没有什么大的区别,只是在泛型上有个区别。
第四种是先拿到map的key值,再拿取value值。 这种方式效率比较低,一般不推荐使用
for (Integer key : map.keySet()) {
Integer value = map.get(key);
System.out.println("Key = " + key + ", Value = " + value);
}
总结
- 增强for循环使用方便,但性能较差,不适合处理超大量级的数据。
- 迭代器的遍历速度要比增强for循环快很多,是增强for循环的2倍左右。
- 使用entrySet遍历的速度要比keySet快很多,是keySet的1.5倍左右。
8.7.5 决定实施方案
- 决定使用何种List
为体会各种List 实施方案间的差异,最简便的方法就是进行一次性能测验。下述代码的作用是建立一个内部基础类,将其作为一个测试床使用。然后为每次测验都创建一个匿名内部类。每个这样的内部类都由一个test()方法调用。利用这种方法,可以方便添加和删除测试项目。
可以看出,在ArrayList 中进行随机访问(即get())以及循环反复是最划得来的;但对于LinkedList 却是一个不小的开销。但另一方面,在列表中部进行插入和删除操作对于LinkedList 来说却比ArrayList 划算得多。我们最好的做法也许是先选择一个ArrayList 作为自己的默认起点。以后若发现由于大量的插入和删除造成了性能的降低,再考虑换成LinkedList 不迟。
-
决定使用何种Set
可在ArraySet 以及HashSet 间作出选择,具体取决于Set 的大小(如果需要从一个Set 中获得一个顺序列表,请用TreeSet;注释)
进行add()以及contains()操作时,HashSet 显然要比ArraySet 出色得多,而且性能明显与元素的多寡关系不大。一般编写程序的时候,几乎永远用不着使用ArraySet。
-
决定使用何种Map
8.7.6 未支持的操作
对那些采用Collection,List,Set 或者Map 作为参数的方法,它们的文档应当指出哪些可选的方法是必须实现的。
8.7.7 排序和搜索
Collections提供以下方法对List进行排序操作
void reverse(List list):反转
void shuffle(List list),随机排序
void sort(List list),按自然排序的升序排序
void sort(List list, Comparator c);定制排序,由Comparator控制排序逻辑
void swap(List list, int i , int j),交换两个索引位置的元素
void rotate(List list, int distance),旋转。当distance为正数时,将list后distance个元素整体移到前面。当distance为负数时,将 list的前distance个元素整体移到后面。
查找,替换操作
int binarySearch(List list, Object key), 对List进行二分查找,返回索引,注意List必须是有序的
int max(Collection coll),根据元素的自然顺序,返回最大的元素。 类比int min(Collection coll)
int max(Collection coll, Comparator c),根据定制排序,返回最大元素,排序规则由Comparatator类控制。类比int min(Collection coll, Comparator c)
void fill(List list, Object obj),用元素obj填充list中所有元素
int frequency(Collection c, Object o),统计元素出现次数
int indexOfSubList(List list, List target), 统计targe在list中第一次出现的索引,找不到则返回-1,类比int lastIndexOfSubList(List source, list target).
boolean replaceAll(List list, Object oldVal, Object newVal), 用新元素替换旧元素。
同步控制
Collections中几乎对每个集合都定义了同步控制方法,例如 SynchronizedList(), SynchronizedSet()等方法,来将集合包装成线程安全的集合。下面是Collections将普通集合包装成线程安全集合的用法。
8.7.8 实用工具
见上一节
第 9 章 违例差错控制
“违例”(Exception)这个词表达的是一种“例外”情况,亦即正常情况之外的一种“异常”。在问题发生的时候,我们可能不知具体该如何解决,但肯定知道已不能不顾一切地继续下去。此时,必须坚决地停下来,并由某人、某地指出发生了什么事情,以及该采取何种对策。但为了真正解决问题,当地可能并没有足够多的信息。因此,我们需要将其移交给更级的负责人,令其作出正确的决定(类似一个命令链)。
违例机制的另一项好处就是能够简化错误控制代码。我们再也不用检查一个特定的错误,然后在程序的多处地方对其进行控制。此外,也不需要在方法调用的时候检查错误(因为保证有人能捕获这里的错误)。我们只需要在一个地方处理问题:“违例控制模块”或者“违例控制器”。这样可有效减少代码量,并将那些用于描述具体操作的代码与专门纠正错误的代码分隔开。一般情况下,用于读取、写入以及调试的代码会变得更富有条理。
9.1 基本违例
“违例条件”表示在出现什么问题的时候应中止方法或作用域的继续。为了将违例条件与普通问题区分开,违例条件是非常重要的一个因素。
产生一个违例时,会发生几件事情。首先,按照与创建Java 对象一样的方法创建违例对象:在内存“堆”里,使用new 来创建。随后,停止当前执行路径(记住不可沿这条路径继续下去),然后从当前的环境中释放出违例对象的句柄。此时,违例控制机制会接管一切,并开始查找一个恰当的地方,用于继续程序的执行。这个恰当的地方便是“违例控制器”,它的职责是从问题中恢复,使程序要么尝试另一条执行路径,要么简单地继续。
9.1.1 违例自变量
和Java 的其他任何对象一样,需要用new 在内存堆里创建违例,并需调用一个构建器。在所有标准违例中,存在着两个构建器:第一个是默认构建器,第二个则需使用一个字串自变量,使我们能在违例里置入相关信息:
if(t == null)
throw new NullPointerException(“t = null”);
我们可根据需要掷出任何类型的“可掷”对象。典型情况下,我们要为每种不同类型的错误“掷”出一类不同的违例。我们的思路是在违例对象以及挑选的违例对象类型中保存信息,所以在更大场景中的某个人可知道如何对待我们的违例。
9.2 违例的捕获
9.2.1 try 块
若不想一个throw 离开方法,可在那个方法内部设置一个特殊的代码块,用它
捕获违例。这就叫作“try 块”,因为要在这个地方“尝试”各种方法调用。try 块属于一种普通的作用域,
用一个try 关键字开头:
try {
// 可能产生违例的代码
}
9.2.2 违例控制器
生成的违例必须在某个地方中止。这个“地方”便是违例控制器或者违例控制模块。而且针对想捕获
的每种违例类型,都必须有一个相应的违例控制器。违例控制器紧接在try 块后面,且用catch(捕获)关
键字标记。如下所示:
try {
// Code that might generate exceptions
} catch(Type1 id1) {
// Handle exceptions of Type1
} catch(Type2 id2) {
// Handle exceptions of Type2
} catch(Type3 id3) {
// Handle exceptions of Type3
}
我们有时也根本不使用标识符,因为违例类型已提供了足够的信息,可有效处理违例。但即使不用,标识符也必须就位。控制器必须“紧接”在try 块后面。若“掷”出一个违例,违例控制机制就会搜寻自变量与违例类型相符的第一个控制器。随后,它会进入那个catch 从句,并认为违例已得到控制(一旦catch 从句结束,对控制器的搜索也会停止)。只有相符的catch 从句才会得到执行。
- 中断与恢复
在违例控制理论中,共存在两种基本方法。在“中断”方法中(Java 和C++提供了对这种方法的支持),我们假定错误非常关键,没有办法返回违例发生的地方。无论谁只要“掷”出一个违例,就表明没有办法补救错误,而且也不希望再回来。
另一种方法叫作“恢复”。它意味着违例控制器有责任来纠正当前的状况,然后取得出错的方法,假定下一次会成功执行。若使用恢复,意味着在违例得到控制以后仍然想继续执行。在这种情况下,我们的违例更象一个方法调用——我们用它在Java 中设置各种各样特殊的环境,产生类似于“恢复”的行为(换言之,此时不是“掷”出一个违例,而是调用一个用于解决问题的方法)。另外,也可以将自己的try 块置入一个while 循环里,用它不断进入try 块,直到结果满意时为止。
从历史的角度看,若程序员使用的操作系统支持可恢复的违例控制,最终都会用到类似于中断的代码,并跳过恢复进程。所以尽管“恢复”表面上十分不错,但在实际应用中却显得困难重重。其中决定性的原因可能是:我们的控制模块必须随时留意是否产生了违例,以及是否包含了由产生位置专用的代码。这便使代码很难编写和维护——大型系统尤其如此,因为违例可能在多个位置产生。
9.2.3 违例规范
违例规范采用了一个额外的关键字:throws;后面跟随全部潜在的违例类型。因此,我们的方法定义看起来应象下面这个样子:
void f() throws tooBig, tooSmall, divZero { //…
若使用下述代码:
void f() [ // …
它意味着不会从方法里“掷”出违例(除类型为RuntimeException 的违例以外,它可能从任何地方掷出——稍后还会详细讲述)。
我们在这个地方可采取欺骗手段:要求“掷”出一个并没有发生的违例。编译器能理解我们的要求,并强迫使用这个方法的用户当作真的产生了那个违例处理。在实际应用中,可将其作为那个违例的一个“占位符”使用。这样一来,以后可以方便地产生实际的违例,毋需修改现有的代码。
9.2.4 捕获所有违例
我们可创建一个控制器,令其捕获所有类型的违例。
catch(Exception e) {
System.out.println("caught an exception");
}
这段代码能捕获任何违例,所以在实际使用时最好将其置于控制器列表的末尾,防止跟随在后面的任何特殊违例控制器失效。
对于程序员常用的所有违例类来说,由于Exception 类是它们的基础,所以我们不会获得关于违例太多的信息,但可调用来自它的基础类Throwable 的方法:
String getMessage(): 获得详细的消息。
**String toString():**返回对Throwable 的一段简要说明,其中包括详细的消息(如果有的话)。
void printStackTrace()
void printStackTrace(PrintStream)
打印出Throwable 和Throwable 的调用堆栈路径。调用堆栈显示出将我们带到违例发生地点的方法调用的顺序。第一个版本会打印出标准错误,第二个则打印出我们的选择流程.
9.2.5 重新“掷”出违例
在某些情况下,我们想重新掷出刚才产生过的违例,特别是在用Exception 捕获所有可能的违例时。由于我们已拥有当前违例的句柄,所以只需简单地重新掷出那个句柄即可。下面是一个例子:
重新“掷”出一个违例导致违例进入更高一级环境的违例控制器中。用于同一个try 块的任何更进一步的catch 从句仍然会被忽略。此外,与违例对象有关的所有东西都会得到保留,所以用于捕获特定违例类型的更高一级的控制器可以从那个对象里提取出所有信息。
catch(Exception e) {
System.out.println("一个违例已经产生");
throw e;
}
重新“掷”出一个违例导致违例进入更高一级环境的违例控制器中。用于同一个try 块的任何更进一步的catch 从句仍然会被忽略。此外,与违例对象有关的所有东西都会得到保留,所以用于捕获特定违例类型的更高一级的控制器可以从那个对象里提取出所有信息。
永远不必关心如何清除前一个违例,或者与之有关的其他任何违例。它们都属于用new 创建的、以内存堆为基础的对象,所以垃圾收集器会自动将其清除。
9.3 标准 Java 违例
Java 包含了一个名为Throwable 的类,它对可以作为违例“掷”出的所有东西进行了描述。Exception 是可以从任何标准Java 库的类方法中“掷”出的基本类型。此外,它们亦可从我们自己的方法以及运行期偶发事件中“掷”出。
9.3.1 RuntimeException 的特殊情况
若对一个空句柄发出了调用,Java 会自动产生一个NullPointerException 违例。
这个类别里含有一系列违例类型。它们全部由Java 自动生成,毋需我们亲自动手把它们包含到自己的违例规范里。最方便的是,通过将它们置入单独一个名为RuntimeException 的基础类下面,它们全部组合到一起。这是一个很好的继承例子:它建立了一系列具有某种共通性的类型,都具有某些共通的特征与行为。
我们不可将Java 违例划分为单一用途的工具。的确,它们设计用于控制那些讨厌的运行期错误——由代码控制范围之外的其他力量产生。但是,它也特别有助于调试某些特殊类型的编程错误,那些是编译器侦测不到的。
9.4 创建自己的违例
为创建自己的违例类,必须从一个现有的违例类型继承——最好在含义上与新违例近似。继承一个违例相当简单:
//: Inheriting.java
// Inheriting your own exceptions
class MyException extends Exception {
public MyException() {}
public MyException(String msg) {
super(msg);
}
}
public class Inheriting {
public static void f() throws MyException {
System.out.println(
"Throwing MyException from f()");
throw new MyException();
}
public static void g() throws MyException {
System.out.println(
"Throwing MyException from g()");
throw new MyException("Originated in g()");
}
public static void main(String[] args) {
try {
f();
} catch(MyException e) {
e.printStackTrace();
}
try {
g();
} catch(MyException e) {
e.printStackTrace();
}
}
} ///:~
这里的关键是“extends Exception”,它的意思是:除包括一个Exception 的全部含义以外,还有更多的含义。增加的代码数量非常少——实际只添加了两个构建器,对MyException 的创建方式进行了定义。
由于违例不过是另一种形式的对象,所以可以继续这个进程,进一步增强违例类的能力。但要注意,对使用自己这个包的客户程序员来说,他们可能错过所有这些增强。因为他们可能只是简单地寻找准备生成的违例,除此以外不做任何事情——这是大多数Java 库违例的标准用法。
9.5 违例的限制
覆盖一个方法时,只能产生已在方法的基础类版本中定义的违例。这是一个重要的限制,因为它意味着与基础类协同工作的代码也会自动应用于从基础类衍生的任何对象(当然,这属于基本的OOP 概念),其中包括违例。
我们必须认识到这一点:尽管违例规范是由编译器在继承期间强行遵守的,但违例规范并不属于方法类型的一部分,后者仅包括了方法名以及自变量类型。因此,我们不可在违例规范的基础上覆盖方法。除此以外,尽管违例规范存在于一个方法的基础类版本中,但并不表示它必须在方法的衍生类版本中存在。这与方法的“继承”颇有不同(进行继承时,基础类中的方法也必须在衍生类中存在)。换言之,用于一个特定方法的“违例规范接口”可能在继承和覆盖时变得更“窄”,但它不会变得更“宽”——这与继承时的类接口规则是正好相反的。
9.6 用 finally 清除
无论一个违例是否在try 块中发生,我们经常都想执行一些特定的代码。对一些特定的操作,经常都会遇到这种情况,但在恢复内存时一般都不需要(因为垃圾收集器会自动照料一切)。为达到这个目的,可在所有违例控制器的末尾使用一个finally 从句。所以完整的违例控制小节象下面这个样子:
try {
// 要保卫的区域:
// 可能“掷”出A,B,或C 的危险情况
} catch (A a1) {
// 控制器 A
} catch (B b1) {
// 控制器 B
} catch (C c1) {
// 控制器 C
} finally {
// 每次都会发生的情况
}
无论是否“掷”出一个违例,finally 从句都会执行。
9.6.1 用 finally 做什么
除将内存设回原始状态以外,若要设置另一些东西,finally 就是必需的。例如,我们有时需要打开一个文件或者建立一个网络连接,或者在屏幕上画一些东西,甚至设置外部世界的一个开关,等等。
若调用了break 和continue 语句,finally 语句也会得以执行。请注意,与作上标签的break 和continue一道,finally 排除了Java 对goto 跳转语句的需求。
9.6.2 缺点:丢失的违例
一般情况下,Java 的违例实施方案都显得十分出色。不幸的是,它依然存在一个缺点。尽管违例指出程序里存在一个危机,而且绝不应忽略,但一个违例仍有可能简单地“丢失”。在采用finally 从句的一种特殊配置下,便有可能发生这种情况:
//: LostMessage.java
// How an exception can be lost
class VeryImportantException extends Exception {
public String toString() {
return "A very important exception!";
}
}
class HoHumException extends Exception {
public String toString() {
return "A trivial exception";
}
}
public class LostMessage {
void f() throws VeryImportantException {
throw new VeryImportantException();
}
void dispose() throws HoHumException {
throw new HoHumException();
}
public static void main(String[] args)
throws Exception {
LostMessage lm = new LostMessage();
try {
lm.f();
} finally {
lm.dispose();
}
}
} ///:~
输出如下:
A trivial exception
at LostMessage.dispose(LostMessage.java:21)
at LostMessage.main(LostMessage.java:29)
可以看到,这里不存在VeryImportantException(非常重要的违例)的迹象,它只是简单地被finally 从句中的HoHumException 代替了。
这是一项相当严重的缺陷,因为它意味着一个违例可能完全丢失。而且就象前例演示的那样,这种丢失显得非常“自然”,很难被人查出蛛丝马迹。
9.7 构建器
构建器将对象置于一个安全的起始状态,但它可能执行一些操作——如打开一个文件。除非用户完成对象的使用,并调用一个特殊的清除方法,否则那些操作不会得到正确的清除。若从一个构建器内部“掷”出一个违例,这些清除行为也可能不会正确地发生。所有这些都意味着在编写构建器时,我们必须特别加以留意。
finally每次都会执行清除代码——即使我们在清除方法运行之前不想执行清除代码。因此,假如真的用finally 进行清除,必须在构建器正常结束时设置某种形式的标志。而且只要设置了标志,就不要执行finally 块内的任何东西。由于这种做法并不完美(需要将一个地方的代码同另一个地方的结合起来),所以除非特别需要,否则一般不要尝试在finally 中进行这种形式的清除。
9.8 违例匹配
“掷”出一个违例后,违例控制系统会按当初编写的顺序搜索“最接近”的控制器。一旦找到相符的控制器,就认为违例已得到控制,不再进行更多的搜索工作。
在违例和它的控制器之间,并不需要非常精确的匹配。一个衍生类对象可与基础类的一个控制器相配。
9.8.1 违例准则
用违例做下面这些事情:
(1) 解决问题并再次调用造成违例的方法。
(2) 平息事态的发展,并在不重新尝试方法的前提下继续。
(3) 计算另一些结果,而不是希望方法产生的结果。
(4) 在当前环境中尽可能解决问题,以及将相同的违例重新“掷”出一个更高级的环境。
(5) 在当前环境中尽可能解决问题,以及将不同的违例重新“掷”出一个更高级的环境。
(6) 中止程序执行。
(7) 简化编码。若违例方案使事情变得更加复杂,那就会令人非常烦恼,不如不用。
(8) 使自己的库和程序变得更加安全。这既是一种“短期投资”(便于调试),也是一种“长期投资”(改善应用程序的健壮性)
9.9 总结
try、catch、finally用法总结:
1、不管有没有异常,finally中的代码都会执行
2、当try、catch中有return时,finally中的代码依然会继续执行
3、finally是在return后面的表达式运算之后执行的,此时并没有返回运算之后的值,而是把值保存起来,不管finally对该值做任何的改变,返回的值都不会改变,依然返回保存起来的值。也就是说方法的返回值是在finally运算之前就确定了的。
4、finally代码中最好不要包含return,程序会提前退出,也就是说返回的值不是try或catch中的值
第 10 章 Java IO 系统
由于 Thinking in Java 基于 Java 5 过于老旧,此章参考了基于 java 8 的 On Java 8
https://github.com/LingCoder/OnJava8
10.1 文件和目录路径
一个 Path 对象表示一个文件或者目录的路径,是一个跨操作系统(OS)和文件系统的抽象,目的是在构造路径时不必关注底层操作系统,代码可以在不进行修改的情况下运行在不同的操作系统上。java.nio.file.Paths 类包含一个重载方法 static get(),该方法接受一系列 String 字符串或一个统一资源标识符(URI)作为参数,并且进行转换返回一个 Path 对象:
// files/PathInfo.java
import java.nio.file.*;
import java.net.URI;
import java.io.File;
import java.io.IOException;
public class PathInfo {
static void show(String id, Object p) {
System.out.println(id + ": " + p);
}
static void info(Path p) {
show("toString", p);
show("Exists", Files.exists(p));
show("RegularFile", Files.isRegularFile(p));
show("Directory", Files.isDirectory(p));
show("Absolute", p.isAbsolute());
show("FileName", p.getFileName());
show("Parent", p.getParent());
show("Root", p.getRoot());
System.out.println("******************");
}
public static void main(String[] args) {
System.out.println(System.getProperty("os.name"));
info(Paths.get("C:", "path", "to", "nowhere", "NoFile.txt"));
Path p = Paths.get("PathInfo.java");
info(p);
Path ap = p.toAbsolutePath();
info(ap);
info(ap.getParent());
try {
info(p.toRealPath());
} catch(IOException e) {
System.out.println(e);
}
URI u = p.toUri();
System.out.println("URI: " + u);
Path puri = Paths.get(u);
System.out.println(Files.exists(puri));
File f = ap.toFile(); // Don't be fooled
}
}
/* 输出:
Windows 10
toString: C:\path\to\nowhere\NoFile.txt
Exists: false
RegularFile: false
Directory: false
Absolute: true
FileName: NoFile.txt
Parent: C:\path\to\nowhere
Root: C:\
******************
toString: PathInfo.java
Exists: true
RegularFile: true
Directory: false
Absolute: false
FileName: PathInfo.java
Parent: null
Root: null
******************
toString: C:\Users\Bruce\Documents\GitHub\onjava\
ExtractedExamples\files\PathInfo.java
Exists: true
RegularFile: true
Directory: false
Absolute: true
FileName: PathInfo.java
Parent: C:\Users\Bruce\Documents\GitHub\onjava\
ExtractedExamples\files
Root: C:\
******************
toString: C:\Users\Bruce\Documents\GitHub\onjava\
ExtractedExamples\files
Exists: true
RegularFile: false
Directory: true
Absolute: true
FileName: files
Parent: C:\Users\Bruce\Documents\GitHub\onjava\
ExtractedExamples
Root: C:\
******************
toString: C:\Users\Bruce\Documents\GitHub\onjava\
ExtractedExamples\files\PathInfo.java
Exists: true
RegularFile: true
Directory: false
Absolute: true
FileName: PathInfo.java
Parent: C:\Users\Bruce\Documents\GitHub\onjava\
ExtractedExamples\files
Root: C:\
******************
URI: file:///C:/Users/Bruce/Documents/GitHub/onjava/
ExtractedExamples/files/PathInfo.java
true
*/
我已经在这一章第一个程序的 main() 方法添加了第一行用于展示操作系统的名称,因此你可以看到不同操作系统之间存在哪些差异。理想情况下,差别会相对较小,并且使用 / 或者 ** 路径分隔符进行分隔。你可以看到我运行在Windows 10 上的程序输出。
当 toString() 方法生成完整形式的路径,你可以看到 getFileName() 方法总是返回当前文件名。 通过使用 Files 工具类(我们接下类将会更多地使用它),可以测试一个文件是否存在,测试是否是一个"普通"文件还是一个目录等等。"Nofile.txt"这个示例展示我们描述的文件可能并不在指定的位置;这样可以允许你创建一个新的路径。“PathInfo.java"存在于当前目录中,最初它只是没有路径的文件名,但它仍然被检测为"存在”。一旦我们将其转换为绝对路径,我们将会得到一个从"C:"盘(因为我们是在Windows机器下进行测试)开始的完整路径,现在它也拥有一个父路径。“真实”路径的定义在文档中有点模糊,因为它取决于具体的文件系统。例如,如果文件名不区分大小写,即使路径由于大小写的缘故而不是完全相同,也可能得到肯定的匹配结果。在这样的平台上,toRealPath() 将返回实际情况下的 Path,并且还会删除任何冗余元素。
这里你会看到 URI 看起来只能用于描述文件,实际上 URI 可以用于描述更多的东西;通过 维基百科 可以了解更多细节。现在我们成功地将 URI 转为一个 Path 对象。
最后,你会在 Path 中看到一些有点欺骗的东西,这就是调用 toFile() 方法会生成一个 File 对象。听起来似乎可以得到一个类似文件的东西(毕竟被称为 File ),但是这个方法的存在仅仅是为了向后兼容。虽然看上去应该被称为"路径",实际上却应该表示目录或者文件本身。这是个非常草率并且令人困惑的命名,但是由于 java.nio.file 的存在我们可以安全地忽略它的存在。
10.2 选取路径部分片段
Path 对象可以非常容易地生成路径的某一部分:
// files/PartsOfPaths.java
import java.nio.file.*;
public class PartsOfPaths {
public static void main(String[] args) {
System.out.println(System.getProperty("os.name"));
Path p = Paths.get("PartsOfPaths.java").toAbsolutePath();
for(int i = 0; i < p.getNameCount(); i++)
System.out.println(p.getName(i));
System.out.println("ends with '.java': " +
p.endsWith(".java"));
for(Path pp : p) {
System.out.print(pp + ": ");
System.out.print(p.startsWith(pp) + " : ");
System.out.println(p.endsWith(pp));
}
System.out.println("Starts with " + p.getRoot() + " " + p.startsWith(p.getRoot()));
}
}
/* 输出:
Windows 10
Users
Bruce
Documents
GitHub
on-java
ExtractedExamples
files
PartsOfPaths.java
ends with '.java': false
Users: false : false
Bruce: false : false
Documents: false : false
GitHub: false : false
on-java: false : false
ExtractedExamples: false : false
files: false : false
PartsOfPaths.java: false : true
Starts with C:\ true
*/
可以通过 getName() 来索引 Path 的各个部分,直到达到上限 getNameCount()。Path 也实现了 Iterable 接口,因此我们也可以通过增强的 for-each 进行遍历。请注意,即使路径以 .java 结尾,使用 endsWith() 方法也会返回 false。这是因为使用 endsWith() 比较的是整个路径部分,而不会包含文件路径的后缀。通过使用 startsWith() 和 endsWith() 也可以完成路径的遍历。但是我们可以看到,遍历 Path 对象并不包含根路径,只有使用 startsWith() 检测根路径时才会返回 true。
10.3 路径分析
Files 工具类包含一系列完整的方法用于获得 Path 相关的信息。
// files/PathAnalysis.java
import java.nio.file.*;
import java.io.IOException;
public class PathAnalysis {
static void say(String id, Object result) {
System.out.print(id + ": ");
System.out.println(result);
}
public static void main(String[] args) throws IOException {
System.out.println(System.getProperty("os.name"));
Path p = Paths.get("PathAnalysis.java").toAbsolutePath();
say("Exists", Files.exists(p));
say("Directory", Files.isDirectory(p));
say("Executable", Files.isExecutable(p));
say("Readable", Files.isReadable(p));
say("RegularFile", Files.isRegularFile(p));
say("Writable", Files.isWritable(p));
say("notExists", Files.notExists(p));
say("Hidden", Files.isHidden(p));
say("size", Files.size(p));
say("FileStore", Files.getFileStore(p));
say("LastModified: ", Files.getLastModifiedTime(p));
say("Owner", Files.getOwner(p));
say("ContentType", Files.probeContentType(p));
say("SymbolicLink", Files.isSymbolicLink(p));
if(Files.isSymbolicLink(p))
say("SymbolicLink", Files.readSymbolicLink(p));
if(FileSystems.getDefault().supportedFileAttributeViews().contains("posix"))
say("PosixFilePermissions",
Files.getPosixFilePermissions(p));
}
}
/* 输出:
Windows 10
Exists: true
Directory: false
Executable: true
Readable: true
RegularFile: true
Writable: true
notExists: false
Hidden: false
size: 1631
FileStore: SSD (C:)
LastModified: : 2017-05-09T12:07:00.428366Z
Owner: MINDVIEWTOSHIBA\Bruce (User)
ContentType: null
SymbolicLink: false
*/
在调用最后一个测试方法 getPosixFilePermissions() 之前我们需要确认一下当前文件系统是否支持 Posix 接口,否则会抛出运行时异常。
10.4 Paths的增减修改
我们必须能通过对 Path 对象增加或者删除一部分来构造一个新的 Path 对象。我们使用 relativize() 移除 Path 的根路径,使用 resolve() 添加 Path 的尾路径(不一定是“可发现”的名称)。
对于下面代码中的示例,我使用 relativize() 方法从所有的输出中移除根路径,部分原因是为了示范,部分原因是为了简化输出结果,这说明你可以使用该方法将绝对路径转为相对路径。 这个版本的代码中包含 id,以便于跟踪输出结果:
// files/AddAndSubtractPaths.java
import java.nio.file.*;
import java.io.IOException;
public class AddAndSubtractPaths {
static Path base = Paths.get("..", "..", "..").toAbsolutePath().normalize();
static void show(int id, Path result) {
if(result.isAbsolute())
System.out.println("(" + id + ")r " + base.relativize(result));
else
System.out.println("(" + id + ") " + result);
try {
System.out.println("RealPath: " + result.toRealPath());
} catch(IOException e) {
System.out.println(e);
}
}
public static void main(String[] args) {
System.out.println(System.getProperty("os.name"));
System.out.println(base);
Path p = Paths.get("AddAndSubtractPaths.java").toAbsolutePath();
show(1, p);
Path convoluted = p.getParent().getParent()
.resolve("strings").resolve("..")
.resolve(p.getParent().getFileName());
show(2, convoluted);
show(3, convoluted.normalize());
Path p2 = Paths.get("..", "..");
show(4, p2);
show(5, p2.normalize());
show(6, p2.toAbsolutePath().normalize());
Path p3 = Paths.get(".").toAbsolutePath();
Path p4 = p3.resolve(p2);
show(7, p4);
show(8, p4.normalize());
Path p5 = Paths.get("").toAbsolutePath();
show(9, p5);
show(10, p5.resolveSibling("strings"));
show(11, Paths.get("nonexistent"));
}
}
/* 输出:
Windows 10
C:\Users\Bruce\Documents\GitHub
(1)r onjava\
ExtractedExamples\files\AddAndSubtractPaths.java
RealPath: C:\Users\Bruce\Documents\GitHub\onjava\
ExtractedExamples\files\AddAndSubtractPaths.java
(2)r on-java\ExtractedExamples\strings\..\files
RealPath: C:\Users\Bruce\Documents\GitHub\onjava\
ExtractedExamples\files
(3)r on-java\ExtractedExamples\files
RealPath: C:\Users\Bruce\Documents\GitHub\onjava\
ExtractedExamples\files
(4) ..\..
RealPath: C:\Users\Bruce\Documents\GitHub\on-java
(5) ..\..
RealPath: C:\Users\Bruce\Documents\GitHub\on-java
(6)r on-java
RealPath: C:\Users\Bruce\Documents\GitHub\on-java
(7)r on-java\ExtractedExamples\files\.\..\..
RealPath: C:\Users\Bruce\Documents\GitHub\on-java
(8)r on-java
RealPath: C:\Users\Bruce\Documents\GitHub\on-java
(9)r on-java\ExtractedExamples\files
RealPath: C:\Users\Bruce\Documents\GitHub\onjava\
ExtractedExamples\files
(10)r on-java\ExtractedExamples\strings
RealPath: C:\Users\Bruce\Documents\GitHub\onjava\
ExtractedExamples\strings
(11) nonexistent
java.nio.file.NoSuchFileException:
C:\Users\Bruce\Documents\GitHub\onjava\
ExtractedExamples\files\nonexistent
*/
我还为 toRealPath() 添加了更多的测试,这是为了扩展和规则化,防止路径不存在时抛出运行时异常。
10.5 目录
Files 工具类包含大部分我们需要的目录操作和文件操作方法。出于某种原因,它们没有包含删除目录树相关的方法,因此我们将实现并将其添加到 onjava 库中。
// onjava/RmDir.java
package onjava;
import java.nio.file.*;
import java.nio.file.attribute.BasicFileAttributes;
import java.io.IOException;
public class RmDir {
public static void rmdir(Path dir) throws IOException {
Files.walkFileTree(dir, new SimpleFileVisitor() {
@Override
public FileVisitResult visitFile(Path file, BasicFileAttributes attrs) throws IOException {
Files.delete(file);
return FileVisitResult.CONTINUE;
}
@Override
public FileVisitResult postVisitDirectory(Path dir, IOException exc) throws IOException {
Files.delete(dir);
return FileVisitResult.CONTINUE;
}
});
}
}
删除目录树的方法实现依赖于 Files.walkFileTree(),“walking” 目录树意味着遍历每个子目录和文件。Visitor 设计模式提供了一种标准机制来访问集合中的每个对象,然后你需要提供在每个对象上执行的操作。 此操作的定义取决于实现的 FileVisitor 的四个抽象方法,包括:
1. **preVisitDirectory()**:在访问目录中条目之前在目录上运行。
2. **visitFile()**:运行目录中的每一个文件。
3. **visitFileFailed()**:调用无法访问的文件。
4. **postVisitDirectory()**:在访问目录中条目之后在目录上运行,包括所有的子目录。
为了简化,java.nio.file.SimpleFileVisitor 提供了所有方法的默认实现。这样,在我们的匿名内部类中,我们只需要重写非标准行为的方法:visitFile() 和 postVisitDirectory() 实现删除文件和删除目录。两者都应该返回标志位决定是否继续访问(这样就可以继续访问,直到找到所需要的)。 作为探索目录操作的一部分,现在我们可以有条件地删除已存在的目录。在以下例子中,makeVariant() 接受基本目录测试,并通过旋转部件列表生成不同的子目录路径。这些旋转与路径分隔符 sep 使用 String.join() 贴在一起,然后返回一个 Path 对象。
// files/Directories.java
import java.util.*;
import java.nio.file.*;
import onjava.RmDir;
public class Directories {
static Path test = Paths.get("test");
static String sep = FileSystems.getDefault().getSeparator();
static List parts = Arrays.asList("foo", "bar", "baz", "bag");
static Path makeVariant() {
Collections.rotate(parts, 1);
return Paths.get("test", String.join(sep, parts));
}
static void refreshTestDir() throws Exception {
if(Files.exists(test))
RmDir.rmdir(test);
if(!Files.exists(test))
Files.createDirectory(test);
}
public static void main(String[] args) throws Exception {
refreshTestDir();
Files.createFile(test.resolve("Hello.txt"));
Path variant = makeVariant();
// Throws exception (too many levels):
try {
Files.createDirectory(variant);
} catch(Exception e) {
System.out.println("Nope, that doesn't work.");
}
populateTestDir();
Path tempdir = Files.createTempDirectory(test, "DIR_");
Files.createTempFile(tempdir, "pre", ".non");
Files.newDirectoryStream(test).forEach(System.out::println);
System.out.println("*********");
Files.walk(test).forEach(System.out::println);
}
static void populateTestDir() throws Exception {
for(int i = 0; i < parts.size(); i++) {
Path variant = makeVariant();
if(!Files.exists(variant)) {
Files.createDirectories(variant);
Files.copy(Paths.get("Directories.java"),
variant.resolve("File.txt"));
Files.createTempFile(variant, null, null);
}
}
}
}
/* 输出:
Nope, that doesn't work.
test\bag
test\bar
test\baz
test\DIR_5142667942049986036
test\foo
test\Hello.txt
*********
test
test\bag
test\bag\foo
test\bag\foo\bar
test\bag\foo\bar\baz
test\bag\foo\bar\baz\8279660869874696036.tmp
test\bag\foo\bar\baz\File.txt
test\bar
test\bar\baz
test\bar\baz\bag
test\bar\baz\bag\foo
test\bar\baz\bag\foo\1274043134240426261.tmp
test\bar\baz\bag\foo\File.txt
test\baz
test\baz\bag
test\baz\bag\foo
test\baz\bag\foo\bar
test\baz\bag\foo\bar\6130572530014544105.tmp
test\baz\bag\foo\bar\File.txt
test\DIR_5142667942049986036
test\DIR_5142667942049986036\pre7704286843227113253.non
test\foo
test\foo\bar
test\foo\bar\baz
test\foo\bar\baz\bag
test\foo\bar\baz\bag\5412864507741775436.tmp
test\foo\bar\baz\bag\File.txt
test\Hello.txt
*/
首先,refreshTestDir() 用于检测 test 目录是否已经存在。若存在,则使用我们新工具类 rmdir() 删除其整个目录。检查是否 exists 是多余的,但我想说明一点,因为如果你对于已经存在的目录调用 createDirectory() 将会抛出异常。createFile() 使用参数 Path 创建一个空文件; resolve() 将文件名添加到 test Path 的末尾。
我们尝试使用 createDirectory() 来创建多级路径,但是这样会抛出异常,因为这个方法只能创建单级路径。我已经将 populateTestDir() 作为一个单独的方法,因为它将在后面的例子中被重用。对于每一个变量 variant,我们都能使用 createDirectories() 创建完整的目录路径,然后使用此文件的副本以不同的目标名称填充该终端目录。然后我们使用 createTempFile() 生成一个临时文件。
在调用 populateTestDir() 之后,我们在 test 目录下面下面创建一个临时目录。请注意,createTempDirectory() 只有名称的前缀选项。与 createTempFile() 不同,我们再次使用它将临时文件放入新的临时目录中。你可以从输出中看到,如果未指定后缀,它将默认使用".tmp"作为后缀。
为了展示结果,我们首次使用看起来很有希望的 newDirectoryStream(),但事实证明这个方法只是返回 test 目录内容的 Stream 流,并没有更多的内容。要获取目录树的全部内容的流,请使用 Files.walk()。
10.6 文件系统
为了完整起见,我们需要一种方法查找文件系统相关的其他信息。在这里,我们使用静态的 FileSystems 工具类获取"默认"的文件系统,但你同样也可以在 Path 对象上调用 getFileSystem() 以获取创建该 Path 的文件系统。你可以获得给定 URI 的文件系统,还可以构建新的文件系统(对于支持它的操作系统)。
// files/FileSystemDemo.java
import java.nio.file.*;
public class FileSystemDemo {
static void show(String id, Object o) {
System.out.println(id + ": " + o);
}
public static void main(String[] args) {
System.out.println(System.getProperty("os.name"));
FileSystem fsys = FileSystems.getDefault();
for(FileStore fs : fsys.getFileStores())
show("File Store", fs);
for(Path rd : fsys.getRootDirectories())
show("Root Directory", rd);
show("Separator", fsys.getSeparator());
show("UserPrincipalLookupService",
fsys.getUserPrincipalLookupService());
show("isOpen", fsys.isOpen());
show("isReadOnly", fsys.isReadOnly());
show("FileSystemProvider", fsys.provider());
show("File Attribute Views",
fsys.supportedFileAttributeViews());
}
}
/* 输出:
Windows 10
File Store: SSD (C:)
Root Directory: C:\
Root Directory: D:\
Separator: \
UserPrincipalLookupService:
sun.nio.fs.WindowsFileSystem$LookupService$1@15db9742
isOpen: true
isReadOnly: false
FileSystemProvider:
sun.nio.fs.WindowsFileSystemProvider@6d06d69c
File Attribute Views: [owner, dos, acl, basic, user]
*/
一个 FileSystem 对象也能生成 WatchService 和 PathMatcher 对象,将会在接下来两章中详细讲解。
10.7 路径监听
通过 WatchService 可以设置一个进程对目录中的更改做出响应。在这个例子中,delTxtFiles() 作为一个单独的任务执行,该任务将遍历整个目录并删除以 .txt 结尾的所有文件,WatchService 会对文件删除操作做出反应:
// files/PathWatcher.java
// {ExcludeFromGradle}
import java.io.IOException;
import java.nio.file.*;
import static java.nio.file.StandardWatchEventKinds.*;
import java.util.concurrent.*;
public class PathWatcher {
static Path test = Paths.get("test");
static void delTxtFiles() {
try {
Files.walk(test)
.filter(f ->
f.toString()
.endsWith(".txt"))
.forEach(f -> {
try {
System.out.println("deleting " + f);
Files.delete(f);
} catch(IOException e) {
throw new RuntimeException(e);
}
});
} catch(IOException e) {
throw new RuntimeException(e);
}
}
public static void main(String[] args) throws Exception {
Directories.refreshTestDir();
Directories.populateTestDir();
Files.createFile(test.resolve("Hello.txt"));
WatchService watcher = FileSystems.getDefault().newWatchService();
test.register(watcher, ENTRY_DELETE);
Executors.newSingleThreadScheduledExecutor()
.schedule(PathWatcher::delTxtFiles,
250, TimeUnit.MILLISECONDS);
WatchKey key = watcher.take();
for(WatchEvent evt : key.pollEvents()) {
System.out.println("evt.context(): " + evt.context() +
"\nevt.count(): " + evt.count() +
"\nevt.kind(): " + evt.kind());
System.exit(0);
}
}
}
/* Output:
deleting test\bag\foo\bar\baz\File.txt
deleting test\bar\baz\bag\foo\File.txt
deleting test\baz\bag\foo\bar\File.txt
deleting test\foo\bar\baz\bag\File.txt
deleting test\Hello.txt
evt.context(): Hello.txt
evt.count(): 1
evt.kind(): ENTRY_DELETE
*/
delTxtFiles() 中的 try 代码块看起来有些多余,因为它们捕获的是同一种类型的异常,外部的 try 语句似乎已经足够了。然而出于某种原因,Java 要求两者都必须存在(这也可能是一个 bug)。还要注意的是在 filter() 中,我们必须显式地使用 f.toString() 转为字符串,否则我们调用 endsWith() 将会与整个 Path 对象进行比较,而不是路径名称字符串的一部分进行比较。
一旦我们从 FileSystem 中得到了 WatchService 对象,我们将其注册到 test 路径以及我们感兴趣的项目的变量参数列表中,可以选择 ENTRY_CREATE,ENTRY_DELETE 或 ENTRY_MODIFY(其中创建和删除不属于修改)。
因为接下来对 watcher.take() 的调用会在发生某些事情之前停止所有操作,所以我们希望 deltxtfiles() 能够并行运行以便生成我们感兴趣的事件。为了实现这个目的,我通过调用 Executors.newSingleThreadScheduledExecutor() 产生一个 ScheduledExecutorService 对象,然后调用 schedule() 方法传递所需函数的方法引用,并且设置在运行之前应该等待的时间。
此时,watcher.take() 将等待并阻塞在这里。当目标事件发生时,会返回一个包含 WatchEvent 的 Watchkey 对象。展示的这三种方法是能对 WatchEvent 执行的全部操作。
查看输出的具体内容。即使我们正在删除以 .txt 结尾的文件,在 Hello.txt 被删除之前,WatchService 也不会被触发。你可能认为,如果说"监视这个目录",自然会包含整个目录和下面子目录,但实际上的:只会监视给定的目录,而不是下面的所有内容。如果需要监视整个树目录,必须在整个树的每个子目录上放置一个 Watchservice。
// files/TreeWatcher.java
// {ExcludeFromGradle}
import java.io.IOException;
import java.nio.file.*;
import static java.nio.file.StandardWatchEventKinds.*;
import java.util.concurrent.*;
public class TreeWatcher {
static void watchDir(Path dir) {
try {
WatchService watcher =
FileSystems.getDefault().newWatchService();
dir.register(watcher, ENTRY_DELETE);
Executors.newSingleThreadExecutor().submit(() -> {
try {
WatchKey key = watcher.take();
for(WatchEvent evt : key.pollEvents()) {
System.out.println(
"evt.context(): " + evt.context() +
"\nevt.count(): " + evt.count() +
"\nevt.kind(): " + evt.kind());
System.exit(0);
}
} catch(InterruptedException e) {
return;
}
});
} catch(IOException e) {
throw new RuntimeException(e);
}
}
public static void main(String[] args) throws Exception {
Directories.refreshTestDir();
Directories.populateTestDir();
Files.walk(Paths.get("test"))
.filter(Files::isDirectory)
.forEach(TreeWatcher::watchDir);
PathWatcher.delTxtFiles();
}
}
/* Output:
deleting test\bag\foo\bar\baz\File.txt
deleting test\bar\baz\bag\foo\File.txt
evt.context(): File.txt
evt.count(): 1
evt.kind(): ENTRY_DELETE
*/
在 watchDir() 方法中给 WatchSevice 提供参数 ENTRY_DELETE,并启动一个独立的线程来监视该Watchservice。这里我们没有使用 schedule() 进行启动,而是使用 submit() 启动线程。我们遍历整个目录树,并将 watchDir() 应用于每个子目录。现在,当我们运行 deltxtfiles() 时,其中一个 Watchservice 会检测到每一次文件删除。
10.8 文件查找
到目前为止,为了找到文件,我们一直使用相当粗糙的方法,在 path 上调用 toString(),然后使用 string 操作查看结果。事实证明,java.nio.file 有更好的解决方案:通过在 FileSystem 对象上调用 getPathMatcher() 获得一个 PathMatcher,然后传入您感兴趣的模式。模式有两个选项:glob 和 regex。glob 比较简单,实际上功能非常强大,因此您可以使用 glob 解决许多问题。如果您的问题更复杂,可以使用 regex,这将在接下来的 Strings 一章中解释。
在这里,我们使用 glob 查找以 .tmp 或 .txt 结尾的所有 Path:
// files/Find.java
// {ExcludeFromGradle}
import java.nio.file.*;
public class Find {
public static void main(String[] args) throws Exception {
Path test = Paths.get("test");
Directories.refreshTestDir();
Directories.populateTestDir();
// Creating a *directory*, not a file:
Files.createDirectory(test.resolve("dir.tmp"));
PathMatcher matcher = FileSystems.getDefault()
.getPathMatcher("glob:**/*.{tmp,txt}");
Files.walk(test)
.filter(matcher::matches)
.forEach(System.out::println);
System.out.println("***************");
PathMatcher matcher2 = FileSystems.getDefault()
.getPathMatcher("glob:*.tmp");
Files.walk(test)
.map(Path::getFileName)
.filter(matcher2::matches)
.forEach(System.out::println);
System.out.println("***************");
Files.walk(test) // Only look for files
.filter(Files::isRegularFile)
.map(Path::getFileName)
.filter(matcher2::matches)
.forEach(System.out::println);
}
}
/* Output:
test\bag\foo\bar\baz\5208762845883213974.tmp
test\bag\foo\bar\baz\File.txt
test\bar\baz\bag\foo\7918367201207778677.tmp
test\bar\baz\bag\foo\File.txt
test\baz\bag\foo\bar\8016595521026696632.tmp
test\baz\bag\foo\bar\File.txt
test\dir.tmp
test\foo\bar\baz\bag\5832319279813617280.tmp
test\foo\bar\baz\bag\File.txt
***************
5208762845883213974.tmp
7918367201207778677.tmp
8016595521026696632.tmp
dir.tmp
5832319279813617280.tmp
***************
5208762845883213974.tmp
7918367201207778677.tmp
8016595521026696632.tmp
5832319279813617280.tmp
*/
在 matcher 中,glob 表达式开头的 **/ 表示“当前目录及所有子目录”,这在当你不仅仅要匹配当前目录下特定结尾的 Path 时非常有用。单 * 表示“任何东西”,然后是一个点,然后大括号表示一系列的可能性—我们正在寻找以 .tmp 或 .txt 结尾的东西。您可以在 getPathMatcher() 文档中找到更多详细信息。
matcher2 只使用 *.tmp,通常不匹配任何内容,但是添加 map() 操作会将完整路径减少到末尾的名称。
注意,在这两种情况下,输出中都会出现 dir.tmp,即使它是一个目录而不是一个文件。要只查找文件,必须像在最后 files.walk() 中那样对其进行筛选。
10.9 文件读写
此时,我们可以对路径和目录做任何事情。 现在让我们看一下操纵文件本身的内容。
如果一个文件很“小”,也就是说“它运行得足够快且占用内存小”,那么 java.nio.file.Files 类中的实用程序将帮助你轻松读写文本和二进制文件。
Files.readAllLines() 一次读取整个文件(因此,“小”文件很有必要),产生一个List。 对于示例文件,我们将重用streams/Cheese.dat:
// files/ListOfLines.java
import java.util.*;
import java.nio.file.*;
public class ListOfLines {
public static void main(String[] args) throws Exception {
Files.readAllLines(
Paths.get("../streams/Cheese.dat"))
.stream()
.filter(line -> !line.startsWith("//"))
.map(line ->
line.substring(0, line.length()/2))
.forEach(System.out::println);
}
}
/* Output:
Not much of a cheese
Finest in the
And what leads you
Well, it's
It's certainly uncon
*/
跳过注释行,其余的内容每行只打印一半。 这实现起来很简单:你只需将 Path 传递给 readAllLines() (以前的 java 实现这个功能很复杂)。readAllLines() 有一个重载版本,包含一个 Charset 参数来存储文件的 Unicode 编码。
Files.write() 被重载以写入 byte 数组或任何 Iterable 对象(它也有 Charset 选项):
// files/Writing.java
import java.util.*;
import java.nio.file.*;
public class Writing {
static Random rand = new Random(47);
static final int SIZE = 1000;
public static void main(String[] args) throws Exception {
// Write bytes to a file:
byte[] bytes = new byte[SIZE];
rand.nextBytes(bytes);
Files.write(Paths.get("bytes.dat"), bytes);
System.out.println("bytes.dat: " + Files.size(Paths.get("bytes.dat")));
// Write an iterable to a file:
List lines = Files.readAllLines(
Paths.get("../streams/Cheese.dat"));
Files.write(Paths.get("Cheese.txt"), lines);
System.out.println("Cheese.txt: " + Files.size(Paths.get("Cheese.txt")));
}
}
/* Output:
bytes.dat: 1000
Cheese.txt: 199
*/
我们使用 Random 来创建一个随机的 byte 数组; 你可以看到生成的文件大小是 1000。
一个 List 被写入文件,任何 Iterable 对象也可以这么做。
如果文件大小有问题怎么办? 比如说:
- 文件太大,如果你一次性读完整个文件,你可能会耗尽内存。
- 您只需要在文件的中途工作以获得所需的结果,因此读取整个文件会浪费时间。
Files.lines() 方便地将文件转换为行的 Stream:
// files/ReadLineStream.java
import java.nio.file.*;
public class ReadLineStream {
public static void main(String[] args) throws Exception {
Files.lines(Paths.get("PathInfo.java"))
.skip(13)
.findFirst()
.ifPresent(System.out::println);
}
}
/* Output:
show("RegularFile", Files.isRegularFile(p));
*/
这对本章中第一个示例代码做了流式处理,跳过 13 行,然后选择下一行并将其打印出来。
Files.lines() 对于把文件处理行的传入流时非常有用,但是如果你想在 Stream 中读取,处理或写入怎么办?这就需要稍微复杂的代码:
// files/StreamInAndOut.java
import java.io.*;
import java.nio.file.*;
import java.util.stream.*;
public class StreamInAndOut {
public static void main(String[] args) {
try(
Stream input =
Files.lines(Paths.get("StreamInAndOut.java"));
PrintWriter output =
new PrintWriter("StreamInAndOut.txt")
) {
input.map(String::toUpperCase)
.forEachOrdered(output::println);
} catch(Exception e) {
throw new RuntimeException(e);
}
}
}
因为我们在同一个块中执行所有操作,所以这两个文件都可以在相同的 try-with-resources 语句中打开。PrintWriter 是一个旧式的 java.io 类,允许你“打印”到一个文件,所以它是这个应用的理想选择。如果你看一下 StreamInAndOut.txt,你会发现它里面的内容确实是大写的。
10.10 本章小结
虽然本章对文件和目录操作做了相当全面的介绍,但是仍然有没被介绍的类库中的功能——一定要研究 java.nio.file 的 Javadocs,尤其是 java.nio.file.Files 这个类。
Java 7 和 8 对于处理文件和目录的类库做了大量改进。如果您刚刚开始使用 Java,那么您很幸运。在过去,它令人非常不愉快,我确信 Java 设计者以前对于文件操作不够重视才没做简化。对于初学者来说这是一件很棒的事,对于教学者来说也一样。我不明白为什么花了这么长时间来解决这个明显的问题,但不管怎么说它被解决了,我很高兴。使用文件现在很简单,甚至很有趣,这是你以前永远想不到的。
第 11 章 运行期类型鉴定
运行期类型鉴定(RTTI)的概念初看非常简单——手上只有基础类型的一个句柄时,利用它判断一个对象的正确类型。
11.1 对 RTTI 的需要
若碰到一个特殊的程序设计问题,只有在知道常规句柄的确切类型后,才能最容易地解决这个问题,这个时候又该怎么办呢?举个例子来说,我们有时候想让自己的用户将某一具体类型的几何形状(如三角形)全都变成紫色,以便突出显示它们,并快速找出这一类型的所有形状。此时便要用到RTTI 技术,用它查询某个Shape 句柄引用的准确类型是什么。
11.1.1 Class 对象
对于作为程序一部分的每个类,它们都有一个Class 对象。换言之,每次写一个新类时,同时也会创建一个Class 对象(更恰当地说,是保存在一个完全同名的.class 文件中)。在运行期,一旦我们想生成那个类的一个对象,用于执行程序的Java 虚拟机(JVM)首先就会检查那个类型的Class 对象是否已经载入。若尚未载入,JVM 就会查找同名的.class 文件,并将其载入。所以Java 程序启动时并不是完全载入的,这一点与许多传统语言都不同。
一旦那个类型的Class 对象进入内存,就用它创建那一类型的所有对象。
- 类标记
在Java 1.1 中,可以采用第二种方式来产生Class 对象的句柄:使用“类标记”。对上述程序来说,看起来就象下面这样:
Gum.class;
这样做不仅更加简单,而且更安全,因为它会在编译期间得到检查。由于它取消了对方法调用的需要,所以执行的效率也会更高。
类标记不仅可以应用于普通类,也可以应用于接口、数组以及基本数据类型。除此以外,针对每种基本数据类型的封装器类,它还存在一个名为TYPE 的标准字段。TYPE 字段的作用是为相关的基本数据类型产生Class对象的一个句柄。
11.1.2 造型前的检查
RTTI 在Java 中存在三种形式。关键字instanceof 告诉我们对象是不是一个特定类型的实例(Instance 即“实例”)。它会返回一个布尔值,以便以问题的形式使用,就象下面这样:
if(x instanceof Dog)
((Dog)x).bark();
将x 造型至一个Dog 前,上面的if 语句会检查对象x 是否从属于Dog 类。进行造型前,如果没有其他信息可以告诉自己对象的类型,那么instanceof 的使用是非常重要的——否则会得到一个ClassCastException 违例。
11.2 RTTI 语法
Java 用Class 对象实现自己的RTTI 功能——即便我们要做的只是象造型那样的一些工作。Class 类也提供了其他大量方式,以方便我们使用RTTI。
首先必须获得指向适当Class 对象的的一个句柄。就象前例演示的那样,一个办法是用一个字串以及Class.forName()方法。这是非常方便的,因为不需要那种类型的一个对象来获取Class 句柄。然而,对于自己感兴趣的类型,如果已有了它的一个对象,那么为了取得Class 句柄,可调用属于Object 根类一部分的一个方法:getClass()。它的作用是返回一个特定的Class 句柄,用来表示对象的实际类型。
11.3 反射:运行期类信息
如果不知道一个对象的准确类型,RTTI 会帮助我们调查。但却有一个限制:类型必须是在编译期间已知的,否则就不能用RTTI 调查它,进而无法展开下一步的工作。换言之,编译器必须明确知道RTTI 要处理的所有类。
在Java 1.1 中,Class 类(本章前面已有详细论述)得到了扩展,可以支持“反射”的概念。针对Field,Method 以及Constructor 类(每个都实现了Memberinterface——成员接口),它们都新增了一个库:java.lang.reflect。这些类型的对象都是JVM 在运行期创建的,用于代表未知类里对应的成员。这样便可用构建器创建新对象,用get()和set()方法读取和修改与Field 对象关联的字段,以及用invoke()方法调用与Method 对象关联的方法。此外,我们可调用方法getFields(),getMethods(),getConstructors(),分别返回用于表示字段、方法以及构建器的对象数组(在联机文档中,还可找到与Class 类有关的更多的资料)。因此,匿名对象的类信息可在运行期被完整的揭露出来,而在编译期间不需要知道任何东西。
RTTI 和“反射”之间唯一的区别就是对RTTI 来说,编译器会在编译期打开和检查.class 文件。
11.3.1 一个类方法提取器
我们许多时候仍然需要动态提取与一个类有关的资料。其中特别有用的工具便是一个类方法提取器。正如前面指出的那样,若检视类定义源码或者联机文档,只能看到在那个类定义中被定义或覆盖的方法,基础类那里还有大量资料拿不到。幸运的是,“反射”做到了这一点,可用它写一个简单的工具,令其自动展示整个接口。
第 12 章 传递和返回对象
准确地说,Java 是有指针的!事实上,Java 中每个对象(除基本数据类型以外)的标识符都属于指针的一种。但它们的使用受到了严格的限制和防范,不仅编译器对它们有“戒心”,运行期系统也不例外。或者换从另一个角度说,Java 有指针,但没有传统指针的麻烦。我曾一度将这种指针叫做“句柄”,但你可以把它想像成“安全指针”。
12.1 传递句柄
将句柄传递进入一个方法时,指向的仍然是相同的对象。
12.1.1 别名问题
“别名”意味着多个句柄都试图指向同一个对象,就象前面的例子展示的那样。若有人向那个对象里写入一点什么东西,就会产生别名问题。
一旦准备将句柄作为一个自变量或参数传递——这是Java 设想的正常方法——别名问题就会自动出现,因为创建的本地句柄可能修改“外部对象”(在方法作用域之外创建的对象)。
12.2 制作本地副本
Java 中的所有自变量或参数传递都是通过传递句柄进行的。也就是说,当我们传递“一个对
象”时,实际传递的只是指向位于方法外部的那个对象的“一个句柄”。所以一旦要对那个句柄进行任何修改,便相当于修改外部对象。
■参数传递过程中会自动产生别名问题
■不存在本地对象,只有本地句柄
■句柄有自己的作用域,而对象没有
■对象的“存在时间”在Java 里不是个问题
■没有语言上的支持(如常量)可防止对象被修改(以避免别名的副作用)
12.2.1 按值传递
Java 主要按值传递(无自变量),但对象却是按引用传递的。得到这个结论的前提是句柄只是对象的一个“别名”,所以不考虑传递句柄的问题,而是直接指出“我准备传递对象”。由于将其传递进入一个方法时没有获得对象的一个本地副本,所以对象显然不是按值传递的。Sun 公司似乎在某种程度上支持这一见解,因为它“保留但未实现”的关键字之一便是byvalue(按值)。
12.2.2 克隆对象
若需修改一个对象,同时不想改变调用者的对象,就要制作该对象的一个本地副本。这也是本地副本最常见的一种用途。若决定制作一个本地副本,只需简单地使用clone()方法即可。这个方法在基础类Object 中定义成“protected”(受保护)模式。但在希望克隆的任何衍生类中,必须将其覆盖为“public”模式。
12.2.3 使类具有克隆能力
如果想在一个类里使用克隆方法,唯一的办法就是专门添加一些代码,以便保证克隆的正常进行。
-
使用 protected 时的技巧
为避免我们创建的每个类都默认具有克隆能力,clone()方法在基础类Object 里得到了“保留”(设为 protected)。这样造成的后果就是:对那些简单地使用一下这个类的客户程序员来说,他们不会默认地拥有这个方法;其次,我们不能利用指向基础类的一个句柄来调用clone()。
但是,假若我们是在一个从Object 衍生出来的类中(所有类都是从Object 衍生的),就有权调用
Object.clone(),因为它是“protected”,而且我们在一个继承器中。基础类clone()提供了一个有用的功能——它进行的是对衍生类对象的真正“按位”复制,所以相当于标准的克隆行动。然而,我们随后需要将自己的克隆操作设为public,否则无法访问。总之,克隆时要注意的两个关键问题是:几乎肯定要调用super.clone(),以及注意将克隆设为public。 -
实现 Cloneable 接口
为使一个对象的克隆能力功成圆满,还需要做另一件事情:实现Cloneable 接口。这个接口使人稍觉奇怪,因为它是空的!
interface Cloneable {}
之所以要实现这个空接口,显然不是因为我们准备上溯造型成一个Cloneable,以及调用它的某个方法。有些人认为在这里使用接口属于一种“欺骗”行为,因为它使用的特性打的是别的主意,而非原来的意思。Cloneable interface 的实现扮演了一个标记的角色,封装到类的类型中。
两方面的原因促成了Cloneable interface 的存在。首先,可能有一个上溯造型句柄指向一个基础类型,而
且不知道它是否真的能克隆那个对象。在这种情况下,可用instanceof 关键字(第11 章有介绍)调查句柄是否确实同一个能克隆的对象连接:
if(myHandle instanceof Cloneable) // …
第二个原因是考虑到我们可能不愿所有对象类型都能克隆。所以Object.clone()会验证一个类是否真的是实现了Cloneable 接口。若答案是否定的,则“掷”出一个CloneNotSupportedException 违例。所以在一般情况下,我们必须将“implement Cloneable”作为对克隆能力提供支持的一部分。
12.2.4 成功的克隆
clone()必须能够访问,所以必须将其设为public(公共的)。其次,作为clone()的初期行动,
应调用clone()的基础类版本。这里调用的clone()是Object 内部预先定义好的。之所以能调用它,是由于它具有protected(受到保护的)属性,所以能在衍生的类里访问。
Object.clone()会检查原先的对象有多大,再为新对象腾出足够多的内存,将所有二进制位从原来的对象复制到新对象。这叫作“按位复制”,而且按一般的想法,这个工作应该是由clone()方法来做的。但在Object.clone()正式开始操作前,首先会检查一个类是否Cloneable,即是否具有克隆能力——换言之,它是否实现了Cloneable 接口。若未实现,Object.clone()就掷出一个CloneNotSupportedException 违例,指出我们不能克隆它。因此,我们最好用一个try-catch 块将对super.clone()的调用代码包围(或封装)起来,试图捕获一个应当永不出现的违例(因为这里确实已实现了Cloneable 接口)。
==和!=运算符只是简单地对比句柄的内容。若句柄内的地址相同,就认为句柄指向同样的对象,所以认为它们是“等价”的。
12.2.5 Object.clone() 的效果
通常可在从一个能克隆的类里调用super.clone(),以确保所有基础类行动(包括Object.clone())能够进行。随着是为对象内每个句柄都明确调用一个clone();否则那些句柄会别名变成原始对象的句柄。构建器的调用也大致相同——首先构造基础类,然后是下一个衍生的构建器⋯⋯以此类推,直到位于最深层的衍生构建器。区别在于clone()并不是个构建器,所以没有办法实现自动克隆。为了克隆,必须由自己明确进行。
12.2.6 克隆合成对象
为了能正常实现深层复制,必须对所有类中的代码进行控制,或者至少全面掌握深层复制中需要涉及的类,确保它们自己的深层复制能正确进行。
如果在拷贝一个对象时,要想让这个拷贝的对象和源对象完全彼此独立,那么在引用链上的每一级对象都要被显式的拷贝。所以创建彻底的深拷贝是非常麻烦的,尤其是在引用关系非常复杂的情况下, 或者在引用链的某一级上引用了一个第三方的对象, 而这个对象没有实现clone方法, 那么在它之后的所有引用的对象都是被共享的。
12.2.7 用 Vector 进行深层复制
Vector 进行深层复制的先决条件:在克隆了Vector 后,必须在其中遍历,并克隆由Vector 指向的每个对象。为了对Hashtable(散列表)进行深层复制,也必须采取类似的处理。
12.2.8 通过序列化进行深层复制
Serializable 类很容易设置,但在复制它们时却要做多得多的工作。克隆涉及到大量的类设置工作,但实际的对象复制是相当简单的。除了序列化和克隆之间巨大的时间差异以外,我们也注意到序列化技术的运行结果并不稳定,而克隆每一次花费的时间都是相同的。
12.2.9 使克隆具有更大的深度
若新建一个类,它的基础类会默认为Object,并默认为不具备克隆能力(就象在下一节会看到的那样)。只要不明确地添加克隆能力,这种能力便不会自动产生。但我们可以在任何层添加它,然后便可从那个层开始向下具有克隆能力。
12.2.10 为什么有这个奇怪的设计
突然地,人们提出了安全问题,而且理所当然,这些问题与使用对象有关,我们不愿望任何人克隆自己的保密对象。所以我们最后看到的是为原来那个简单、直观的方案添加的大量补丁:clone()在Object 里被设置成“protected”。必须将其覆盖,并使用“implement Cloneable”,同时解决违例的问题。
只有在准备调用Object 的clone()方法时,才没有必要使用Cloneable 接口,因为那个方法会在运行期间得到检查,以确保我们的类实现了Cloneable。但为了保持连贯性(而且由于Cloneable 无论如何都是空的),最好还是由自己实现Cloneable。
12.3 克隆的控制
我们有必要控制一个对象是否能够克隆。对于我们设计的一个类,实际有许多种方案都是可以采取的:
(1) 保持中立,不为克隆做任何事情。也就是说,尽管不可对我们的类克隆,但从它继承的一个类却可根据实际情况决定克隆。只有Object.clone()要对类中的字段进行某些合理的操作时,才可以作这方面的决定。
(2) 支持clone(),采用实现Cloneable(可克隆)能力的标准操作,并覆盖clone()。在被覆盖的clone()中,可调用super.clone(),并捕获所有违例(这样可使clone()不“掷”出任何违例)。
(3) 有条件地支持克隆。若类容纳了其他对象的句柄,而那些对象也许能够克隆(集合类便是这样的一个例子),就可试着克隆拥有对方句柄的所有对象;如果它们“掷”出了违例,只需让这些违例通过即可。举个例子来说,假设有一个特殊的Vector,它试图克隆自己容纳的所有对象。编写这样的一个Vector 时,并不知道客户程序员会把什么形式的对象置入这个Vector 中,所以并不知道它们是否真的能够克隆。
(4) 不实现Cloneable(),但是将clone()覆盖成protected,使任何字段都具有正确的复制行为。这样一来,从这个类继承的所有东西都能覆盖clone(),并调用super.clone() 来产生正确的复制行为。注意在我们实现方案里,可以而且应该调用super.clone()——即使那个方法本来预期的是一个Cloneable 对象(否则会掷出一个违例),因为没有人会在我们这种类型的对象上直接调用它。它只有通过一个衍生类调用;对那个衍生类来说,如果要保证它正常工作,需实现Cloneable。
(5) 不实现Cloneable 来试着防止克隆,并覆盖clone(),以产生一个违例。为使这一设想顺利实现,只有令从它衍生出来的任何类都调用重新定义后的clone()里的suepr.clone()。
(6) 将类设为final,从而防止克隆。若clone()尚未被我们的任何一个上级类覆盖,这一设想便不会成功。若已被覆盖,那么再一次覆盖它,并“掷”出一个CloneNotSupportedException(克隆不支持)违例。为担保克隆被禁止,将类设为final 是唯一的办法。除此以外,一旦涉及保密对象或者遇到想对创建的对象数量进行控制的其他情况,应该将所有构建器都设为private,并提供一个或更多的特殊方法来创建对象。采用这种方式,这些方法就可以限制创建的对象数量以及它们的创建条件——一种特殊情况是第16 章要介绍的singleton(独子)方案。
12.3.1 副本构建器
克隆看起来要求进行非常复杂的设置,似乎还该有另一种替代方案。一个办法是制作特殊的构建器,令其负责复制一个对象。
12.4 只读类
假如想制作一个库,令其具有常规用途,但却不能担保它肯定能在正确的类中得以克隆,这时又该怎么办呢?更有可能的一种情况是,假如我们想让别名发挥积极的作用——禁止不必要的对象复制——但却不希望看到由此造成的副作用,那么又该如何处理呢?
一个办法是创建“不变对象”,令其从属于只读类。可定义一个特殊的类,使其中没有任何方法能造成对象内部状态的改变。在这样的一个类中,别名处理是没有问题的。因为我们只能读取内部状态,所以当多处代码都读取相同的对象时,不会出现任何副作用。
12.4.1 创建只读类
//: Immutable1.java
// Objects that cannot be modified
// are immune to aliasing.
public class Immutable1 {
private int data;
public Immutable1(int initVal) {
data = initVal;
}
public int read() { return data; }
371
public boolean nonzero() { return data != 0; }
public Immutable1 quadruple() {
return new Immutable1(data * 4);
}
static void f(Immutable1 i1) {
Immutable1 quad = i1.quadruple();
System.out.println("i1 = " + i1.read());
System.out.println("quad = " + quad.read());
}
public static void main(String[] args) {
Immutable1 x = new Immutable1(47);
System.out.println("x = " + x.read());
f(x);
System.out.println("x = " + x.read());
}
} ///:~
所有数据都设为private,可以看到没有任何public 方法对数据作出修改。事实上,确实需要修改一个对象的方法是quadruple(),但它的作用是新建一个Immutable1 对象,初始对象则是原封未动的。
12.4.2 “一成不变”的弊端
从表面看,不变类的建立似乎是一个好方案。但是,一旦真的需要那种新类型的一个修改的对象,就必须辛苦地进行新对象的创建工作,同时还有可能涉及更频繁的垃圾收集。对有些类来说,这个问题并不是很大。但对其他类来说(比如String 类),这一方案的代价显得太高了
这一方法特别适合在下述场合应用:
(1) 需要不可变的对象,而且
(2) 经常需要进行大量修改,或者
(3) 创建新的不变对象代价太高
12.4.3 不变字串
-
隐式常数
若使用下述语句:
String s = “asdf”;
String x = Stringer.upcase(s);
那么真的希望upcase()方法改变自变量或者参数吗?我们通常是不愿意的,因为作为提供给方法的一种信息,自变量一般是拿给代码的读者看的,而不是让他们修改。这是一个相当重要的保证,因为它使代码更易编写和理解。 -
覆盖"+"和StringBuffer
在 Java 8 中,String 内部使用 char 数组存储数据。
public final class String implements java.io.Serializable, Comparable<String>, CharSequence { /** The value is used for character storage. */ private final char value[]; }在 Java 9 之后,String 类的实现改用 byte 数组存储字符串,同时使用
coder来标识使用了哪种编码。public final class String implements java.io.Serializable, Comparable<String>, CharSequence { /** The value is used for character storage. */ private final byte[] value; /** The identifier of the encoding used to encode the bytes in {@code value}. */ private final byte coder; }value 数组被声明为 final,这意味着 value 数组初始化之后就不能再引用其它数组。并且 String 内部没有改变 value 数组的方法,因此可以保证 String 不可变。
针对String 对象使用时,“+”允许我们将不同的字串连接起来
编译
器可以自动创建一个StringBuffer,以便计算特定的表达式,特别是面向String 对象应用覆盖过的运算符+和+=时。
12.4.4 String、StringBuffer 和 StringBuilder 类
当对字符串进行修改的时候,需要使用 StringBuffer 和 StringBuilder 类。
和 String 类不同的是,StringBuffer 和 StringBuilder 类的对象能够被多次的修改,并且不产生新的未使用对象。
StringBuilder 类在 Java 5 中被提出,它和 StringBuffer 之间的最大不同在于 StringBuilder 的方法不是线程安全的(不能同步访问)。
由于 StringBuilder 相较于 StringBuffer 有速度优势,所以多数情况下建议使用 StringBuilder 类。然而在应用程序要求线程安全的情况下,则必须使用 StringBuffer 类。
StringBuffer 方法:
以下是 StringBuffer 类支持的主要方法:
| 序号 | 方法描述 |
|---|---|
| 1 | public StringBuffer append(String s) 将指定的字符串追加到此字符序列。 |
| 2 | public StringBuffer reverse() 将此字符序列用其反转形式取代。 |
| 3 | public delete(int start, int end) 移除此序列的子字符串中的字符。 |
| 4 | public insert(int offset, int i) 将 int 参数的字符串表示形式插入此序列中。 |
| 5 | replace(int start, int end, String str) 使用给定 String 中的字符替换此序列的子字符串中的字符。 |
下面的列表里的方法和 String 类的方法类似:
| 序号 | 方法描述 |
|---|---|
| 1 | int capacity() 返回当前容量。 |
| 2 | char charAt(int index) 返回此序列中指定索引处的 char 值。 |
| 3 | void ensureCapacity(int minimumCapacity) 确保容量至少等于指定的最小值。 |
| 4 | void getChars(int srcBegin, int srcEnd, char[] dst, int dstBegin) 将字符从此序列复制到目标字符数组 dst。 |
| 5 | int indexOf(String str) 返回第一次出现的指定子字符串在该字符串中的索引。 |
| 6 | int indexOf(String str, int fromIndex) 从指定的索引处开始,返回第一次出现的指定子字符串在该字符串中的索引。 |
| 7 | int lastIndexOf(String str) 返回最右边出现的指定子字符串在此字符串中的索引。 |
| 8 | int lastIndexOf(String str, int fromIndex) 返回 String 对象中子字符串最后出现的位置。 |
| 9 | int length() 返回长度(字符数)。 |
| 10 | void setCharAt(int index, char ch) 将给定索引处的字符设置为 ch。 |
| 11 | void setLength(int newLength) 设置字符序列的长度。 |
| 12 | CharSequence subSequence(int start, int end) 返回一个新的字符序列,该字符序列是此序列的子序列。 |
| 13 | String substring(int start) 返回一个新的 String,它包含此字符序列当前所包含的字符子序列。 |
| 14 | String substring(int start, int end) 返回一个新的 String,它包含此序列当前所包含的字符子序列。 |
| 15 | String toString() 返回此序列中数据的字符串表示形式。 |