Hive函数06_多维计算函数(grouping sets,cube,roll up)
一、GROUPING SETS
GROUPING SETS作为GROUP BY的子句,允许开发人员在GROUP BY语句后面指定多个统计选项,可以简单理解为多条group by语句通过union all把查询结果聚合起来结合起来,下面是几个实例可以帮助我们了解,
1.基础语法
| grouping sets语句 | 等价hive语句 |
|---|---|
| select device_id,os_id,app_id,count(user_id) from test_xinyan_reg group by device_id,os_id,app_id grouping sets((device_id)) | SELECT device_id,null,null,count(user_id) FROM test_xinyan_reg group by device_id |
| select device_id,os_id,app_id,count(user_id) from test_xinyan_reg group by device_id,os_id,app_id grouping sets((device_id,os_id)) | SELECT device_id,os_id,null,count(user_id) FROM test_xinyan_reg group by device_id,os_id |
| select device_id,os_id,app_id,count(user_id) from test_xinyan_reg group by device_id,os_id,app_id grouping sets((device_id,os_id),(device_id)) | SELECT device_id,os_id,null,count(user_id) FROM test_xinyan_reg group by device_id,os_id UNION ALL SELECT device_id,null,null,count(user_id) FROM test_xinyan_reg group by device_id |
| select device_id,os_id,app_id,count(user_id) from test_xinyan_reg group by device_id,os_id,app_id grouping sets((device_id),(os_id),(device_id,os_id),()) | SELECT device_id,null,null,count(user_id) FROM test_xinyan_reg group by device_id UNION ALL SELECT null,os_id,null,count(user_id) FROM test_xinyan_reg group by os_id UNION ALLSELECT device_id,os_id,null,count(user_id) FROM test_xinyan_reg group by device_id,os_id UNION ALL SELECT null,null,null,count(user_id) FROM test_xinyan_reg |
2.案例:分组汇公司的每一年的收入
我们大家也都很熟悉GROUP BY子句来实现聚合表达式,但是如果打算在一个结果集中包含多种不同的汇总结果,可能会比较麻烦。我将举例展示给大家使用GROUPING SETS操作符来完成这个“混合的结果集”。
如果你想要多种不同组合的聚合时,一般有两种方式:
a.将不懂组合聚合的结果集UNIONALL在一起。
b.使用 GROUPING SETS操作符,结合GROUP BY一起在一个语句中实现。
Query 1. 汇总每年收入
SELECT
YEAR( OrderDate ) AS OrderYear,
SUM( SubTotal ) AS Income
FROM
Sales.SalesOrderHeader
GROUP BY
YEAR ( OrderDate )
ORDER BY
OrderYear;
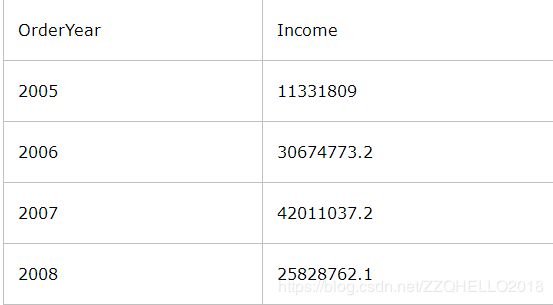
根据这个结果集,可知该公2005到2008年的收入情况。这类数据信息对于商业分析来说很常见。
如果你想要更多关于收入的信息,比如其他汇总条件,你必须要重新运行一个GROUP BY子句。比如查询返回公司每个月的收入情况。查询语句如下:
Query 2. 公司每个月的收入
SELECT YEAR
( OrderDate ) AS OrderYear,
MONTH ( OrderDate ) AS OrderMonth,
SUM( SubTotal ) AS Income
FROM
Sales.SalesOrderHeader
GROUP BY
YEAR ( OrderDate ),
MONTH ( OrderDate )
ORDER BY
OrderYear,
OrderMonth;
结果集格式如下:
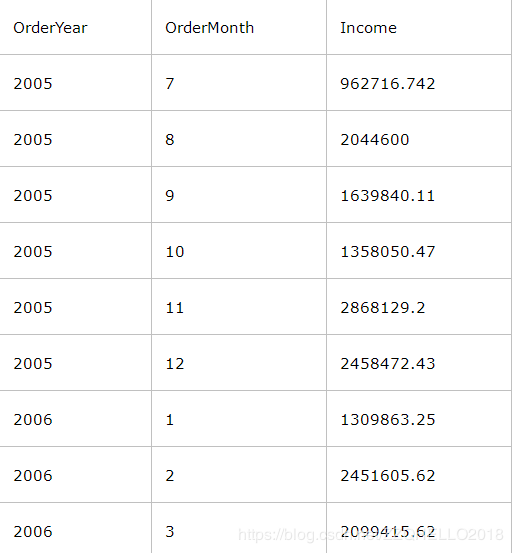
这个结果集要比之前的更详细一点。可以得到具体某个月的收入汇总。显然GROUP BY 后面的列越多其越详细,结果一般也越多(除非有传递依赖键)。
如果你仔细观察两个查询,你会发现他们都是根据个子的分组表达式进行分组汇总的。前面的是按照年,后面的是按照年和月。
假如我想查看两种汇总结果在一个结果集中应该怎么处理那?为了实现这个目标,我们前面说了两个方案,方案1就是使用UNION ALL,代码如下:
Query 3. 公司收入(每年|每月)
SELECT
YEAR( OrderDate ) AS OrderYear,
NULL AS OrderMonth,-- 虚拟列
SUM( SubTotal ) AS Incomes
FROM
Sales.SalesOrderHeader
GROUP BY
YEAR ( OrderDate )
UNION ALL
SELECT
YEAR( OrderDate ) AS OrderYear,
MONTH ( OrderDate ) AS OrderMonth,
SUM( SubTotal ) AS Incomes
FROM
Sales.SalesOrderHeader
GROUP BY
YEAR ( OrderDate ),
MONTH ( OrderDate )
ORDER BY
OrderYear,
OrderMonth;
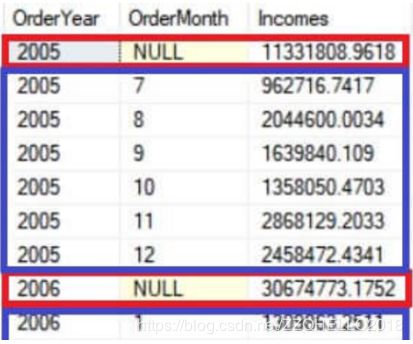
其中红色框内为按照年的汇总数据。蓝色框内为按照年和月的分组汇总。
如图所示两个结果集被合并在一起了。
注意。此时NULL出现在里面,使用NULL作为假列(虚拟列)来标识order year分组的结果。因为按年分组没有这个列。
尽管你已经获得了想要的结果,但是这样需要完成两次的语句,接下来我们尝试一下grouping sets,
目的就是 “更少代码,相同结果"
SELECT
YEAR( OrderDate ) AS OrderYear,
MONTH ( OrderDate ) AS OrderMonth,
SUM( SubTotal ) AS Incomes
FROM
Sales.SalesOrderHeader
GROUP BY
GROUPING SETS
( YEAR ( OrderDate ), -- 1st grouping SET
( YEAR ( OrderDate ),
MONTH ( OrderDate ) ) -- 2nd grouping SET );
结果集跟之前的一模一样。但是新的代码要少很多。GROUPING SETS 操作符要和GROUP BY 子句在一起使用。并且允许我们可以做一个多分组的查询。尽管如此,我们要仔细检查指定的分组集。例如假如一个分组包含两个列,假设列A和B,两个列都需要包含在括号内:(column A, column B)。如果没有括号,这个子句将会被定义为独立的分组,结果就不同了。
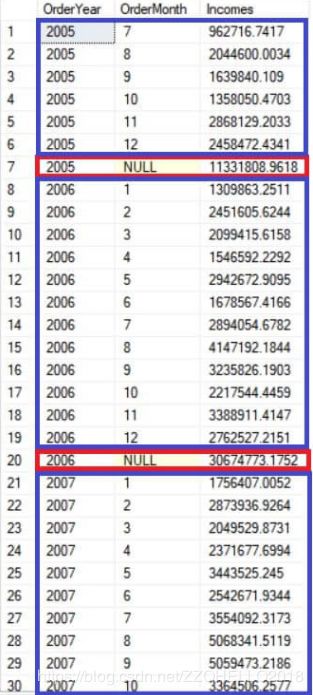
上面的结果集:
顺便说一下,如果我们打算聚合整个结果集(不分组聚合所有数据),只需要添加有一个空的括号在分组集里面即可。查询语句如下:
SELECT YEAR
( OrderDate ) AS OrderYear,
MONTH ( OrderDate ) AS OrderMonth,
SUM( SubTotal ) AS Incomes
FROM
Sales.SalesOrderHeader
GROUP BY
GROUPING SETS ( YEAR ( OrderDate ), -- 1st grouping set
( YEAR ( OrderDate ), MONTH ( OrderDate ) ), -- 2nd grouping set
( ) -- 3rd grouping set (grand total)
);
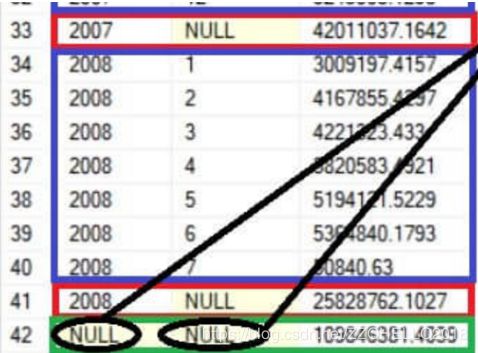
注意最下方的42行,年月都为null,这个查询汇总了郑铁的所有收入,因为没有进行任何分组。
注意,需要强调一个十强,一定要确保分组列字段部位NULL,因此NULLS不能被用作分组列在GROUPING SETS中使用。如果非要那个为空字段,需要使用 GROUPING 或者 GROUPING_ID 函数判断是否NULL来自GROUPING SETS 操作符。
二、CUBE
cube简称数据魔方,可以实现hive多个任意维度的查询,cube(a,b,c)则首先会对(a,b,c)进行group by,然后依次是(a,b),(a,c),(a),(b,c),(b),©,最后在对全表进行group by,他会统计所选列中值的所有组合的聚合
select device_id,os_id,app_id,client_version,from_id,count(user_id)
from test_xinyan_reg
group by device_id,os_id,app_id,client_version,from_id with cube;
等价于以下sql
SELECT device_id,null,null,null,null ,count(user_id) FROM test_xinyan_reg
group by device_id
UNION ALL
SELECT null,os_id,null,null,null ,count(user_id) FROM test_xinyan_reg
group by os_id
UNION ALL
SELECT device_id,os_id,null,null,null ,count(user_id) FROM test_xinyan_reg
group by device_id,os_id
UNION ALL
SELECT null,null,app_id,null,null ,count(user_id) FROM test_xinyan_reg
group by app_id
UNION ALL
SELECT device_id,null,app_id,null,null ,count(user_id) FROM test_xinyan_reg
group by device_id,app_id
UNION ALL
SELECT null,os_id,app_id,null,null ,count(user_id) FROM test_xinyan_reg
group by os_id,app_id
UNION ALL
SELECT device_id,os_id,app_id,null,null ,count(user_id) FROM test_xinyan_reg
group by device_id,os_id,app_id
UNION ALL
SELECT null,null,null,client_version,null ,count(user_id) FROM test_xinyan_reg
group by client_version
UNION ALL
SELECT device_id,null,null,client_version,null ,count(user_id) FROM test_xinyan_reg
group by device_id,client_version
UNION ALL
SELECT null,os_id,null,client_version,null ,count(user_id) FROM test_xinyan_reg
group by os_id,client_version
UNION ALL
SELECT device_id,os_id,null,client_version,null ,count(user_id) FROM test_xinyan_reg
group by device_id,os_id,client_version
UNION ALL
SELECT null,null,app_id,client_version,null ,count(user_id) FROM test_xinyan_reg
group by app_id,client_version
UNION ALL
SELECT device_id,null,app_id,client_version,null ,count(user_id) FROM test_xinyan_reg
group by device_id,app_id,client_version
UNION ALL
SELECT null,os_id,app_id,client_version,null ,count(user_id) FROM test_xinyan_reg
group by os_id,app_id,client_version
UNION ALL
SELECT device_id,os_id,app_id,client_version,null ,count(user_id) FROM test_xinyan_reg
group by device_id,os_id,app_id,client_version
UNION ALL
SELECT null,null,null,null,from_id ,count(user_id) FROM test_xinyan_reg
group by from_id
UNION ALL
SELECT device_id,null,null,null,from_id ,count(user_id) FROM test_xinyan_reg
group by device_id,from_id
UNION ALL
SELECT null,os_id,null,null,from_id ,count(user_id) FROM test_xinyan_reg
group by os_id,from_id
UNION ALL
SELECT device_id,os_id,null,null,from_id ,count(user_id) FROM test_xinyan_reg
group by device_id,os_id,from_id
UNION ALL
SELECT null,null,app_id,null,from_id ,count(user_id) FROM test_xinyan_reg
group by app_id,from_id
UNION ALL
SELECT device_id,null,app_id,null,from_id ,count(user_id) FROM test_xinyan_reg
group by device_id,app_id,from_id
UNION ALL
SELECT null,os_id,app_id,null,from_id ,count(user_id) FROM test_xinyan_reg
group by os_id,app_id,from_id
UNION ALL
SELECT device_id,os_id,app_id,null,from_id ,count(user_id) FROM test_xinyan_reg
group by device_id,os_id,app_id,from_id
UNION ALL
SELECT null,null,null,client_version,from_id ,count(user_id) FROM test_xinyan_reg
group by client_version,from_id
UNION ALL
SELECT device_id,null,null,client_version,from_id ,count(user_id) FROM test_xinyan_reg
group by device_id,client_version,from_id
UNION ALL
SELECT null,os_id,null,client_version,from_id ,count(user_id) FROM test_xinyan_reg
group by os_id,client_version,from_id
UNION ALL
SELECT device_id,os_id,null,client_version,from_id ,count(user_id) FROM test_xinyan_reg
group by device_id,os_id,client_version,from_id
UNION ALL
SELECT null,null,app_id,client_version,from_id ,count(user_id) FROM test_xinyan_reg
group by app_id,client_version,from_id
UNION ALL
SELECT device_id,null,app_id,client_version,from_id ,count(user_id) FROM test_xinyan_reg
group by device_id,app_id,client_version,from_id
UNION ALL
SELECT null,os_id,app_id,client_version,from_id ,count(user_id) FROM test_xinyan_reg
group by os_id,app_id,client_version,from_id
UNION ALL
SELECT device_id,os_id,app_id,client_version,from_id ,count(user_id) FROM test_xinyan_reg
group by device_id,os_id,app_id,client_version,from_id
UNION ALL
SELECT null,null,null,null,null ,count(user_id) FROM test_xinyan_reg
三、ROLL UP
rollup可以实现从右到左递减多级的统计,显示统计某一层次结构的聚合。
select device_id,os_id,app_id,client_version,from_id,count(user_id)
from test_xinyan_reg
group by device_id,os_id,app_id,client_version,from_id
with rollup;
等价于以下sql
select device_id,os_id,app_id,client_version,from_id,count(user_id)
from test_xinyan_reg
group by device_id,os_id,app_id,client_version,from_id
grouping sets ((device_id,os_id,app_id,
client_version,from_id),
(device_id,os_id,app_id,client_version),
(device_id,os_id,app_id),
(device_id,os_id),(device_id),());
四、Grouping_ID
当我们没有统计某一列时,它的值显示为null,这可能与列本身就有null值冲突,这就需要一种方法区分是没有统计还是值本来就是null。(grouping_id其实就是所统计各列二进制和)
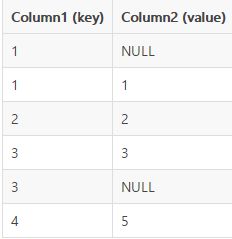
hsql:
SELECT key, value, GROUPING__ID, count(*) from T1 GROUP BY key, value WITH ROLLUP
结果
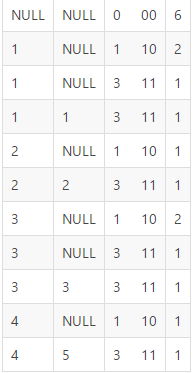
GROUPING__ID转变为二进制,如果对应位上有值为null,说明这列本身值就是null。