散列表?B-树?B+树?原来是这么个玩意
散列表
散列表(也称哈希表)是根据关键码值(Key value)而直接进行访问的数据结构,它让码值经过哈希函数的转换映射到散列表对应的位置上,查找效率非常高。哈希索引就是基于散列表实现的,假设我们对名字建立了哈希索引,则查找过程如下图所示:

对于每一行数据,存储引擎都会对所有的索引列(上图中的 name 列)计算一个哈希码(上图散列表的位置),散列表里的每个元素指向数据行的指针,由于索引自身只存储对应的哈希值,所以索引的结构十分紧凑,这让哈希索引查找速度非常快!但是哈希索引也有它的劣势,如下:
- 针对哈希索引,只有精确匹配索引所有列的查询才有效,比如我在列(A,B)上建立了哈希索引,如果只查询数据列 A,则无法使用该索引
- 哈希索引并不是按照索引值顺序存存储的,所以也就无法用于排序,也就是说无法根据区间快速查找
- 哈希索引只包含哈希值和行指针,不存储字段值,所以不能使用索引中的值来避免读取行
- 哈希索引只支持等值比较查询,包括 =,IN(),不支持任何范围的查找,如 age > 17
在 InnoDB 引擎中,有一种特殊的功能叫「自适应哈希索引」,如果 InnoDB 注意到某些索引列值被频繁使用时,它会在内存基于 B+ 树索引之上再创建一个哈希索引,这样就能让 B+树也具有哈希索引的优点,比如快速的哈希查找
跳表
跳表,是基于链表实现的一种类似“二分”的算法,它可以快速的实现增,删,改,查操作。
简单地说,跳表是在链表之上加上多层索引构成的
先来看一下单向链表如何实现查找

当我们要在该单链表中查找某个数据的时候需要的时间复杂度为O(n)
如果我们给该单链表加一级索引,将会改善查询效率
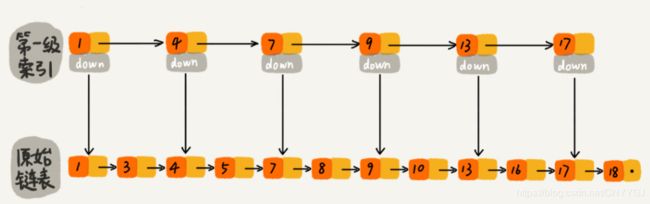
如图所示,当我们每隔一个节点就提取出来一个元素到上一层,把这一层称作索引,其中的down指针指向原始链表。
当我们查找元素16的时候,单链表需要比较10次,而加过索引的两级链表只需要比较7次。当数据量增大到一定程度的时候,效率将会有显著的提升
跳表的查询时间复杂度可以达到O(logn)
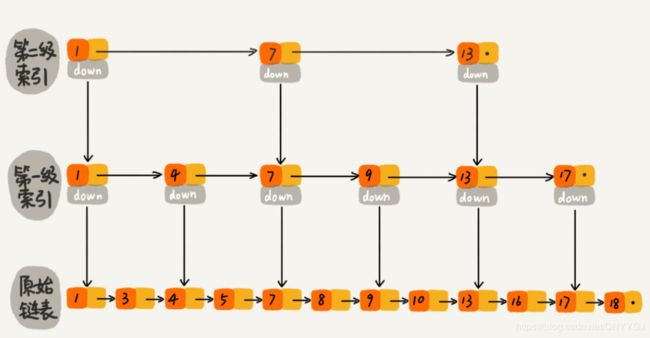
如果我们再加多几级索引的话,效率将会进一步提升。这种链表加多级索引的结构,就叫做跳表
B-树
平衡多路查找树
what ??? 平衡@#¥%树? 稳住,能赢!!!
首先我们先看一下什么是平衡二叉树?
平衡二叉树又称为AVL树,是一种特殊的二叉排序树
emmmmm..... 什么又是二叉排序树(BST树)????
我们来看一下二叉排序树的特性(⚠️ 二叉排序树可以是空树):
- 若它的左子树不空,则左子树上所有关键字的值均小于根关键字的值
- 若它的右子树不空,则右子树上所有关键字的值均大于根关键字的值
- 左右子树又各是一棵二叉排序树
好,了解完特性,我们来看看二叉排序树到底长什么样字?

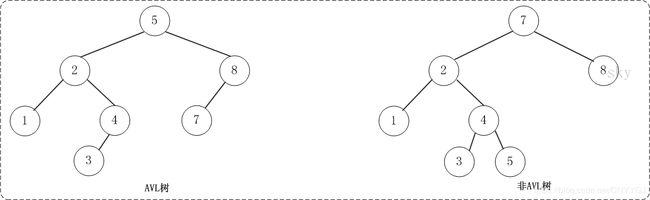
二叉查找树可以任意地构造,同样是2,3,5,6,7,8这六个数字,也可以按照下图的方式来构造:

但是这棵二叉树的查询效率就低了(二叉排序树越矮查找效率越高)。因此若想二叉树的查询效率尽可能高,需要这棵二叉树是平衡的,从而引出新的定义——平衡二叉树,或称AVL树
AVL树(平衡二叉树)有以下特性:
- 首先它是一个二叉排序树,具有二叉排序树的全部性质
- 其次,其左右子树都是平衡二叉树,且左右子树高度之差的绝对值不超过1
一句话概括就是:平衡二叉树是一种特殊的二叉排序树,以树中所有结点为根的树的左右子树高度之差的绝对值不能超过1
最终,平衡二叉树它是长这样的:
好,知道了二叉排序树(BST树),平衡二叉树(AVL树)后,我们看一下主角 B-树 (平衡多路查找树)
B-树中,含有最多分支数的结点,该结点分支树的总数就是B-树的阶,通常用m表示,从查找效率考虑,要求m>=3
一棵m阶的B-树或者一棵空树,或者是满足以下要求的m叉树
- 每个结点最多有m个分支(实际为指向子树的指针,下文用P表示),而最少分支数要看是否为根结点,如果是根结点且不是叶子结点,则至少有两个分支,非根非叶子结点至少有⌈m/2⌉个分支(⌈⌉为向上取整符号)
- 每个结点n个关键字(下文用K表示),由于关键字的个数等于分支数减一,即 n = m - 1,所以在B-树中,根结点关键字的取值范围为1 <= n <= m-1,除根结点外,其他结点中关键字的取值范围为⌈m/2⌉ - 1 <= n <= m - 1
- Kℹ(1 <= i <= n)为关键字,结点内各关键字互不相等,且按从小到大排序,即 Kℹ < K(ℹ+1)
- Pℹ(0 <= i <=n)为指向子树根节点的指针,且满足P(ℹ-1)(1 <= i <= n-1)指向的子树的所有节点关键字均大于Kℹ且小于K(ℹ+1),当然Po所指结点上的关键字小于K1,Pn所指结点上的关键字大于Kn
- 所有叶子结点都在同一层
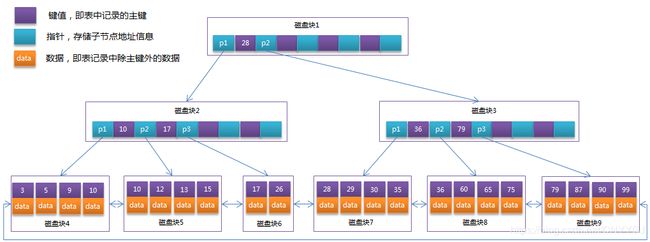
了解了B-树的特性后,是不是很好奇B-树长啥挫样?呐~看下面:

没错,这就是一个3阶的B-树(为什么是3阶你明白了吗?)
通过上面的图我们可以看到:
- 每个节点占用一个==磁盘块==的磁盘空间,指针存储的是子节点所在磁盘块的地址
- 每个节点中不仅包含数据的键值,还有对应的数据记录
模拟查找关键字29的过程:
- 根据根节点找到磁盘块1,读入内存。【磁盘I/O操作第1次】
- 比较关键字29在区间(17,35),找到磁盘块1的指针P2。
- 根据P2指针找到磁盘块3,读入内存。【磁盘I/O操作第2次】
- 比较关键字29在区间(26,30),找到磁盘块3的指针P2。
- 根据P2指针找到磁盘块8,读入内存。【磁盘I/O操作第3次】
- 在磁盘块8中的关键字列表中找到关键字29。
从上面的过程可以看出,整个 查找需要3次磁盘I/O操作,和3次内存查找操作。由于内存中的关键字是一个有序表结构,可以利用二分法查找提高效率。而3次磁盘I/O操作是影响整个B-Tree查找效率的决定因素。B-Tree相对于AVLTree(平衡二叉树)缩减了节点个数,使每次磁盘I/O取到内存的数据都发挥了作用,从而提高了查询效率
通过上面的图,有个概念叫磁盘块
系统从磁盘读取数据到内存时是以磁盘块(block)为基本单位的,位于同一个磁盘块中的数据会被一次性读取出来,而不是需要什么取什么
那什么叫页(Page)呢?
页是InnoDB存储引擎中的概念,页是其磁盘管理的最小单位,InnoDB存储引擎中默认每个页的大小为16KB
在计算机里,无论是内存还是磁盘,操作系统都是按页的大小进行读取的,磁盘每次读取都会预读,会提前将连续的数据读入内存中,这样就避免了多次 IO,这就是计算机中有名的局部性原理
即我用到一块数据,很大可能这块数据附近的数据也会被用到,干脆一起加载,省得多次 IO 拖慢速度,以此提高查询效率
这个连续数据有多大呢,这个连续数据就是 MySQL 的页,默认值为 16 KB,页大小并不是越大越好,InnoDB 是通过内存中的缓存池(pool buffer)来管理从磁盘中读取的页数据的页太大的话,很快就把这个缓存池撑满了,可能会造成页在内存与磁盘间频繁换入换出,影响性能
B+树
B+树是在B-树的基础上的一种优化,
使其更适合实现外存储索引结构,InnoDB存储引擎就是用B+Tree实现其索引结构
B+树相对B-树有几点不同:
- 有n个关键字的结点就有n个分支(指针)
- 每个结点(除根结点外)中的关键字个数n的取之范围为⌈m/2⌉ <= n <= m,根结点的取值范围为2 <= n <= m
- 非叶子结点只存储键值信息,即所有非叶子结点仅起到一个索引的作用,而数据记录都存放在叶子结点中
- 在B+树上有一个指针指向关键字最小的叶子结点,所有叶子结点之间都有一个链指针,链接成一个线性链表
下面看一下B+树的容颜:
B-Tree结构图中可以看到每个节点中不仅包含数据的key值,还有data值。而每一个页的存储空间是有限的,如果data数据较大时将会导致每个结点(即一个页)能存储的key的数量很小,当存储的数据量很大时同样会导致B-Tree的深度较大,增大查询时的磁盘I/O次数,进而影响查询效率。在B+Tree中,所有数据记录节点都是按照键值大小顺序存放在同一层的叶子结点上,而非叶子结点上只存储key值信息,这样可以大大加大每个节点存储的key值数量,降低B+Tree的高度
InnoDB存储引擎中,一个16KB大小的页可以存多少条数据呢?
一般表的主键类型为INT(占用4个字节)或BIGINT(占用8个字节),指针类型也一般为4或8个字节,也就是说一个页,中大概存储16KB/(8B+8B)=1K个键值(因为是估值,为方便计算,这里的K取值为〖10〗^3)。
也就是说一个深度为3的B+Tree索引可以维护10^3 * 10^3 * 10^3 = 10亿 条记录
页分裂 与 页合并
B+ 树为了维护索引的有序性,每插入或更新一条记录的时候,会对索引进行更新
以3阶B+树为例,
假设当某个结点的关键字总数为3(以达到最大关键字数量),如果恰好需要再往该结点上插入关键字时,显然就不再符合B+ 树条件,这时就会造成页分裂,以调整这个节点以让它符合B+ 树条件。页分裂造成的调整必然导致性能的下降
什么时候会发生页合并呢?答案是在删除记录的时候,当删除表记录的时候,索引也要删除。此时就有可能发生页合并
为什么官方建议使用自增长主键作为索引?
结合B+Tree的特点,自增主键是连续的,在插入过程中尽量减少页分裂,即使要进行页分裂,也只会分裂很少一部分。并且能减少数据的移动,每次插入都是插入到最后。总之就是减少分裂和移动的频率
为什么索引结构默认使用B-Tree,而不是hash,二叉树,红黑树?
- hash:虽然可以快速定位,但是没有顺序,IO复杂度高。
- 二叉树:树的高度不均匀,不能自平衡,查找效率跟数据有关(树的高度),并且IO代价高。
- 红黑树:树的高度随着数据量增加而增加,IO代价高。
以上就是关于散列表,B-树,B+树的总结,如有错误之处,欢迎大家指正,讨论!
【参考文档】
1. https://mp.weixin.qq.com/s?__biz=MzI5MTU1MzM3MQ==&mid=2247484006&idx=1&sn=3e15abeb5299a3e9b578332dd8565273&scene=21#wechat_redirect
2. https://blog.csdn.net/sinat_32176267/article/details/85460695
3. https://www.cnblogs.com/liqiangchn/p/9060521.html
4. << 数据库结构高分笔记 >>