007 Hadoop集群配置 Hadoop集群的启动和测试 SSH免登陆配置( start-all.sh) hdfs常用的shell
Hadoop集群配置

三种模式 本地 伪分布式 全分布式
伪分布式 看官网配置 比较简单?https://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-common/SingleCluster.html#Standalone_Operation
全分布式
Fully-Distributed Mode
http://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/ClusterSetup.html
先安装Java
再安装与Java版本相匹配的Hadoop版本
hadoop全分布式环境搭建
规划:




通过前面的学习
Java的jdk和单机版hadoop已经安装
ssh先不安装
然后进行
还是规划


即

我的是192.168.37.111
开始配置hadoop
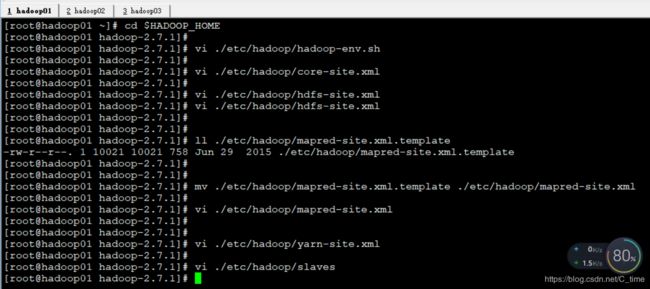
1.先进入目录然后配置 cd $HADOOP_HOME
vi ./etc/hadoop/hadoop-env.sh
这个以前配过了

2.hadoop的核心配置文件
vi ./etc/hadoop/core-site.xml
官网上是2.9.2版本 131072 我们这里先使用4096
进入后有一个空的configuration 写在这里面 配三个东西
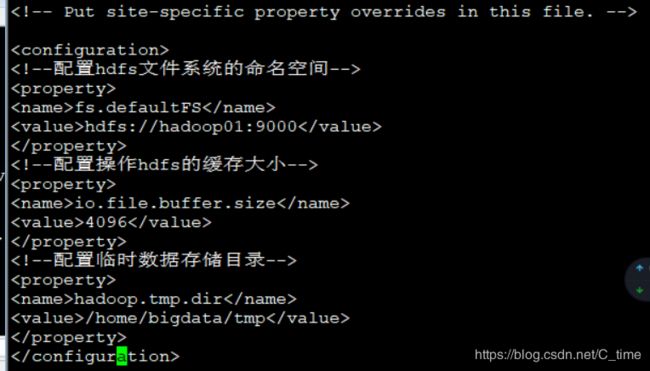
fs.defaultFS
hdfs://hadoop01:9000
io.file.buffer.size
4096
hadoop.tmp.dir
/home/bigdata/tmp
3.配置hdfs模块相关信息
vi ./etc/hadoop/hdfs-site.xml
dfs.replication
3
dfs.block.size
134217728
dfs.namenode.name.dir
/home/hadoopdata/dfs/name
dfs.datanode.dir
/home/hadoopdata/dfs/data
fs.checkpoint.dir
/home/hadoopdata/checkpoint/dfs/cname
dfs.http.address
hadoop01:50070
dfs.secondary.http.address
hadoop01:50090
dfs.webhdfs.enabled
false
dfs.permissions
false
需要先将文件改个名 再去配置内容
mv ./etc/hadoop/mapred-site.xml.template ./etc/hadoop/mapred-site.xml

现在完成规划
01后添加NameNode DataNode resourcemanager nodemanager
02 03添加DataNode nodemanager

mapreduce.framework.name
yarn
true
mapreduce.jobhistory.address
hadoop01:10020
mapreduce.jobhistory.webapp.address
hadoop01:19888
vi ./etc/hadoop/yarn-site.xml
yarn.resourcemanager.hostname
hadoop01
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.address
hadoop01:8032
yarn.resourcemanager.scheduler.address
hadoop01:8030
yarn.resourcemanager.resource-tracker.address
hadoop01:8031
yarn:resourcemanager.admin.address
hadoop01:8033
yarn:resourcemanager.webapp.address
hadoop01:8088
前面那几个都写到配置文件的configuration里面
vi ./etc/hadoop/slaves
打开后 删除里面的localhost
然后写入
hadoop01
hadoop02
hadoop03
这样六个配置文件就算弄完了

下一步
远程分发到别的服务器上面
首先 先把hadoop02 03的hadoop文件删掉
所以
使用
rm -rf /usr/local/hadoop-2.7.1/
删除完成后检查一下是否还有
结果02 03都没了hadoop了

此时这两个which hadoop是没了的

然后可以分发了
scp -r ../hadoop-2.7.1/ hadoop02:/usr/local/
如果出现找不到hadoop02的问题 需要配置hosts
将02 03 写上

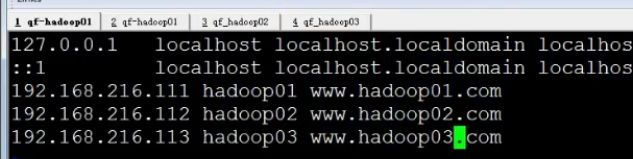
这里我们之前是弄了的 只是说明一下
可能会让你输入yes 输入就行
然后输入hadoop02的密码root
然后就开始了
可能比较慢
相同的方法搞到03上去

哎 这里视频说 你要嫌慢 可以删除 01里面的hadoop的学习文档 再传输
(如果已经传输了 可是执行rm的操作 删除学习文档后重新传输)
其实差不了几秒 我就没弄

结束
上面的操作即这两句话

然后
我们就可以启动我们的hadoop集群了
不过还有好多工作要做
1.启动之前格式化 只需要一次即可
在namenode服务器上 即hadoop01

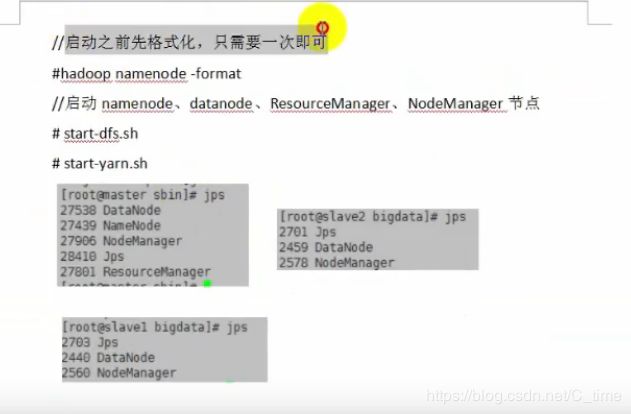
格式化之前

使用hadoop namenode -format语句格式化(在01上使用)

看到这一句时表示格式化成功
格式化之后 home目录出现hadoopdata文件目录

然后一层一层的往下看
最下面就是我们的元数据

格式化之后就可以正常的启动服务了
这里一共有三种启动方式
1.全启动
2.模块启动
3单个进程启动

注意此时啊
02 03 的/home/下面是没有hadoop的相关目录的
只有01有 因为只有01有元数据
当真正写数据的时候 02 03才会创建相应目录
我们使用
./sbin/start-dfs.sh 启动试试
过程中需要输入yes
密码
输好几次
所以很繁琐 在我们配置ssh免密登录之后就可以不用这么麻烦了

我们看到它停在02这个地方
所以我们到02看看
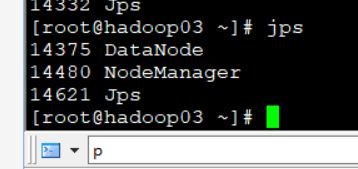
使用jps命令

判断是否启动成功使用jps 查看java进程的例子
这里啊 我启动了两编 视频中一遍就成功了
我第一遍01和03的jps都没有DataNode
又运行了一遍启动命令才可以
结果如下
三个的DataNode都启动了
01的SecondaryNameNode也启动了
01

02

03
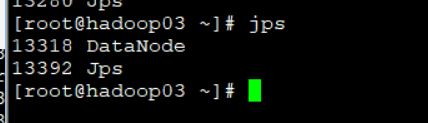
测试
1.如上jps命令查看 (查看进程是否安装规划启动起来)
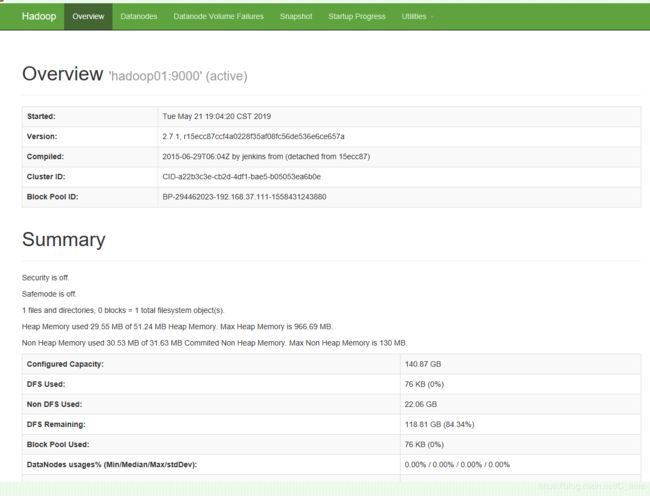
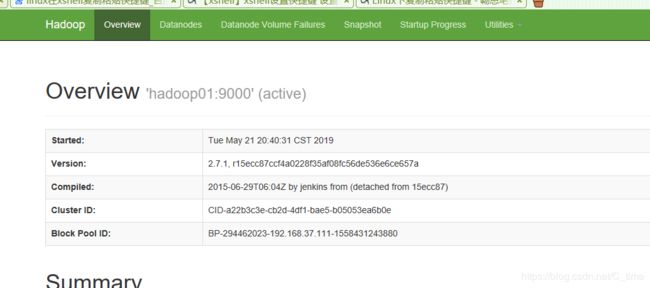
2.访问192.168.37.111:50070(查看对应模块的web ui监控是否正常)
3.上传和下载文件(测试hsfs)
然后跑一个MapReduce的作业
上传测试
先使用hdfs dfs -ls / (查看根目录是否有文件 结果是没有)
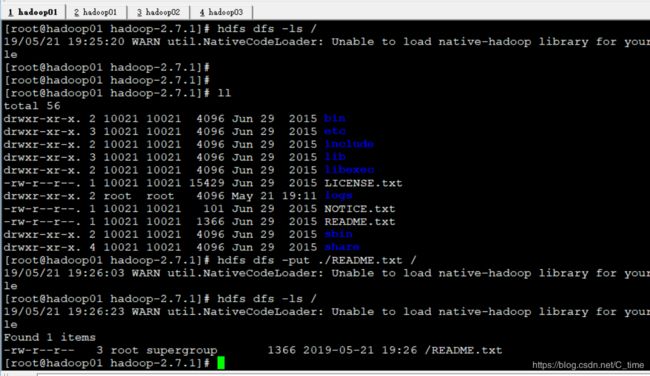
然后看一下当前目录下有啥 ll 看到有个Readme txt 就它了 把它传上去
使用
hdfs dfs -put ./README.txt /
上传至根目录
然后再次查看
结果显示有了那个文件
上传成功
然后我们看一下其中内容
注意 hdfs没有相对目录 不能打点. 只能使用绝对路径
使用hdfs dfs -cat /README.txt
结果如下 内容就读出来了

至此 hdfs模块的集群就算是搞完了
接下来我们看 yarn模块
还是那三步

start-yarn.sh
启动起来
然后是输入三遍密码
然后使用jps看一下 看看是否NodeManager启动了
其中 01 多启动了 ResourceManager
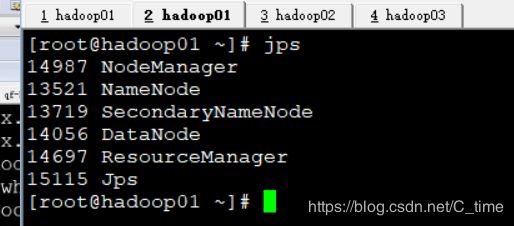

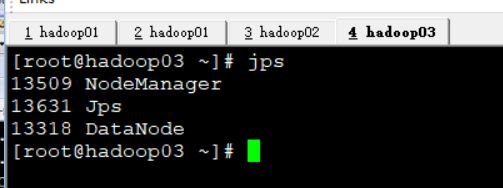
成功启动了三个的NodeManager
这个符合规划
-
./sbin/start-dfs.sh启动hdfs模块的DataManager和SecondaryManager
-
start-yarn.sh 启动yarn模块的 NodeManager 和 ResourceManager
测试第二步
192.168.37.111:8088
也成功了


3.测试第三步 跑一个MapReduce作业
使用默认的jar来跑
我们来测试一个文件单词出现次数
此时使用的目录
即输入文件的目录
如果说是集群在跑作业的时候
我们的输入数据一定是hdfs文件系统下的数据
我们刚刚上传了一个文件就用这个吧readme的
yarn jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.1.jar wordcount /README.txt /out/00
wordcount这个单词不能写错
然后写输入目录
输出目录
回车

这样算是跑完了 然后就是结果
先看web端

然后继续看
hdfs dfs -ls /out
看看这下面是否有文件

有的
然后继续看00的信息

注意里面有两个 part那个是内容
使用-cat查看
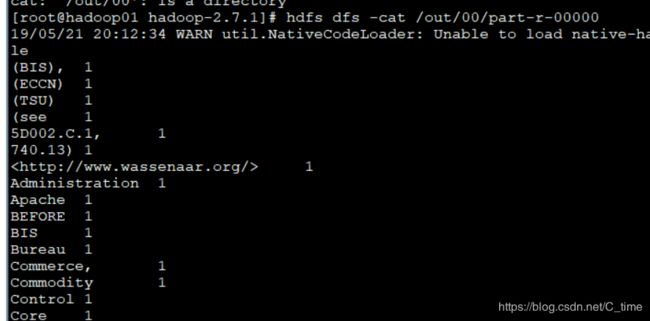
现在我们的启动和测试完成了
但是
每次启动都需要输好多密码 麻烦
所以我们需要配置SSH
SSH免登陆设置
官网上说要先下载
不用的 Linux上都有
我们which ssd就可以看到

现在 我们来做一些配置
第一步 :输入
ssh-keygen -t rsa
然后回车回车回车 目的就是生成几个文件 (貌似是 什么 …公钥私钥的信息 登陆过服务器的主机名)
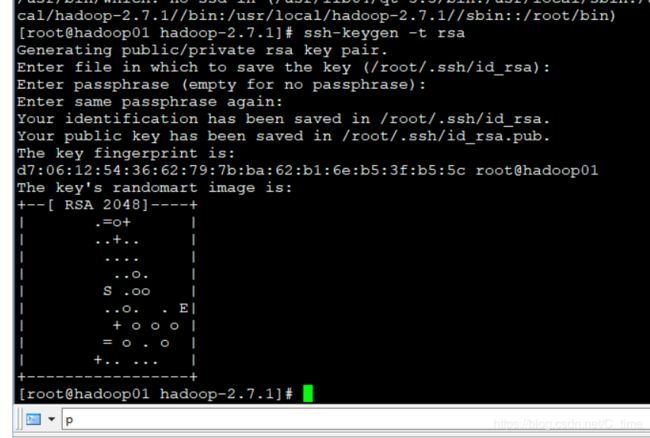
我们看一下
hadoop01家目录下面的ssh多了几个文件的
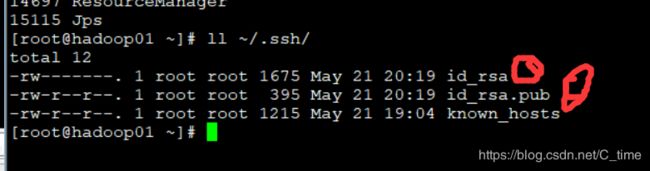
以02作对比 02是没有任何内容的

第二步:
然后开始设置ssh
有三种方式

我们这里使用最后一种 比较简单一些
首先我们先试试哈 这是配置之前的效果
ssh hadoop01 然后输密码
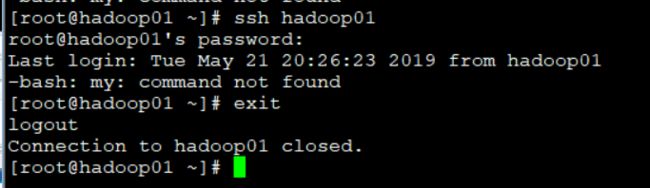
然后我们照着方法配置一下
ssh-copy-id hadoop01 输密码 退出

看ssh文件 果然 多了一个keys文件
我们再次登录
ok 不需要输密码了

同样的方法配置hadoop02 03 (在01下进行 其实都可以 目的就为了生成那个文件)
ssh-cppy-id hadoop02 输密码 退出 查看02的ssh文件 登录 不需要密码了
ssh-cppy-id hadoop03 输密码 退出 查看03的ssh文件 登录 不需要密码了
这样就可以了
我们来停止所有服务
原来是需要输入密码 现在应该不输入密码了
stop-all.sh

然后再启动
start-all.sh
不用输密码启动成功
start-all.sh

使用jps查看也是正确的
01

02
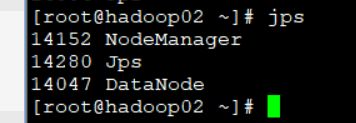
03
然后看web
50070
8088

hdfs常用的shell

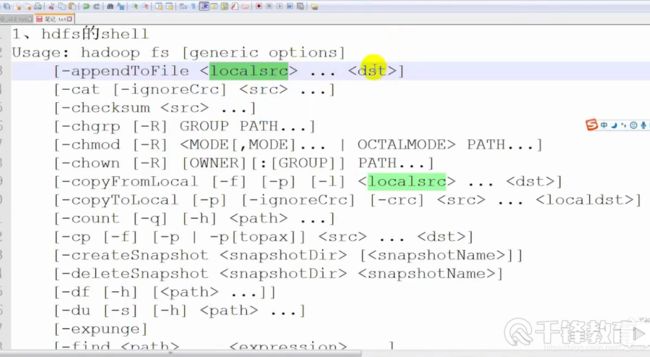
这个是输入
hdfs dfs -
hdfs dfs -
出来了这么多 我们可供使用的
Usage: hadoop fs [generic options]
[-appendToFile … ]追加文件到某个 localsrc指的是LInux本地的 dst指的是hdfs文件系统的
[-cat [-ignoreCrc] …]读取文件内容
[-checksum …]
[-chgrp [-R] GROUP PATH…]改变组 -R递归
[-chmod [-R]
[-chown [-R] [OWNER][:[GROUP]] PATH…]改拥有者
[-copyFromLocal [-f] [-p] [-l] … ]把来自本地的文件copy到hdfs系统
[-copyToLocal [-p] [-ignoreCrc] [-crc] … ]这个反着 copy到本地
[-count [-q] [-h] …]
[-cp [-f] [-p | -p[topax]] … ]
[-createSnapshot []]
[-deleteSnapshot ]
[-df [-h] [ …]]
[-du [-s] [-h] …]
[-expunge]
[-find … …]
[-get [-p] [-ignoreCrc] [-crc] … ]下载·
[-getfacl [-R] ]
[-getfattr [-R] {-n name | -d} [-e en] ]
[-getmerge [-nl] ]
[-help [cmd …]]
[-ls [-d] [-h] [-R] [ …]]
[-mkdir [-p] …]
[-moveFromLocal … ]
[-moveToLocal ]
[-mv … ]
[-put [-f] [-p] [-l] … ]
[-renameSnapshot ]
[-rm [-f] [-r|-R] [-skipTrash] …]
[-rmdir [–ignore-fail-on-non-empty]
[-setfacl [-R] [{-b|-k} {-m|-x
[-setfattr {-n name [-v value] | -x name} ]
[-setrep [-R] [-w] …]
[-stat [format] …]
[-tail [-f] ]
[-test -[defsz] ]
[-text [-ignoreCrc] …]
[-touchz …]
[-truncate [-w] …]
[-usage [cmd …]]
hdfs中的shell命令
通常都是这样
hdfs dfs - /
杠 加命令 斜杠 加 绝对目录
或者hadoop fs - /
例子
查看 -ls

hdfs dfs -ls /
查看hdfs根目录的文件
或者hadoop fs -ls /也行(不过这是老版本了)

也可以使用-ls -R大写 递归查看目录
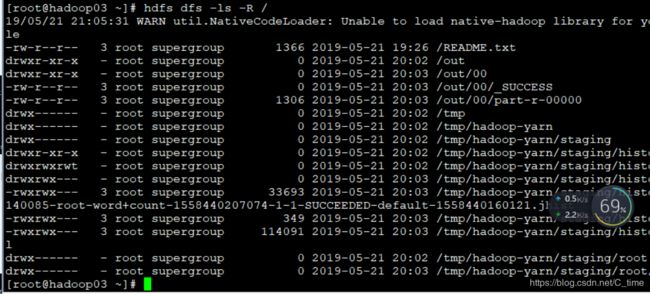
创建目录
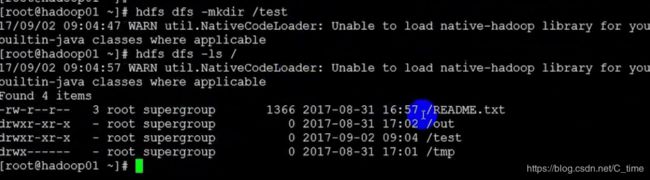
hdfs dfs -mkdir /test
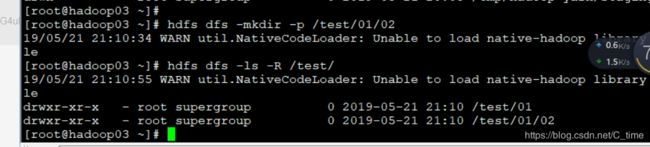
递归创建目录
递归创建 -p
hdfs dfs -mkdir -p /test/01/02
然后查看 hdfs dfs -ls -R /test/
创建文件 (是空的!!!)
hdfs dfs -touchz /test/te.txt
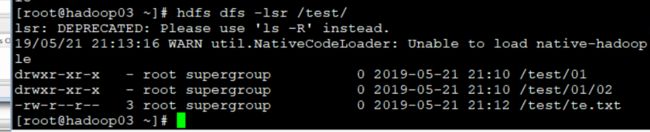
注意 由于不能修改 所以只能追加
然后复制-cp
hdfs dfs -lsr /test/01
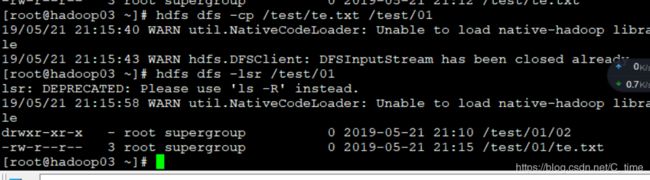

移动-mv
hdfs dfs -mv /test/01/te.txt /test/01/02
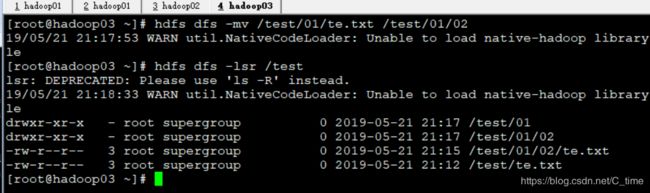
-mv还可以在移动过程中改名

上传文件
将本地的上传到hdfs中
先进入到home的shell目录下 看看有啥 我们传一个if.sh吧
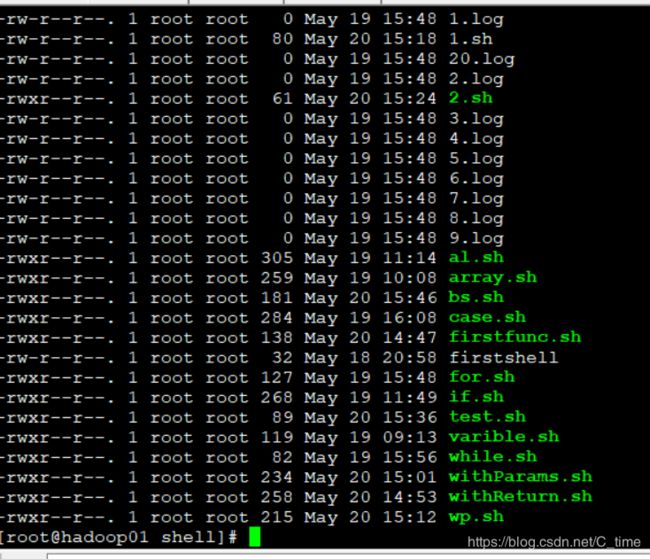
然后hdfs dfs -put ./if.sh /test

除了-put
还有一个-copyFromLocal可以实现文件复制上传

hdfs dfs -get /test/if.sh /home/if 顺便还可以改名
然后我们实现文件下载-get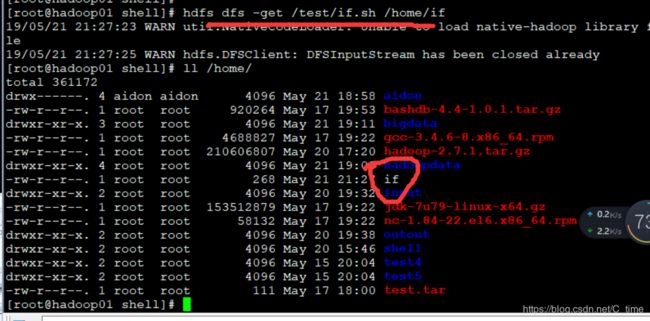
下载成功
同样的 下载命令还有
-copyToLocal
hdfs dfs -copyToLocal /test/for.sh /home/for
下载成功

hdfs查看真正的文件内容
-text

hdfs dfs -text /test/if.sh
-tail
这个也能查看文件内容
也可以进行监控功能

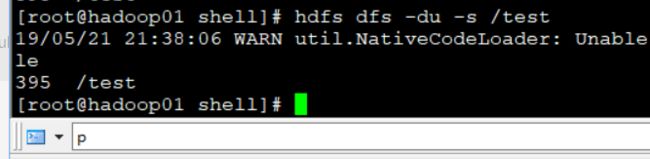
-du
查看目录大小

-du -s
加s是总和的意思